

(八)sklearn中计算准确率、召回率、精确度、F1值
介绍
准确率、召回率、精确度和F1分数是用来评估模型性能的指标。尽管这些术语听起来很复杂,但它们的基本概念非常简单。它们基于简单的公式,很容易计算。
这篇文章将解释以下每个术语:
- 为什么用它
- 公式
- 不用sklearn来计算
- 使用sklearn进行计算
在本教程结束时,我们将复习混淆矩阵以及如何呈现它们。文章的最后提供了谷歌colab笔记本的链接。
数据
假设我们正在对一封电子邮件进行分类,看它是不是垃圾邮件。
我们将有两个数组,第一个数组将存储实际值,而第二个数组将存储预测值。这些预测值是从分类器模型中获得的。模型的类型并不重要,我们感兴趣的是模型所做的预测。
# 实际值
labels = [1, 0, 0, 1, 1, 1, 0, 1, 1, 1]
# 预测值
predictions = [0, 1, 1, 1, 1, 0, 1, 0, 1, 0]
0-邮件不是垃圾邮件(负)
1-电子邮件是垃圾邮件(正)
关键术语
真正例
当标签为正且我们的预测值也为正时,就会发生这种情况。在我们的场景中,当电子邮件是垃圾邮件时,模型也将其分类为垃圾邮件。
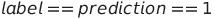
TP = 0
for i in range(0,len(labels)):
if labels[i] == predictions[i] and labels[i] == 1:
TP+=1
print("True Positive: ", TP) # 3
假正例
这种情况发生在标签为负但我们的模型预测为正的情况下。在我们的场景中,当电子邮件不是垃圾邮件,但模型将其分类为垃圾邮件时。
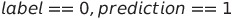
FP = 0
for i in range(0,len(labels)):
if labels[i] == 0 and predictions[i] == 1:
FP+=1
print("False Positive: ", FP) # 3
真反例
这类似于真正例,唯一的区别是标签和预测值都是负。在我们的场景中,当电子邮件不是垃圾邮件时,模型也将其分类为非垃圾邮件。
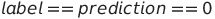
TN = 0
for i in range(0,len(labels)):
if labels[i] == predictions[i] and labels[i] == 0:
TN+=1
print("True Negative: ", TN) # 0
假反例
这种情况发生在标签为正但预测值为负的情况下。在某种程度上,与假正例相反。在我们的场景中,当电子邮件是垃圾邮件,但模型将其分类为非垃圾邮件。
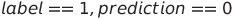
FN = 0
for i in range(0,len(labels)):
if labels[i] == 1 and predictions[i] == 0:
FN+=1
print("False Negative: ", FN) # 4
正确预测
这种情况是标签和预测值相同。在本例中,当模型将垃圾邮件分类为垃圾邮件,将非垃圾邮件分类为非垃圾邮件时。
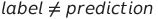
也可以计算为真正例与真负例的总和。

ICP = 0
for i in range(0,len(labels)):
if labels[i] != predictions[i]:
ICP+=1
print("Incorrect Prediction: ", ICP)# 7
print(ICP == FP + FN) # True
不正确的预测
这种情况的条件是,标签和预测值不相等。在我们的场景中,错误的预测是模型将垃圾邮件分类为非垃圾邮件,将非垃圾邮件分类为垃圾邮件。
错误预测也可以计算为假正例和假反例的总和。
ICP = 0
for i in range(0,len(labels)):
if labels[i] != predictions[i]:
ICP+=1
print("Incorrect Prediction: ", ICP)# 7
print(ICP == FP + FN) # True
准确率
准确率是正确的预测数与预测总数的比率。这是对模型最简单的度量之一。我们必须力求我们的模型达到高准确率。如果一个模型具有较高的准确率,可以推断出该模型在大多数情况下做出了正确的预测。
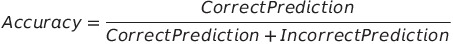
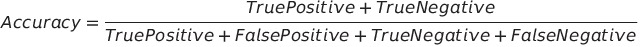
不使用Sklearn
accuracy = (TP + TN)/(TP + FP + TN + FN)
print(accuracy*100)
使用Sklearn
from sklearn.metrics import accuracy_score
print(accuracy_score(labels , predictions)*100)
召回率
准确率可能会误导人
高准确率有时会使人产生误解。考虑下面的场景:
labels = [0,0,0,0,1,0,0,1,0,0]
predictions = [0 ,0 ,0 ,0 ,0 , 0 ,0 ,0 ,0 ,0]
print(accuracy_score(labels , predictions)*100) # 80
与非垃圾邮件相比,垃圾邮件很少见。因此,label = 0的出现次数要高于label = 1的出现次数。在上面的代码中,labels有8个非垃圾邮件和2个垃圾邮件。
如果模型总是将邮件分类为非垃圾邮件,那么准确率将达到80%。这是高度误导,因为模型基本上无法检测垃圾邮件。
计算召回率
召回率计算预测正例数与正例标签总数的比率。
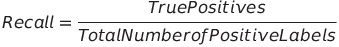
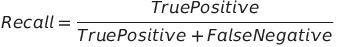
在上面的例子中,模型召回率为0,因为它有0个真正的正例。这告诉我们,模型在垃圾邮件上表现不佳,需要改进它。
不使用Sklearn
recall = (TP)/(TP+FN)
print(recall*100)
使用Sklearn
from sklearn.metrics import recall_score
print(recall_score(labels,predictions))
精确度
召回率可能具有误导性的案例
高召回率也很容易误导人。考虑当模型被调优为总是返回正值的预测时的情况。它基本上把所有的电子邮件都归类为垃圾邮件。
labels = [0,0,0,0,1,0,0,1,0,0]
predictions = [1,1,1,1,1,1,1,1,1,1]
print(accuracy_score(labels , predictions)*100)
print(recall_score(labels , predictions)*100)
虽然上述情况的准确率较低(20%),但召回率较高(100%)。
计算精确度
精确度是预测正确的正例数与正预测总数的比率。
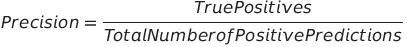

在上述情况下,精确度较低(20%),因为模型预测共10个正例,其中只有2个是正确的。这告诉我们,尽管召回率很高,而且模型在正面案例(即垃圾邮件)上表现很好,但在非垃圾邮件上表现很差。
我们的准确率和精确度相等的原因是,模型预测的是所有的正例结果。在现实世界中,模型可以正确地预测一些负面的情况,从而获得更高的准确率。然而,精确度仍然保持不变,因为它只依赖于预测正确的正例数和正预测总数。
不使用Sklearn
precision = TP/(TP+FP)
print(precision)
使用Sklearn
from sklearn.metrics import precision_score
print(precision_score(labels,predictions)*100)
F1得分
F1得分取决于召回和精确度,它是这两个值的调和平均值。
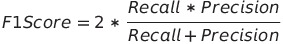
我们考虑调和平均值除以算术平均值,因为想要低召回率或精确度来产生低F1分数。在之前的例子中,召回率为100%,精确度为20%,算术平均值为60%,而调和平均值为33.33%。调和平均值更低,更有意义,因为我们知道模型很糟糕。
AM = (1 + 0.2)/2
HM = 2*(1*0.2)/(1+0.2)
print(AM)# 0.6
print(HM)# 0.333
不使用Sklearn
f1 = 2*(precision * recall)/(precision + recall)
print(f1)
使用Sklearn
from sklearn.metrics import f1_score
print(f1_score(labels, predictions))
混淆矩阵

混淆矩阵是一个表示真正例、假正例、真反例和假反例数的矩阵。
假设我们正在处理以下数据:
# 实际值
labels = [1, 0, 0, 1, 1, 1, 0, 1, 1, 1]
# 预测值
predictions = [0, 0, 1, 1, 1, 0, 1, 0, 1, 0]
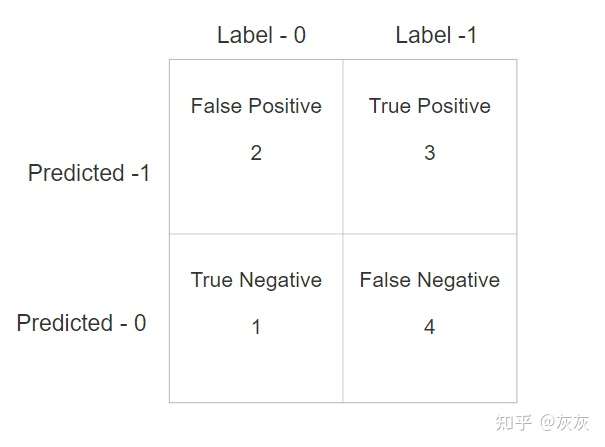
使用sklearn计算混淆矩阵
from sklearn.metrics import confusion_matrix
confusion = confusion_matrix(labels, predictions)
FN = confusion[1][0]
TN = confusion[0][0]
TP = confusion[1][1]
FP = confusion[0][1][1]
你还可以传递一个normalize参数来对计算数据进行规范化。
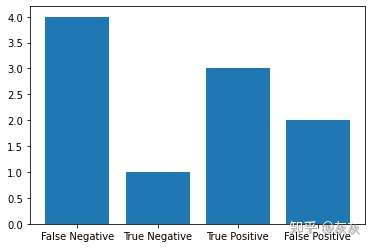
以条形图显示混乱矩阵
plt.bar(['False Negative' , 'True Negative' , 'True Positive' , 'False Positive'],[FN,TN,TP,FP])
plt.show()
将混淆矩阵显示为热图
import seaborn as sns
sns.heatmap(confusion , annot=True , xticklabels=['Negative' , 'Positive'] , yticklabels=['Negative' , 'Positive'])
plt.ylabel("Label")
plt.xlabel("Predicted")
plt.show()

使用pandas显示混乱矩阵
import pandas as pd
data = {'Labels' : labels, 'Predictions': predictions}
df = pd.DataFrame(data, columns=['Labels','Predictions'])
confusion_matrix = pd.crosstab(df['Labels'], df['Predictions'], rownames=['Labels'], colnames=['Predictions'])
print (confusion_matrix)

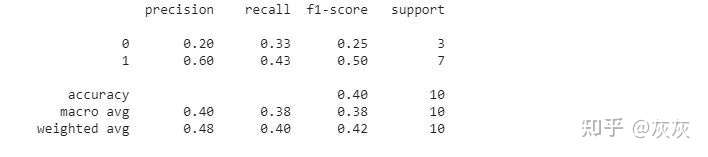
使用Sklearn生成分类报告
from sklearn.metrics import classification_report
print(classification_report(labels,predictions))
下面是输出:
结论
准确率本身并不能决定一个模型的好坏,但是准确率结合精确度、召回率和F1分数可以很好地说明模型的性能。
