

NLP(二十):相似问句生成--机器人的“标准问”库之Query生成
一、Query生成的目的及意义?
在问答系统任务(问答机器人)中,我们往往会人为地配置一些常用并且描述清晰的问题及其对应的回答,我们将这些配置好的问题称之为“标准问”。当用户进行提问时,常常将用户的问题与所有配置好的标准问进行相似度计算,找出与用户问题最相似的标准问,并返回其答案给用户,这样就完成了一次问答操作。
但是人为配置“标准问”库是一个耗时耗力的过程,并且生成高质量而具有总结概括性质的问题会给运营人员带来极大的负担。如果我们可以自动生成一些Query,供运营人员去选择的话,无疑于会给运营人员减轻很大的负担。简单地来说,就是创造与选择的区别,选择比创造要简单地多。
二、Query生成方法有哪些?
Query生成方法主要有两大类,一种是规则的方法,另一种就是模型的方法。而每种方法其实又包含两个方面。如果我们已经人为地配置过一些query了,但是量比较少时,可以根据已有的query去生成query。
规则的方法是比较简单的,但是生成的问题会比较单一。一般通过词典或NER技术,识别出已有query的关键词或重要词汇,然后将其中的关键词做替换或者通过模板将关键词套入,最终生成新的问题。如表1所示。

然而,规则方法的核心是规则的归纳与总结,这通常是比较麻烦地事情;往往需要人看过大量数据后(需要很多人力),才能构造出比较优秀的规则,但规则之间有时也会有冲突。
模型的方法一般是用过Seq2Seq模型,根据所给问题去生成新的问题。模型方法相较于规则方法来说,生成的问题会更多样化,陈述不会一成不变;并且会生成一些具有概述性质或者更加具体的问题,供运营人员的选择更多。如表2所示。

三、GPT2模型
目前,Seq2Seq模型有很多,包括LSTM、Transform、GPT、UniLM、GPT2、MASS等等。而GPT2模型在生成问题上表现优秀,因此使用GPT2模型训练了一个Query2Query的模型去扩充我们现有的“标准问”库。
GPT2_ML的项目开源了一个具有15亿参数的中文版的GPT2开源模型,我们在此模型基础上进行微调。
三军未动,粮草先行。模型未练,数据先行。我们的数据来自百度相似问句对,共有220多万相似问对。具体训练参数如表3所示。
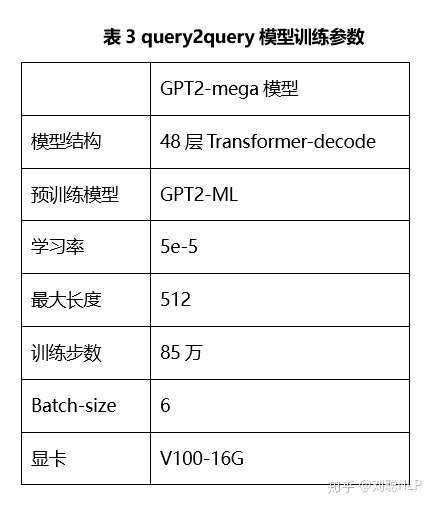
问题生成的效果如表4所示。

具体测试代码及模型,见github。
cd scripts/
python3 interactive_conditional_samples.py -model_config_fn ../configs/mega.json -model_ckpt /iyunwen/lcong/model/model.ckpt-850000 -top_p 5.0 -eos_token 102 -min_len 7 -samples 5 -do_topk True结果:

四、预训练权重与代码
1、代码
https://github.com/JasonZhangXianRong/QueryGeneration
2、权重
百度网盘
