

NLP(十九):基于transformer的对话系统:RNN、seq2seq、bert、GPT2
参考了pytorch官方文档:https://pytorch.org/tutorials/beginner/chatbot_tutorial.html
一、概述
使用pycharm编写项目,代码分为四个文件:process.py、neural_network.py、train.py、evaluate.py。
先大致说一下搭建chatbot的思路吧,其实很简单:这里的chatbot是基于带Luong attention机制的seq2seq。研究过NLP的同学应该对seq2seq很熟悉,它可以将任意长度的时序信息映射到任意长度,在基于深度神经网络的机器翻译中使用广泛。
实际上,中文翻译成英文就是训练出一个中文序列到英文序列的映射,而我们的chatbot不就是一个句子到句子的映射吗?在不考虑上下语境的情况下,聊天机器人可以使用seq2seq搭建。如此搭建的聊天机器人对用户输入的语句给出的回复更像是将用户说的话翻译成了用户希望得到的回复。那么假设我们已经对seq2seq很熟悉了,那么只需要使用一条条对话(下面叫dialog或者pair)作为数据,训练这个seq2seq模型就可以得到这个训练集风格的chatbot了。
tutorial使用的数据是Cornell Movie-Dialogs,下载地址。这部分数据的编码格式不是utf-8,如果你对编码转换这部分不感兴趣,可以直接使用笔者仓库中./data中的tsv数据。后面的程序中将会直接使用tsv数据。
提前说明一下,对话数据集中的每个pair中,我们把第一句话成为input_dialog,后面一句回复的话称为ouput_dialog。
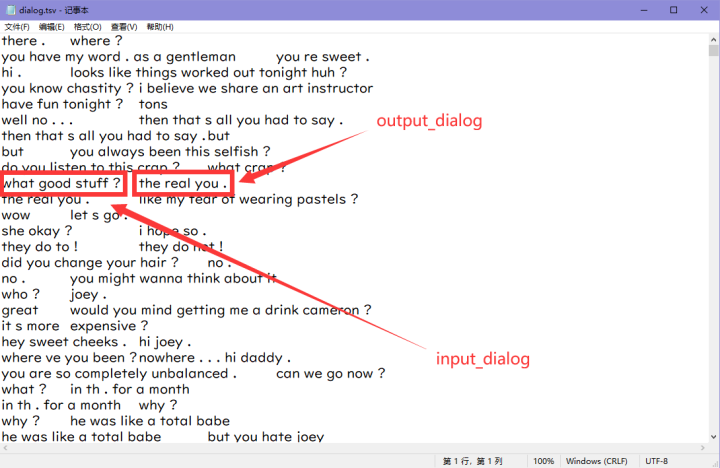
二、数据加载器
下面完成process.py,这个文件完成词表建立和数据加载器的建立。
说明:下面所有数据组织都是按照batch_first来的,也就是所有torch张量的第一个维度是batch_size
先引入需要的库
from itertools import zip_longest import random import torch
构建词表
第一步我们需要构建词表,因为网络中只会传递张量,我们需要通过构建词表将每个单词映射成一个个单词索引(后面成为index),也就是将一句话转化为index序列。
词表中最核心的数据是三个python类型的词典:
- word2index:单词到其对应的index的映射。
- index2word:index到其对应的单词的映射。
- word2count:单词到其在数据集中的总数的映射。
构建词表的逻辑也很简单,只需要遍历数据集,每遇到一个词表中没有的单词,就根据已经添加单词的总数给与这个新的单词一个index,并由此给word2index和index2word两个字典增加新的元素。
程序如下:
# 用来构造字典的类 class vocab(object): def __init__(self, name, pad_token, sos_token, eos_token, unk_token): self.name = name self.pad_token = pad_token self.sos_token = sos_token self.eos_token = eos_token self.unk_token = unk_token self.trimmed = False # 代表这个词表对象是否经过了剪枝操作 self.word2index = {"PAD" : pad_token, "SOS" : sos_token, "EOS" : eos_token, "UNK" : unk_token} self.word2count = {"UNK" : 0} self.index2word = {pad_token : "PAD", sos_token : "SOS", eos_token : "EOS", unk_token : "UNK"} self.num_words = 4 # 刚开始的四个占位符 pad(0), sos(1), eos(2),unk(3) 代表目前遇到的不同的单词数量 # 向voc中添加一个单词的逻辑 def addWord(self, word): if word not in self.word2index: self.word2index[word] = self.num_words self.word2count[word] = 1 self.index2word[self.num_words] = word self.num_words += 1 else: self.word2count[word] += 1 # 向voc中添加一个句子的逻辑 def addSentence(self, sentence): for word in sentence.split(): self.addWord(word) # 将词典中词频过低的单词替换为unk_token # 需要一个代表修剪阈值的参数min_count,词频低于这个参数的单词会被替换为unk_token,相应的词典变量也会做出相应的改变 def trim(self, min_count): if self.trimmed: # 如果已经裁剪过了,那就直接返回 return self.trimmed = True keep_words = [] keep_num = 0 for word, count in self.word2count.items(): if count >= min_count: keep_num += 1 # 由于后面是通过对keep_word列表中的数据逐一统计,所以需要对count>1的单词重复填入 for _ in range(count): keep_words.append(word) print("keep words: {} / {} = {:.4f}".format( keep_num, self.num_words - 4, keep_num / (self.num_words - 4) )) # 重构词表 self.word2index = {"PAD" : self.pad_token, "SOS" : self.sos_token, "EOS" : self.eos_token, "UNK" : self.unk_token} self.word2count = {} self.index2word = {self.pad_token : "PAD", self.sos_token : "SOS", self.eos_token : "EOS", self.unk_token : "UNK"} self.num_words = 4 for word in keep_words: self.addWord(word) # 读入数据,统计词频,并返回数据 def load_data(self, path): pairs = [] for line in open(path, "r", encoding="utf-8"): try: input_dialog, output_dialog = line.strip().split("\t") self.addSentence(input_dialog.strip()) self.addSentence(output_dialog.strip()) pairs.append([input_dialog, output_dialog]) except: pass return pairs
这个词表类,需要五个参数初始化:name、pad_token、sos_token、eos_token、unk_token。分别为词表的名称、填充词的index、句子开头标识符的index、句子结束标识符的index和未识别单词的index。
主要方法说明如下:
- __init__:完成词表的初始化。
- trim:根据min_count对词表进行剪枝。
- load_data:载入外部tsv数据,完成三个字典的搭建,并返回处理好的pairs。
处理input_dialog和output_dialog
有了词表,我们就可以根据词表把一句话转换成index序列,为此我们通过sentenceToIndex函数完成sentence到index sequence的转换,需要说明的是,为了让后续搭建的网络知道一句话已经结束了,我们需要给每个转换成的index序列的句子添加一个eos_token作为后缀:
# 将一句话转换成id序列(str->list),结尾加上EOS def sentenceToIndex(sentence, voc): return [voc.word2index[word] for word in sentence.split()] + [voc.eos_token]
接下来我们需要分别处理input_dialog和output_dialog。
处理input_dialog需要一个batchInput2paddedTensor函数,这个函数接受batch_size句没有处理过的input_dialog文字、将它们转换为index序列、填充pad_token、转换成batch_first=True的torch张量,返回处理好的torch张量和每句话的长度信息。
大致过程还是画张图吧。。。
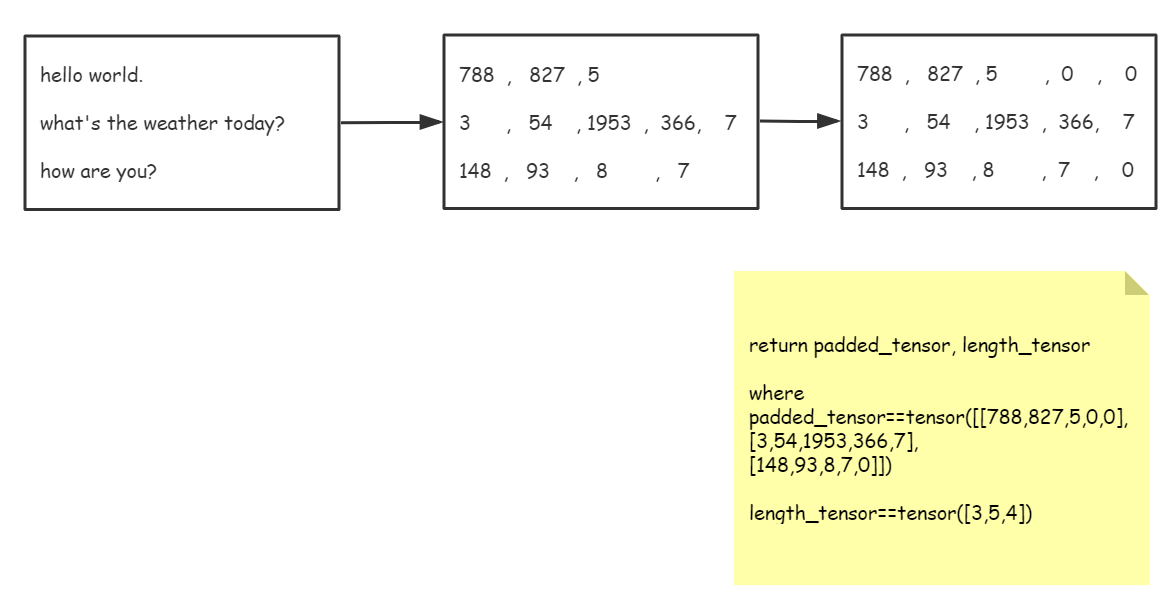
代码如下:
# 将一个batch中的input_dialog转化为有pad填充的tensor,并返回tensor和记录长度的变量 # 返回的tensor是batch_first的 def batchInput2paddedTensor(batch, voc): # 先转换为id序列,但是这个id序列不对齐 batch_index_seqs = [sentenceToIndex(sentence, voc) for sentence in batch] length_tensor = torch.tensor([len(index_seq) for index_seq in batch_index_seqs]) # 下面填充0(PAD),使得这个batch中的序列对齐 zipped_list = list(zip_longest(*batch_index_seqs, fillvalue=voc.pad_token)) padded_tensor = torch.tensor(zipped_list).t() return padded_tensor, length_tensor
处理output_dialog与input_dialog差不多,只不过需要多返回一个mask矩阵,所谓mask矩阵,就是将padded_tensor转换成bool类型。这些返回的量在后续的训练中都会使用到。output_dialog的处理如下:
# 将一个batch中的output_dialog转化为有pad填充的tensor,并返回tensor、mask和最大句长 # 返回的tensor是batch_first的 def batchOutput2paddedTensor(batch, voc): # 先转换为id序列,但是这个id序列不对齐 batch_index_seqs = [sentenceToIndex(sentence, voc) for sentence in batch] max_length = max([len(index_seq) for index_seq in batch_index_seqs]) # 下面填充0(PAD),使得这个batch中的序列对齐 zipped_list = list(zip_longest(*batch_index_seqs, fillvalue=voc.pad_token)) padded_tensor = torch.tensor(zipped_list).t() # 得到padded_tensor对应的mask mask = torch.BoolTensor(zipped_list).t() return padded_tensor, mask, max_length
有了处理pair的函数,我们可以把上面的函数整合成一个数据加载器loader。数据加载器在深度学习中很重要,我们在训练中需要能够不重复的、快速地获取一个batch的格式化数据,这就是loader的功能,惬意舒适(in my dream...)的训练中,一个设计合理而高效的loader是必不可少的。
此处不再解释Python中生成器的概念,为了更加节省内存空间,我们将loader做成一个生成器:
# 获取数据加载器的函数 # 将输入的一个batch的dialog转换成id序列,填充pad,并返回训练可用的id张量和mask def DataLoader(pairs, voc, batch_size, shuffle=True): if shuffle: random.shuffle(pairs) batch = [] for idx, pair in enumerate(pairs): batch.append([pair[0], pair[1]]) # 数据数量到达batch_size就yield出去并清空 if len(batch) == batch_size: # 为了后续的pack_padded_sequence操作,我们需要给这个batch中的数据按照input_dialog的长度排序(降序) batch.sort(key=lambda x : len(x[0].split()), reverse=True) input_dialog_batch = [] output_dialog_batch = [] for pair in batch: input_dialog_batch.append(pair[0]) output_dialog_batch.append(pair[1]) input_tensor, input_length_tensor = batchInput2paddedTensor(input_dialog_batch, voc) output_tensor, mask, max_length = batchOutput2paddedTensor(output_dialog_batch, voc) # 清空临时缓冲区 batch = [] yield [ input_tensor, input_length_tensor, output_tensor, mask, max_length ]
要写的函数差不多写好了,我们可以测试一下:
if __name__ == "__main__": PAD_token = 0 # 补足句长的pad占位符的index SOS_token = 1 # 代表一句话开头的占位符的index EOS_token = 2 # 代表一句话结尾的占位符的index UNK_token = 3 # 代表不在词典中的字符 BATCH_SIZE = 64 # 一个batch中的对话数量(样本数量) MAX_LENGTH = 20 # 一个对话中每句话的最大句长 MIN_COUNT = 3 # trim方法的修剪阈值 # 实例化词表 voc = vocab(name="corpus", pad_token=PAD_token, sos_token=SOS_token, eos_token=EOS_token, unk_token=UNK_token) # 为词表载入数据,统计词频,并得到对话数据 pairs = voc.load_data(path="./data/dialog.tsv") print("total number of dialogs:", len(pairs)) # 修剪与替换 pairs = trimAndReplace(voc, pairs, MIN_COUNT) # 获取loader loader = DataLoader(pairs, voc, batch_size=5) batch_item_names = ["input_tensor", "input_length_tensor", "output_tensor", "mask", "max_length"] for batch_index, batch in enumerate(loader): for name, item in zip(batch_item_names, batch): print(f"\n{name} : {item}") break
out:
total number of dialogs: 64223 keep words: 7821 / 17999 = 0.4345 Trimmed from 64223 pairs to 58362, 0.9087 of total input_tensor : tensor([[ 123, 51, 48, 8, 918, 2227, 330, 3068, 7, 2], [ 302, 303, 102, 38, 3, 71, 3, 7, 2, 0], [ 158, 3, 7, 2, 0, 0, 0, 0, 0, 0], [ 188, 7, 2, 0, 0, 0, 0, 0, 0, 0], [ 563, 5, 2, 0, 0, 0, 0, 0, 0, 0]]) input_length_tensor : tensor([10, 9, 4, 3, 3]) output_tensor : tensor([[3244, 5, 2, 0, 0, 0, 0, 0, 0, 0], [ 35, 37, 38, 68, 77, 5, 2, 0, 0, 0], [ 181, 5, 1233, 13, 1233, 13, 1222, 5, 2, 0], [ 102, 38, 45, 188, 99, 680, 1375, 5, 2, 0], [ 26, 198, 118, 25, 51, 41, 48, 1597, 5, 2]]) mask : tensor([[ True, True, True, False, False, False, False, False, False, False], [ True, True, True, True, True, True, True, False, False, False], [ True, True, True, True, True, True, True, True, True, False], [ True, True, True, True, True, True, True, True, True, False], [ True, True, True, True, True, True, True, True, True, True]]) max_length : 10
做好了数据加载器,后面就可以开始构建网络结构了。
三、定义seq2seq网络前向逻辑
前一节我们完成了词表和数据加载器的构建,接下来便是构建chatbot的核心了。本节我们完成neural_network.py的编写,这个文件中承载了网络主体的定义和前馈逻辑。
Tutorial中使用了Luong attention机制的seq2seq作为网络主体,Luong attention机制在原论文中讲得很清楚了,不熟悉的同学可以去看看,论文链接如下:
https://arxiv.org/abs/1508.04025
网络结构我也画了画了:
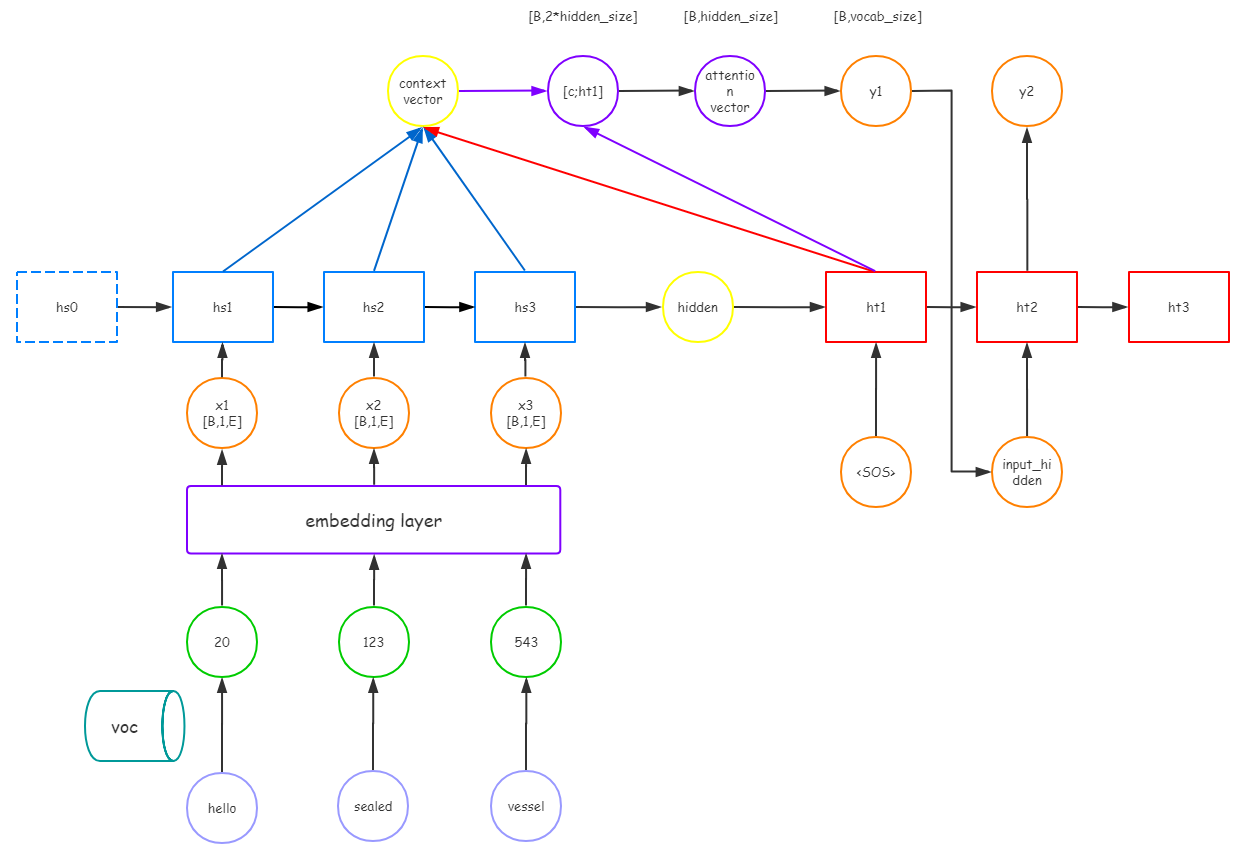
构建encoder
对于这个网络来说,encoder的部分没什么特殊的,让我们输入的时序信息通过RNN就行。这里我们使用双向RNN,每个cell都是GRU作为特征提取算子。我们把encoder写成一个EncoderRNN类:
# neural_network.py import torch import torch.nn as nn # 前馈的encoder class EncoderRNN(nn.Module): def __init__(self, hidden_size, embedding, n_layers=1,dropout=0): """ :param hidden_size: RNN隐藏层的维度,同时也是词向量的维度 :param embedding: 外部的词向量嵌入矩阵 :param n_layers: 单个RNNcell的层数 :param dropout: 单个RNN过程隐层参数被丢弃的概率,如果n_layer==1,那么这个参数设为0 """ super(EncoderRNN, self).__init__() self.n_layer = n_layers self.hidden_size = hidden_size self.embedding = embedding # 此处词向量维度(嵌入维度)和RNN隐藏层维度都是hidden_size # 下面定义GRU算子,其中bidirectional=True代表我们的GRU会对序列双向计算 # 我们按照batch_first的数据输入维度来定义gru self.gru = nn.GRU(input_size=hidden_size, hidden_size=hidden_size, num_layers=n_layers, dropout=(0 if n_layers==1 else dropout), bidirectional=True, batch_first=True) # 定义前向逻辑 def forward(self, input_seq, input_length, hidden=None): """ :param input_seq: 一个batch的index序列 :param input_length: 对应每个index序列长度的tensor :param hidden: 三阶张量,代表RNN的第一个隐藏层(h0)的初值 :return: [output, hidden]. 其中output为RNN的所有输出ot,hidden为RNN最后一个隐藏层 """ # 首先将index序列转化为词向量组成的矩阵 embedded = self.embedding(input_seq) # embedded:[batch_size, max_length, embedding_dim], 此处embedding_dim==hidden_size # 为了避免让RNN迭代过程中计算PAD的词向量(它理应是全0向量)的那一行 # 使用pack_padded_sequence方法进行压缩; # 压缩会按照传入的句长信息,只保留句长之内的词向量 # 压缩会返回一个PackedSequence类,GRU算子可以迭代该数据类型 # GRU算子迭代完后返回的还是PackedSequence类,届时我们需要使用pad_packed_sequence,将PackedSequence类解压为tensor # 压缩 packed = nn.utils.rnn.pack_padded_sequence(input=embedded, lengths=input_length, batch_first=True) # 前向传播, 使用hidden初始化h_0 outputs, hidden = self.gru(packed, hidden) # 由于hidden的shape不受输入句长的影响,所以outputs还是PackedSequence类,但hidden已经自动转换成tensor类了 # 解压outputs, 返回解压后的tensor和原本的长度信息 outputs, _ = nn.utils.rnn.pad_packed_sequence(sequence=outputs, batch_first=True, padding_value=0) # outputs: [batch_size, max_length, 2 * hidden_size] # 将双向RNN的outputs按位加起来 outputs = outputs[:, :, : self.hidden_size] + outputs[:, :, self.hidden_size : ] # outputs: [batch_size, max_length, hidden_size] # hidden: [batch_size, 2, hidden_size] return outputs, hidden
其中在前向传播中,我们使用了pack_padded_sequence和pad_packed_sequence对输入的一个batch的index序列进行了压缩和解压,这两个算子的细节可以参考笔者曾经的拙笔:
PyTorch中的pack_padded_sequence和pad_packed_sequence_weixin_45576923的博客-CSDN博客blog.csdn.net
而且因为我们的网络是双向RNN,所以需要对最后输出的序列进行折半合并操作。还有就是我们所有的数据维度操作都是batch_first=True,而pytorch的算子貌似都是默认batch_first=False的,所以需要时刻记得添加batch_first=True的参数。
实现Luong attention
得到encoder的输出后(输出有两部分:原时序数据在max_length维度上的等长序列和RNN的最后一个隐层)。
下一步就是根据encoder的输出来进行数据生成了,具体过程是以encoder的最后一个隐层为decoder的隐层,sos_token作为decoder的第一个time_step,将decoder的输出通过Luong attention层得到decoder在输入sos_token后的第一个输出 。再将这个
作为新的time_step输入decoder中,再接受上次得到的decoder的隐层,再将decoder的输出通过Luong attention层得到第二个输出
,以此不断循环,知道输出长度达到了我们规定的长度MAX_LENGTH时,decoder停止工作。
因此,在搭建decoder前向传播逻辑前,我们需要先实现Luong attention层。
Luong attention层其实就是学习decoder层当前输出与encoder所有输出关联性的操作。为了度量decoder当前隐层 与encoder所有输出
的关联程度,我们需要一种度量映射
,论文中给出了三种score映射的构造方案:
接下来便是通过score计算每个需要分配的权重
,再由此计算decoder目前的文本向量(context vector)
,最后计算注意力向量(attention vector)
。通过对
做维度变换就可以得到最终的输出
。
主要公式如下:

读者可以结合论文中的原图理解:
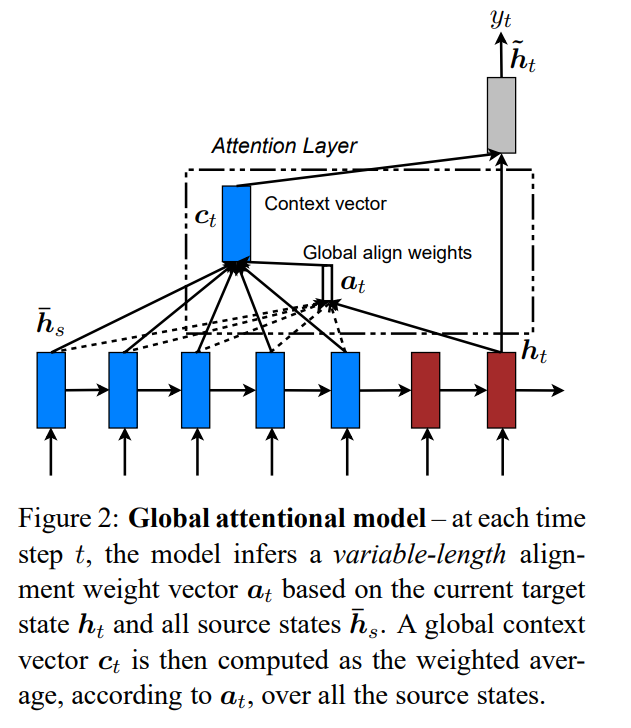 与公式对照,图中的global align weights a应该为α
与公式对照,图中的global align weights a应该为α
明晓了Luong attention的逻辑,我们通过LuongAttentionLayer类实现Luong attention层的映射逻辑,我们的LuongAttentionLayer的前向传播需要完成从 和所有
到注意力向量
的映射。
# Luong提出的全局注意力机制层 class LuongAttentionLayer(nn.Module): def __init__(self, score_name, hidden_size): """ :param score_name: score函数的类型 :param hidden_size: 隐层的维度 :return: """ # score函数是Luong论文中提出用来衡量decoder的目前的隐层和encoder所有输出的相关性 # 论文中不仅介绍了score函数的概念,而且给出了三种映射:dot,general,concat # 这三种score函数都是向量与向量到标量的映射 super(LuongAttentionLayer, self).__init__() self.score_name = score_name self.hidden_size = hidden_size if score_name not in ["dot", "general", "concat"]: raise ValueError(self.score_name, "is not an appropriate attention score_name(dot, general, concat)") # general有一个向量的外积变换, concat有一个外积变换与一个内积变换,所以这两个方法会产生额外的网络参数 # 下面为这两个方法设置需要的网络参数 if score_name == "general": self.Wa = nn.Linear(hidden_size, hidden_size) # 使用h->h的全连接层模拟h*h的矩阵与h维列向量的乘法 elif score_name == "concat": self.Wa = nn.Linear(hidden_size * 2, hidden_size) # 需要将h_t与h_s联级再做矩阵乘法,所以是2h->h的全连接层 self.v = nn.Parameter(torch.FloatTensor(hidden_size)) # FloatTensor会生成hidden_size维的全零(浮点0)向量,我们通过参数可更新的向量来模拟内积变换 # 计算attention vector的变换 self.Wc = nn.Linear(hidden_size * 2, hidden_size) # 需要将c_t与h_t联级再做矩阵乘法,所以是2h->h的全连接层 # 下面定义三个score: # 其中: current_hidden : [batch_size, 1, hidden_size] # encoder_output : [batch_size, max_length, hidden_size] def dot_score(self, current_hidden, encoder_ouput): return torch.sum(encoder_ouput * current_hidden, dim=2) def general_score(self, current_hidden, encoder_output): energy = self.Wa(encoder_output) # energy : [batch_size, max_length, hidden_size] return torch.sum(energy * current_hidden, dim=2) def concat_score(self, current_hidden, encoder_output): concat = torch.cat([current_hidden.expand(encoder_output.shape), encoder_output], dim=2) # concat : [batch, max_length, 2 * hidden_size] energy = self.Wa(concat).tanh() return torch.sum(self.v * energy, dim=2) # 前馈运算为encoder的全体output与decoder的current output值到attention向量的映射 def forward(self, current_hidden, encoder_output): if self.score_name == "dot": score = self.dot_score(current_hidden, encoder_output) elif self.score_name == "general": score = self.general_score(current_hidden, encoder_output) elif self.score_name == "concat": score = self.concat_score(current_hidden, encoder_output) # score : [batch_size, max_length] # 通过 softmax将score转化成注意力权重alpha attention_weights = nn.functional.softmax(score, dim=1) # attention_weights : [batch_size, max_length] # 通过encoder_output与alpha的加权和得到context vector(上下文向量) # 通过广播运算完成 context_vector = torch.sum(encoder_output * attention_weights.unsqueeze(2), dim=1) # context_vector : [batch_size, hidden_size] # 有了上下文向量,就可以计算attention vector了 attention_vector = self.Wc(torch.cat([context_vector.unsqueeze(1), current_hidden], dim=2)).tanh() # attention_vector : [batch_size, 1, hidden_size] return attention_vector
构建decoder
网络的最后,我们构建decoder。不同于encoder,虽然也是RNN,但是decoder需要把Luong attention层嵌入其中,所以我们不能一股脑生成最终的数据,而是需要把decoder的RNN拆开来写,在拆开的每一步中使用上面定义的Luong attention层。因此总的计算图如下:
- 将index序列通过embedding层,将每个位置上的index映射成词向量。
- 将词向量放入encoder中前向传播得到encoder_output和encoder_hidden。
- 将encoder_hidden作为decoder的隐层初值,sos_token作为decoder的初始输入,经过RNN得到current_output和current_hidden。
- 由current_output和encoder_output经过Luong attention层得到attention_vector。
- 将attention_vector通过全连接层映射到以词表长度为维度的向量,并进行softmax得到每一位置的概率,选取最大概率的index得到预测单词
。
- 将
- 若输出长度等于MAX_LENGTH,结束循环。
由此,我们将上述过程(不预测 )写到decoder的前馈逻辑中:
# decoder class LuongAttentionDecoderRNN(nn.Module): def __init__(self, score_name, embedding, hidden_size, output_size, n_layers=1, dropout=0): """ :param score_name: Luong Attention Layer 的score函数的类型,可选:dot, general, concat :param embedding: 词向量嵌入矩阵 :param hidden_size: RNN隐层维度 :param output_size: 每一个cell的输出维度,一般会通过一个 hidden_size->output_size的映射把attention vector映射到output_size维向量 :param n_layers: 单个RNN cell的层数 :param dropout: 代表某层参数被丢弃的概率,在n_layers==1的情况下设为0 """ super(LuongAttentionDecoderRNN, self).__init__() self.score_name = score_name self.hidden_size = hidden_size self.output_size = output_size self.n_layers = n_layers self.dropout = dropout # 定义或获取前向传播需要的算子 self.embedding = embedding self.embedding_dropout = nn.Dropout(dropout) self.gru = nn.GRU(input_size=hidden_size, hidden_size=hidden_size, num_layers=n_layers, dropout=(0 if n_layers == 1 else dropout), batch_first=True) self.attention = LuongAttentionLayer(score_name, hidden_size) self.hidden2output = nn.Linear(hidden_size, output_size) # decoder的前向传播逻辑 # 需要注意的是,不同一般的RNN,由于我们的decoder输出需要做注意力运算 # 所以decoder的RNN需要拆开来算,也就是我们的forward一次只能算一个time_step,而不是一次性循环到底 def forward(self, input_single_seq, last_hidden, encoder_output): """ :param input_single_seq: 上一步预测的单词对应的序列 [batch_size, 1] :param last_hidden: decoder上次RNN 的隐层 [batch_size, 2, hidden_size] :param encoder_output: encoder的全体输出 [batch_size, max_length, hidden_size] :return: 代表个位置概率的output向量[batch_size, output_size]和current hidden [batch_size, 2, hidden_size] """ embedded = self.embedding(input_single_seq) # [batch_size, max_length, hidden_size] embedded = self.embedding_dropout(embedded) # [batch_size, max_length, hidden_size] current_output, current_hidden = self.gru(embedded, last_hidden) # current_output : [batch_size, 1, hidden_size] # current_hidden : [1, batch_size, hidden_size] # 这里拿current_output当做current_hidden来参与attention运算 # 当然,直接拿current_hidden也行 attention_vector = self.attention(current_output, encoder_output) # attention_vector : [batch_size, 1, hidden_size] # 将attention_vector变到output_size维 output = self.hidden2output(attention_vector) # output : [batch_size, 1, output_size] output = nn.functional.softmax(output.squeeze(1), dim=1) # output : [batch_size, output_size] return output, current_hidden
最终,我们模拟一个输出来看看decoder的前馈是否成功:
if __name__ == "__main__": embedding = nn.Embedding(num_embeddings=10, embedding_dim=16) # encoder = EncoderRNN(hidden_size=16, embedding=embedding, n_layer=1, dropout=0) decoder = LuongAttentionDecoderRNN(score_name="dot", embedding=embedding, hidden_size=16, output_size=10, n_layers=1, dropout=0) x = torch.tensor([[2], [2]]) out = torch.arange(320).reshape([2, 10, 16]) length = torch.tensor([5, 3]) #outputs, hidden = encoder.forward(input_seq=x, input_length=length) output, current_hidden = decoder.forward(input_single_seq=x, last_hidden=None, encoder_output=out) print(f"output : {output}") print(f"current_hidden : {current_hidden}")
out:
output : tensor([[0.1832, 0.0861, 0.0588, 0.2255, 0.0403, 0.0393, 0.1062, 0.0719, 0.1100, 0.0786], [0.1832, 0.0861, 0.0588, 0.2255, 0.0403, 0.0393, 0.1062, 0.0719, 0.1100, 0.0786]], grad_fn=<SoftmaxBackward>) current_hidden : tensor([[[ 0.3959, 0.3439, -0.0588, -0.0933, 0.0965, -0.2926, -0.1794, -0.0680, 0.0837, -0.1553, -0.0835, 0.2807, 0.1596, -0.0033, -0.1039, -0.0772], [ 0.3959, 0.3439, -0.0588, -0.0933, 0.0965, -0.2926, -0.1794, -0.0680, 0.0837, -0.1553, -0.0835, 0.2807, 0.1596, -0.0033, -0.1039, -0.0772]]], grad_fn=<StackBackward>)
四、训练与评估
数据加载器有了,网络前馈逻辑也定义好了,接下来便是训练了,先将需要的库、超参、设备名称定义完:
# train.py import torch import random from time import time import os import math # 导入之前写好的函数或类 from process import vocab, trimAndReplace, DataLoader from neural_network import EncoderRNN, LuongAttentionDecoderRNN # 定义运算设备 USE_CUDA = torch.cuda.is_available() device = torch.device("cuda" if USE_CUDA else "cpu") # 常量 PAD_token = 0 # 补足句长的pad占位符的index SOS_token = 1 # 代表一句话开头的占位符的index EOS_token = 2 # 代表一句话结尾的占位符的index UNK_token = 3 # 代表不在词典中的字符 # 超参 BATCH_SIZE = 64 # 一个batch中的对话数量(样本数量) MAX_LENGTH = 20 # 一个对话中每句话的最大句长 MIN_COUNT = 3 # trim方法的修剪阈值 TEACHER_FORCING_RATIO = 1.0 # 实行teacher_force_ratio的概率 LEARNING_RATE = 0.0001 # 学习率 CLIP = 50.0 # 梯度裁剪阈值 # 网络参数 hidden_size = 512 # RNN隐层维度 encoder_n_layers = 2 # encoder的cell层数 decoder_n_layers = 2 # decoder的cell层数 dropout = 0.1 # 丢弃参数的概率 # 轮数与打印间隔 epoch_num = 15 # 迭代轮数 print_interval = 50 # 打印间隔 save_interval = 900 # 保存模型间隔
使用mask loss的方法避免计算pad的loss
在训练之前我们一般需要获取优化器和损失函数,这些PyTorch中都是定义好的,只不过这次的损失函数我们需要自己定义,因为我们一般是计算一个batch的loss,但是这个batch中的标签值中(标签值就是output_dialog),会存在一些pad_token,这些pad_token的无关字样不需要计算其损失,因此我们需要通过(一)中的mask矩阵来过滤损失,让我们只计算非pad_token位置上的似然值。
# 使用mask loss的方法避免计算pad的loss # 计算非pad对应位置的交叉熵(负对数似然) def maskNLLLoss(output, target, mask): """ :param output: decoder的所有output的拼接 [batch_size, max_length, output_size] :param target: 标签,也就是batch的output_dialog对应的id序列 [batch_size, max_length] :param mask: mask矩阵 与target同形 :return: 交叉熵损失、单词个数 """ target = target.type(torch.int64).to(device) mask = mask.type(torch.BoolTensor).to(device) total_word = mask.sum() # 单词个数 crossEntropy = -torch.log(torch.gather(output, dim=2, index=target.unsqueeze(2))) # crossEntropy : [batch_size, max_length, 1] loss = crossEntropy.squeeze(2).masked_select(mask).mean() loss = loss.to(device) return loss, total_word.item()
定义训练一个batch数据的函数
下面给出训练一个batch数据的函数,tutorial中在训练方面给出了两个tricks:梯度裁剪和teacher forcing。
梯度裁剪很好理解,为了防止梯度爆炸,我们可以给每个参数反向传播得到的梯度值设置一个阈值,高于这个阈值就全部设为这个阈值大小。
第二个技巧teacher forcing是加速收敛的一个技巧,在decoder迭代计算出预测index的过程中,如果第一个字就预测错了,那么作为错误的输入,后面预测的结果大概率也就是错的了,第一个字错误意整个序列错误,这样的情况很显然会让训练收敛很困难,所以我们可以让网络在训练过程中有一定概率进行teacher forcing:在网络预测网一个单词后,我们不以这个预测出的单词作为decoder的下一次输入,而是把这个位置上的标签值作为下一次输入。这么做相当于强制要求网络学会每一单词的输入。形象一点,也就是把网络往每个时序节点上拉扯(这是我对teacher forcing的理解,若有误,欢迎在评论区指出)
接下来便是训练一个batch数据的函数,这个函数根据输出的一个batch的数据,输出这个batch上非pad字符的平均损失。
# 定义训练一个batch的逻辑 # 在这个batch中更新网络时,有一定的概率会使用teacher forcing的方法来加速收敛, 这个概率为teacher_forcing_ratio def trainOneBatch(input_seq, input_length, target, mask, max_target_len, encoder, decoder, encoder_optimizer, decoder_optimizer, batch_size, clip, teacher_forcing_ratio, encoder_lr_scheduler=None, decoder_lr_scheduler=None): """ :param input_seq: 输入encoder的index序列 [batch_size, max_length] :param input_length: input_seq中每个序列的长度 [batch_size] :param target: 每个input_dialog对应的output_dialog的index序列 [batch_size, max_length] :param mask: target对应的mask矩阵 [batch_size, max_length] :param max_target_len: target中的最大句长 :param encoder: encoder实例 :param decoder: decoder实例 :param encoder_optimizer: 承载encoder参数的优化器 :param decoder_optimizer: 承载decoder参数的优化器 :param batch_size: batch大小 :param clip: 修剪梯度的阈值,超过该值的导数值会被裁剪 :param teacher_forcing_ratio: 训练该batch启动teacher force的策略 :param encoder_lr_scheduler: encoder_optimizer学习率调整策略 :param decoder_lr_scheduler: decoder_optimizer学习率调整策略 :return: 平均似然损失 """ # 清空优化器 encoder_optimizer.zero_grad() decoder_optimizer.zero_grad() # 设置变量的运算设备 input_seq = input_seq.to(device) input_length = input_length.to(device) target = target.to(device) mask = mask.to(device) decoder_output = torch.FloatTensor() # 用来保存decoder的所有输出 decoder_output = decoder_output.to(device) # encoder的前向计算 encoder_output, encoder_hidden = encoder(input_seq, input_length) # 为decoder的计算初始化一个开头SOS decoder_input = torch.tensor([SOS_token for _ in range(batch_size)]).reshape([-1, 1]) decoder_input = decoder_input.to(device) # 根据decoder的cell层数截取encoder的h_n的层数 decoder_hidden = encoder_hidden[:decoder.n_layers] # 根据概率决定是否使用teacher force use_teacher_forcing = True if random.random() < teacher_forcing_ratio else False if use_teacher_forcing: for i in range(max_target_len): # 执行一步decoder前馈,只计算了一个单词 output, current_hidden = decoder(decoder_input, decoder_hidden, encoder_output) # output : [batch_size, output_size] # current_hidden : [1, batch_size, hidden_size] # 将本次time_step得到的结果放入decoder_output中 decoder_output = torch.cat([decoder_output, output.unsqueeze(1)], dim=1) # 使用teacher forcing:使用target(真实的单词)作为decoder的下一次的输入,而不是我们计算出的预测值(计算出的概率最大的单词) decoder_input = target[:, i].reshape([-1, 1]) decoder_hidden = current_hidden else: for i in range(max_target_len): # 执行一步decoder前馈,只计算了一个单词 output, current_hidden = decoder(decoder_input, decoder_hidden, encoder_output) # output : [batch_size, output_size] # current_hidden : [1, batch_size, hidden_size] # 从softmax的结果中得到预测的index predict_index = torch.argmax(output, dim=1) # 将本次time_step得到的结果放入decoder_output中 decoder_output = torch.cat([decoder_output, output.unsqueeze(1)], dim=1) decoder_input = predict_index.reshape([-1, 1]) decoder_hidden = current_hidden # 计算本次batch中的mask_loss和总共的单词数 mask_loss, word_num = maskNLLLoss(output=decoder_output, target=target, mask=mask) # 开始反向传播,更新参数 mask_loss.backward() # 裁剪梯度 torch.nn.utils.clip_grad_norm_(encoder.parameters(), clip) torch.nn.utils.clip_grad_norm_(decoder.parameters(), clip) # 更新网络参数 encoder_optimizer.step() decoder_optimizer.step() # 调整优化器的学习率 if encoder_lr_scheduler and decoder_lr_scheduler: encoder_lr_scheduler.step() decoder_lr_scheduler.step() return mask_loss.item()
准备训练需要的数据加载器、网络和优化器
此处我们引入前两个文件process.py和neural_network.py中的类或方法,快速获取训练需要的数据加载器、网络。另外,我们需要通过PyTorch获取优化mask loss需要的优化器,此处就使用Adam优化器。
另外,我们可以定义动态调整学习率的策略。笔者实现并尝试了Leslie的Triangle2学习率衰减方法,但是效果并不佳(loss一直在4.0左右),于是我使用的是学习策略对象为None的方案。感兴趣的读者可以使用torch.optim.lr_scheduler下的方法尝试动态调整学习率。
print("build vocab_list...") # 首先构建字典 voc = vocab(name="corpus", pad_token=PAD_token, sos_token=SOS_token, eos_token=EOS_token, unk_token=UNK_token) # 载入数据 pairs = voc.load_data(path="./data/dialog.tsv") print(f"load {len(pairs)} dialogs successfully") # 对数据进行裁剪 pairs = trimAndReplace(voc=voc, pairs=pairs, min_count=MIN_COUNT) print(f"there are {voc.num_words} words in the vocab") # 定义词向量嵌入矩阵 embedding = torch.nn.Embedding(num_embeddings=voc.num_words, embedding_dim=hidden_size, padding_idx=PAD_token) # 获取encoder和decoder encoder = EncoderRNN(hidden_size=hidden_size, embedding=embedding, n_layers=encoder_n_layers, dropout=dropout) decoder = LuongAttentionDecoderRNN(score_name="dot", embedding=embedding, hidden_size=hidden_size, output_size=voc.num_words, n_layers=decoder_n_layers, dropout=dropout) encoder = encoder.to(device) decoder = decoder.to(device) # 为encoder和decoder分别定义优化器 encoder_optimizer = torch.optim.Adam(encoder.parameters(), lr=LEARNING_RATE) decoder_optimizer = torch.optim.Adam(decoder.parameters(), lr=LEARNING_RATE) # Leslie的Triangle2学习率衰减方法 #def Triangular2(T_max, gamma): # def new_lr(step): # region = step // T_max + 1 # 所处分段 # increase_rate = 1 / T_max * math.pow(gamma, region - 2) # 增长率的绝对值 # return increase_rate * (step - (region - 1) * T_max) if step <= (region - 0.5) * T_max else - increase_rate * (step - region * T_max) # return new_lr # 定义优化器学习率的衰减策略 # encoder_lr_scheduler = torch.optim.lr_scheduler.LambdaLR(optimizer=encoder_optimizer, # # lr_lambda=Triangular2(T_max=300, gamma=0.5)) # # decoder_lr_scheduler = torch.optim.lr_scheduler.LambdaLR(optimizer=decoder_optimizer, # # lr_lambda=Triangular2(T_max=300, gamma=0.5)) encoder_lr_scheduler = None decoder_lr_scheduler = None global_step = 0 start_time = time() # 计时起点 # 将模型设为训练模式 encoder.train() decoder.train()
开始训练
接下来终于可以开始训练了,记得每隔save_interval步保存一下模型的相关信息(如果你使用了动态调整学习率的策略,那么记得把lr_scheduler对象也保存到checkpoint中)
# 轮数遍历 for epoch in range(epoch_num): print("-" * 20) print("Epoch : ",epoch) # 获取loader train_loader = DataLoader(pairs=pairs, voc=voc, batch_size=BATCH_SIZE, shuffle=True) # 遍历生成器 for batch_num, batch in enumerate(train_loader): global_step += 1 # batch中的信息 : ["input_tensor", "input_length_tensor", "output_tensor", "mask", "max_length"] loss = trainOneBatch(input_seq=batch[0], input_length=batch[1], target=batch[2], mask=batch[3], max_target_len=batch[4], encoder=encoder, decoder=decoder, encoder_optimizer=encoder_optimizer, decoder_optimizer=decoder_optimizer, batch_size=BATCH_SIZE, clip=CLIP, teacher_forcing_ratio=TEACHER_FORCING_RATIO, encoder_lr_scheduler=encoder_lr_scheduler, decoder_lr_scheduler=decoder_lr_scheduler) mask_loss_all.append(loss) if global_step % print_interval == 0: print("Epoch : {}\tbatch_num : {}\tloss: {:.6f}\ttime point : {:.2f}s\tmodel_lr : {:.10f}".format( epoch, batch_num, loss, time() - start_time, encoder_optimizer.param_groups[0]["lr"] )) # 将check_point存入./data/check_points这个文件夹中 if global_step % save_interval == 0: # 先判断目标路径是否存在,不存在则创建 if not os.path.exists("./data/checkpoints"): os.makedirs("./data/checkpoints") check_point_save_path = f"./data/checkpoints/{global_step}_checkpoint.tar" torch.save({ "iteration" : global_step, "encoder" : encoder.state_dict(), "decoder" : decoder.state_dict(), "encoder_optimizer" : encoder_optimizer.state_dict(), "decoder_optimizer" : decoder_optimizer.state_dict(), # "encoder_lr_scheduler" : encoder_lr_scheduler.state_dict(), # "decoder_lr_scheduler" : decoder_lr_scheduler.state_dict(), "loss" : loss, "voc_dict" : voc.__dict__, "embedding" : embedding.state_dict() }, check_point_save_path) print(f"save model to {check_point_save_path}")
out:
build vocab_list... load 64223 dialogs successfully keep words: 7821 / 17999 = 0.4345 Trimmed from 64223 pairs to 58362, 0.9087 of total there are 7825 words in the vocab start to train... -------------------- Epoch : 0 Epoch : 0 batch_num : 49 loss: 5.211146 time point : 10.65s model_lr : 0.0001000000 Epoch : 0 batch_num : 99 loss: 4.775126 time point : 21.10s model_lr : 0.0001000000 Epoch : 0 batch_num : 149 loss: 4.713544 time point : 31.61s model_lr : 0.0001000000 Epoch : 0 batch_num : 199 loss: 4.480552 time point : 42.09s model_lr : 0.0001000000 Epoch : 0 batch_num : 249 loss: 4.603276 time point : 52.54s model_lr : 0.0001000000 Epoch : 0 batch_num : 299 loss: 4.419000 time point : 62.96s model_lr : 0.0001000000 Epoch : 0 batch_num : 349 loss: 4.409772 time point : 73.43s model_lr : 0.0001000000 Epoch : 0 batch_num : 399 loss: 4.426375 time point : 83.89s model_lr : 0.0001000000 Epoch : 0 batch_num : 449 loss: 4.090558 time point : 94.34s model_lr : 0.0001000000 Epoch : 0 batch_num : 499 loss: 4.207512 time point : 104.78s model_lr : 0.0001000000 Epoch : 0 batch_num : 549 loss: 4.104476 time point : 115.22s model_lr : 0.0001000000 Epoch : 0 batch_num : 599 loss: 4.093010 time point : 125.68s model_lr : 0.0001000000 Epoch : 0 batch_num : 649 loss: 3.939747 time point : 135.98s model_lr : 0.0001000000 Epoch : 0 batch_num : 699 loss: 4.007159 time point : 146.42s model_lr : 0.0001000000 Epoch : 0 batch_num : 749 loss: 3.918721 time point : 156.88s model_lr : 0.0001000000 Epoch : 0 batch_num : 799 loss: 3.948490 time point : 167.28s model_lr : 0.0001000000 Epoch : 0 batch_num : 849 loss: 4.215139 time point : 177.68s model_lr : 0.0001000000 Epoch : 0 batch_num : 899 loss: 4.044553 time point : 188.08s model_lr : 0.0001000000 save model to ./data/checkpoints/900_checkpoint.tar -------------------- Epoch : 1 Epoch : 1 batch_num : 38 loss: 3.819281 time point : 199.19s model_lr : 0.0001000000 Epoch : 1 batch_num : 88 loss: 4.114137 time point : 209.73s model_lr : 0.0001000000 Epoch : 1 batch_num : 138 loss: 3.546693 time point : 220.16s model_lr : 0.0001000000 Epoch : 1 batch_num : 188 loss: 3.866693 time point : 230.52s model_lr : 0.0001000000 Epoch : 1 batch_num : 238 loss: 3.826230 time point : 240.87s model_lr : 0.0001000000 Epoch : 1 batch_num : 288 loss: 4.061031 time point : 251.24s model_lr : 0.0001000000 Epoch : 1 batch_num : 338 loss: 3.750829 time point : 261.62s model_lr : 0.0001000000 Epoch : 1 batch_num : 388 loss: 3.919177 time point : 272.16s model_lr : 0.0001000000 Epoch : 1 batch_num : 438 loss: 3.918060 time point : 282.56s model_lr : 0.0001000000 Epoch : 1 batch_num : 488 loss: 3.705923 time point : 293.11s model_lr : 0.0001000000 Epoch : 1 batch_num : 538 loss: 3.571774 time point : 303.80s model_lr : 0.0001000000 Epoch : 1 batch_num : 588 loss: 3.728690 time point : 314.50s model_lr : 0.0001000000 Epoch : 1 batch_num : 638 loss: 3.723015 time point : 325.40s model_lr : 0.0001000000 Epoch : 1 batch_num : 688 loss: 3.831923 time point : 335.93s model_lr : 0.0001000000 Epoch : 1 batch_num : 738 loss: 3.705489 time point : 346.55s model_lr : 0.0001000000 Epoch : 1 batch_num : 788 loss: 3.703197 time point : 356.87s model_lr : 0.0001000000 Epoch : 1 batch_num : 838 loss: 3.628496 time point : 367.27s model_lr : 0.0001000000 Epoch : 1 batch_num : 888 loss: 3.647458 time point : 377.59s model_lr : 0.0001000000 save model to ./data/checkpoints/1800_checkpoint.tar -------------------- Epoch : 2 Epoch : 2 batch_num : 27 loss: 3.962345 time point : 388.80s model_lr : 0.0001000000 Epoch : 2 batch_num : 77 loss: 3.592104 time point : 399.08s model_lr : 0.0001000000 Epoch : 2 batch_num : 127 loss: 3.567289 time point : 409.37s model_lr : 0.0001000000 Epoch : 2 batch_num : 177 loss: 4.042858 time point : 419.61s model_lr : 0.0001000000 Epoch : 2 batch_num : 227 loss: 3.427825 time point : 429.84s model_lr : 0.0001000000 Epoch : 2 batch_num : 277 loss: 3.950862 time point : 440.08s model_lr : 0.0001000000 Epoch : 2 batch_num : 327 loss: 3.757668 time point : 450.31s model_lr : 0.0001000000 Epoch : 2 batch_num : 377 loss: 3.467505 time point : 460.55s model_lr : 0.0001000000 Epoch : 2 batch_num : 427 loss: 3.440686 time point : 470.79s model_lr : 0.0001000000 Epoch : 2 batch_num : 477 loss: 3.590461 time point : 481.01s model_lr : 0.0001000000 Epoch : 2 batch_num : 527 loss: 3.361732 time point : 491.24s model_lr : 0.0001000000 Epoch : 2 batch_num : 577 loss: 3.371861 time point : 501.48s model_lr : 0.0001000000 Epoch : 2 batch_num : 627 loss: 3.704220 time point : 511.70s model_lr : 0.0001000000 Epoch : 2 batch_num : 677 loss: 3.535992 time point : 521.92s model_lr : 0.0001000000 Epoch : 2 batch_num : 727 loss: 3.626462 time point : 532.16s model_lr : 0.0001000000 Epoch : 2 batch_num : 777 loss: 3.580423 time point : 542.41s model_lr : 0.0001000000 ...... Epoch : 14 batch_num : 245 loss: 2.503512 time point : 2703.19s model_lr : 0.0001000000 Epoch : 14 batch_num : 295 loss: 2.464522 time point : 2713.41s model_lr : 0.0001000000 Epoch : 14 batch_num : 345 loss: 2.393009 time point : 2723.63s model_lr : 0.0001000000 Epoch : 14 batch_num : 395 loss: 2.496835 time point : 2733.85s model_lr : 0.0001000000 Epoch : 14 batch_num : 445 loss: 2.641428 time point : 2744.07s model_lr : 0.0001000000 Epoch : 14 batch_num : 495 loss: 2.519416 time point : 2754.30s model_lr : 0.0001000000 Epoch : 14 batch_num : 545 loss: 2.622985 time point : 2764.49s model_lr : 0.0001000000 Epoch : 14 batch_num : 595 loss: 2.490081 time point : 2774.92s model_lr : 0.0001000000 Epoch : 14 batch_num : 645 loss: 2.908693 time point : 2785.12s model_lr : 0.0001000000 Epoch : 14 batch_num : 695 loss: 2.483515 time point : 2795.32s model_lr : 0.0001000000 Epoch : 14 batch_num : 745 loss: 2.687601 time point : 2805.53s model_lr : 0.0001000000 save model to ./data/checkpoints/13500_checkpoint.tar Epoch : 14 batch_num : 795 loss: 2.547039 time point : 2816.44s model_lr : 0.0001000000 Epoch : 14 batch_num : 845 loss: 2.410642 time point : 2826.59s model_lr : 0.0001000000 Epoch : 14 batch_num : 895 loss: 2.648225 time point : 2836.83s model_lr : 0.0001000000
评估模型
模型训练完后就是评估模型了。最后,我们完成evaluate.py文件,这个文件中含有最终评估模型的程序,当然,evaluate.py已经具有玩耍的功能。
网络由input_dialog到output_dialog的映射我们可以再写成一个类,这个类的前馈逻辑和decoder的没什么两样的(贪心选取预测出的index),只不过我们取消了teacher forcing(也没有标签值来做teacher foring呀=_=)
import torch import torch.nn as nn from neural_network import EncoderRNN, LuongAttentionDecoderRNN # 根据encoder和decoder预测的网络 class GreedySearchDecoder(nn.Module): def __init__(self, encoder, decoder): super(GreedySearchDecoder, self).__init__() self.encoder = encoder self.decoder = decoder # 整个模型的前向逻辑 def forward(self, input_seq, input_length, output_length, sos_token=1): """ :param input_seq: index序列 [1, max_length] :param input_length: 长度 :param output_length: chatbot回复的句长 :param sos_token: SOS占位符的index :return: """ # 先在encoder中前向传播 encoder_output, encoder_hidden = self.encoder(input_seq, input_length) # 根据decoder的cell层数截取encoder_hidden作为decoder起始hidden decoder_hidden = encoder_hidden[:self.decoder.n_layers] # decoder最开始的input是一个SOS decoder_input = torch.tensor([[sos_token]]) # 用来存储decoder得到的每个单词和这个单词的置信度 predict_word_index = [] predict_confidence = [] for _ in range(output_length): # 经过decoder的前向计算 decoder_output, current_hidden = self.decoder(decoder_input, decoder_hidden, encoder_output) max_possibility, index = torch.max(decoder_output, dim=1) predict_word_index.append(index.item()) predict_confidence.append(max_possibility.item()) # 传递下一次迭代的初值 decoder_input = index.unsqueeze(0) decoder_hidden = current_hidden return predict_word_index, predict_confidence
接下来,我们需要载入训练好的模型,为了载入训练模型的state_dict,我们需要先把网络的实例化,然后使用load_state_dict方法载入模型参数。
# 载入模型和字典 load_path = "./data/checkpoints/13500_checkpoint.tar" # 模型有可能是在gpu上训练的,需要先把模型参数转换成cpu可以运算的类型 checkpoint = torch.load(load_path, map_location=torch.device("cpu")) encoder_state_dict = checkpoint["encoder"] decoder_state_dict = checkpoint["decoder"] embedding_state_dict = checkpoint["embedding"] voc_dict = checkpoint["voc_dict"] # 网络参数 hidden_size = 512 # RNN隐层维度 encoder_n_layers = 2 # encoder的cell层数 decoder_n_layers = 2 # decoder的cell层数 dropout = 0.1 # 丢弃参数的概率 # 初始化,词向量矩阵、encoder、decoder并载入参数 embedding = torch.nn.Embedding(num_embeddings=voc_dict["num_words"], embedding_dim=hidden_size, padding_idx=voc_dict["pad_token"]) embedding.load_state_dict(embedding_state_dict) encoder = EncoderRNN(hidden_size=hidden_size, embedding=embedding, n_layers=encoder_n_layers, dropout=dropout) decoder = LuongAttentionDecoderRNN(score_name="dot", embedding=embedding, hidden_size=hidden_size, output_size=voc_dict["num_words"], n_layers=decoder_n_layers, dropout=dropout) encoder.load_state_dict(encoder_state_dict) decoder.load_state_dict(decoder_state_dict) # 设为评估模式,网络参数停止更新 encoder.eval() decoder.eval()
最后我们只需要写个死循环来不断获取用户输入,然后让chatbot做出回应就行了。当然,我们还需要对用户的输入、chatbot的输出做些处理,比如,我们需要将用户的输入都改成小写字母,并将不再词表中的词用UNK替代;对于chatbot,我们要将所有的eos_token和pad_token都去除。最终的代码如下:
# 实例化最终评估模型的实例 chatbot = GreedySearchDecoder(encoder, decoder) MAX_LENGTH = 20 # 回复的最大句长 # 进入主循环 while True: user_dialog = input("User:").lower() if user_dialog == "q" or user_dialog == "quit": break # word转index, 并将不在词表中的单词替换成unk_token input_seq = [voc_dict["word2index"].get(word, voc_dict["unk_token"]) for word in user_dialog.split()] input_length = torch.tensor([len(input_seq)]) input_seq = torch.tensor(input_seq).unsqueeze(0) # 将index序列输入chatbot,获取回复index序列 predict_indexes, predict_confidence = chatbot(input_seq, input_length, MAX_LENGTH) # 将chatbot回复的index序列转为word,并将代表pad_token和eos_token的index去除 chatbot_words = [] for index in predict_indexes: if index in [voc_dict["pad_token"], voc_dict["eos_token"]]: continue else: chatbot_words.append(voc_dict["index2word"][index]) print(f"chatbot: {' '.join(chatbot_words)}") # 将除去pad_token和eos_token的占位符后剩下的字符对应的置信度,保留3位小数输出 print("chatbot's confidence: {}".format( list(map(lambda x : str(round(x * 100, 1)) + "%" , predict_confidence[:len(chatbot_words)])) ))
out:
User:do you like cs? chatbot: yes . . . . . chatbot's confidence: ['20.3%', '96.4%', '96.2%', '40.7%', '96.5%', '57.7%'] User:Am I a rookie king ? chatbot: sure . . . . . . . . . . chatbot's confidence: ['5.0%', '97.7%', '80.9%', '3.0%', '82.8%', '14.5%', '90.2%', '41.6%', '98.3%', '75.4%', '99.5%'] User:bye chatbot: i m sorry . day . chatbot's confidence: ['13.8%', '33.7%', '18.5%', '74.4%', '94.4%', '10.0%'] User:q
chatbot会输出回答的句子和每一个单词的置信度,由于模型训练尚浅,所以大多数置信度不高
确实,它不是个成熟的chatbot,还没学会怎么夸它的创造者=_=
好了,这大概就是基于seq2seq的chatbot的全部了。其实就是一个翻译机啦,缺点很明显,它不会根据上下文做出回答,所以只要输入的文字序列是不变的,它就会像一个复读机一样一直说同样的话,直到user愤怒的按下q为止。。
五、详细代码
1、draft.py
import numpy as np import matplotlib.pyplot as plt import math # Leslie的Triangle2学习率衰减方法 def Triangular2(T_max, gamma): def new_lr(step): region = step // T_max + 1 # 所处分段 increase_rate = 1 / T_max * math.pow(gamma, region - 2) # 增长率的绝对值 return increase_rate * (step - (region - 1) * T_max) if step <= (region - 0.5) * T_max else - increase_rate * (step - region * T_max) return new_lr # Loshchilov&Hutter 提出的warm_start def WarmStart(T_max): def new_lr(step): return math.cos((step % T_max) * math.pi / T_max) + 1 return new_lr # 获取映射 Lambda_lr = WarmStart(T_max=100) x = np.linspace(1, 600, 1000) y = np.array([Lambda_lr(num) for num in x]) plt.plot(x, y) plt.show()
2、evaluate.py
import torch import torch.nn as nn from neural_network import EncoderRNN, LuongAttentionDecoderRNN # 根据encoder和decoder预测的网络 class GreedySearchDecoder(nn.Module): def __init__(self, encoder, decoder): super(GreedySearchDecoder, self).__init__() self.encoder = encoder self.decoder = decoder # 整个模型的前向逻辑 def forward(self, input_seq, input_length, output_length, sos_token=1): """ :param input_seq: index序列 [1, max_length] :param input_length: 长度 :param output_length: chatbot回复的句长 :param sos_token: SOS占位符的index :return: """ # 先在encoder中前向传播 encoder_output, encoder_hidden = self.encoder(input_seq, input_length) # 根据decoder的cell层数截取encoder_hidden作为decoder起始hidden decoder_hidden = encoder_hidden[:self.decoder.n_layers] # decoder最开始的input是一个SOS decoder_input = torch.tensor([[sos_token]]) # 用来存储decoder得到的每个单词和这个单词的置信度 predict_word_index = [] predict_confidence = [] for _ in range(output_length): # 经过decoder的前向计算 decoder_output, current_hidden = self.decoder(decoder_input, decoder_hidden, encoder_output) max_possibility, index = torch.max(decoder_output, dim=1) predict_word_index.append(index.item()) predict_confidence.append(max_possibility.item()) # 传递下一次迭代的初值 decoder_input = index.unsqueeze(0) decoder_hidden = current_hidden return predict_word_index, predict_confidence # 载入模型和字典 load_path = "./data/checkpoints/13500_checkpoint.tar" # 模型有可能是在gpu上训练的,需要先把模型参数转换成cpu可以运算的类型 checkpoint = torch.load(load_path, map_location=torch.device("cpu")) encoder_state_dict = checkpoint["encoder"] decoder_state_dict = checkpoint["decoder"] embedding_state_dict = checkpoint["embedding"] voc_dict = checkpoint["voc_dict"] # 网络参数 hidden_size = 512 # RNN隐层维度 encoder_n_layers = 2 # encoder的cell层数 decoder_n_layers = 2 # decoder的cell层数 dropout = 0.1 # 丢弃参数的概率 # 初始化,词向量矩阵、encoder、decoder并载入参数 embedding = torch.nn.Embedding(num_embeddings=voc_dict["num_words"], embedding_dim=hidden_size, padding_idx=voc_dict["pad_token"]) embedding.load_state_dict(embedding_state_dict) encoder = EncoderRNN(hidden_size=hidden_size, embedding=embedding, n_layers=encoder_n_layers, dropout=dropout) decoder = LuongAttentionDecoderRNN(score_name="dot", embedding=embedding, hidden_size=hidden_size, output_size=voc_dict["num_words"], n_layers=decoder_n_layers, dropout=dropout) encoder.load_state_dict(encoder_state_dict) decoder.load_state_dict(decoder_state_dict) # 设为评估模式,网络参数停止更新 encoder.eval() decoder.eval() # 实例化最终评估模型的实例 chatbot = GreedySearchDecoder(encoder, decoder) MAX_LENGTH = 20 # 回复的最大句长 # 进入主循环 while True: user_dialog = input("User:").lower() if user_dialog == "q" or user_dialog == "quit": break # word转index, 并将不在词表中的单词替换成unk_token input_seq = [voc_dict["word2index"].get(word, voc_dict["unk_token"]) for word in user_dialog.split()] input_length = torch.tensor([len(input_seq)]) input_seq = torch.tensor(input_seq).unsqueeze(0) # 将index序列输入chatbot,获取回复index序列 predict_indexes, predict_confidence = chatbot(input_seq, input_length, MAX_LENGTH) # 将chatbot回复的index序列转为word,并将代表pad_token和eos_token的index去除 chatbot_words = [] for index in predict_indexes: if index in [voc_dict["pad_token"], voc_dict["eos_token"]]: continue else: chatbot_words.append(voc_dict["index2word"][index]) print(f"chatbot: {' '.join(chatbot_words)}") # 将除去pad_token和eos_token的占位符后剩下的字符对应的置信度,保留3位小数输出 print("chatbot's confidence: {}".format( list(map(lambda x : str(round(x * 100, 1)) + "%" , predict_confidence[:len(chatbot_words)])) ))
3、natural_natwork.py
# neural_network.py import torch import torch.nn as nn # 前馈的encoder class EncoderRNN(nn.Module): def __init__(self, hidden_size, embedding, n_layers=1,dropout=0): """ :param hidden_size: RNN隐藏层的维度,同时也是词向量的维度 :param embedding: 外部的词向量嵌入矩阵 :param n_layers: 单个RNNcell的层数 :param dropout: 单个RNN过程隐层参数被丢弃的概率,如果n_layer==1,那么这个参数设为0 """ super(EncoderRNN, self).__init__() self.n_layer = n_layers self.hidden_size = hidden_size self.embedding = embedding # 此处词向量维度(嵌入维度)和RNN隐藏层维度都是hidden_size # 下面定义GRU算子,其中bidirectional=True代表我们的GRU会对序列双向计算 # 我们按照batch_first的数据输入维度来定义gru self.gru = nn.GRU(input_size=hidden_size, hidden_size=hidden_size, num_layers=n_layers, dropout=(0 if n_layers==1 else dropout), bidirectional=True, batch_first=True) # 定义前向逻辑 def forward(self, input_seq, input_length, hidden=None): """ :param input_seq: 一个batch的index序列 :param input_length: 对应每个index序列长度的tensor :param hidden: 三阶张量,代表RNN的第一个隐藏层(h0)的初值 :return: [output, hidden]. 其中output为RNN的所有输出ot,hidden为RNN最后一个隐藏层 """ # 首先将index序列转化为词向量组成的矩阵 embedded = self.embedding(input_seq) # embedded:[batch_size, max_length, embedding_dim], 此处embedding_dim==hidden_size # 为了避免让RNN迭代过程中计算PAD的词向量(它理应是全0向量)的那一行 # 使用pack_padded_sequence方法进行压缩; # 压缩会按照传入的句长信息,只保留句长之内的词向量 # 压缩会返回一个PackedSequence类,GRU算子可以迭代该数据类型 # GRU算子迭代完后返回的还是PackedSequence类,届时我们需要使用pad_packed_sequence,将PackedSequence类解压为tensor # 压缩 packed = nn.utils.rnn.pack_padded_sequence(input=embedded, lengths=input_length, batch_first=True) # 前向传播, 使用hidden初始化h_0 outputs, hidden = self.gru(packed, hidden) # 由于hidden的shape不受输入句长的影响,所以outputs还是PackedSequence类,但hidden已经自动转换成tensor类了 # 解压outputs, 返回解压后的tensor和原本的长度信息 outputs, _ = nn.utils.rnn.pad_packed_sequence(sequence=outputs, batch_first=True, padding_value=0) # outputs: [batch_size, max_length, 2 * hidden_size] # 将双向RNN的outputs按位加起来 outputs = outputs[:, :, : self.hidden_size] + outputs[:, :, self.hidden_size : ] # outputs: [batch_size, max_length, hidden_size] # hidden: [batch_size, 2, hidden_size] return outputs, hidden # Luong提出的全局注意力机制层 class LuongAttentionLayer(nn.Module): def __init__(self, score_name, hidden_size): """ :param score_name: score函数的类型 :param hidden_size: 隐层的维度 :return: """ # score函数是Luong论文中提出用来衡量decoder的目前的隐层和encoder所有输出的相关性 # 论文中不仅介绍了score函数的概念,而且给出了三种映射:dot,general,concat # 这三种score函数都是向量与向量到标量的映射 super(LuongAttentionLayer, self).__init__() self.score_name = score_name self.hidden_size = hidden_size if score_name not in ["dot", "general", "concat"]: raise ValueError(self.score_name, "is not an appropriate attention score_name(dot, general, concat)") # general有一个向量的外积变换, concat有一个外积变换与一个内积变换,所以这两个方法会产生额外的网络参数 # 下面为这两个方法设置需要的网络参数 if score_name == "general": self.Wa = nn.Linear(hidden_size, hidden_size) # 使用h->h的全连接层模拟h*h的矩阵与h维列向量的乘法 elif score_name == "concat": self.Wa = nn.Linear(hidden_size * 2, hidden_size) # 需要将h_t与h_s联级再做矩阵乘法,所以是2h->h的全连接层 self.v = nn.Parameter(torch.FloatTensor(hidden_size)) # FloatTensor会生成hidden_size维的全零(浮点0)向量,我们通过参数可更新的向量来模拟内积变换 # 计算attention vector的变换 self.Wc = nn.Linear(hidden_size * 2, hidden_size) # 需要将c_t与h_t联级再做矩阵乘法,所以是2h->h的全连接层 # 下面定义三个score: # 其中: current_hidden : [batch_size, 1, hidden_size] # encoder_output : [batch_size, max_length, hidden_size] def dot_score(self, current_hidden, encoder_ouput): return torch.sum(encoder_ouput * current_hidden, dim=2) def general_score(self, current_hidden, encoder_output): energy = self.Wa(encoder_output) # energy : [batch_size, max_length, hidden_size] return torch.sum(energy * current_hidden, dim=2) def concat_score(self, current_hidden, encoder_output): concat = torch.cat([current_hidden.expand(encoder_output.shape), encoder_output], dim=2) # concat : [batch, max_length, 2 * hidden_size] energy = self.Wa(concat).tanh() return torch.sum(self.v * energy, dim=2) # 前馈运算为encoder的全体output与decoder的current output值到attention向量的映射 def forward(self, current_hidden, encoder_output): if self.score_name == "dot": score = self.dot_score(current_hidden, encoder_output) elif self.score_name == "general": score = self.general_score(current_hidden, encoder_output) elif self.score_name == "concat": score = self.concat_score(current_hidden, encoder_output) # score : [batch_size, max_length] # 通过 softmax将score转化成注意力权重alpha attention_weights = nn.functional.softmax(score, dim=1) # attention_weights : [batch_size, max_length] # 通过encoder_output与alpha的加权和得到context vector(上下文向量) # 通过广播运算完成 context_vector = torch.sum(encoder_output * attention_weights.unsqueeze(2), dim=1) # context_vector : [batch_size, hidden_size] # 有了上下文向量,就可以计算attention vector了 attention_vector = self.Wc(torch.cat([context_vector.unsqueeze(1), current_hidden], dim=2)).tanh() # attention_vector : [batch_size, 1, hidden_size] return attention_vector # decoder class LuongAttentionDecoderRNN(nn.Module): def __init__(self, score_name, embedding, hidden_size, output_size, n_layers=1, dropout=0): """ :param score_name: Luong Attention Layer 的score函数的类型,可选:dot, general, concat :param embedding: 词向量嵌入矩阵 :param hidden_size: RNN隐层维度 :param output_size: 每一个cell的输出维度,一般会通过一个 hidden_size->output_size的映射把attention vector映射到output_size维向量 :param n_layers: 单个RNN cell的层数 :param dropout: 代表某层参数被丢弃的概率,在n_layers==1的情况下设为0 """ super(LuongAttentionDecoderRNN, self).__init__() self.score_name = score_name self.hidden_size = hidden_size self.output_size = output_size self.n_layers = n_layers self.dropout = dropout # 定义或获取前向传播需要的算子 self.embedding = embedding self.embedding_dropout = nn.Dropout(dropout) self.gru = nn.GRU(input_size=hidden_size, hidden_size=hidden_size, num_layers=n_layers, dropout=(0 if n_layers == 1 else dropout), batch_first=True) self.attention = LuongAttentionLayer(score_name, hidden_size) self.hidden2output = nn.Linear(hidden_size, output_size) # decoder的前向传播逻辑 # 需要注意的是,不同一般的RNN,由于我们的decoder输出需要做注意力运算 # 所以decoder的RNN需要拆开来算,也就是我们的forward一次只能算一个time_step,而不是一次性循环到底 def forward(self, input_single_seq, last_hidden, encoder_output): """ :param input_single_seq: 上一步预测的单词对应的序列 [batch_size, 1] :param last_hidden: decoder上次RNN 的隐层 [batch_size, 2, hidden_size] :param encoder_output: encoder的全体输出 [batch_size, max_length, hidden_size] :return: 代表个位置概率的output向量[batch_size, output_size]和current hidden [batch_size, 2, hidden_size] """ embedded = self.embedding(input_single_seq) # [batch_size, max_length, hidden_size] embedded = self.embedding_dropout(embedded) # [batch_size, max_length, hidden_size] current_output, current_hidden = self.gru(embedded, last_hidden) # current_output : [batch_size, 1, hidden_size] # current_hidden : [1, batch_size, hidden_size] # 这里拿current_output当做current_hidden来参与attention运算 # 当然,直接拿current_hidden也行 attention_vector = self.attention(current_output, encoder_output) # attention_vector : [batch_size, 1, hidden_size] # 将attention_vector变到output_size维 output = self.hidden2output(attention_vector) # output : [batch_size, 1, output_size] output = nn.functional.softmax(output.squeeze(1), dim=1) # output : [batch_size, output_size] return output, current_hidden if __name__ == "__main__": embedding = nn.Embedding(num_embeddings=10, embedding_dim=16) # encoder = EncoderRNN(hidden_size=16, embedding=embedding, n_layer=1, dropout=0) decoder = LuongAttentionDecoderRNN(score_name="dot", embedding=embedding, hidden_size=16, output_size=10, n_layers=1, dropout=0) x = torch.tensor([[2], [2]]) out = torch.arange(320).reshape([2, 10, 16]) length = torch.tensor([5, 3]) #outputs, hidden = encoder.forward(input_seq=x, input_length=length) output, current_hidden = decoder.forward(input_single_seq=x, last_hidden=None, encoder_output=out) print(f"output : {output}") print(f"current_hidden : {current_hidden}")
4、process.py
# process.py from itertools import zip_longest import random import torch # 用来构造字典的类 class vocab(object): def __init__(self, name, pad_token, sos_token, eos_token, unk_token): self.name = name self.pad_token = pad_token self.sos_token = sos_token self.eos_token = eos_token self.unk_token = unk_token self.trimmed = False # 代表这个词表对象是否经过了剪枝操作 self.word2index = {"PAD" : pad_token, "SOS" : sos_token, "EOS" : eos_token, "UNK" : unk_token} self.word2count = {"UNK" : 0} self.index2word = {pad_token : "PAD", sos_token : "SOS", eos_token : "EOS", unk_token : "UNK"} self.num_words = 4 # 刚开始的四个占位符 pad(0), sos(1), eos(2),unk(3) 代表目前遇到的不同的单词数量 # 向voc中添加一个单词的逻辑 def addWord(self, word): if word not in self.word2index: self.word2index[word] = self.num_words self.word2count[word] = 1 self.index2word[self.num_words] = word self.num_words += 1 else: self.word2count[word] += 1 # 向voc中添加一个句子的逻辑 def addSentence(self, sentence): for word in sentence.split(): self.addWord(word) # 将词典中词频过低的单词替换为unk_token # 需要一个代表修剪阈值的参数min_count,词频低于这个参数的单词会被替换为unk_token,相应的词典变量也会做出相应的改变 def trim(self, min_count): if self.trimmed: # 如果已经裁剪过了,那就直接返回 return self.trimmed = True keep_words = [] keep_num = 0 for word, count in self.word2count.items(): if count >= min_count: keep_num += 1 # 由于后面是通过对keep_word列表中的数据逐一统计,所以需要对count>1的单词重复填入 for _ in range(count): keep_words.append(word) print("keep words: {} / {} = {:.4f}".format( keep_num, self.num_words - 4, keep_num / (self.num_words - 4) )) # 重构词表 self.word2index = {"PAD" : self.pad_token, "SOS" : self.sos_token, "EOS" : self.eos_token, "UNK" : self.unk_token} self.word2count = {} self.index2word = {self.pad_token : "PAD", self.sos_token : "SOS", self.eos_token : "EOS", self.unk_token : "UNK"} self.num_words = 4 for word in keep_words: self.addWord(word) # 读入数据,统计词频,并返回数据 def load_data(self, path): pairs = [] for line in open(path, "r", encoding="utf-8"): try: input_dialog, output_dialog = line.strip().split("\t") self.addSentence(input_dialog.strip()) self.addSentence(output_dialog.strip()) pairs.append([input_dialog, output_dialog]) except: pass return pairs # 处理数据,因为我们所有低词频和无法识别的单词(就是不在字典中的词)都替换成UNK # 但是我们不想要看到程序输出给用户的话中带有UNK,所以下面做的处理为: # 先判断output_dialog,如果其中含有不存在与字典中的词,则直接舍弃整个dialog, # 如果output_dialog满足要求,那么我们将input_dialog中无法识别的单词全部替换为UNK def trimAndReplace(voc, pairs, min_count): keep_pairs = [] # 先在词表中删去低频词 voc.trim(min_count) for input_dialog, output_dialog in pairs: drop_dialog = False # 判断output_dialog中是否有无法识别的词, 有的话,直接跳过这个循环 for word in output_dialog.split(): if word not in voc.word2index: drop_dialog = True if drop_dialog: continue # 输入句的未识别单词用UNK替换 input_dialog = input_dialog.split() for idx, word in enumerate(input_dialog): if word not in voc.word2index: input_dialog[idx] = "UNK" input_dialog = " ".join(input_dialog) keep_pairs.append([input_dialog, output_dialog]) print("Trimmed from {} pairs to {}, {:.4f} of total".format(len(pairs), len(keep_pairs), len(keep_pairs) / len(pairs))) return keep_pairs # 将一句话转换成id序列(str->list),结尾加上EOS def sentenceToIndex(sentence, voc): return [voc.word2index[word] for word in sentence.split()] + [voc.eos_token] # 将一个batch中的input_dialog转化为有pad填充的tensor,并返回tensor和记录长度的变量 # 返回的tensor是batch_first的 def batchInput2paddedTensor(batch, voc): # 先转换为id序列,但是这个id序列不对齐 batch_index_seqs = [sentenceToIndex(sentence, voc) for sentence in batch] length_tensor = torch.tensor([len(index_seq) for index_seq in batch_index_seqs]) # 下面填充0(PAD),使得这个batch中的序列对齐 zipped_list = list(zip_longest(*batch_index_seqs, fillvalue=voc.pad_token)) padded_tensor = torch.tensor(zipped_list).t() return padded_tensor, length_tensor # 将一个batch中的output_dialog转化为有pad填充的tensor,并返回tensor、mask和最大句长 # 返回的tensor是batch_first的 def batchOutput2paddedTensor(batch, voc): # 先转换为id序列,但是这个id序列不对齐 batch_index_seqs = [sentenceToIndex(sentence, voc) for sentence in batch] max_length = max([len(index_seq) for index_seq in batch_index_seqs]) # 下面填充0(PAD),使得这个batch中的序列对齐 zipped_list = list(zip_longest(*batch_index_seqs, fillvalue=voc.pad_token)) padded_tensor = torch.tensor(zipped_list).t() # 得到padded_tensor对应的mask mask = torch.BoolTensor(zipped_list).t() return padded_tensor, mask, max_length # 获取数据加载器的函数 # 将输入的一个batch的dialog转换成id序列,填充pad,并返回训练可用的id张量和mask def DataLoader(pairs, voc, batch_size, shuffle=True): if shuffle: random.shuffle(pairs) batch = [] for idx, pair in enumerate(pairs): batch.append([pair[0], pair[1]]) # 数据数量到达batch_size就yield出去并清空 if len(batch) == batch_size: # 为了后续的pack_padded_sequence操作,我们需要给这个batch中的数据按照input_dialog的长度排序(降序) batch.sort(key=lambda x : len(x[0].split()), reverse=True) input_dialog_batch = [] output_dialog_batch = [] for pair in batch: input_dialog_batch.append(pair[0]) output_dialog_batch.append(pair[1]) input_tensor, input_length_tensor = batchInput2paddedTensor(input_dialog_batch, voc) output_tensor, mask, max_length = batchOutput2paddedTensor(output_dialog_batch, voc) # 清空临时缓冲区 batch = [] yield [ input_tensor, input_length_tensor, output_tensor, mask, max_length ] # # 循环结束后,可能还有数据没有yield出去 # if len(batch) != 0: # # 下面的代码和上面的一致 # batch.sort(key=lambda x: len(x[0].split()), reverse=True) # input_dialog_batch = [] # output_dialog_batch = [] # for pair in batch: # input_dialog_batch.append(pair[0]) # output_dialog_batch.append(pair[1]) # # input_tensor, input_length_tensor = batchInput2paddedTensor(input_dialog_batch, voc) # output_tensor, mask, max_length = batchOutput2paddedTensor(output_dialog_batch, voc) # # yield [ # input_tensor, input_length_tensor, output_tensor, mask, max_length # ] if __name__ == "__main__": PAD_token = 0 # 补足句长的pad占位符的index SOS_token = 1 # 代表一句话开头的占位符的index EOS_token = 2 # 代表一句话结尾的占位符的index UNK_token = 3 # 代表不在词典中的字符 BATCH_SIZE = 64 # 一个batch中的对话数量(样本数量) MAX_LENGTH = 20 # 一个对话中每句话的最大句长 MIN_COUNT = 3 # trim方法的修剪阈值 # 实例化词表 voc = vocab(name="corpus", pad_token=PAD_token, sos_token=SOS_token, eos_token=EOS_token, unk_token=UNK_token) # 为词表载入数据,统计词频,并得到对话数据 pairs = voc.load_data(path="./data/dialog.tsv") print("total number of dialogs:", len(pairs)) # 修剪与替换 pairs = trimAndReplace(voc, pairs, MIN_COUNT) # 获取loader loader = DataLoader(pairs, voc, batch_size=5) batch_item_names = ["input_tensor", "input_length_tensor", "output_tensor", "mask", "max_length"] for batch_index, batch in enumerate(loader): for name, item in zip(batch_item_names, batch): print(f"\n{name} : {item}") break
5、train.py
# train.py import torch import random from time import time import os import math # 导入之前写好的函数或类 from process import vocab, trimAndReplace, DataLoader from neural_network import EncoderRNN, LuongAttentionDecoderRNN # 定义运算设备 USE_CUDA = torch.cuda.is_available() device = torch.device("cuda" if USE_CUDA else "cpu") # 常量 PAD_token = 0 # 补足句长的pad占位符的index SOS_token = 1 # 代表一句话开头的占位符的index EOS_token = 2 # 代表一句话结尾的占位符的index UNK_token = 3 # 代表不在词典中的字符 # 超参 BATCH_SIZE = 64 # 一个batch中的对话数量(样本数量) MAX_LENGTH = 20 # 一个对话中每句话的最大句长 MIN_COUNT = 3 # trim方法的修剪阈值 TEACHER_FORCING_RATIO = 1.0 # 实行teacher_force_ratio的概率 LEARNING_RATE = 0.0001 # 学习率 CLIP = 50.0 # 梯度裁剪阈值 # 网络参数 hidden_size = 512 # RNN隐层维度 encoder_n_layers = 2 # encoder的cell层数 decoder_n_layers = 2 # decoder的cell层数 dropout = 0.1 # 丢弃参数的概率 # 轮数与打印间隔 epoch_num = 15 # 迭代轮数 print_interval = 50 # 打印间隔 save_interval = 900 # 保存模型间隔 mask_loss_all = [] # 使用mask loss的方法避免计算pad的loss # 计算非pad对应位置的交叉熵(负对数似然) def maskNLLLoss(output, target, mask): """ :param output: decoder的所有output的拼接 [batch_size, max_length, output_size] :param target: 标签,也就是batch的output_dialog对应的id序列 [batch_size, max_length] :param mask: mask矩阵 与target同形 :return: 交叉熵损失、单词个数 """ target = target.type(torch.int64).to(device) mask = mask.type(torch.BoolTensor).to(device) total_word = mask.sum() # 单词个数 crossEntropy = -torch.log(torch.gather(output, dim=2, index=target.unsqueeze(2))) # crossEntropy : [batch_size, max_length, 1] loss = crossEntropy.squeeze(2).masked_select(mask).mean() loss = loss.to(device) return loss, total_word.item() # 定义训练一个batch的逻辑 # 在这个batch中更新网络时,有一定的概率会使用teacher forcing的方法来加速收敛, 这个概率为teacher_forcing_ratio def trainOneBatch(input_seq, input_length, target, mask, max_target_len, encoder, decoder, encoder_optimizer, decoder_optimizer, batch_size, clip, teacher_forcing_ratio, encoder_lr_scheduler=None, decoder_lr_scheduler=None): """ :param input_seq: 输入encoder的index序列 [batch_size, max_length] :param input_length: input_seq中每个序列的长度 [batch_size] :param target: 每个input_dialog对应的output_dialog的index序列 [batch_size, max_length] :param mask: target对应的mask矩阵 [batch_size, max_length] :param max_target_len: target中的最大句长 :param encoder: encoder实例 :param decoder: decoder实例 :param encoder_optimizer: 承载encoder参数的优化器 :param decoder_optimizer: 承载decoder参数的优化器 :param batch_size: batch大小 :param clip: 修剪梯度的阈值,超过该值的导数值会被裁剪 :param teacher_forcing_ratio: 训练该batch启动teacher force的策略 :param encoder_lr_scheduler: encoder_optimizer学习率调整策略 :param decoder_lr_scheduler: decoder_optimizer学习率调整策略 :return: 平均似然损失 """ # 清空优化器 encoder_optimizer.zero_grad() decoder_optimizer.zero_grad() # 设置变量的运算设备 input_seq = input_seq.to(device) input_length = input_length.to(device) target = target.to(device) mask = mask.to(device) decoder_output = torch.FloatTensor() # 用来保存decoder的所有输出 decoder_output = decoder_output.to(device) # encoder的前向计算 encoder_output, encoder_hidden = encoder(input_seq, input_length) # 为decoder的计算初始化一个开头SOS decoder_input = torch.tensor([SOS_token for _ in range(batch_size)]).reshape([-1, 1]) decoder_input = decoder_input.to(device) # 根据decoder的cell层数截取encoder的h_n的层数 decoder_hidden = encoder_hidden[:decoder.n_layers] # 根据概率决定是否使用teacher force use_teacher_forcing = True if random.random() < teacher_forcing_ratio else False if use_teacher_forcing: for i in range(max_target_len): # 执行一步decoder前馈,只计算了一个单词 output, current_hidden = decoder(decoder_input, decoder_hidden, encoder_output) # output : [batch_size, output_size] # current_hidden : [1, batch_size, hidden_size] # 将本次time_step得到的结果放入decoder_output中 decoder_output = torch.cat([decoder_output, output.unsqueeze(1)], dim=1) # 使用teacher forcing:使用target(真实的单词)作为decoder的下一次的输入,而不是我们计算出的预测值(计算出的概率最大的单词) decoder_input = target[:, i].reshape([-1, 1]) decoder_hidden = current_hidden else: for i in range(max_target_len): # 执行一步decoder前馈,只计算了一个单词 output, current_hidden = decoder(decoder_input, decoder_hidden, encoder_output) # output : [batch_size, output_size] # current_hidden : [1, batch_size, hidden_size] # 从softmax的结果中得到预测的index predict_index = torch.argmax(output, dim=1) # 将本次time_step得到的结果放入decoder_output中 decoder_output = torch.cat([decoder_output, output.unsqueeze(1)], dim=1) decoder_input = predict_index.reshape([-1, 1]) decoder_hidden = current_hidden # 计算本次batch中的mask_loss和总共的单词数 mask_loss, word_num = maskNLLLoss(output=decoder_output, target=target, mask=mask) # 开始反向传播,更新参数 mask_loss.backward() # 裁剪梯度 torch.nn.utils.clip_grad_norm_(encoder.parameters(), clip) torch.nn.utils.clip_grad_norm_(decoder.parameters(), clip) # 更新网络参数 encoder_optimizer.step() decoder_optimizer.step() # 调整优化器的学习率 if encoder_lr_scheduler and decoder_lr_scheduler: encoder_lr_scheduler.step() decoder_lr_scheduler.step() return mask_loss.item() # 开始训练 print("build vocab_list...") # 首先构建字典 voc = vocab(name="corpus", pad_token=PAD_token, sos_token=SOS_token, eos_token=EOS_token, unk_token=UNK_token) # 载入数据 pairs = voc.load_data(path="./data/dialog.tsv") print(f"load {len(pairs)} dialogs successfully") # 对数据进行裁剪 pairs = trimAndReplace(voc=voc, pairs=pairs, min_count=MIN_COUNT) print(f"there are {voc.num_words} words in the vocab") # 定义词向量嵌入矩阵 embedding = torch.nn.Embedding(num_embeddings=voc.num_words, embedding_dim=hidden_size, padding_idx=PAD_token) # 获取encoder和decoder encoder = EncoderRNN(hidden_size=hidden_size, embedding=embedding, n_layers=encoder_n_layers, dropout=dropout) decoder = LuongAttentionDecoderRNN(score_name="dot", embedding=embedding, hidden_size=hidden_size, output_size=voc.num_words, n_layers=decoder_n_layers, dropout=dropout) encoder = encoder.to(device) decoder = decoder.to(device) # 为encoder和decoder分别定义优化器 encoder_optimizer = torch.optim.Adam(encoder.parameters(), lr=LEARNING_RATE) decoder_optimizer = torch.optim.Adam(decoder.parameters(), lr=LEARNING_RATE) # Leslie的Triangle2学习率衰减方法 def Triangular2(T_max, gamma): def new_lr(step): region = step // T_max + 1 # 所处分段 increase_rate = 1 / T_max * math.pow(gamma, region - 2) # 增长率的绝对值 return increase_rate * (step - (region - 1) * T_max) if step <= (region - 0.5) * T_max else - increase_rate * (step - region * T_max) return new_lr # 定义优化器学习率的衰减策略 # encoder_lr_scheduler = torch.optim.lr_scheduler.LambdaLR(optimizer=encoder_optimizer, # # lr_lambda=Triangular2(T_max=300, gamma=0.5)) # # decoder_lr_scheduler = torch.optim.lr_scheduler.LambdaLR(optimizer=decoder_optimizer, # # lr_lambda=Triangular2(T_max=300, gamma=0.5)) encoder_lr_scheduler = None decoder_lr_scheduler = None global_step = 0 start_time = time() encoder.train() decoder.train() print("start to train...") # 轮数遍历 for epoch in range(epoch_num): print("-" * 20) print("Epoch : ",epoch) # 获取loader train_loader = DataLoader(pairs=pairs, voc=voc, batch_size=BATCH_SIZE, shuffle=True) # 遍历生成器 for batch_num, batch in enumerate(train_loader): global_step += 1 # batch中的信息 : ["input_tensor", "input_length_tensor", "output_tensor", "mask", "max_length"] loss = trainOneBatch(input_seq=batch[0], input_length=batch[1], target=batch[2], mask=batch[3], max_target_len=batch[4], encoder=encoder, decoder=decoder, encoder_optimizer=encoder_optimizer, decoder_optimizer=decoder_optimizer, batch_size=BATCH_SIZE, clip=CLIP, teacher_forcing_ratio=TEACHER_FORCING_RATIO, encoder_lr_scheduler=encoder_lr_scheduler, decoder_lr_scheduler=decoder_lr_scheduler) mask_loss_all.append(loss) if global_step % print_interval == 0: print("Epoch : {}\tbatch_num : {}\tloss: {:.6f}\ttime point : {:.2f}s\tmodel_lr : {:.10f}".format( epoch, batch_num, loss, time() - start_time, encoder_optimizer.param_groups[0]["lr"] )) # 将check_point存入./data/check_points这个文件夹中 if global_step % save_interval == 0: # 先判断目标路径是否存在,不存在则创建 if not os.path.exists("./data/checkpoints"): os.makedirs("./data/checkpoints") check_point_save_path = f"./data/checkpoints/{global_step}_checkpoint.tar" torch.save({ "iteration" : global_step, "encoder" : encoder.state_dict(), "decoder" : decoder.state_dict(), "encoder_optimizer" : encoder_optimizer.state_dict(), "decoder_optimizer" : decoder_optimizer.state_dict(), # "encoder_lr_scheduler" : encoder_lr_scheduler.state_dict(), # "decoder_lr_scheduler" : decoder_lr_scheduler.state_dict(), "loss" : loss, "voc_dict" : voc.__dict__, "embedding" : embedding.state_dict() }, check_point_save_path) print(f"save model to {check_point_save_path}")
六、训练过程与结果
D:\Users\zxr20\Anaconda3\python.exe C:/Users/zxr20/Downloads/chatbot-based-on-seq2seq2-master/train.py
build vocab_list...
load 64223 dialogs successfully
keep words: 7821 / 17999 = 0.4345
Trimmed from 64223 pairs to 58362, 0.9087 of total
there are 7825 words in the vocab
start to train...
--------------------
Epoch : 0
Epoch : 0 batch_num : 49 loss: 4.991693 time point : 44.72s model_lr : 0.0001000000
Epoch : 0 batch_num : 99 loss: 4.566347 time point : 86.06s model_lr : 0.0001000000
Epoch : 0 batch_num : 149 loss: 4.462077 time point : 128.47s model_lr : 0.0001000000
Epoch : 0 batch_num : 199 loss: 4.543541 time point : 171.10s model_lr : 0.0001000000
Epoch : 0 batch_num : 249 loss: 4.261803 time point : 214.57s model_lr : 0.0001000000
Epoch : 0 batch_num : 299 loss: 4.373475 time point : 258.23s model_lr : 0.0001000000
Epoch : 0 batch_num : 349 loss: 4.455844 time point : 302.26s model_lr : 0.0001000000
Epoch : 0 batch_num : 399 loss: 3.997347 time point : 346.85s model_lr : 0.0001000000
Epoch : 0 batch_num : 449 loss: 4.109106 time point : 391.87s model_lr : 0.0001000000
Epoch : 0 batch_num : 499 loss: 4.210484 time point : 436.89s model_lr : 0.0001000000
Epoch : 0 batch_num : 549 loss: 3.893747 time point : 484.78s model_lr : 0.0001000000
Epoch : 0 batch_num : 599 loss: 4.201549 time point : 529.91s model_lr : 0.0001000000
Epoch : 0 batch_num : 649 loss: 4.083264 time point : 574.67s model_lr : 0.0001000000
Epoch : 0 batch_num : 699 loss: 3.922026 time point : 618.74s model_lr : 0.0001000000
Epoch : 0 batch_num : 749 loss: 3.875324 time point : 661.42s model_lr : 0.0001000000
Epoch : 0 batch_num : 799 loss: 4.137966 time point : 704.38s model_lr : 0.0001000000
Epoch : 0 batch_num : 849 loss: 3.970867 time point : 748.27s model_lr : 0.0001000000
Epoch : 0 batch_num : 899 loss: 4.118044 time point : 792.55s model_lr : 0.0001000000
save model to ./data/checkpoints/900_checkpoint.tar
--------------------
Epoch : 1
Epoch : 1 batch_num : 38 loss: 3.883439 time point : 837.34s model_lr : 0.0001000000
Epoch : 1 batch_num : 88 loss: 3.946029 time point : 881.18s model_lr : 0.0001000000
Epoch : 1 batch_num : 138 loss: 3.800174 time point : 925.49s model_lr : 0.0001000000
Epoch : 1 batch_num : 188 loss: 3.743748 time point : 970.92s model_lr : 0.0001000000
Epoch : 1 batch_num : 238 loss: 3.678756 time point : 1015.53s model_lr : 0.0001000000
Epoch : 1 batch_num : 288 loss: 3.697902 time point : 1060.22s model_lr : 0.0001000000
Epoch : 1 batch_num : 338 loss: 3.924529 time point : 1105.09s model_lr : 0.0001000000
Epoch : 1 batch_num : 388 loss: 3.965059 time point : 1150.03s model_lr : 0.0001000000
Epoch : 1 batch_num : 438 loss: 3.997313 time point : 1194.99s model_lr : 0.0001000000
Epoch : 1 batch_num : 488 loss: 3.737204 time point : 1239.56s model_lr : 0.0001000000
Epoch : 1 batch_num : 538 loss: 3.634290 time point : 1283.20s model_lr : 0.0001000000
Epoch : 1 batch_num : 588 loss: 3.899791 time point : 1327.69s model_lr : 0.0001000000
Epoch : 1 batch_num : 638 loss: 3.566592 time point : 1372.10s model_lr : 0.0001000000
Epoch : 1 batch_num : 688 loss: 3.870382 time point : 1417.75s model_lr : 0.0001000000
Epoch : 1 batch_num : 738 loss: 3.869323 time point : 1463.22s model_lr : 0.0001000000
Epoch : 1 batch_num : 788 loss: 3.565725 time point : 1506.46s model_lr : 0.0001000000
Process finished with exit code -1
测试结果:
D:\Users\zxr20\Anaconda3\python.exe C:/Users/zxr20/Downloads/chatbot-based-on-seq2seq2-master/evaluate.py User:what is your name chatbot: you re going ? ? . . . . . . . chatbot's confidence: ['2.3%', '2.9%', '0.5%', '0.6%', '82.8%', '0.7%', '80.8%', '0.8%', '83.1%', '1.0%', '82.8%', '1.4%'] User:your name ? chatbot: i m not . . . . . . . . . chatbot's confidence: ['3.4%', '12.7%', '1.3%', '10.3%', '87.3%', '2.0%', '84.8%', '3.3%', '87.0%', '4.1%', '87.8%', '4.6%'] User:do you like banana? chatbot: i m not . . . . . . . . . chatbot's confidence: ['6.2%', '13.6%', '1.6%', '1.6%', '92.1%', '3.3%', '91.3%', '4.9%', '91.7%', '5.6%', '91.8%', '6.0%'] User:what's your name? chatbot: i m going . . . . . . . . . chatbot's confidence: ['0.7%', '9.2%', '0.5%', '1.4%', '88.6%', '0.4%', '85.3%', '0.7%', '85.1%', '0.9%', '85.0%', '1.0%'] User:Do you like me? chatbot: i m not . . . . . . . . . chatbot's confidence: ['6.2%', '13.6%', '1.6%', '1.6%', '92.1%', '3.3%', '91.3%', '4.9%', '91.7%', '5.6%', '91.8%', '6.0%'] User:
七、基于transformer、BERT、GPT2的聊天机器人
代码见我的git: https://github.com/JasonZhangXianRong/transformer_Bert_GPT2
1、RNN

2、BERT

3、GPT2

