

推荐系统(一):DeepFm原理与实战
一、概述
https://blog.csdn.net/springtostring/article/details/108157070
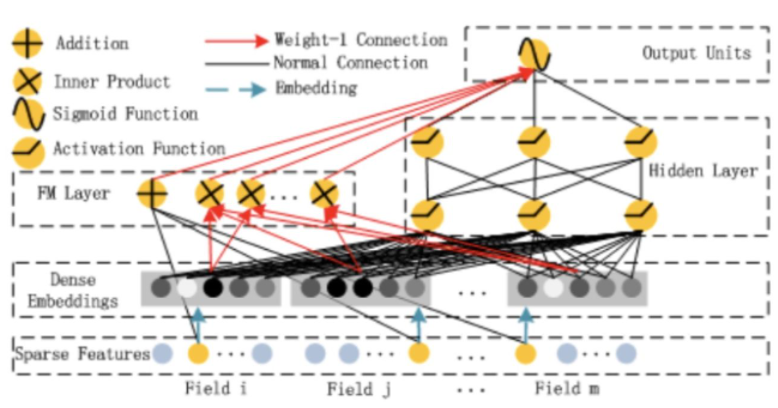
FM模型善于挖掘二阶特征交叉关系,而神经网络DNN的优点是能够挖掘高阶的特征交叉关系,于是DeepFM将两者组合到一起,实验证明DeepFM比单模型FM、DNN效果好。DeepFM相当于同时组合了原Wide部分+二阶特征交叉部分+Deep部分三种结构,无疑进一步增强了模型的表达能力。
二、数据集
运行环境:python 3.6、pytorch 1.5、pandas、numpy
Criteo数据集:Criteo Dataset 是CTR领域的经典数据集,特征经过脱敏处理,[I1,I13]为数值特征,[C1,C26]为类别特征。
kaggle Criteo:是完整的数据集,大概有45000000个样本
下载地址: http://labs.criteo.com/2014/02/kaggle-display-advertising-challenge-dataset/
sample Criteo:是对kaggle Criteo数据集的采样,有1000000个样本
三、代码实现
1、run_deepfm.py代码实现

import pandas as pd import torch from sklearn.metrics import log_loss, roc_auc_score from sklearn.model_selection import train_test_split from sklearn.preprocessing import LabelEncoder, MinMaxScaler import sys import os import torch.nn as nn import numpy as np import torch.utils.data as Data from torch.utils.data import DataLoader import torch.optim as optim import torch.nn.functional as F from sklearn.metrics import log_loss, roc_auc_score from collections import OrderedDict, namedtuple, defaultdict import random from deepctrmodels.deepfm import Deepfm
设置随机种子,保证程序可再现
seed = 1024 torch.manual_seed(seed) # 为CPU设置随机种子 torch.cuda.manual_seed(seed) # 为当前GPU设置随机种子 torch.cuda.manual_seed_all(seed) # 为所有GPU设置随机种子 np.random.seed(seed) random.seed(seed)
读入数据
sparse_features = ['C' + str(i) for i in range(1, 27)] #C代表类别特征 class dense_features = ['I' + str(i) for i in range(1, 14)] #I代表数值特征 int col_names = ['label'] + dense_features + sparse_features data = pd.read_csv('dac/train.txt', names=col_names, sep='\t') feature_names = sparse_features + dense_features #全体特征名 data[sparse_features] = data[sparse_features].fillna('-1', ) # 类别特征缺失 ,使用-1代替 data[dense_features] = data[dense_features].fillna(0, ) # 数值特征缺失,使用0代替 target = ['label']
类别特征编号,数值特征maxmin归一化
# 1.Label Encoding for sparse features,and do simple Transformation for dense features # 使用LabelEncoder(),为类别特征的每一个item编号 for feat in sparse_features: lbe = LabelEncoder() data[feat] = lbe.fit_transform(data[feat]) # 数值特征 max-min 0-1归化 mms = MinMaxScaler(feature_range=(0, 1)) data[dense_features] = mms.fit_transform(data[dense_features])
建立字典{特征名:特征总类别数} (数值特征类别数直接置为1)
# 2.count #unique features for each sparse field,and record dense feature field name feat_sizes1={ feat:1 for feat in dense_features} feat_sizes2 = {feat: len(data[feat].unique()) for feat in sparse_features} feat_sizes={} feat_sizes.update(feat_sizes1) feat_sizes.update(feat_sizes2)
划分数据集,这里的得到的训练集、测试集都以 {特征名 : 特征数据} 这样的形式输入模型
# 3.generate input data for model train, test = train_test_split(data, test_size=0.2,random_state=2020) # print(train.head(5)) # print(test.head(5)) train_model_input = {name: train[name] for name in feature_names} test_model_input = {name: test[name] for name in feature_names}
模型运行,模型参数主要是 dnn_hidden_units:神经网络参数,dnn_dropout:dropout参数 ,ebedding_size:embedding向量长度。
device = 'cpu' use_cuda = True if use_cuda and torch.cuda.is_available(): print('cuda ready...') device = 'cuda:0' model = Deepfm(feat_sizes , dnn_hidden_units=[400,400,400] , dnn_dropout=0.9 , ebedding_size = 8 , l2_reg_linear=1e-3, device=device) # print(model) # for name,tensor in model.named_parameters(): # print(name,tensor) model.fit(train_model_input, train[target].values , test_model_input , test[target].values ,batch_size=50000, epochs=150, verbose=1) pred_ans = model.predict(test_model_input, 50000) print("final test") print("test LogLoss", round(log_loss(test[target].values, pred_ans), 4)) print("test AUC", round(roc_auc_score(test[target].values, pred_ans), 4))
2、deepfm框架实现
init 部分
(1) 模型参数传递
def __init__(self, feat_sizes, sparse_feature_columns, dense_feature_columns,dnn_hidden_units=[400, 400,400], dnn_dropout=0.0, ebedding_size=4, l2_reg_linear=0.00001, l2_reg_embedding=0.00001, l2_reg_dnn=0, init_std=0.0001, seed=1024, device='cpu'): super(Deepfm, self).__init__() self.feat_sizes = feat_sizes self.device = device self.sparse_feature_columns = sparse_feature_columns self.dense_feature_columns = dense_feature_columns self.embedding_size = ebedding_size self.l2_reg_linear = l2_reg_linear
(2)FM 模型参数设置,具体就是设置embedding变换
self.feature_index 建立feature到列名到输入数据X的相对位置的映射
self.weight、self.embedding_dict1 与FM一阶项相关
self.embedding_dict2 用于embedding向量生成,与FM二阶项相关
self.feature_index = self.build_input_features(self.feat_sizes) self.bias = nn.Parameter(torch.zeros((1,))) # self.weight self.weight = nn.Parameter(torch.Tensor(len(self.dense_feature_columns), 1)).to(device) torch.nn.init.normal_(self.weight, mean=0, std=0.0001) self.embedding_dict1 = self.create_embedding_matrix(self.sparse_feature_columns , feat_sizes , 1 , sparse=False, device=self.device) self.embedding_dict2 = self.create_embedding_matrix(self.sparse_feature_columns , feat_sizes , self.embedding_size , sparse=False, device=self.device)
(3)DNN模型参数设置,神经元数目,dropout率设置
# dnn self.dropout = nn.Dropout(dnn_dropout) self.dnn_input_size = self.embedding_size * len(self.sparse_feature_columns) + len(self.dense_feature_columns) hidden_units = [self.dnn_input_size] + dnn_hidden_units self.linears = nn.ModuleList( [nn.Linear(hidden_units[i], hidden_units[i + 1]) for i in range(len(hidden_units) - 1)]) self.relus = nn.ModuleList( [nn.ReLU() for i in range(len(hidden_units) - 1)]) for name, tensor in self.linears.named_parameters(): if 'weight' in name: nn.init.normal_(tensor, mean=0, std=init_std) # self.linears =self.linears.to(device) self.dnn_linear = nn.Linear( dnn_hidden_units[-1], 1, bias=False).to(device)
模型forward部分
FM实现
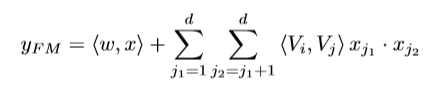
FM线性部分,即求一阶项之和
''' FM liner ''' sparse_embedding_list1 = [self.embedding_dict1[feat]( X[:, self.feature_index[feat][0]:self.feature_index[feat][1]].long()) for feat in self.sparse_feature_columns] dense_value_list2 = [X[:, self.feature_index[feat][0]:self.feature_index[feat][1]] for feat in self.dense_feature_columns] linear_sparse_logit = torch.sum( torch.cat(sparse_embedding_list1, dim=-1), dim=-1, keepdim=False) linear_dense_logit = torch.cat( dense_value_list2, dim=-1).matmul(self.weight) logit = linear_sparse_logit + linear_dense_logit sparse_embedding_list = [self.embedding_dict2[feat]( X[:, self.feature_index[feat][0]:self.feature_index[feat][1]].long()) for feat in self.sparse_feature_columns]
FM二阶项求和
''' FM second ''' fm_input = torch.cat(sparse_embedding_list, dim=1) # shape: (batch_size,field_size,embedding_size) square_of_sum = torch.pow(torch.sum(fm_input, dim=1, keepdim=True), 2) # shape: (batch_size,1,embedding_size) sum_of_square = torch.sum(torch.pow(fm_input, 2), dim=1, keepdim=True) # shape: (batch_size,1,embedding_size) cross_term = square_of_sum - sum_of_square cross_term = 0.5 * torch.sum(cross_term, dim=2, keepdim=False) # shape: (batch_size,1) logit += cross_term
DNN部分
''' DNN ''' # sparse_embedding_list、 dense_value_list2 dnn_sparse_input = torch.cat(sparse_embedding_list, dim=1) batch_size = dnn_sparse_input.shape[0] # print(dnn_sparse_input.shape) dnn_sparse_input=dnn_sparse_input.reshape(batch_size,-1) # dnn_sparse_input shape: [ batch_size, len(sparse_feat)*embedding_size ] dnn_dense_input = torch.cat(dense_value_list2, dim=-1) # print(dnn_sparse_input.shape) # dnn_dense_input shape: [ batch_size, len(dense_feat) ] dnn_total_input = torch.cat([dnn_sparse_input, dnn_dense_input], dim=-1) deep_input = dnn_total_input for i in range(len(self.linears)): fc = self.linears[i](deep_input) fc = self.relus[i](fc) fc = self.dropout(fc) deep_input = fc dnn_output = self.dnn_linear(deep_input)
三、实验结果
在kaggle Criteo 数据集上运行,实验结果图如下,最高AUC可以达到79.15%

四、完整代码
1、运行类
import torch from sklearn.metrics import log_loss, roc_auc_score from sklearn.model_selection import train_test_split from sklearn.preprocessing import LabelEncoder, MinMaxScaler import sys import os import torch.nn as nn import numpy as np import torch.utils.data as Data from torch.utils.data import DataLoader import torch.optim as optim import torch.nn.functional as F from sklearn.metrics import log_loss, roc_auc_score from collections import OrderedDict, namedtuple, defaultdict import random from deepctrmodels.deepfm import Deepfm if __name__ == "__main__": seed = 1024 torch.manual_seed(seed) # 为CPU设置随机种子 torch.cuda.manual_seed(seed) # 为当前GPU设置随机种子 torch.cuda.manual_seed_all(seed) # 为所有GPU设置随机种子 np.random.seed(seed) random.seed(seed) sparse_features = ['C' + str(i) for i in range(1, 27)] #C代表类别特征 class dense_features = ['I' + str(i) for i in range(1, 14)] #I代表数值特征 int col_names = ['label'] + dense_features + sparse_features data = pd.read_csv('dac/train.txt', names=col_names, sep='\t') # data = pd.read_csv('criteo_train_1m.txt', names=col_names, sep='\t') # data = pd.read_csv('total.txt') feature_names = sparse_features + dense_features #全体特征名 data[sparse_features] = data[sparse_features].fillna('-1', ) # 类别特征缺失 ,使用-1代替 data[dense_features] = data[dense_features].fillna(0, ) # 数值特征缺失,使用0代替 target = ['label'] # label # 1.Label Encoding for sparse features,and do simple Transformation for dense features # 使用LabelEncoder(),为类别特征的每一个item编号 for feat in sparse_features: lbe = LabelEncoder() data[feat] = lbe.fit_transform(data[feat]) # 数值特征 max-min 0-1归化 mms = MinMaxScaler(feature_range=(0, 1)) data[dense_features] = mms.fit_transform(data[dense_features]) # 2.count #unique features for each sparse field,and record dense feature field name feat_sizes1={ feat:1 for feat in dense_features} feat_sizes2 = {feat: len(data[feat].unique()) for feat in sparse_features} feat_sizes={} feat_sizes.update(feat_sizes1) feat_sizes.update(feat_sizes2) # print(feat_sizes) # 3.generate input data for model train, test = train_test_split(data, test_size=0.2,random_state=2020) # print(train.head(5)) # print(test.head(5)) train_model_input = {name: train[name] for name in feature_names} test_model_input = {name: test[name] for name in feature_names} # 4.Define Model,train,predict and evaluate device = 'cpu' use_cuda = True if use_cuda and torch.cuda.is_available(): print('cuda ready...') device = 'cuda:0' model = Deepfm(feat_sizes ,sparse_feature_columns = sparse_features,dense_feature_columns = dense_features, dnn_hidden_units=[400,400,400] , dnn_dropout=0.9 , ebedding_size = 8 , l2_reg_linear=1e-3, device=device) model.fit(train_model_input, train[target].values , test_model_input , test[target].values ,batch_size=50000, epochs=150, verbose=1) pred_ans = model.predict(test_model_input, 50000) print("final test") print("test LogLoss", round(log_loss(test[target].values, pred_ans), 4)) print("test AUC", round(roc_auc_score(test[target].values, pred_ans), 4))
2、模型类
# -*- coding: utf-8 -*- import pandas as pd import torch from sklearn.metrics import log_loss, roc_auc_score from sklearn.model_selection import train_test_split from sklearn.preprocessing import LabelEncoder, MinMaxScaler import sys import os import torch.nn as nn import numpy as np import torch.utils.data as Data from torch.utils.data import DataLoader import torch.optim as optim import torch.nn.functional as F from sklearn.metrics import log_loss, roc_auc_score from collections import OrderedDict, namedtuple, defaultdict import random # 添加 dropout 和 L2正则项 添加后与deepctr还是有区别 L2正则项需要继续改进 # init()代码太冗杂了,封装几个函数 class Deepfm(nn.Module): def __init__(self, feat_sizes, sparse_feature_columns, dense_feature_columns,dnn_hidden_units=[400, 400,400], dnn_dropout=0.0, ebedding_size=4, l2_reg_linear=0.00001, l2_reg_embedding=0.00001, l2_reg_dnn=0, init_std=0.0001, seed=1024, device='cpu'): super(Deepfm, self).__init__() self.feat_sizes = feat_sizes self.device = device self.sparse_feature_columns = sparse_feature_columns self.dense_feature_columns = dense_feature_columns self.embedding_size = ebedding_size self.l2_reg_linear = l2_reg_linear # self.feature_index 建立feature到列名到输入数据X的相对位置的映射 self.feature_index = self.build_input_features(self.feat_sizes) self.bias = nn.Parameter(torch.zeros((1,))) # self.weight self.weight = nn.Parameter(torch.Tensor(len(self.dense_feature_columns), 1)).to(device) torch.nn.init.normal_(self.weight, mean=0, std=0.0001) self.embedding_dict1 = self.create_embedding_matrix(self.sparse_feature_columns , feat_sizes , 1 , sparse=False, device=self.device) self.embedding_dict2 = self.create_embedding_matrix(self.sparse_feature_columns , feat_sizes , self.embedding_size , sparse=False, device=self.device) # dnn self.dropout = nn.Dropout(dnn_dropout) self.dnn_input_size = self.embedding_size * len(self.sparse_feature_columns) + len(self.dense_feature_columns) hidden_units = [self.dnn_input_size] + dnn_hidden_units self.linears = nn.ModuleList( [nn.Linear(hidden_units[i], hidden_units[i + 1]) for i in range(len(hidden_units) - 1)]) self.relus = nn.ModuleList( [nn.ReLU() for i in range(len(hidden_units) - 1)]) for name, tensor in self.linears.named_parameters(): if 'weight' in name: nn.init.normal_(tensor, mean=0, std=init_std) # self.linears =self.linears.to(device) self.dnn_linear = nn.Linear( dnn_hidden_units[-1], 1, bias=False).to(device) self.to(device) def forward(self, X): ''' :param X: pd.DtateFrame :return: y_pre ''' ''' FM liner ''' sparse_embedding_list1 = [self.embedding_dict1[feat]( X[:, self.feature_index[feat][0]:self.feature_index[feat][1]].long()) for feat in self.sparse_feature_columns] dense_value_list2 = [X[:, self.feature_index[feat][0]:self.feature_index[feat][1]] for feat in self.dense_feature_columns] linear_sparse_logit = torch.sum( torch.cat(sparse_embedding_list1, dim=-1), dim=-1, keepdim=False) linear_dense_logit = torch.cat( dense_value_list2, dim=-1).matmul(self.weight) logit = linear_sparse_logit + linear_dense_logit sparse_embedding_list = [self.embedding_dict2[feat]( X[:, self.feature_index[feat][0]:self.feature_index[feat][1]].long()) for feat in self.sparse_feature_columns] ''' FM second ''' fm_input = torch.cat(sparse_embedding_list, dim=1) # shape: (batch_size,field_size,embedding_size) square_of_sum = torch.pow(torch.sum(fm_input, dim=1, keepdim=True), 2) # shape: (batch_size,1,embedding_size) sum_of_square = torch.sum(torch.pow(fm_input, 2), dim=1, keepdim=True) # shape: (batch_size,1,embedding_size) cross_term = square_of_sum - sum_of_square cross_term = 0.5 * torch.sum(cross_term, dim=2, keepdim=False) # shape: (batch_size,1) logit += cross_term ''' DNN ''' # sparse_embedding_list、 dense_value_list2 dnn_sparse_input = torch.cat(sparse_embedding_list, dim=1) batch_size = dnn_sparse_input.shape[0] # print(dnn_sparse_input.shape) dnn_sparse_input=dnn_sparse_input.reshape(batch_size,-1) # dnn_sparse_input shape: [ batch_size, len(sparse_feat)*embedding_size ] dnn_dense_input = torch.cat(dense_value_list2, dim=-1) # print(dnn_sparse_input.shape) # dnn_dense_input shape: [ batch_size, len(dense_feat) ] dnn_total_input = torch.cat([dnn_sparse_input, dnn_dense_input], dim=-1) deep_input = dnn_total_input for i in range(len(self.linears)): fc = self.linears[i](deep_input) fc = self.relus[i](fc) fc = self.dropout(fc) deep_input = fc dnn_output = self.dnn_linear(deep_input) logit += dnn_output ''' output ''' y_pred = torch.sigmoid(logit+self.bias) return y_pred def fit(self, train_input, y_label, val_input, y_val, batch_size=5000, epochs=15, verbose=5): x = [train_input[feature] for feature in self.feature_index] for i in range(len(x)): if len(x[i].shape) == 1: x[i] = np.expand_dims(x[i], axis=1) # 扩展成2维,以便后续cat train_tensor_data = Data.TensorDataset(torch.from_numpy(np.concatenate(x, axis=-1)), torch.from_numpy(y_label)) train_loader = DataLoader(dataset=train_tensor_data,shuffle=True ,batch_size=batch_size) print(self.device, end="\n") model = self.train() loss_func = F.binary_cross_entropy # loss_func = F.binary_cross_entropy_with_logits optimizer = optim.Adam(model.parameters(), lr=0.001, weight_decay = 0.0) # optimizer = optim.Adagrad(model.parameters(),lr=0.01) # 显示 一次epoch需要几个step sample_num = len(train_tensor_data) steps_per_epoch = (sample_num - 1) // batch_size + 1 print("Train on {0} samples, {1} steps per epoch".format( len(train_tensor_data), steps_per_epoch)) for epoch in range(epochs): loss_epoch = 0 total_loss_epoch = 0.0 train_result = {} pred_ans = [] true_ans = [] with torch.autograd.set_detect_anomaly(True): for index, (x_train, y_train) in enumerate(train_loader): x = x_train.to(self.device).float() y = y_train.to(self.device).float() y_pred = model(x).squeeze() optimizer.zero_grad() loss = loss_func(y_pred, y.squeeze(),reduction='mean') #L2 norm loss = loss + self.l2_reg_linear * self.get_L2_Norm() loss.backward(retain_graph=True) optimizer.step() total_loss_epoch = total_loss_epoch + loss.item() y_pred = y_pred.cpu().data.numpy() # .squeeze() pred_ans.append(y_pred) true_ans.append(y.squeeze().cpu().data.numpy()) if (epoch % verbose == 0): print('epoch %d train loss is %.4f train AUC is %.4f' % (epoch,total_loss_epoch / steps_per_epoch,roc_auc_score(np.concatenate(true_ans), np.concatenate(pred_ans)))) self.val_auc_logloss(val_input, y_val, batch_size=50000) print(" ") def predict(self, test_input, batch_size = 256, use_double=False): """ :param x: The input data, as a Numpy array (or list of Numpy arrays if the model has multiple inputs). :param batch_size: Integer. If unspecified, it will default to 256. :return: Numpy array(s) of predictions. """ model = self.eval() x = [test_input[feature] for feature in self.feature_index] for i in range(len(x)): if len(x[i].shape) == 1: x[i] = np.expand_dims(x[i], axis=1) # 扩展成2维,以便后续cat tensor_data = Data.TensorDataset( torch.from_numpy(np.concatenate(x, axis=-1))) test_loader = DataLoader( dataset=tensor_data, shuffle=False, batch_size=batch_size) pred_ans = [] with torch.no_grad(): for index, x_test in enumerate(test_loader): x = x_test[0].to(self.device).float() # y = y_test.to(self.device).float() y_pred = model(x).cpu().data.numpy() # .squeeze() pred_ans.append(y_pred) if use_double: return np.concatenate(pred_ans).astype("float64") else: return np.concatenate(pred_ans) def val_auc_logloss(self, val_input, y_val, batch_size=50000, use_double=False): pred_ans = self.predict(val_input, batch_size) print("test LogLoss is %.4f test AUC is %.4f"%(log_loss(y_val, pred_ans),roc_auc_score(y_val, pred_ans)) ) def get_L2_Norm(self ): loss = torch.zeros((1,), device=self.device) loss = loss + torch.norm(self.weight) for t in self.embedding_dict1.parameters(): loss = loss+ torch.norm(t) for t in self.embedding_dict2.parameters(): loss = loss+ torch.norm(t) return loss def build_input_features(self, feat_sizes): # Return OrderedDict: {feature_name:(start, start+dimension)} features = OrderedDict() start = 0 for feat in feat_sizes: feat_name = feat if feat_name in features: continue features[feat_name] = (start, start + 1) start += 1 return features def create_embedding_matrix(self ,sparse_feature_columns, feat_sizes,embedding_size,init_std=0.0001, sparse=False, device='cpu'): embedding_dict = nn.ModuleDict( {feat: nn.Embedding(feat_sizes[feat], embedding_size, sparse=False) for feat in sparse_feature_columns} ) for tensor in embedding_dict.values(): nn.init.normal_(tensor.weight, mean=0, std=init_std) return embedding_dict.to(device)


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 开发者必知的日志记录最佳实践
· SQL Server 2025 AI相关能力初探
· Linux系列:如何用 C#调用 C方法造成内存泄露
· AI与.NET技术实操系列(二):开始使用ML.NET
· 记一次.NET内存居高不下排查解决与启示
· 阿里最新开源QwQ-32B,效果媲美deepseek-r1满血版,部署成本又又又降低了!
· 开源Multi-agent AI智能体框架aevatar.ai,欢迎大家贡献代码
· Manus重磅发布:全球首款通用AI代理技术深度解析与实战指南
· 被坑几百块钱后,我竟然真的恢复了删除的微信聊天记录!
· 没有Manus邀请码?试试免邀请码的MGX或者开源的OpenManus吧