

tensorflow(四十二):宝可梦精灵自定义数据集加载、数据增强、数据正则化、迁移学习
一、数据集加载步骤
1、获得图片路径列表给x,获得标签列表给y.
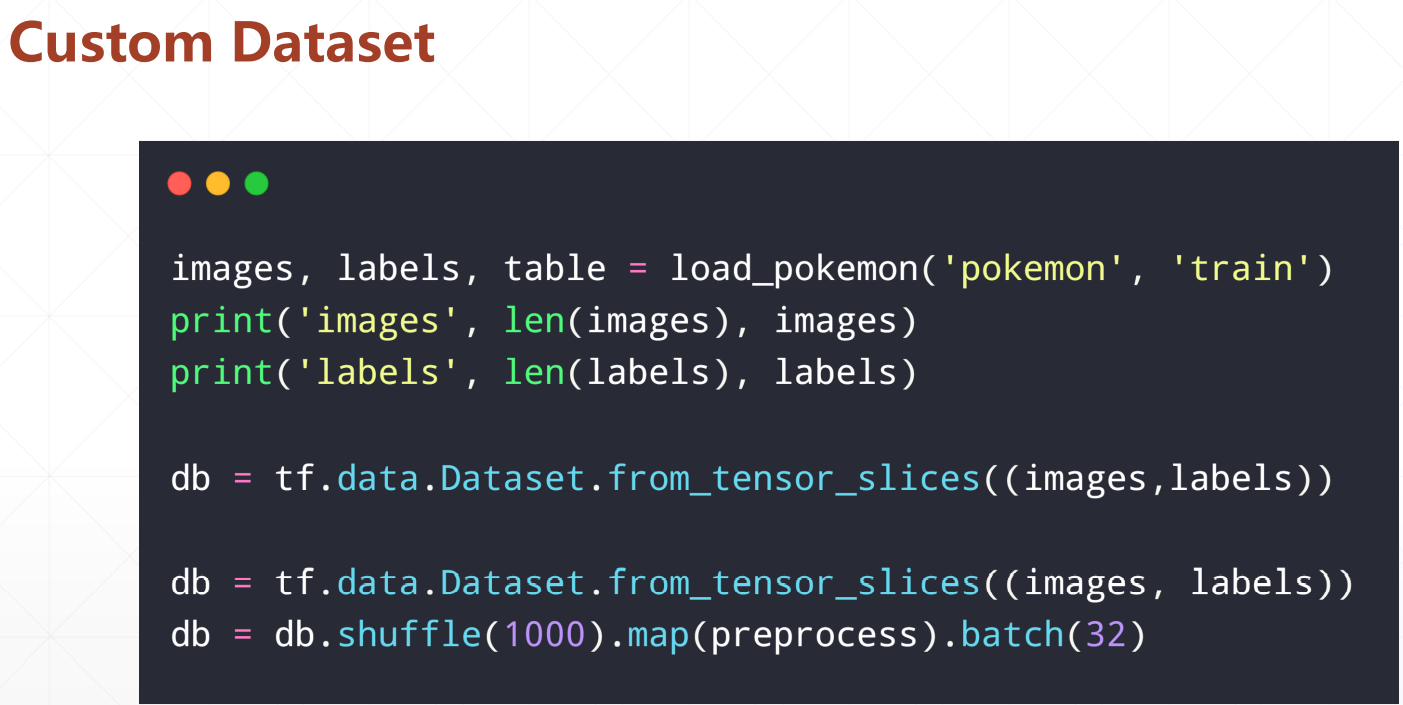
2、将数据集装载到dataset。
3、打乱,用map()函数读取图片数据。
(1) images and labels ▪ 𝑋 = [1. 𝑝𝑛𝑔, 2. 𝑝𝑛𝑔, 3. 𝑝𝑛𝑔, … ] ▪ 𝑌 = [4,9,1, … ] (2)tf.data.Dataset.from_tensor_slices((X,Y)) (3).shuffle().map(𝑓𝑢𝑛𝑐).batch()
4、map()函数如下:
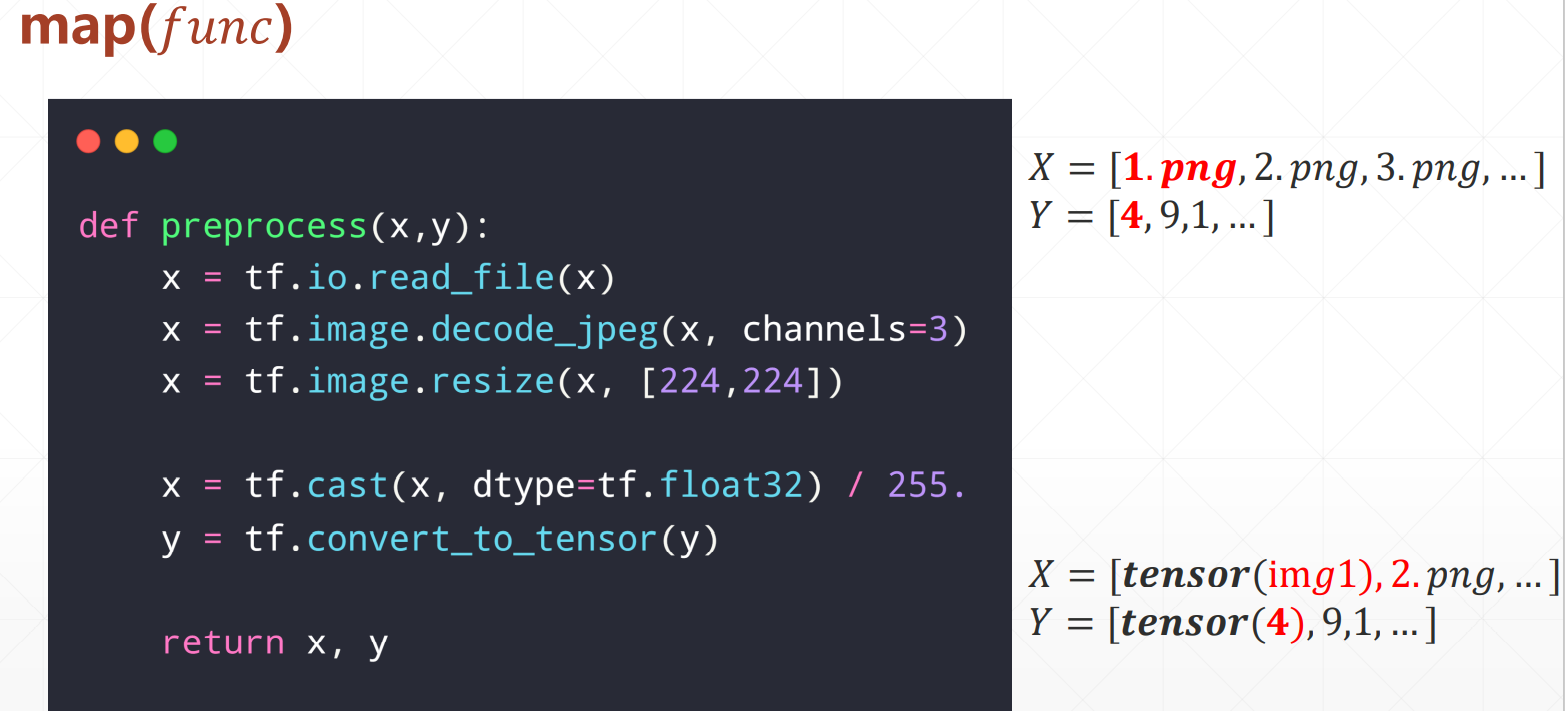
5、数据集步骤:
6、数据预处理步骤:



二、自定义数据集实战

import os, glob import random, csv import tensorflow as tf def load_csv(root, filename, name2label): # root:数据集根目录 # filename:csv文件名 # name2label:类别名编码表 if not os.path.exists(os.path.join(root, filename)): images = [] for name in name2label.keys(): # 'pokemon\\mewtwo\\00001.png images += glob.glob(os.path.join(root, name, '*.png')) images += glob.glob(os.path.join(root, name, '*.jpg')) images += glob.glob(os.path.join(root, name, '*.jpeg')) # 1167, 'pokemon\\bulbasaur\\00000000.png' print(len(images), images) random.shuffle(images) with open(os.path.join(root, filename), mode='w', newline='') as f: writer = csv.writer(f) for img in images: # 'pokemon\\bulbasaur\\00000000.png' name = img.split(os.sep)[-2] label = name2label[name] # 'pokemon\\bulbasaur\\00000000.png', 0 writer.writerow([img, label]) print('written into csv file:', filename) # read from csv file images, labels = [], [] with open(os.path.join(root, filename)) as f: reader = csv.reader(f) for row in reader: # 'pokemon\\bulbasaur\\00000000.png', 0 img, label = row label = int(label) images.append(img) labels.append(label) assert len(images) == len(labels) return images, labels def load_pokemon(root, mode='train'): # 创建数字编码表 name2label = {} # "sq...":0 for name in sorted(os.listdir(os.path.join(root))): if not os.path.isdir(os.path.join(root, name)): continue # 给每个类别编码一个数字 name2label[name] = len(name2label.keys()) # 读取Label信息 # [file1,file2,], [3,1] images, labels = load_csv(root, 'images.csv', name2label) if mode == 'train': # 60% images = images[:int(0.6 * len(images))] labels = labels[:int(0.6 * len(labels))] elif mode == 'val': # 20% = 60%->80% images = images[int(0.6 * len(images)):int(0.8 * len(images))] labels = labels[int(0.6 * len(labels)):int(0.8 * len(labels))] else: # 20% = 80%->100% images = images[int(0.8 * len(images)):] labels = labels[int(0.8 * len(labels)):] return images, labels, name2label img_mean = tf.constant([0.485, 0.456, 0.406]) img_std = tf.constant([0.229, 0.224, 0.225]) def normalize(x, mean=img_mean, std=img_std): # x: [224, 224, 3] # mean: [224, 224, 3], std: [3] x = (x - mean)/std return x def denormalize(x, mean=img_mean, std=img_std): x = x * std + mean return x def preprocess(x,y): # x: 图片的路径,y:图片的数字编码 x = tf.io.read_file(x) x = tf.image.decode_jpeg(x, channels=3) # RGBA x = tf.image.resize(x, [244, 244]) # data augmentation, 0~255 # x = tf.image.random_flip_up_down(x) x= tf.image.random_flip_left_right(x) x = tf.image.random_crop(x, [224, 224, 3]) # x: [0,255]=> 0~1 x = tf.cast(x, dtype=tf.float32) / 255. # 0~1 => D(0,1) x = normalize(x) y = tf.convert_to_tensor(y) return x, y def main(): import time images, labels, table = load_pokemon('pokemon', 'train') print('images', len(images), images) print('labels', len(labels), labels) print(table) # images: string path # labels: number db = tf.data.Dataset.from_tensor_slices((images, labels)) db = db.shuffle(1000).map(preprocess).batch(32) writter = tf.summary.create_file_writer('logs') for step, (x,y) in enumerate(db): # x: [32, 224, 224, 3] # y: [32] with writter.as_default(): x = denormalize(x) tf.summary.image('img',x,step=step,max_outputs=9) time.sleep(5) if __name__ == '__main__': main()
三、数据增强
1、在preprocess(x,y)函数加入:
# 图片缩放 # x = tf.image.resize(x, [244, 244]) # 图片旋转 # x = tf.image.rot90(x,2) # 随机水平翻转 x = tf.image.random_flip_left_right(x) # 随机竖直翻转 # x = tf.image.random_flip_up_down(x) # 图片先缩放到稍大尺寸 x = tf.image.resize(x, [244, 244]) # 再随机裁剪到合适尺寸 x = tf.image.random_crop(x, [224,224,3])
四、数据normalize
1、定义正则化函数和反正则化函数
img_mean = tf.constant([0.485, 0.456, 0.406]) img_std = tf.constant([0.229, 0.224, 0.225]) def normalize(x, mean=img_mean, std=img_std): # x: [224, 224, 3] # mean: [224, 224, 3], std: [3] x = (x - mean)/std return x def denormalize(x, mean=img_mean, std=img_std): x = x * std + mean return x
2、在preprocess(x,y)调用正则化
3、在图片显示部分调用反正则化。
五、提前停止
1、写个回调函数,其中,意思是检测'val_accuracy'连续55次都没增加0.001,就停止。
early_stopping = EarlyStopping( monitor='val_accuracy', min_delta=0.001, patience=5 )
2、放到fit里面
resnet.fit(db_train, validation_data=db_val, validation_freq=1, epochs=100,
callbacks=[early_stopping])
六、训练代码
1、train_scratch.py
import os os.environ['TF_CPP_MIN_LOG_LEVEL'] = '2' import tensorflow as tf import numpy as np from tensorflow import keras from tensorflow.keras import layers,optimizers,losses from tensorflow.keras.callbacks import EarlyStopping tf.random.set_seed(22) np.random.seed(22) assert tf.__version__.startswith('2.') # 设置GPU显存按需分配 gpus = tf.config.experimental.list_physical_devices('GPU') if gpus: try: # Currently, memory growth needs to be the same across GPUs for gpu in gpus: tf.config.experimental.set_memory_growth(gpu, True) logical_gpus = tf.config.experimental.list_logical_devices('GPU') print(len(gpus), "Physical GPUs,", len(logical_gpus), "Logical GPUs") except RuntimeError as e: # Memory growth must be set before GPUs have been initialized print(e) from pokemon import load_pokemon, normalize, denormalize from resnet import ResNet def preprocess(x,y): # x: 图片的路径,y:图片的数字编码 x = tf.io.read_file(x) x = tf.image.decode_jpeg(x, channels=3) # RGBA # 图片缩放 # x = tf.image.resize(x, [244, 244]) # 图片旋转 # x = tf.image.rot90(x,2) # 随机水平翻转 x = tf.image.random_flip_left_right(x) # 随机竖直翻转 # x = tf.image.random_flip_up_down(x) # 图片先缩放到稍大尺寸 x = tf.image.resize(x, [244, 244]) # 再随机裁剪到合适尺寸 x = tf.image.random_crop(x, [224,224,3]) # x: [0,255]=> -1~1 x = tf.cast(x, dtype=tf.float32) / 255. x = normalize(x) y = tf.convert_to_tensor(y) y = tf.one_hot(y, depth=5) return x, y batchsz = 256 # creat train db images, labels, table = load_pokemon('pokemon',mode='train') db_train = tf.data.Dataset.from_tensor_slices((images, labels)) db_train = db_train.shuffle(1000).map(preprocess).batch(batchsz) # crate validation db images2, labels2, table = load_pokemon('pokemon',mode='val') db_val = tf.data.Dataset.from_tensor_slices((images2, labels2)) db_val = db_val.map(preprocess).batch(batchsz) # create test db images3, labels3, table = load_pokemon('pokemon',mode='test') db_test = tf.data.Dataset.from_tensor_slices((images3, labels3)) db_test = db_test.map(preprocess).batch(batchsz) resnet = keras.Sequential([ layers.Conv2D(16,5,3), layers.MaxPool2D(3,3), layers.ReLU(), layers.Conv2D(64,5,3), layers.MaxPool2D(2,2), layers.ReLU(), layers.Flatten(), layers.Dense(64), layers.ReLU(), layers.Dense(5) ]) resnet = ResNet(5) resnet.build(input_shape=(4, 224, 224, 3)) resnet.summary() early_stopping = EarlyStopping( monitor='val_accuracy', min_delta=0.001, patience=5 ) resnet.compile(optimizer=optimizers.Adam(lr=1e-3), loss=losses.CategoricalCrossentropy(from_logits=True), metrics=['accuracy']) resnet.fit(db_train, validation_data=db_val, validation_freq=1, epochs=100, callbacks=[early_stopping]) resnet.evaluate(db_test)
2、resnet
import os import tensorflow as tf import numpy as np from tensorflow import keras from tensorflow.keras import layers tf.random.set_seed(22) np.random.seed(22) os.environ['TF_CPP_MIN_LOG_LEVEL'] = '2' assert tf.__version__.startswith('2.') class ResnetBlock(keras.Model): def __init__(self, channels, strides=1): super(ResnetBlock, self).__init__() self.channels = channels self.strides = strides self.conv1 = layers.Conv2D(channels, 3, strides=strides, padding=[[0,0],[1,1],[1,1],[0,0]]) self.bn1 = keras.layers.BatchNormalization() self.conv2 = layers.Conv2D(channels, 3, strides=1, padding=[[0,0],[1,1],[1,1],[0,0]]) self.bn2 = keras.layers.BatchNormalization() if strides!=1: self.down_conv = layers.Conv2D(channels, 1, strides=strides, padding='valid') self.down_bn = tf.keras.layers.BatchNormalization() def call(self, inputs, training=None): residual = inputs x = self.conv1(inputs) x = tf.nn.relu(x) x = self.bn1(x, training=training) x = self.conv2(x) x = tf.nn.relu(x) x = self.bn2(x, training=training) # 残差连接 if self.strides!=1: residual = self.down_conv(inputs) residual = tf.nn.relu(residual) residual = self.down_bn(residual, training=training) x = x + residual x = tf.nn.relu(x) return x class ResNet(keras.Model): def __init__(self, num_classes, initial_filters=16, **kwargs): super(ResNet, self).__init__(**kwargs) self.stem = layers.Conv2D(initial_filters, 3, strides=3, padding='valid') self.blocks = keras.models.Sequential([ ResnetBlock(initial_filters * 2, strides=3), ResnetBlock(initial_filters * 2, strides=1), # layers.Dropout(rate=0.5), ResnetBlock(initial_filters * 4, strides=3), ResnetBlock(initial_filters * 4, strides=1), ResnetBlock(initial_filters * 8, strides=2), ResnetBlock(initial_filters * 8, strides=1), ResnetBlock(initial_filters * 16, strides=2), ResnetBlock(initial_filters * 16, strides=1), ]) self.final_bn = layers.BatchNormalization() self.avg_pool = layers.GlobalMaxPool2D() self.fc = layers.Dense(num_classes) def call(self, inputs, training=None): # print('x:',inputs.shape) out = self.stem(inputs,training=training) out = tf.nn.relu(out) # print('stem:',out.shape) out = self.blocks(out, training=training) # print('res:',out.shape) out = self.final_bn(out, training=training) # out = tf.nn.relu(out) out = self.avg_pool(out) # print('avg_pool:',out.shape) out = self.fc(out) # print('out:',out.shape) return out def main(): num_classes = 5 resnet18 = ResNet(5) resnet18.build(input_shape=(4,224,224,3)) resnet18.summary() if __name__ == '__main__': main()
3、小样本问题:把resnet替换成小网络。
七、小样本学习之迁移学习
1、数据少,直接训练大网络可能导致不健壮,准确率不高,可以缩小网络,也可以用迁移学习。
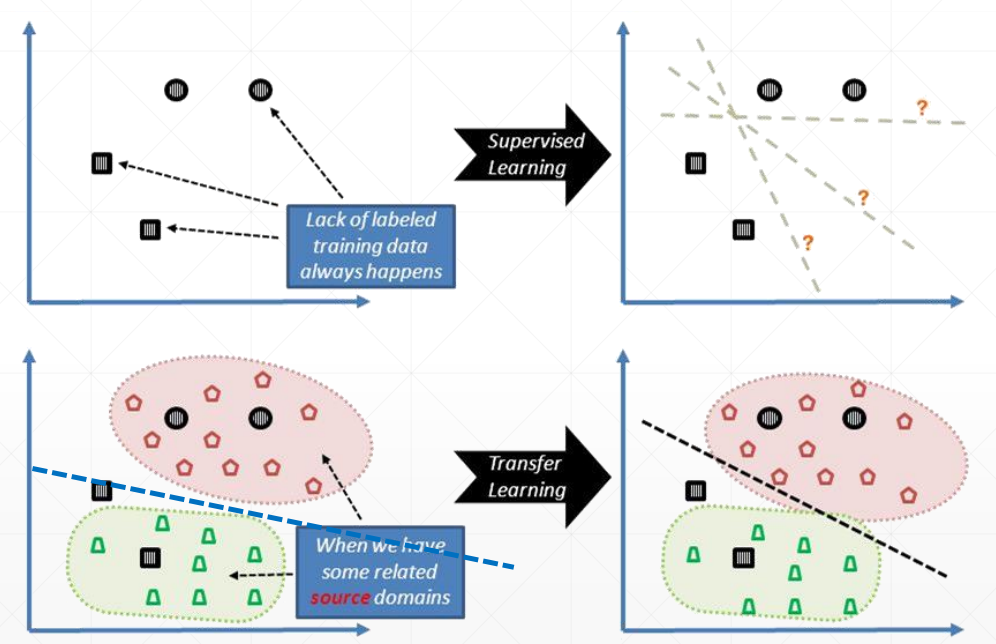
2、如图,左边是VGG19,去掉头部分类器,拿别人训练好的权值,迁移过来。迁移过来后这个大网络不需要训练,只训练头部自定义的一部分全连接层。
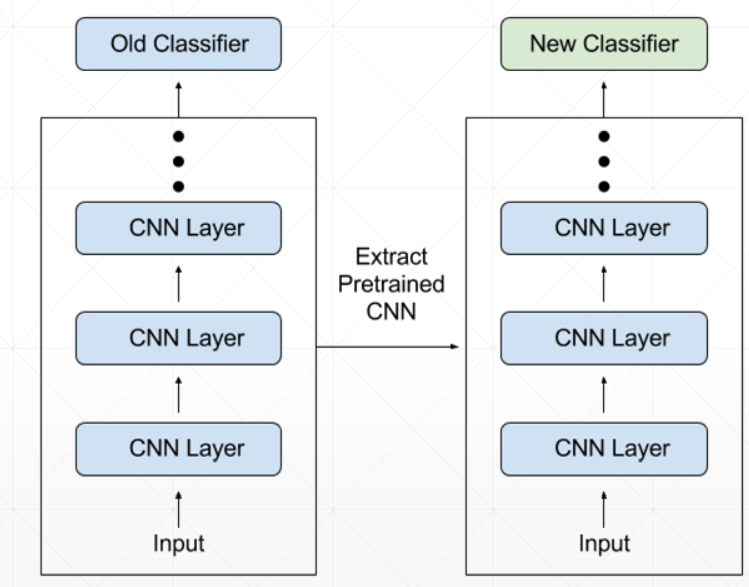
3、代码,拿过来VGG19,以及权值,去掉头部,设置下这个大网络不参与训练,重新再加个全连接层,组成新网络。
net = keras.applications.VGG19(weights='imagenet', include_top=False, pooling='max') net.trainable = False newnet = keras.Sequential([ net, layers.Dense(5) ]) newnet.build(input_shape=(4,224,224,3)) newnet.summary() early_stopping = EarlyStopping( monitor='val_accuracy', min_delta=0.001, patience=5 ) newnet.compile(optimizer=optimizers.Adam(lr=1e-3), loss=losses.CategoricalCrossentropy(from_logits=True), metrics=['accuracy']) newnet.fit(db_train, validation_data=db_val, validation_freq=1, epochs=100, callbacks=[early_stopping]) newnet.evaluate(db_test)
4、完整代码
import os import tensorflow as tf import numpy as np from tensorflow import keras from tensorflow.keras import layers import os import tensorflow as tf import numpy as np from tensorflow import keras from tensorflow.keras import layers,optimizers,losses from tensorflow.keras.callbacks import EarlyStopping tf.random.set_seed(22) np.random.seed(22) os.environ['TF_CPP_MIN_LOG_LEVEL'] = '2' assert tf.__version__.startswith('2.') from pokemon import load_pokemon,normalize def preprocess(x,y): # x: 图片的路径,y:图片的数字编码 x = tf.io.read_file(x) x = tf.image.decode_jpeg(x, channels=3) # RGBA x = tf.image.resize(x, [244, 244]) # x = tf.image.random_flip_left_right(x) x = tf.image.random_flip_up_down(x) x = tf.image.random_crop(x, [224,224,3]) # x: [0,255]=> -1~1 x = tf.cast(x, dtype=tf.float32) / 255. x = normalize(x) y = tf.convert_to_tensor(y) y = tf.one_hot(y, depth=5) return x, y batchsz = 128 # 创建训练集Datset对象 images, labels, table = load_pokemon('pokemon',mode='train') db_train = tf.data.Dataset.from_tensor_slices((images, labels)) db_train = db_train.shuffle(1000).map(preprocess).batch(batchsz) # 创建验证集Datset对象 images2, labels2, table = load_pokemon('pokemon',mode='val') db_val = tf.data.Dataset.from_tensor_slices((images2, labels2)) db_val = db_val.map(preprocess).batch(batchsz) # 创建测试集Datset对象 images3, labels3, table = load_pokemon('pokemon',mode='test') db_test = tf.data.Dataset.from_tensor_slices((images3, labels3)) db_test = db_test.map(preprocess).batch(batchsz) # net = keras.applications.VGG19(weights='imagenet', include_top=False, pooling='max') net.trainable = False newnet = keras.Sequential([ net, layers.Dense(5) ]) newnet.build(input_shape=(4,224,224,3)) newnet.summary() early_stopping = EarlyStopping( monitor='val_accuracy', min_delta=0.001, patience=5 ) newnet.compile(optimizer=optimizers.Adam(lr=1e-3), loss=losses.CategoricalCrossentropy(from_logits=True), metrics=['accuracy']) newnet.fit(db_train, validation_data=db_val, validation_freq=1, epochs=100, callbacks=[early_stopping]) newnet.evaluate(db_test)
分类:
tensorflow2基础


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 开发者必知的日志记录最佳实践
· SQL Server 2025 AI相关能力初探
· Linux系列:如何用 C#调用 C方法造成内存泄露
· AI与.NET技术实操系列(二):开始使用ML.NET
· 记一次.NET内存居高不下排查解决与启示
· 阿里最新开源QwQ-32B,效果媲美deepseek-r1满血版,部署成本又又又降低了!
· 开源Multi-agent AI智能体框架aevatar.ai,欢迎大家贡献代码
· Manus重磅发布:全球首款通用AI代理技术深度解析与实战指南
· 被坑几百块钱后,我竟然真的恢复了删除的微信聊天记录!
· 没有Manus邀请码?试试免邀请码的MGX或者开源的OpenManus吧