
tensorflow(三十一):数据分割与K折交叉验证
一、数据集分割
1、训练集、测试集
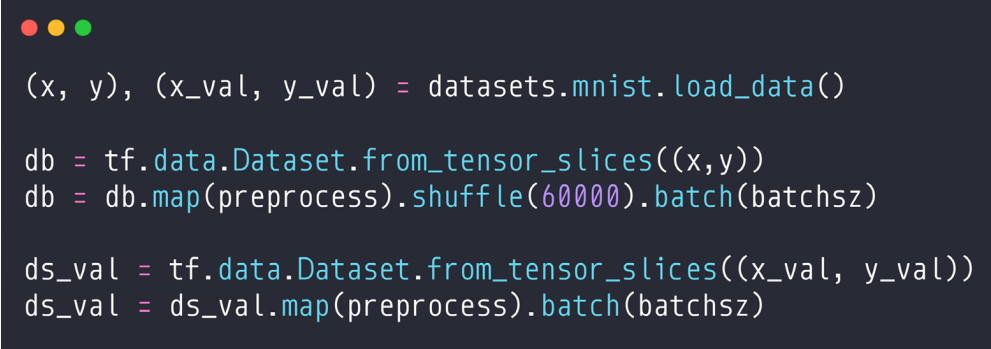
2、训练集、验证集、测试集
步骤:
(1)把训练集60K分成两部分,一部分50K,另一部分10K。
(2)组合成dataset,并打乱。
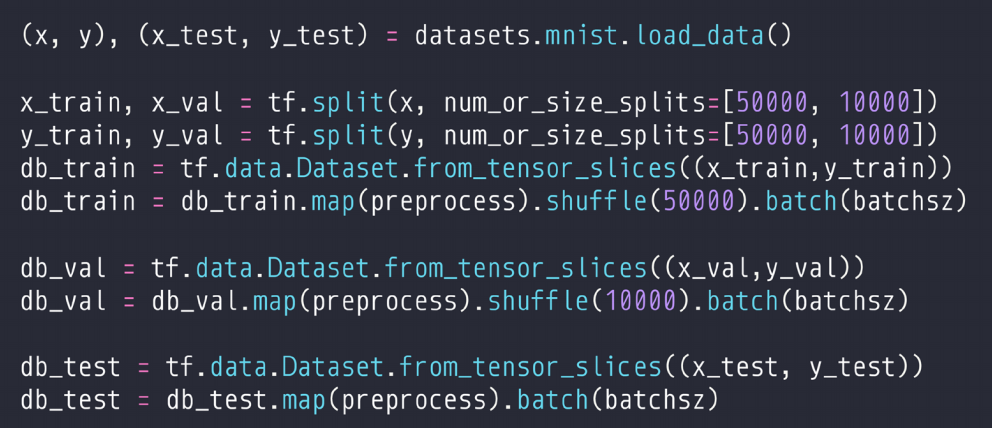
二、训练过程评估
1、训练的过程评估
其中,第二行是训练,总轮数是5,每两轮做一次评估,达到的效果好的话提前停止。
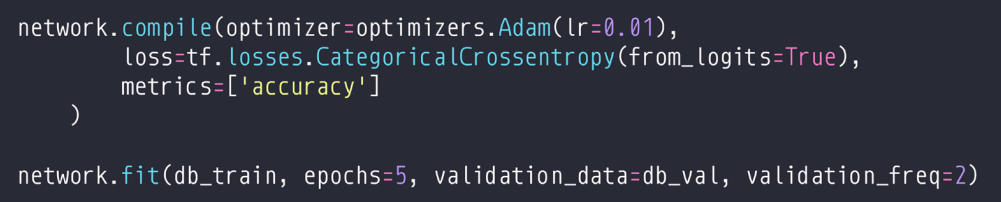
2、在测试集上再次评估

三、K折交叉验证
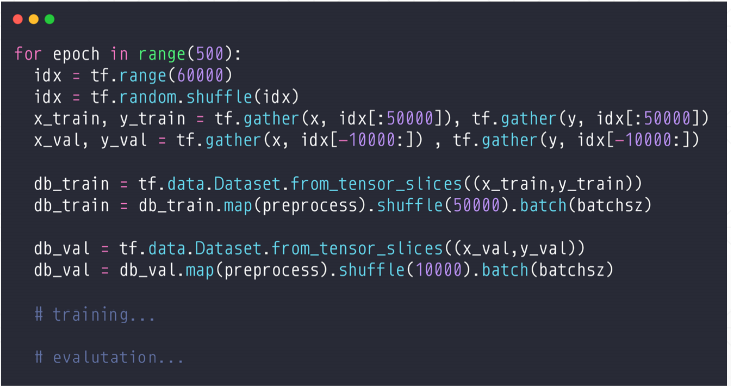
(1)第一种方式:手动
解释:每一轮训练,一共有6万数据集,首先产生1到6万的随机数,然后对随机数打散,然后前五万做训练集,后一万做测试。
(2)第二种方式:调用keras的方法。

四、实战:数据集分割
import tensorflow as tf from tensorflow.keras import datasets, layers, optimizers, Sequential, metrics def preprocess(x, y): """ x is a simple image, not a batch """ x = tf.cast(x, dtype=tf.float32) / 255. x = tf.reshape(x, [28*28]) y = tf.cast(y, dtype=tf.int32) y = tf.one_hot(y, depth=10) return x,y batchsz = 128 (x, y), (x_val, y_val) = datasets.mnist.load_data() print('datasets:', x.shape, y.shape, x.min(), x.max()) db = tf.data.Dataset.from_tensor_slices((x,y)) db = db.map(preprocess).shuffle(60000).batch(batchsz) ds_val = tf.data.Dataset.from_tensor_slices((x_val, y_val)) ds_val = ds_val.map(preprocess).batch(batchsz) sample = next(iter(db)) print(sample[0].shape, sample[1].shape) network = Sequential([layers.Dense(256, activation='relu'), layers.Dense(128, activation='relu'), layers.Dense(64, activation='relu'), layers.Dense(32, activation='relu'), layers.Dense(10)]) network.build(input_shape=(None, 28*28)) network.summary() network.compile(optimizer=optimizers.Adam(lr=0.01), loss=tf.losses.CategoricalCrossentropy(from_logits=True), metrics=['accuracy'] ) network.fit(db, epochs=5, validation_data=ds_val, validation_steps=2) network.evaluate(ds_val) sample = next(iter(ds_val)) x = sample[0] y = sample[1] # one-hot pred = network.predict(x) # [b, 10] # convert back to number y = tf.argmax(y, axis=1) pred = tf.argmax(pred, axis=1) print(pred) print(y)
五、实战:交叉验证
import tensorflow as tf from tensorflow.keras import datasets, layers, optimizers, Sequential, metrics def preprocess(x, y): """ x is a simple image, not a batch """ x = tf.cast(x, dtype=tf.float32) / 255. x = tf.reshape(x, [28*28]) y = tf.cast(y, dtype=tf.int32) y = tf.one_hot(y, depth=10) return x,y batchsz = 128 (x, y), (x_test, y_test) = datasets.mnist.load_data() print('datasets:', x.shape, y.shape, x.min(), x.max()) idx = tf.range(60000) idx = tf.random.shuffle(idx) x_train, y_train = tf.gather(x, idx[:50000]), tf.gather(y, idx[:50000]) x_val, y_val = tf.gather(x, idx[-10000:]) , tf.gather(y, idx[-10000:]) print(x_train.shape, y_train.shape, x_val.shape, y_val.shape) db_train = tf.data.Dataset.from_tensor_slices((x_train,y_train)) db_train = db_train.map(preprocess).shuffle(50000).batch(batchsz) db_val = tf.data.Dataset.from_tensor_slices((x_val,y_val)) db_val = db_val.map(preprocess).shuffle(10000).batch(batchsz) db_test = tf.data.Dataset.from_tensor_slices((x_test, y_test)) db_test = db_test.map(preprocess).batch(batchsz) sample = next(iter(db_train)) print(sample[0].shape, sample[1].shape) network = Sequential([layers.Dense(256, activation='relu'), layers.Dense(128, activation='relu'), layers.Dense(64, activation='relu'), layers.Dense(32, activation='relu'), layers.Dense(10)]) network.build(input_shape=(None, 28*28)) network.summary() network.compile(optimizer=optimizers.Adam(lr=0.01), loss=tf.losses.CategoricalCrossentropy(from_logits=True), metrics=['accuracy'] ) network.fit(db_train, epochs=6, validation_data=db_val, validation_freq=2) print('Test performance:') network.evaluate(db_test) sample = next(iter(db_test)) x = sample[0] y = sample[1] # one-hot pred = network.predict(x) # [b, 10] # convert back to number y = tf.argmax(y, axis=1) pred = tf.argmax(pred, axis=1) print(pred) print(y)

 浙公网安备 33010602011771号
浙公网安备 33010602011771号