

NLP(九):pytorch用transformer库实现BERT
一、资源
(1)预训练模型权重
链接: https://pan.baidu.com/s/10BCm_qOlajUU3YyFDdLVBQ 密码: 1upi
(2)数据集选择的THUCNews,自行下载并整理出10w条数据,内容是10类新闻文本标题的中文分类问题(10分类),每类新闻标题数据量相等,为1w条。数据集可在我的百度网盘自行下载:链接: https://pan.baidu.com/s/1Crj4ELKtW8zRnNuaAkonPA 密码: p0wj。
(3)安装
pip install transformers
(4)参考:
https://zhuanlan.zhihu.com/p/112655246
https://spaces.ac.cn/archives/6736
二、简介
由于pytorch_pretrained_bert库是transformers的老版库,不再进行更新了。所以以下对原文章代码进行了更新,换成以transformers为框架的代码,并且将打印输出设置的更加简约。本文章适用于初学者,有兴趣的可上手尝试。
----------------- 分割线 ----------------
之前用bert一直都是根据keras-bert封装库操作的,操作非常简便(可参考苏剑林大佬博客当Bert遇上Keras:这可能是Bert最简单的打开姿势),这次想要来尝试一下基于pytorch的bert实践。
最近pytorch大火,而目前很少有博客完整的给出基于pytorch的bert的应用代码,本文从最简单的中文文本分类入手,一步一步的给出每段代码~ (代码简单清晰,读者有兴趣可上手实践)
(1)首先安装transformers库, 即:pip install transformers(版本为4.4.2);
(2)然后下载预训练模型权重,这里下载的是 chinese_roberta_wwm_ext_pytorch ,下载链接为中文BERT-wwm系列模型 (这里可选择多种模型),如果下载不了,可在我的百度网盘下载:链接: https://pan.baidu.com/s/10BCm_qOlajUU3YyFDdLVBQ 密码: 1upi;
(3)数据集选择的THUCNews,自行下载并整理出10w条数据,内容是10类新闻文本标题的中文分类问题(10分类),每类新闻标题数据量相等,为1w条。数据集可在我的百度网盘自行下载:链接: https://pan.baidu.com/s/1Crj4ELKtW8zRnNuaAkonPA 密码: p0wj。
下图为数据集展示(最后10行),格式为"title \t label",标题和所属类别两列用'\t'分隔。

废话少说,下面进入代码阶段。(训练环境为Google Colab,GPU为T4,显存大约15G)
1 导入必要的库
import pandas as pd
import numpy as np
import json, time
from tqdm import tqdm
from sklearn.metrics import accuracy_score, classification_report
import torch
import torch.nn as nn
import torch.nn.functional as F
import torch.optim as optim
from torch.utils.data import TensorDataset, DataLoader, RandomSampler, SequentialSampler
from transformers import BertModel, BertConfig, BertTokenizer, AdamW, get_cosine_schedule_with_warmup
import warnings
warnings.filterwarnings('ignore')
bert_path = "bert_model/" # 该文件夹下存放三个文件('vocab.txt', 'pytorch_model.bin', 'config.json')
tokenizer = BertTokenizer.from_pretrained(bert_path) # 初始化分词器2 预处理数据集
input_ids, input_masks, input_types, = [], [], [] # input char ids, segment type ids, attention mask
labels = [] # 标签
maxlen = 30 # 取30即可覆盖99%
with open("news_title_dataset.csv", encoding='utf-8') as f:
for i, line in tqdm(enumerate(f)):
title, y = line.strip().split('\t')
# encode_plus会输出一个字典,分别为'input_ids', 'token_type_ids', 'attention_mask'对应的编码
# 根据参数会短则补齐,长则切断
encode_dict = tokenizer.encode_plus(text=title, max_length=maxlen,
padding='max_length', truncation=True)
input_ids.append(encode_dict['input_ids'])
input_types.append(encode_dict['token_type_ids'])
input_masks.append(encode_dict['attention_mask'])
labels.append(int(y))
input_ids, input_types, input_masks = np.array(input_ids), np.array(input_types), np.array(input_masks)
labels = np.array(labels)
print(input_ids.shape, input_types.shape, input_masks.shape, labels.shape)输出:(27秒,速度较快)
100000it [00:27, 3592.75it/s]
(100000, 30) (100000, 30) (100000, 30) (100000,)
3 切分训练集、验证集和测试集
# 随机打乱索引
idxes = np.arange(input_ids.shape[0])
np.random.seed(2019) # 固定种子
np.random.shuffle(idxes)
print(idxes.shape, idxes[:10])
# 8:1:1 划分训练集、验证集、测试集
input_ids_train, input_ids_valid, input_ids_test = input_ids[idxes[:80000]], input_ids[idxes[80000:90000]], input_ids[idxes[90000:]]
input_masks_train, input_masks_valid, input_masks_test = input_masks[idxes[:80000]], input_masks[idxes[80000:90000]], input_masks[idxes[90000:]]
input_types_train, input_types_valid, input_types_test = input_types[idxes[:80000]], input_types[idxes[80000:90000]], input_types[idxes[90000:]]
y_train, y_valid, y_test = labels[idxes[:80000]], labels[idxes[80000:90000]], labels[idxes[90000:]]
print(input_ids_train.shape, y_train.shape, input_ids_valid.shape, y_valid.shape,
input_ids_test.shape, y_test.shape)输出:

4加载到高效的DataLoader
BATCH_SIZE = 64 # 如果会出现OOM问题,减小它
# 训练集
train_data = TensorDataset(torch.LongTensor(input_ids_train),
torch.LongTensor(input_masks_train),
torch.LongTensor(input_types_train),
torch.LongTensor(y_train))
train_sampler = RandomSampler(train_data)
train_loader = DataLoader(train_data, sampler=train_sampler, batch_size=BATCH_SIZE)
# 验证集
valid_data = TensorDataset(torch.LongTensor(input_ids_valid),
torch.LongTensor(input_masks_valid),
torch.LongTensor(input_types_valid),
torch.LongTensor(y_valid))
valid_sampler = SequentialSampler(valid_data)
valid_loader = DataLoader(valid_data, sampler=valid_sampler, batch_size=BATCH_SIZE)
# 测试集(是没有标签的)
test_data = TensorDataset(torch.LongTensor(input_ids_test),
torch.LongTensor(input_masks_test),
torch.LongTensor(input_types_test))
test_sampler = SequentialSampler(test_data)
test_loader = DataLoader(test_data, sampler=test_sampler, batch_size=BATCH_SIZE)5 定义bert模型
# 定义model
class Bert_Model(nn.Module):
def __init__(self, bert_path, classes=10):
super(Bert_Model, self).__init__()
self.config = BertConfig.from_pretrained(bert_path)
self.bert = BertModel.from_pretrained(bert_path)
self.fc = nn.Linear(self.config.hidden_size, classes) # 直接分类
def forward(self, input_ids, attention_mask=None, token_type_ids=None):
outputs = self.bert(input_ids, attention_mask, token_type_ids)
out_pool = outputs[1] # 池化后的输出
logit = self.fc(out_pool)
return logit可以发现,bert模型的定义由于高效简易的封装库存在,使得定义模型较为容易,如果想要在bert之后加入cnn/rnn等层,可在这里定义。
6 实例化bert模型
def get_parameter_number(model):
# 打印模型参数
total_num = sum(p.numel() for p in model.parameters())
trainable_num = sum(p.numel() for p in model.parameters() if p.requires_grad)
return 'Total parameters: {}, Trainable parameters: {}'.format(total_num, trainable_num)
DEVICE = torch.device("cuda" if torch.cuda.is_available() else "cpu")
EPOCHS = 5
model = Bert_Model(bert_path).to(DEVICE)
print(get_parameter_number(model))输出:Total parameters: 102275338, Trainable parameters: 102275338
7 定义优化器
optimizer = AdamW(model.parameters(), lr=2e-5, weight_decay=1e-4) #AdamW优化器
scheduler = get_cosine_schedule_with_warmup(optimizer, num_warmup_steps=len(train_loader),
num_training_steps=EPOCHS*len(train_loader))
# 学习率先线性warmup一个epoch,然后cosine式下降。8 定义训练函数和验证测试函数
# 评估模型性能,在验证集上
def evaluate(model, data_loader, device):
model.eval()
val_true, val_pred = [], []
with torch.no_grad():
for idx, (ids, att, tpe, y) in (enumerate(data_loader)):
y_pred = model(ids.to(device), att.to(device), tpe.to(device))
y_pred = torch.argmax(y_pred, dim=1).detach().cpu().numpy().tolist()
val_pred.extend(y_pred)
val_true.extend(y.squeeze().cpu().numpy().tolist())
return accuracy_score(val_true, val_pred) #返回accuracy
# 测试集没有标签,需要预测提交
def predict(model, data_loader, device):
model.eval()
val_pred = []
with torch.no_grad():
for idx, (ids, att, tpe) in tqdm(enumerate(data_loader)):
y_pred = model(ids.to(device), att.to(device), tpe.to(device))
y_pred = torch.argmax(y_pred, dim=1).detach().cpu().numpy().tolist()
val_pred.extend(y_pred)
return val_pred
def train_and_eval(model, train_loader, valid_loader,
optimizer, scheduler, device, epoch):
best_acc = 0.0
patience = 0
criterion = nn.CrossEntropyLoss()
for i in range(epoch):
"""训练模型"""
start = time.time()
model.train()
print("***** Running training epoch {} *****".format(i+1))
train_loss_sum = 0.0
for idx, (ids, att, tpe, y) in enumerate(train_loader):
ids, att, tpe, y = ids.to(device), att.to(device), tpe.to(device), y.to(device)
y_pred = model(ids, att, tpe)
loss = criterion(y_pred, y)
optimizer.zero_grad()
loss.backward()
optimizer.step()
scheduler.step() # 学习率变化
train_loss_sum += loss.item()
if (idx + 1) % (len(train_loader)//5) == 0: # 只打印五次结果
print("Epoch {:04d} | Step {:04d}/{:04d} | Loss {:.4f} | Time {:.4f}".format(
i+1, idx+1, len(train_loader), train_loss_sum/(idx+1), time.time() - start))
# print("Learning rate = {}".format(optimizer.state_dict()['param_groups'][0]['lr']))
"""验证模型"""
model.eval()
acc = evaluate(model, valid_loader, device) # 验证模型的性能
if acc > best_acc:
best_acc = acc
torch.save(model.state_dict(), "best_bert_model.pth")
print("current acc is {:.4f}, best acc is {:.4f}".format(acc, best_acc))
print("time costed = {}s \n".format(round(time.time() - start, 5)))9 开始训练和验证模型
# 训练和验证评估
train_and_eval(model, train_loader, valid_loader, optimizer, scheduler, DEVICE, EPOCHS)输出:(训练时间较长,500s左右一个epoch,这里只训练了2个epoch,验证集便得到了0.9680的accuracy)
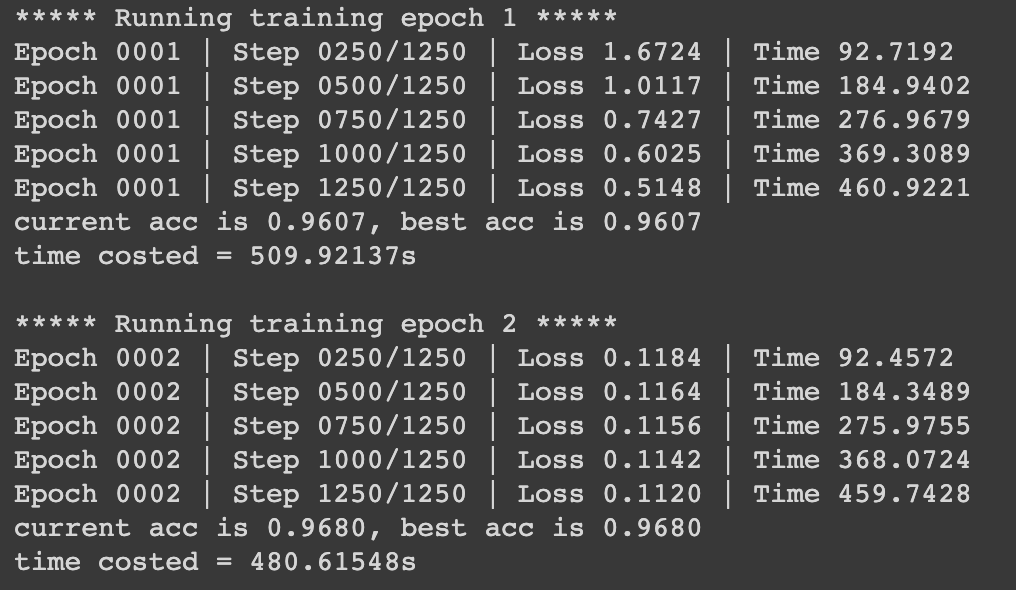
10 加载最优模型进行测试
# 加载最优权重对测试集测试
model.load_state_dict(torch.load("best_bert_model.pth"))
pred_test = predict(model, test_loader, DEVICE)
print("\n Test Accuracy = {} \n".format(accuracy_score(y_test, pred_test)))
print(classification_report(y_test, pred_test, digits=4))输出:测试集准确率为96.72%
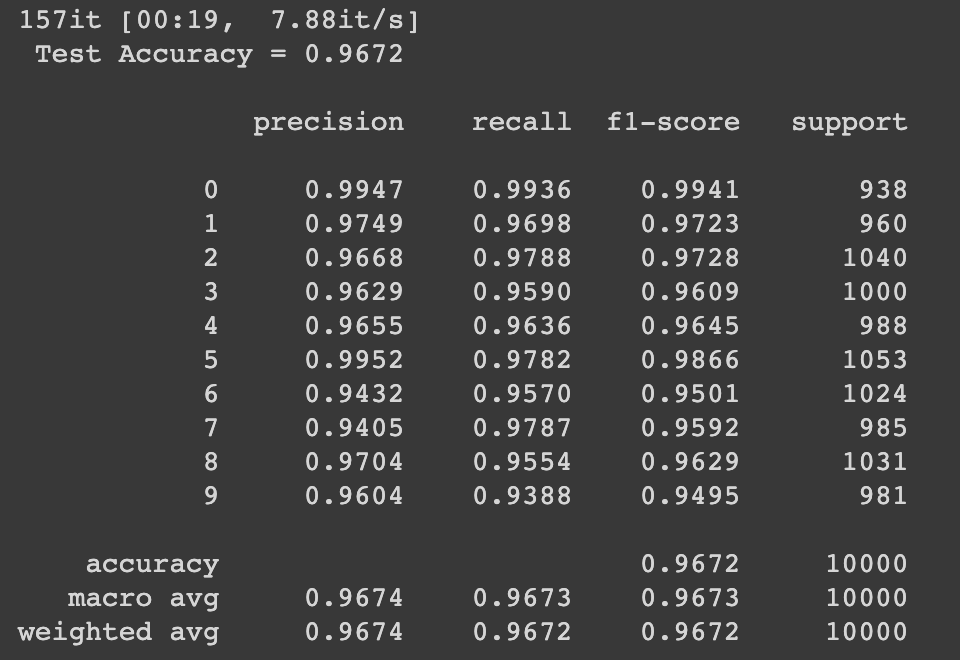
------------------------------------
经过以上10步,即可建立起较为完整的基于pytorch的bert文本分类体系,代码也较为简单易懂,对读者有帮助记得点个赞支持一下呀~
-完结-


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 开发者必知的日志记录最佳实践
· SQL Server 2025 AI相关能力初探
· Linux系列:如何用 C#调用 C方法造成内存泄露
· AI与.NET技术实操系列(二):开始使用ML.NET
· 记一次.NET内存居高不下排查解决与启示
· 阿里最新开源QwQ-32B,效果媲美deepseek-r1满血版,部署成本又又又降低了!
· 开源Multi-agent AI智能体框架aevatar.ai,欢迎大家贡献代码
· Manus重磅发布:全球首款通用AI代理技术深度解析与实战指南
· 被坑几百块钱后,我竟然真的恢复了删除的微信聊天记录!
· 没有Manus邀请码?试试免邀请码的MGX或者开源的OpenManus吧