

opensips压力测试论文
Approach to stress tests in SIP environment based on marginal analysis
摘要
在性能度量和SIP(会话初始协议)代理和B2BUA(背对背用户代理)的度量领域,尚未提出标准化的方法。 这种差距导致确定硬件存在问题,其性能将具有成本效益,并且足以在给定环境中运行SIP服务器。 如今的实践依赖于管理员对电话基础架构需求的技能和经验。 因此,基于SIP的VoIP技术的使用日益增加,这是创建一种方法的主要原因,该方法将使管理员可以精确地测量SIP服务器性能并将其与其他软件和硬件平台进行比较。 这项工作还利用SIP Server性能测量来比较使用转码和不使用转码时的结果,并提供独立比较B2BUA平台的方法。
1、介绍
如今,电信业正在发生巨大的发展变化。 所有这些变化都是通过融合网络概念的不断实施以及向下一代网络的进一步过渡而得出的。在这些网络中,SIP为构建完整的电信解决方案提供了基础。 由于将SIP协议集成到下一代网络的概念,因此该协议的实现现在很普遍。 这导致对方法和工具的需求不断增长,这些方法和工具可用于确定所选硬件是否具有足够的性能来满足给定环境的所有需求,并为将来的扩展提供一些备用资源。 但是,如今,仅通过专有解决方案就可以满足这种需求,一方面需要特殊的硬件,另一方面却不能提供与某些竞争解决方案可比的结果。
2、现有技术
想要执行VoIP基础结构性能分析的管理员不能依靠清晰的方法。该领域尚未发布任何标准,有一些草案,其主要焦点是性能测试的术语和方法[1-3]。这些草稿仍在开发中,但是在过去的一年中,尽管发布这些草稿的新版本的活动有所增加,但几乎没有进行任何外观上的更改,特别是[1]。这表明性能测试的主题越来越重要,并且基本术语和方法的标准化工作的大部分已经完成。根据给定的论据以及结果的未来一致性,应执行这些草案。从方法论的角度来看,可以从IT公司Transnexus白皮书[4,5]的白皮书中介绍的测试场景中获得一些好的想法。尽管这些论文有些过时,但是所介绍的方法可以很好地启发我们。 Transnexus在其测试平台中使用了开源测试工具SIPp [6],该工具可生成高SIP负载并测量单个SIP呼叫的关键参数。这使SIPp成为SIP性能测试的理想选择。
3、方法
尽管Transnexus的基准测试模型在我们方法开发的早期阶段就受到了启发,但仍缺乏标准化的努力。它们测量某些关键消息的发送和接收之间的时间(例如,邀请,100尝试,180振铃),但是他们的方法并不将这些消息视为SIP事务的一部分。这导致输出,用户无法从中读取系统的更复杂属性。更具体地说,您可以了解SIP服务器能够多快地响应您的消息,但不能了解它可以处理并重新发送到目的地的速度。另一方面,我们的方法使之成为可能,因此识别SIP服务器的“真实世界”参数(例如呼叫建立长度(后来称为SRD-会话请求延迟))不是问题。从实用的角度来看,Transnexus的模型过于复杂。作为商业主题,Transnexus专注于创建将利用其某些商业产品的模型,这导致他们使用其管理和计费平台,这需要另外两台单独的计算机。从我们的角度来看,创建尽可能简单的测试平台是有益的,这将使其更易于在任何实际环境中进行部署。这就是为什么我们决定不使用任何其他特殊硬件,而是仅通过侦听的UAS(用户代理服务器)来模拟呼叫的结束位置的原因,这是由于我们希望评估SIP服务器具有以下能力:成功连接主叫方和被叫方。
3.1、测量参数
对于所有测量,我们均采用IETF草案[1]中定义的参数,但除此以外,我们还使用硬件利用率参数。 现在,让我们看看测量这些参数组的位置。 第一组在UAC(用户代理客户端)处进行度量,并包括呼叫统计信息,例如(不成功的)呼叫数和特定事务中消息交换的持续时间。 此处还捕获了用于分析的RTP(实时传输协议)样本。 第二组-硬件利用率参数-直接在SIP服务器上测量。 在此测量CPU和内存的利用率以及网络流量。 所有测得参数的列表包括CPU利用率,内存利用率,(不成功的)呼叫次数,注册请求延迟和会话请求延迟(SRD),它们在图1中进行了描述,最后还包括平均抖动和最大RTP延迟。

3.2、结果分析中的极限定义
先前定义的参数不足以评估SIP服务器的性能。为了能够从收集的数据中确定SIP服务器的性能,我们需要为每种测量参数类别定义极限值。此定义必须来自SIP协议的功能以及IP和经典电话的公认惯例。从硬件利用率的特征来看,CPU利用率在SIP服务器的性能分析中起着主要作用。由于CPU在计算机体系结构中的重要性以及常规SIP服务器体系结构中面向CPU的操作,因此此结论是合乎逻辑的。我们在CPU使用率特征中搜索达到最大CPU使用率的第一点。这就是从硬件性能的角度来看SIP服务器可以处理的最大呼叫数。 SIP延迟特性RRD(注册请求延迟)和SRD的限制定义来自SIP协议的性质[11]。
3.3、SIP代理测试
在SIP代理的基本配置中,我们只能测量SIP和利用率参数。 RTP流不流经SIP代理,因此不代表它的负载。这就是为什么我们不必考虑通话时长的原因,因为无论通话多长时间,硬件利用率都是相同的,因此衡量SIP代理的唯一合适指标是每秒(或任何其他时间)产生的通话次数间隔)。 SIP代理上的每个度量都包括几个步骤。每一步大约需要16分钟,这意味着在15分钟内,将以用户定义的呼叫速率生成10秒长的呼叫。然后有10秒的时间结束未完成的呼叫。对于通话费率的每个步骤,都会重复此步骤。多次提到的10秒长时间间隔是由于合理的呼叫长度和每秒产生尽可能多的呼叫的需要之间的折衷。它可以提供不错的性能,并且不需要庞大的订户数据库。该时间间隔可以更改,但不能超过2.5分钟,以允许收集有效数据。尽管不能将这种情况视为端到端,但仍对SRD进行了测量,此条件在草稿[1]中定义。
3.4、B2BUA测试
与此类SIP服务器的SIP代理不同,RTP流在SIP服务器上呈现最高的负载,因此必须将同时呼叫的数量用作指标。这是B2BUA和SIP代理测试方案之间的主要区别。第二个不太重要的区别(从方法论的角度来看)是,在此配置中,我们要测量转码的有效性,因为在这种情况下,B2BUA的性能不仅受其设置的影响,还受UAC和UAS配置的影响。然后针对不同编解码器设置的每种情况重复测试例程。但是,测试方法几乎相同,我们面临的唯一问题是新指标以及修改单个呼叫时间间隔的需求。当无法命令SIP流量生成器创建一定数量的同时呼叫时,新指标就是一个问题。在这种情况下,有必要计算每秒产生的呼叫数。这可以通过以下关系完成:

CR是设置的呼叫速率,CS是我们要生成的同时呼叫的数量,T是定义呼叫(媒体)应该持续多长时间的时间间隔。 在我们的测量中,用于B2BUA的时间间隔设置为60秒,因为大多数呼叫都具有该长度,但是同样可以更改此参数。 该测试过程中获得的结果是我们将所有其他结果相关联的基础。 该关系在(3.2)中表示为性能比。 性能额定因子PRF是在一定数量的同时呼叫的情况下在转码情况(PCT)中测得的任何先前提及的参数与在没有转码和相同负载的情况下所采用的相同参数(P)的值之比。
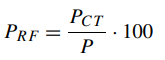
此步骤使我们可以独立比较硬件和平台的结果。
4、实现
所提出的方法可以几种方式实施。 我们的方法尝试利用任何环境中存在的硬件。 作为SIP流量生成器和数据收集器,我们使用已经提到的程序SIPp。 作为硬件利用率监视工具,我们决定使用系统活动报告器(SAR)。
4.1、测试拓扑
SIP服务器代表始终与SIP注册器和SIP代理或B2BUA(背对背用户代理)相关的一组服务器。 对于中小企业(中小企业)和LE(大型企业)而言,后者是企业环境中最常用的解决方案。 图2描绘了用于测试SIP代理(Opensips)和B2BUA(两个不同版本的Asterisk PBX)的测试硬件配置[8,9]。这是一种常规配置,不能反映用于我们测量的测试平台的所有方面。 首先,我们同时使用物理计算机和虚拟计算机来模拟SIP流量。 两种配置的结果几乎相同,从而使该方法的未来用户可以根据可用硬件来决定最适合他的拓扑。
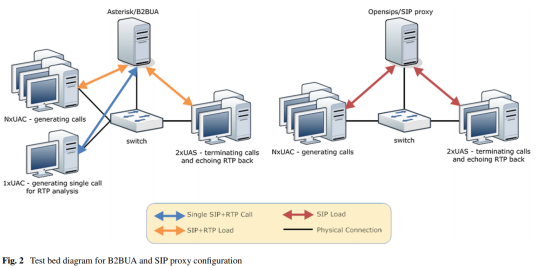
4.2、管理
测试的有效性和准确性取决于计算机之间的时间和过程同步[10]。 为了实现这种同步,将其中一台计算机选为控制器。 我们知道在SIPp IMS Bench网站[7]上介绍的管理计算机模型,在该模型中,仅一台计算机专用于测试的主管,但我们决定采用另一种方法。我们将控制器机制集成到了一台UAC计算机上。 这台计算机然后被称为“主UAC”,除了测试监督之外,它还处理和存储结果。由于使用了非常简单的算法(如图3所示),这种集成才成为可能。
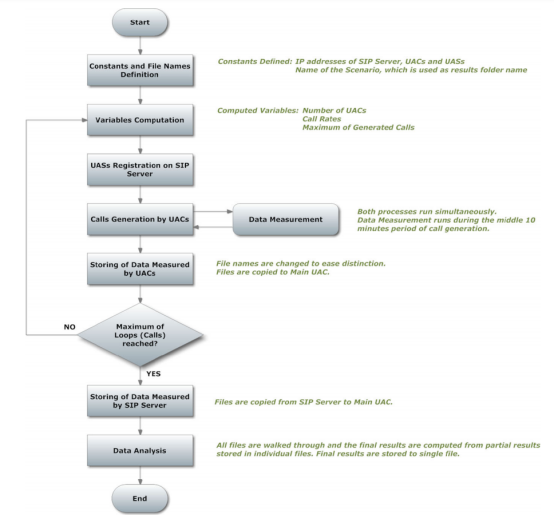
如图3所示,两个进程的冲突仅发生一次。正在进行呼叫生成时会进行数据测量。但是,这种冲突并不代表问题,因为所有UAC上的数据测量均由SIPp本身提供,并在启动时指示执行测量。另一方面,SIP服务器上的数据测量是由SAR提供的,并且只有在启动时间间隔到期之后,因此,在测试过程中会在主UAC上创建额外的负载,这会影响结果,除非采取一些应对措施被执行。这个问题的解决方法很简单。在测试的启动过程中,将通过指令在SIP服务器上调用数据测量,以延迟命令的执行,以恰好克服初始时间间隔,否则结果将不准确。从上面提到的很明显,实际上并不需要在单独的计算机上实现管理程序功能,因此可以简化测试拓扑并提高计算机使用的效率。整个算法以bash脚本的形式实现,该脚本执行所有必需的计算服务,并将命令从主UAC传递到拓扑中的每台计算机。
4.3、呼叫产生
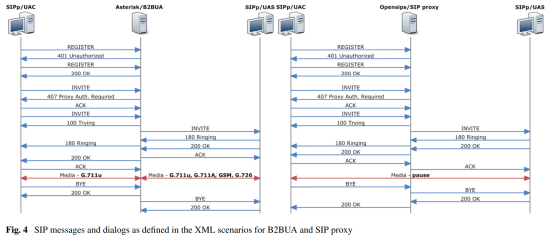
SIPp生成的整个SIP对话框可以通过XML场景由用户定义。这些方案准确地定义了SIP对话框的外观以及各个SIP消息的结构。 B4BUA和SIP代理测试所使用的场景以易于阅读的形式显示在图4中。除这种情况外,还需要告知SIPp应该使用什么SIP帐户信息。为此,我们使用csv格式的数据库文件,因为这是如何将大量信息传递到SIPp的唯一方法。 SIPp不能自行生成媒体流,因此需要记录的pcap文件。在UAC的侧面,使用了pcap文件,其录制的歌曲长度为PCM u-law格式的60 s。接收方UAS接受此媒体流并回传原样,从而使呼叫中出现第二个媒体流。当然,这仅适用于B2BUA方案。当SIP代理代替SIP服务器时,不会生成任何媒体流,并且其位置需要10秒的长暂停间隔。媒体或暂停间隔结束后,使用BYE方法进行标准呼叫终止。每次调用都会重复此过程。
4.4、数据收集
数据收集操作在我们的实施中包括三个要素:SAR,SIPp和Tshark。有关SIP服务器硬件利用率的数据由System Activity Reporter收集,由bash命令调用,然后作为守护程序服务在后台运行,该守护程序按固定的时间间隔收集数据。除了业务量生成之外,SIPp还测量并存储有关SIP消息交换长度的信息,因此,它可用于测量定义的参数RRD和SRD。除此之外,有关已创建呼叫总数和成功呼叫数目的信息也由SIPp度量。这些数据以文本格式存储在每台UAC计算机上,并且主UAC在测试方案的每个步骤(循环)结束时下载并重命名这些文件。为了获得信息,在我们的实现中使用了有关RTP流Tshark的信息。在B2BUA测试方案的每个测试步骤(循环)期间,将在一台专用计算机上生成一个呼叫,并将其转发到B2BUA。然后,它将像处理其他任何呼叫一样处理该呼叫。然后,媒体流由UAS回送,并在通过B2BUA之后再次转发回其源。
4.5、SIP服务
作为B2BUA,我们使用Asterisk PBX,并且作为我们决定使用Opensips的SIP代理,我们将SW平台用作GNU / Debian 5.0.1 x86,Asterisk PBX 1.6.2.0、1.6.2.9和Opensips 1.6.0。 硬件平台CPU AMD Athlon 64 X2 5200、4 GB DDR2 RAM 800 MHz,芯片组nVidia nForce 570-SLI。
5、结果
本章的主要部分集中于两个版本的Asterisk SW的性能比较:Asterisk 1.6.2.0和Asterisk 1.6.2.9。
5.1、B2BUA
对于每个类别,都有两个不同的图表。 第一个显示没有编解码器转换的情况下的结果,并用蓝色显示,第二个显示通过将收集的数据插入到(3.2)公式中获得的归一化值。
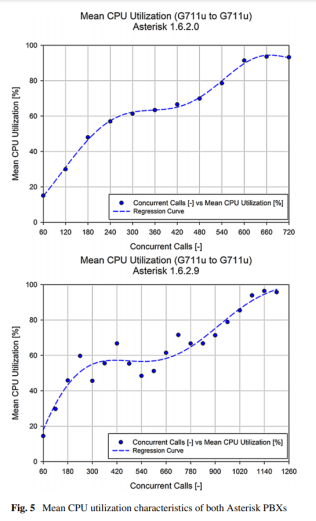
5.1.1平均CPU利用率
最初令人惊讶的结果来自性能分析的开始。尽管两个版本的Asterisk都来自同一分支,但旧版本在600个同时调用时达到了最大CPU使用率,而较新的Asterisk可以处理几乎两倍的负载(图5中为1100个调用,比较600个调用)。
可以在转码有效性中找到另一个令人惊讶的数据。虽然对于Asterisk 1.6.2.0而言,在与G.726编解码器之间进行转换时要测量最重的负载,但较新的Asterisk在GSM编解码器方面存在更多困难,这使G.726和GSM编解码器的编解码器转换效率比相似。 G711-A编解码器使用较新版本的Asterisk会消耗更多性能,但可用于更多同时呼叫(图6)。
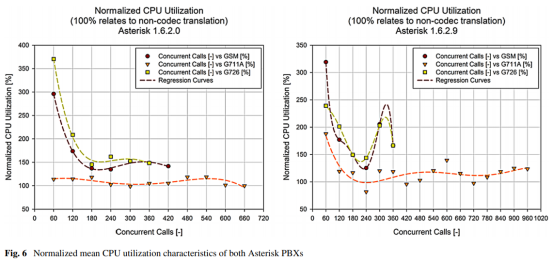
为了更容易地解释结果,在所有图片上还绘制了回归曲线。该曲线表示测量数据的趋势,并且是确定实际结果的最简单方法。
5.1.2、RRD(注册请求延迟)和SRD(会话请求延迟)延迟
与上一节一样,在测量RRD和SRD时遇到了一些有趣的事情。 新版本的Asterisk的性能明显优于旧版本。 虽然Asterisk 1.6.2.0的限制接近600个并发呼叫,但Asterisk 1.6.2.9最多可以处理1080个并发呼叫,尽管在540个并发呼叫后,这两个特性都显着增加。 但是,这种增加幅度不足以引起通信故障(图7)。

通过这些参数测得的编解码器有效性可确认先前所述的信息。 两个星号之间的显着区别只是,新的星号可以处理的同时呼叫数量更多(图8)。

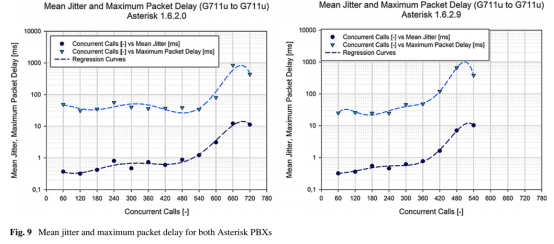
5.1.3、平均抖动和最大数据包延迟
这些特性(图9)最终是最大的惊喜。 然而,到目前为止,新版本的Asterisk有望提高性能,到目前为止,RTP数据包处理远低于预期。 新Asterisk的问题屏障似乎位于420个同时呼叫附近,在此屏障之后,两个参数都迅速增加,丢包成为一个大问题,这使得Asterisk 1.6.2.9无法在此负载下使用。
5.2、SIP代理
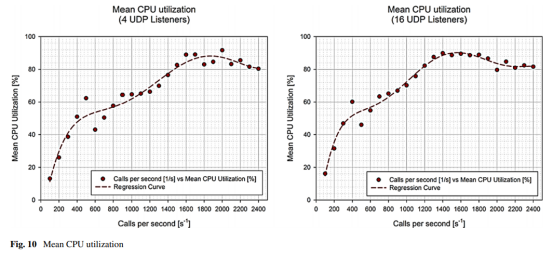
这种情况比B2BUA要简单得多。测量的唯一输出是原始数据,描述了SIP代理处理每秒生成的呼叫数量增加的能力,但是SER体系结构的所有代表都允许用户设置侦听子进程的数量,并且该数量应该(理论上) )也会影响SIP代理的性能。因此,所有测量都是在UDP侦听器的数量分别为4和16的情况下进行的。结果并不令人惊讶,除了每秒产生600个呼叫时出现的峰值。这些数据没有缺陷,因为在同一区域中多次测量相似的峰值,因此很可能是由SIP代理的呼叫处理机制引起的。从两个图表中可以明显看出,增加的UDP侦听器数量不会对SIP代理的性能产生积极影响。相反,具有16个侦听器的CPU利用率与将SIP代理子处理为4个侦听器的性能相当,负载大约增加了150个呼叫。这可能是由于CPU的性能不足所致,它无法实时处理增加的进程数,并导致延误。
5.2.1、平均CPU利用率
在图10所示的两个图表中,我们可以看到值的波动和达到最大负载后趋势特性的缓慢下降。 这些波动每次都会出现,并且是由超出最大合理负载的随机故障数引起的。 可以通过大量的重复测量来减少这些波动,但它们不会影响最终结果分析,因此,在两次测量之后,图表以原始形式显示。
5.2.2、RRD和SRD延迟
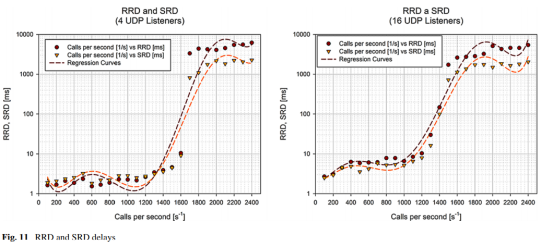
从SIP角度来看,情况类似于从CPU利用率统计信息得出的情况。 同样,子进程的数量对SIP代理的整体性能有负面影响。 当子进程数设置为16时,RRD和SRD延迟大约高2-3倍。此外,两个特性(RRD和SRD)的巨大飞跃出现在大约200个呼叫之前(图11)。
6、结论
本文介绍的SIP基础结构测试和基准测试方法旨在对SIP元素进行基准测试。它允许用户确定系统的最大负载,显示系统的动态变化特性,例如响应时间和数据包延迟。决定应在特定环境中安装哪个系统很有用[13-16]。
从提供的数据可以了解到:
•B2BUA在任何上述配置中可以处理的最大同时呼叫数。
•SIP代理每秒可以处理的最大呼叫数。
•B2BUA的转码效率。
从呈现的结果中,我们发现配置中的Asterisk服务器可以处理大约600个呼叫,而没有使用编解码器转换。如果存在转码,则使用GSM和G.726编解码器时,此数字将大大减少到一半。在我们的案例中,由Opensips实施的SIP代理确认了期望并达到了高负载,而其每秒大约1600个呼叫的限制没有问题。


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 开发者必知的日志记录最佳实践
· SQL Server 2025 AI相关能力初探
· Linux系列:如何用 C#调用 C方法造成内存泄露
· AI与.NET技术实操系列(二):开始使用ML.NET
· 记一次.NET内存居高不下排查解决与启示
· 阿里最新开源QwQ-32B,效果媲美deepseek-r1满血版,部署成本又又又降低了!
· 开源Multi-agent AI智能体框架aevatar.ai,欢迎大家贡献代码
· Manus重磅发布:全球首款通用AI代理技术深度解析与实战指南
· 被坑几百块钱后,我竟然真的恢复了删除的微信聊天记录!
· 没有Manus邀请码?试试免邀请码的MGX或者开源的OpenManus吧