

pytorch(十八):激活函数与GPU加速
一、激活函数

二、实例
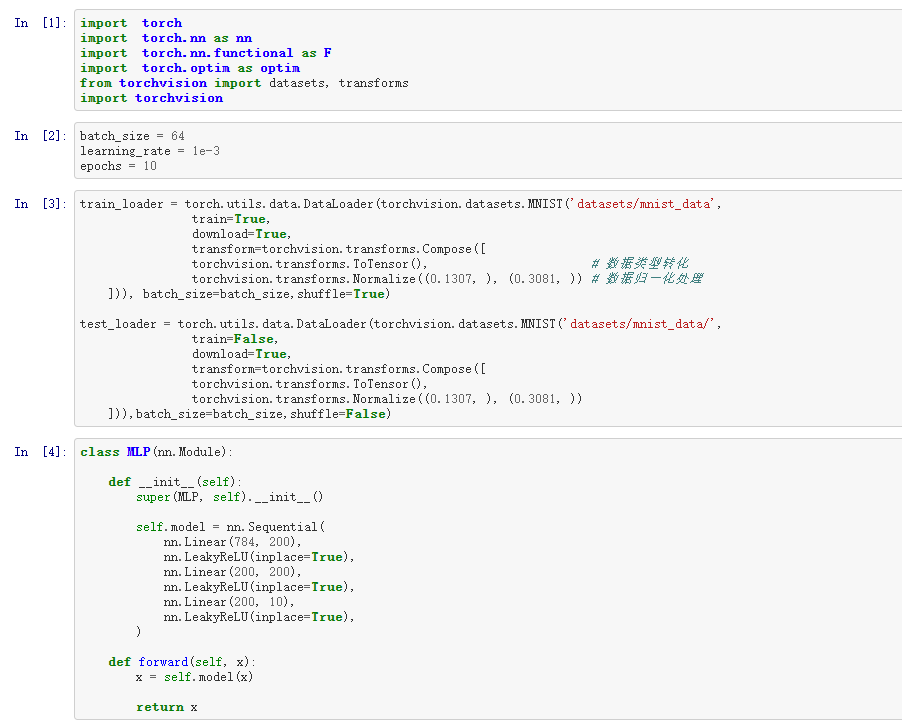
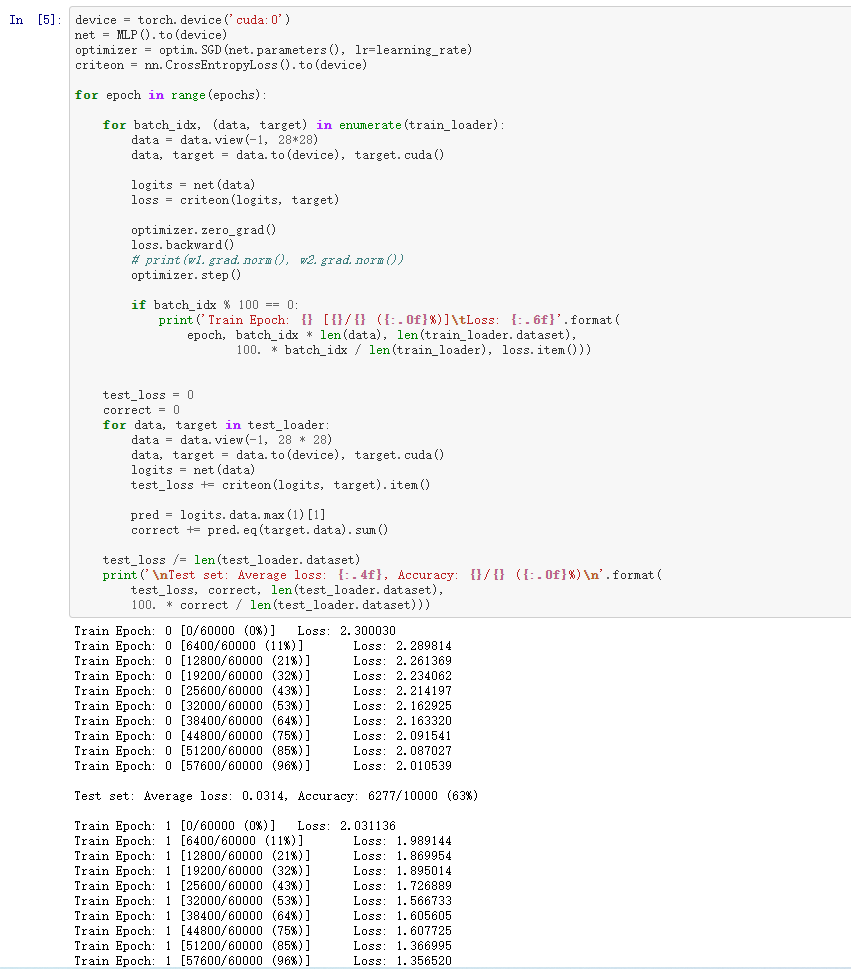
三、具体代码

import torch import torch.nn as nn import torch.nn.functional as F import torch.optim as optim from torchvision import datasets, transforms import torchvision batch_size = 64 learning_rate = 1e-3 epochs = 10 train_loader = torch.utils.data.DataLoader(torchvision.datasets.MNIST('datasets/mnist_data', train=True, download=True, transform=torchvision.transforms.Compose([ torchvision.transforms.ToTensor(), # 数据类型转化 torchvision.transforms.Normalize((0.1307, ), (0.3081, )) # 数据归一化处理 ])), batch_size=batch_size,shuffle=True) test_loader = torch.utils.data.DataLoader(torchvision.datasets.MNIST('datasets/mnist_data/', train=False, download=True, transform=torchvision.transforms.Compose([ torchvision.transforms.ToTensor(), torchvision.transforms.Normalize((0.1307, ), (0.3081, )) ])),batch_size=batch_size,shuffle=False) class MLP(nn.Module): def __init__(self): super(MLP, self).__init__() self.model = nn.Sequential( nn.Linear(784, 200), nn.LeakyReLU(inplace=True), nn.Linear(200, 200), nn.LeakyReLU(inplace=True), nn.Linear(200, 10), nn.LeakyReLU(inplace=True), ) def forward(self, x): x = self.model(x) return x device = torch.device('cuda:0') net = MLP().to(device) optimizer = optim.SGD(net.parameters(), lr=learning_rate) criteon = nn.CrossEntropyLoss().to(device) for epoch in range(epochs): for batch_idx, (data, target) in enumerate(train_loader): data = data.view(-1, 28*28) data, target = data.to(device), target.cuda() logits = net(data) loss = criteon(logits, target) optimizer.zero_grad() loss.backward() # print(w1.grad.norm(), w2.grad.norm()) optimizer.step() if batch_idx % 100 == 0: print('Train Epoch: {} [{}/{} ({:.0f}%)]\tLoss: {:.6f}'.format( epoch, batch_idx * len(data), len(train_loader.dataset), 100. * batch_idx / len(train_loader), loss.item())) test_loss = 0 correct = 0 for data, target in test_loader: data = data.view(-1, 28 * 28) data, target = data.to(device), target.cuda() logits = net(data) test_loss += criteon(logits, target).item() pred = logits.data.max(1)[1] correct += pred.eq(target.data).sum() test_loss /= len(test_loader.dataset) print('\nTest set: Average loss: {:.4f}, Accuracy: {}/{} ({:.0f}%)\n'.format( test_loss, correct, len(test_loader.dataset), 100. * correct / len(test_loader.dataset)))
分类:
pytorch基础


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 开发者必知的日志记录最佳实践
· SQL Server 2025 AI相关能力初探
· Linux系列:如何用 C#调用 C方法造成内存泄露
· AI与.NET技术实操系列(二):开始使用ML.NET
· 记一次.NET内存居高不下排查解决与启示
· 阿里最新开源QwQ-32B,效果媲美deepseek-r1满血版,部署成本又又又降低了!
· 开源Multi-agent AI智能体框架aevatar.ai,欢迎大家贡献代码
· Manus重磅发布:全球首款通用AI代理技术深度解析与实战指南
· 被坑几百块钱后,我竟然真的恢复了删除的微信聊天记录!
· 没有Manus邀请码?试试免邀请码的MGX或者开源的OpenManus吧