


自定义模块
-
自定义模块
-
模块的两种执行方式
-
name``file , all
-
模块导入的多种方式
-
相对导入
-
random:
-
random.random():
-
random.uniform(a,b):
-
random.randint(a,b):
-
random.shuffle(x):
-
random.sample(x,k):
-
常用模块的介绍:
-
time,datetime
-
os,sys
-
hashlib,json,pickle,collections
封装了获取时间戳和字符串形式的时间的一些方法。
-
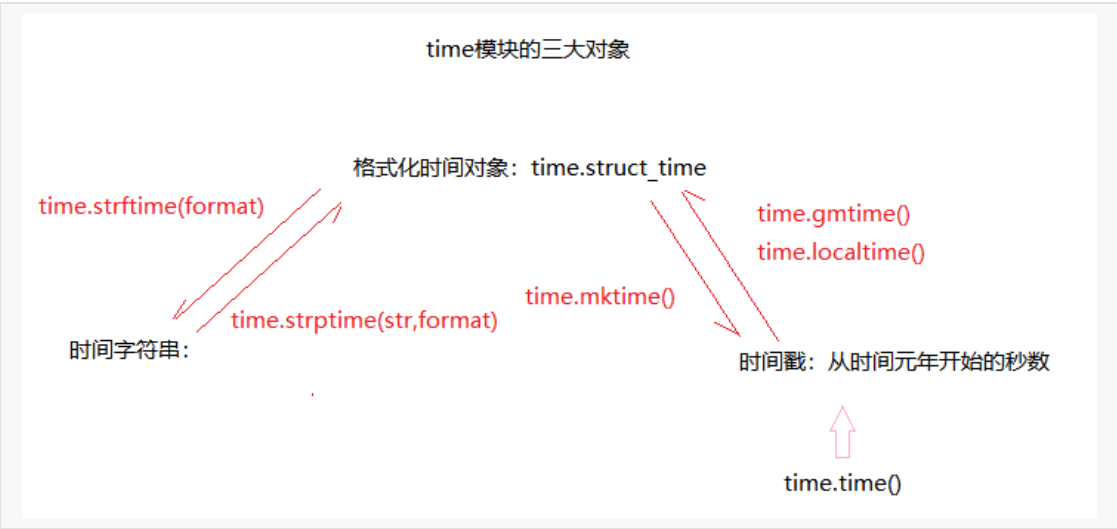
time.time():获取时间戳
-
time.gmtime([seconds]):获取格式化时间对象:是九个字段组成的
-
time.localtime([seconds]):获取格式化时间对象:是九个字段组成的
-
time.mktime(t):时间对象 -> 时间戳
-
time.strftime(format[,t]):把时间对象格式化成字符串
-
time.strptime(str,format):把时间字符串转换成时间对象
1 import time 2 3 # 获取时间戳 4 5 # 时间戳:从时间元年(1970 1 1 00:00:00)到现在经过的秒数。 6 7 # print(time.time()) # 1558314075.7787385 1558314397.275036# 获取格式化时间对象:是九个字段组成的。 8 9 # 默认参数是当前系统时间的时间戳。 10 11 # print(time.gmtime()) # GMT: 12 13 # print(time.localtime()) 14 15 # print(time.gmtime(1)) # 时间元年过一秒后,对应的时间对象 16 17 # 时间对象 -> 时间戳 18 19 # t1 = time.localtime() # 时间对象 20 21 # t2 = time.mktime(t1) # 获取对应的时间戳 22 23 # print(t2) 24 25 # print(time.time()) 26 27 # 格式化时间对象和字符串之间的转换 28 29 # s = time.strftime("year:%Y %m %d %H:%M:%S") 30 31 # print(s) 32 33 # 把时间字符串转换成时间对象 34 35 # time_obj = time.strptime('2010 10 10','%Y %m %d') 36 37 # print(time_obj)
其他方法:
-
time.sleep(x):休眠x秒.
datetime:日期时间相关
包含了和日期时间相关的类.主要有:
-
date:需要年,月,日三个参数
-
time:需要时,分,秒三个参数
-
datetime:需要年,月,日,时,分,秒六个参数.
-
timedelta:需要一个时间段.可以是天,秒,微秒.
获取以上类型的对象,主要作用是和时间段进行数学运算.
timedelta可以和以下三个类进行数学运算:
-
datetime.time,datetime.datetime,datetime.timedelta
练习:
-
显示当前日期前三天是什么时间.
-
显示任意一年的二月份有多少天.
1 # 普通算法:根据年份计算是否是闰年.是:29天,否:28 2 3 # 用datetime模块. 4 5 # 首先创建出指定年份的3月1号.然后让它往前走一天. 6 7 year = int(input("输入年份:")) 8 9 # 创建指定年份的date对象 10 11 d = datetime.date(year,3,1) 12 13 # 创建一天 的时间段 14 15 td = datetime.timedelta(days=1) 16 17 res = d - td 18 19 print(res.day)
和操作系统相关的模块,主要是文件删除,目录删除,重命名等操作.
1 import os 2 3 # 和文件操作相关,重命名,删除 4 5 # os.remove('a.txt') 6 7 # os.rename('a.txt','b.txt') 8 9 # 删除目录,必须是空目录 10 11 # os.removedirs('aa') 12 13 # 使用shutil模块可以删除带内容的目录 14 15 # import shutil 16 17 # shutil.rmtree('aa') 18 19 # 和路径相关的操作,被封装到另一个子模块中:os.path# res = os.path.dirname(r'd:/aaa/bbb/ccc/a.txt') # 不判断路径是否存在. 20 21 # print(res) 22 23 # 24 25 # # 获取文件名 26 27 # res = os.path.basename(r'd:/aaa/bbb/ccc/a.txt') 28 29 # print(res) 30 31 # 把路径中的路径名和文件名切分开,结果是元组. 32 33 # res = os.path.split(r'd:/aaa/bbb/ccc/a.txt') 34 35 # print(res) 36 37 # 拼接路径 38 39 # path = os.path.join('d:\','aaa','bbb','ccc','a.txt') 40 41 # print(path) 42 43 # 如果是/开头的路径,默认是在当前盘符下. 44 45 # res = os.path.abspath(r'/a/b/c') 46 47 # 如果不是以/开头,默认当前路径 48 49 # res = os.path.abspath(r'a/b/c') 50 51 # print(res) 52 53 # 判断 54 55 # print(os.path.isabs('a.txt')) 56 57 # print(os.path.isdir('d:/aaaa.txt')) # 文件不存在.False 58 59 # print(os.path.exists('d:/a.txt')) 60 61 # print(os.path.isfile('d:/asssss.txt')) # 文件不存在.False
sys模块
和解释器操作相关的模块.
主要两个方面:
-
解释器执行时获取参数:sys.argv[x]
-
解释器执行时寻找模块的路径:sys.path
例如:有a.py内容如下:
1 import sys 2 print('脚本名称:',sys.argv[0]) 3 print('第一个参数:',sys.argv[1]) 4 print('第二个参数:',sys.argv[2])
使用脚本方式运行:
1 python a.py hello world
json模块
JavaScript Object Notation:java脚本兑现标记语言.
已经成为一种简单的数据交换格式.
序列化:将其他数据格式转换成json字符串的过程.
反序列化:将json字符串转换其他数据类型的过程.
涉及到的方法:
-
json.dumps(obj):将obj转换成json字符串返回到内存中.
-
json.dump(obj,fp):将obj转换成json字符串并保存在fp指向的文件中.
-
json.loads(s):将内存中的json字符串转换成对应的数据类型对象
-
json.load(f):从文件中读取json字符串,并转换回原来的数据类型.
注意:
-
json并不能序列化所有的数据类型:例如:set.
-
元组数据类型经过json序列化后,变成列表数据类型.
-
json文件通常是一次性写入,一次性读取.但是可以利用文件本身的方式实现:一行存储一个序列化json字符串, 在反序列化时,按行反序列化即可.
内存中的数据:结构化的数据
磁盘上的数据:线性数据.
序列化比喻:
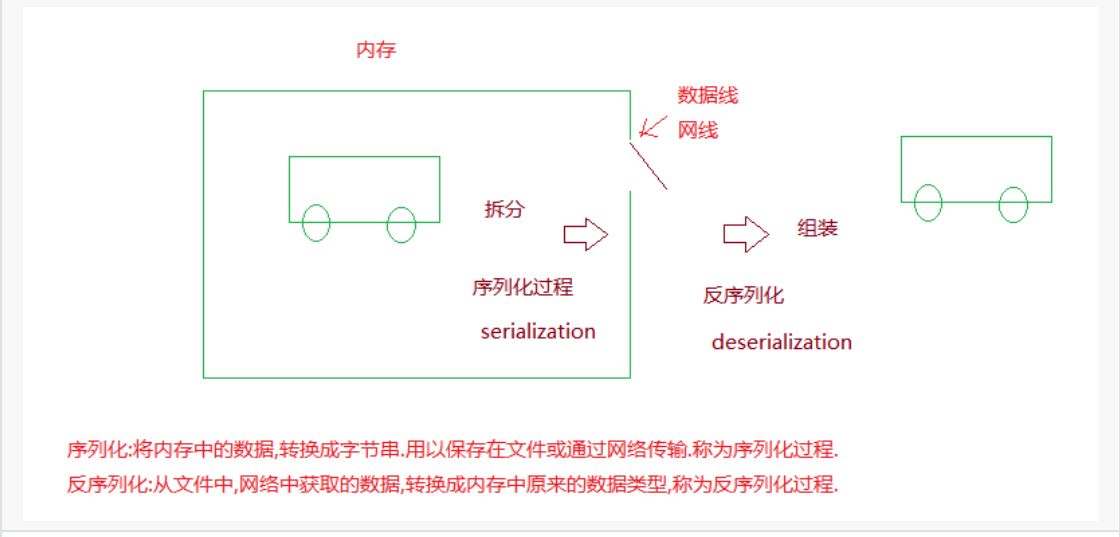
pickle模块
python专用的序列化模块.
和json的方法一致.区别在于:
1 json: 2 1.不是所有的数据类型都可以序列化.结果是字符串. 3 2.不能多次对同一个文件序列化. 4 3.json数据可以跨语言 5 6 pickle: 7 1.所有python类型都能序列化,结果是字节串. 8 2.可以多次对同一个文件序列化 9 3.不能跨语言.
hashlib模块
封装一些用于加密的类.
md5(),...
加密的目的:用于判断和验证,而并非解密.
特点:
-
把一个大的数据,切分成不同块,分别对不同的块进行加密,再汇总的结果,和直接对整体数据加密的结果是一致 的.
-
单向加密,不可逆.
-
原始数据的一点小的变化,将导致结果的非常大的差异,'雪崩'效应.
1 # 注册,登录程序: 2 def get_md5(username, passwd): 3 m = hashlib.md5() 4 m.update(username.encode('utf-8')) 5 m.update(passwd.encode('utf-8')) 6 return m.hexdigest() 7 8 9 def register(username, passwd): 10 # 加密 11 res = get_md5(username, passwd) 12 # 写入文件 13 with open('login', mode='at',encoding='utf-8') as f: 14 f.write(res) 15 f.write('\n') 16 17 18 def login(username, passwd): 19 # 获取当前登录信息的加密结果 20 res = get_md5(username, passwd) 21 # 读文件,和其中的数据进行对比 22 with open('login', mode='rt', encoding='utf-8') as f: 23 for line in f: 24 if res == line.strip(): 25 return True 26 else: 27 return False 28 29 while True: 30 op = int(input("1.注册 2.登录 3.退出")) 31 if op == 3 : 32 break 33 elif op == 1: 34 username = input("输入用户名:") 35 passwd = input("输入密码:") 36 register(username,passwd) 37 elif op == 2: 38 username = input("输入用户名:") 39 passwd = input("输入密码:") 40 res = login(username,passwd) 41 if res: 42 print('登录成功') 43 else: 44 print('登录失败')
不同的加密对象,结果长度不同,长度越长,越耗时.常用的是md5.
总结
-
自定义模块
-
random
-
time
-
datetime
-
os
-
sys
-
json,pickle
-
hashlib
