KMP字符串匹配
KMP字符串匹配算法
引入
在OI中,我们通常会碰到这样的问题
给出两个字符串 \(s_1\) 和 \(s_2\),若 \(s_1\) 的区间 \([l,r]\) 子串与 \(s_2\) 完全相同,则称 \(s_2\) 在 \(s_1\) 中出现了,其出现位置为 \(l\)。
现在请你求出 \(s_1\)在 \(s_2\) 中所有出现的位置。
我们可以用暴力的两重循环来做这个问题。
但是我们看一下题目的数据范围:\(|s_1|,|s_2| \leq 10^6\)
暴力肯定过不了,怎么办呢
1.分析暴力算法
我们来看一下暴力算法是怎么慢的。(多图警告)
原来长这样
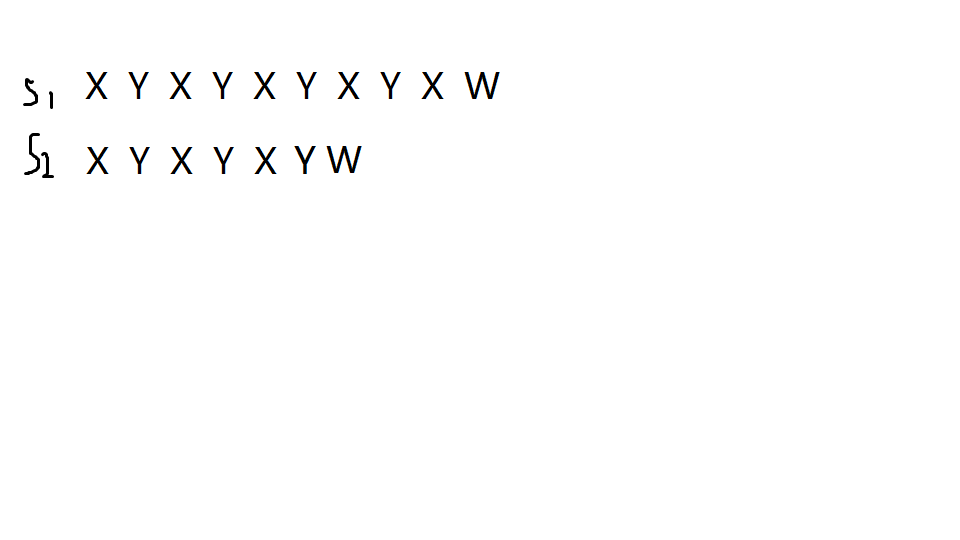
我们的暴力算法发现这个匹配不上,于是就变成了这样
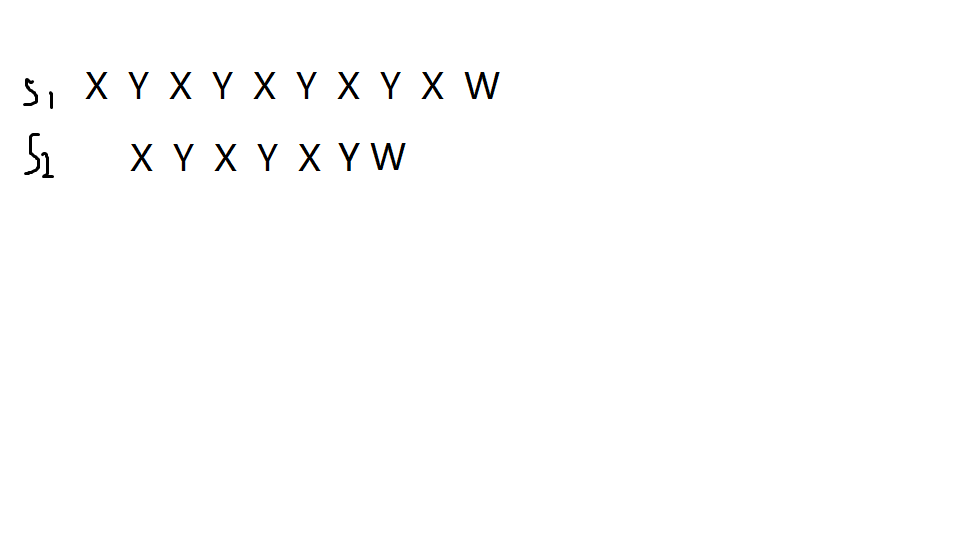
这明显不可以
于是我们就必须话费很多的时间来检查,暴力算法自然就很慢了。
这个算法慢就在于它必须把\(s_2\)串一个一个位置的移动
2.优化暴力算法
我们可以很自然的想到让\(s_2\)串在失配之后一次性多移动一点位置
这就是KMP算法的思想
现在我们来看一下失配时的情况,可以发现一个奇妙的性质
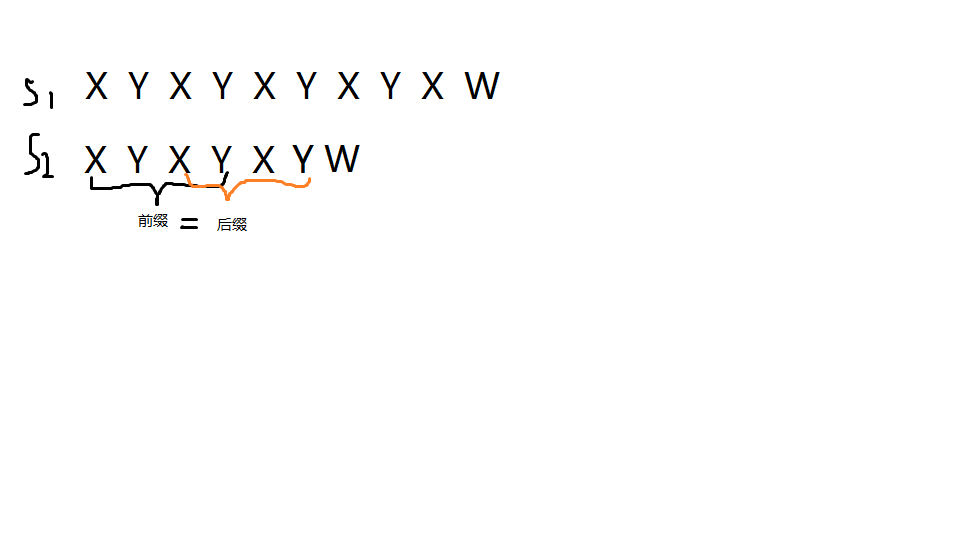
它的前缀和后缀是相等的!!!(注意,这里的前缀和后缀不包括字符串本身)
我们想一下这样的情况怎么优化。
我们可以吧它的字符串开头直接移动到相同的后缀那里去。
为什么这样是正确的呢?因为这个字符串的前缀和后缀是相同的,我们这样一顿操作,它的前缀就变到了原来后缀的位置,我们就可以在刚刚的那个位置继续匹配,从而节省时间
3.实现
说了这么多,我们又出现了一个问题,这个怎么快速求出来。
我们这是定义一个\(next_i\)数组,代表\(s_2\)的前\(i\)位(也就是\(s_2\)的\([0,i-1]\))中最长的前缀和后缀相等时后缀的开头的位置。
这时候我们就将\(s_2\)自己匹配自己,这样用\(O(n)\)就求出了\(next\)数组
想想看为什么可以这么做......
talk is cheap, show you the code
void getNext(string s2) //求nxt数组, 把目标串s2当作主串,把s2的前缀当作目标串进行匹配
{
nxt[0] = -1; //-1并没有特殊的意义,下标跳到-1说明目标串第一个字符就跟主串不匹配
int i = 0, j = -1; // i表示最长公共后缀的末位下标, j表示最长公共前缀的末尾下标
while(i < len2)
{
if(j == -1 || s2[i] == s2[j])
{
i++;
j++;
nxt[i] = j;
}
else //当前缀与后缀的末尾下标不匹配时,前缀的末位下标跳转至
{
j = nxt[j];
}
}
return ;
}
这就是KMP算法的核心代码。之后就很简单了。
这道题就是一个模板题,直接开淦
#include<iostream>
#include<string>
using namespace std;
int nxt[1000005];
int len1, len2;
void getNext(string s2) //求nxt数组, 把目标串s2当作主串,把s2的前缀当作目标串进行匹配
{
nxt[0] = -1; //-1并没有特殊的意义,下标跳到-1说明目标串第一个字符就跟主串不匹配
int i = 0, j = -1; // i表示最长公共后缀的末位下标, j表示最长公共前缀的末尾下标
while(i < len2)
{
if(j == -1 || s2[i] == s2[j])
{
i++;
j++;
nxt[i] = j;
}
else //当前缀与后缀的末尾下标不匹配时,前缀的末位下标跳转至
{
j = nxt[j];
}
}
return ;
}
void KMP(string s1, string s2) //匹配函数,输出s2在s1中出现的下标
{
getNext(s2); //nxt数组
int i = 0, j = 0; //i表示s1的下标, j表示s2的下标
while(i < len1)
{
if(j == len2 - 1 && s1[i] == s2[j]) //找到目标串
{
cout << i - j + 1 << endl; //输出目标串在s1中出现的起始位置 ,题目下标从1开始
j = nxt[j];
}
if(j == -1 || s1[i] == s2[j]) //j == -1目标串第一个字符就不匹配,跟主串的下一个字符开始匹配
{
i++;
j++;
}
else //失配
{
j = nxt[j];
}
}
return;
}
int main()
{
string s1, s2;
cin >> s1 >> s2;
len1 = s1.size();
len2 = s2.size();
KMP(s1, s2);
for(int i = 1; i <= len2; i++) //P3375要求的是没有右移过的nxt数组,所以直接从下标1开始输出
{
cout << nxt[i] << " ";
}
return 0;
}
直接A掉。
4.扩展
洛谷P4824 [USACO15FEB]Censoring S
这个题的难点在于删除了字符串之后两端的字符可能会重新组成一个目标串,但是我们不能每次重新求一次\(next\)数组。
怎么办呢???
我们不能每次都重新求一下\(next\)一波,我们只能利用之前的\(next\)。
其实这个\(next\)在删掉了原串之后还是能用的!!!关键在于我们要找到在\(i\)扫描到删掉的字符串前面的那个字符的时候,\(j\)为多少。
这是我们定义\(match_i\)代表在\(s_1\)的第\(i\)位对应的\(j\),在我们的解法中\(match_i=j+1\)这样就很舒服了
对于删除操作,我们用一个栈来记录当前存在的所有字符的下标,我们匹配完了之后就将栈顶的\(len_2\)个元素弹出,这样就可以在\(O(1)\)的时间来删除这些字符。
这份代码和之前的差不多,注释没有加了,相信大家能看得懂上面的解析
#include <bits/stdc++.h>
using namespace std;
string s1, s2;
int len1, len2;
int nxt[1000005];
void getnext(string s2)
{
nxt[0] = -1;
int i = 0, j = -1;
while(i < len2)
{
if(j == -1 || s2[i] == s2[j])
{
i ++; j ++;
nxt[i] = j;
}
else
{
j = nxt[j];
}
}
}
int stk[1000005], top, match[1000005];
void KMP(string s1, string s2)
{
getnext(s2);
int i = 0, j = 0;
while(i < len1)
{
if(j == -1 || s1[i] == s2[j])
{
match[i] = j + 1;
stk[++ top] = i;
i ++;
j ++;
}
else
j = nxt[j];
if(j == len2)
{
top -= len2;
j = match[stk[top]];
}
}
}
int main()
{
cin >> s1 >> s2;
len1 = s1.size();
len2 = s2.size();
KMP(s1, s2);
for(int i = 1; i <= top; i ++)
cout << s1[stk[i]];
return 0;
}
直接A掉!!!
例题CF1200E Compress Words
传送门
这道题有两种做法,第一种:hash,这就不讲了吧
第二种,我们看到这个题要求的是最长的前缀后缀的长度。这像什么?KMP
欸嘿,我们将两个字符串\(abc\)和\(bcd\)拼起来,得到\(abcbcd\),这个不好处理
我们试着将这两个字符串调换一下位置,得到\(bcdabc\)。
我们回顾一下\(next_i\)数组的双重意义
- 这是字符匹配中\(j\)要跳到的位置
- 代表的是\([0,i]\)中最长公共前后缀的长度
但是这里又有一个问题,TLE!!!
我们发现一个字符串最多完全嵌入到上一个字串之中。这意味着什么?
这意味着我们可以之对前几个字符进行求\(next\),这样就芜湖起....
飞了吗?没有,这样会被hack掉。
假如我们有两个字符串\(aba\)和\(bab\)。按照之前的拼法会得到\(bababa\),发现\(next_{len}=4\)!超过了原字符串的长度!!
我们如何解决这个问题呢?要想让这个字符串不跨串匹配,我们可以在中间加一个奇怪的字符\(/\)来分割,这样就好了!
终于分析完了,请看代码
#include <bits/stdc++.h>
using namespace std;
inline int read()
{
register int x = 0, f = 1;
register char ch = getchar();
while ( ch<'0' || ch>'9' )
{
if ( ch == '-' )
f = -1;
ch = getchar();
}
while ( ch >= '0' && ch <= '9' )
{
x = x * 10 + ch - '0';
ch = getchar();
}
return(x * f);
}
inline void write( register int x )
{
if ( x < 0 )
{
putchar( '-' );
x = -x;
}
if ( x > 9 )
write( x / 10 );
putchar( x % 10 + '0' );
}
const int N = 1e6 + 5;
int n, nxt[N];
string s[100005], ans;
void getNext( string s )
{
int l = s.size();
/* memset(nxt,0,sizeof nxt); */
int i = 0, j = -1;
nxt[0] = -1;
while ( i < l )
{
if ( j == -1 || s[i] == s[j] )
{
i++;
j++;
nxt[i] = j;
} else j = nxt[j];
}
}
int main()
{
n = read();
for ( int i = 1; i <= n; i++ )
{
cin >> s[i];
}
ans = s[1];
for ( int i = 2; i <= n; i++ )
{
int len = min( ans.size(), s[i].size() );
string tmp = s[i] + "/" + ans.substr( ans.size() - len );
getNext( tmp );
/* cout<<nxt[tmp.size()]<<' '<<len<<"\n"; */
ans += s[i].substr( nxt[tmp.size()] );
}
cout << ans;
return(0);
}
洛谷P2375 [NOI2014]动物园
5.总结
KMP算法是一个好东西,很多东西都可以用到,但是这个东西的思维难度比较大,大家要多动脑子,不能无脑CTJ,应该自己思考,这样能为之后的后缀数组和AC自动机打下坚实的基础。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号