oracle 分析函数
Oracle-分析函数之连续求和 sum(…) over(…) Oracle-分析函数之排序值 rank()和dense_rank() Oracle-分析函数之排序后顺序号 row_number() Oracle-分析函数之取上下行数据 lag()和lead()
分析函数和聚合函数的区别
普通的聚合函数用group by分组,每个分组返回一个统计值,
分析函数采用partition by分组,并且每组每行都可以返回一个统计值。
分析函数带有一个开窗函数over(),包含三个分析子句:
1分组(partition by)
2排序(order by)
3窗口(rows)
规则
sum(…) over( ),对所有行求和
sum(…) over( order by … ), 连续求和
sum(…) over( partition by… ),同组内所行求和
sum(…) over( partition by… order by … ),同第1点中的排序求和原理,只是范围限制在组内
select * from t1;
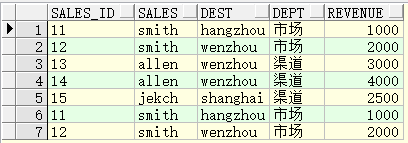
select sales_id, sales, dest, dept, revenue, sum(revenue) over() sum_order from test;
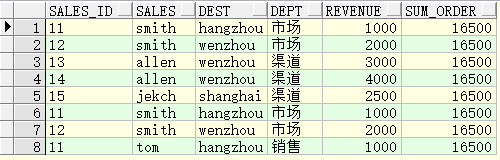
select sales_id, sales, dest, dept, revenue, sum(revenue) over(order by revenue) sum_order from test;
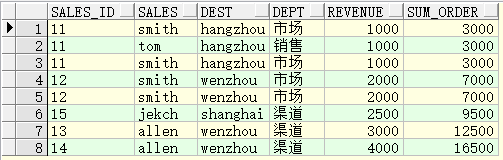
select sales_id, sales, dest, dept, revenue, sum(revenue) over(partition by sales_id) sum_order from test;

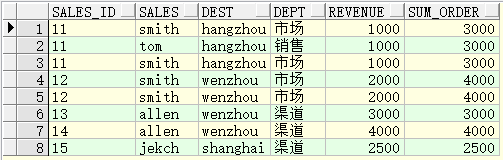
select sales_id, sales, dest, dept, revenue, sum(revenue) over(partition by sales_id order by revenue) sum_order from test;
聚合函数RANK 和 dense_rank
【语法】 rank() over( [query_partition_clause] order_by_clause )
dense_rank() over( [query_partition_clause] order_by_clause )
【功能】聚合函数RANK 和 dense_rank 主要的功能是计算一组数值中的排序值。
【参数】dense_rank与rank()用法相当
【区别】dence_rank在并列关系是,相关等级不会跳过。rank则跳过.
rank()是跳跃排序,有两个第二名时接下来就是第四名(同样是在各个分组内)
dense_rank()l是连续排序,有两个第二名时仍然跟着第三名。
rank() 函数
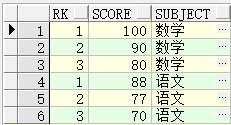
SELECT a.col1,a.col2,RANK() OVER(PARTITION BY col2 ORDER BY col1) "Rank" FROM xgj a;

select * from xgj_2;
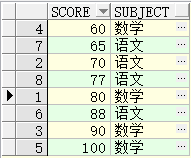
select * from (select rank() over(partition by a.subject order by a.score desc) rk, a.* from xgj_2 a) t where t.rk <= 3;
合计功能:计算出数值(65,’语文’)在Order By score ,subject排序下的排序值,也就是score=65,subject=语文在排序以后的位置
SELECT RANK(65, '语文') WITHIN GROUP(ORDER BY score, subject) "Rank" FROM xgj_2;

dense_rank()
与rank()用法相当,但是有一个区别:dence_rank在并列关系是,相关等级不会跳过。rank则跳过.
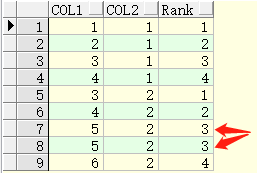
ROW_NUMBER() OVER (PARTITION BY COL1 ORDER BY COL2)
功能】表示根据COL1分组,在分组内部根据 COL2排序,而这个值就表示每组内部排序后的顺序编号(组内连续的唯一的)
row_number() 返回的主要是“行”的信息,并没有排名.
【参数】
【说明】Oracle分析函数
【主要功能】:用于取前几名,或者最后几名等
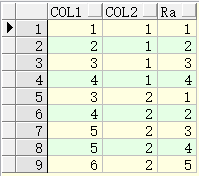
SELECT a.col1,a.col2,row_number() OVER(PARTITION BY col2 ORDER BY col1) "Ra" FROM xgj a;
lag()和lead()
这两个函数是偏移量函数,可以查出一个字段的上一个值或者下一个值,配合over来使用。
Lag和Lead分析函数可以在同一次查询中取出同一字段的前N行的数据(Lag)和后N行的数据(Lead)作为独立的列。
【功能】表示根据COL1分组,在分组内部根据 COL2排序,而这个值就表示每组内部排序后的顺序编号(组内连续的唯一的)
lead () 下一个值 lag() 上一个值
【参数】
EXPR是从其他行返回的表达式
OFFSET是缺省为1 的正数,表示相对行数。希望检索的当前行分区的偏移量
DEFAULT是在OFFSET表示的数目超出了分组的范围时返回的值。
exp_str 是要做对比的字段
offset 是exp_str字段的偏移量 比如说 offset 为2 则 拿exp_str的第一行和第三行对比,第二行和第四行,依次类推,offset的默认值为1!
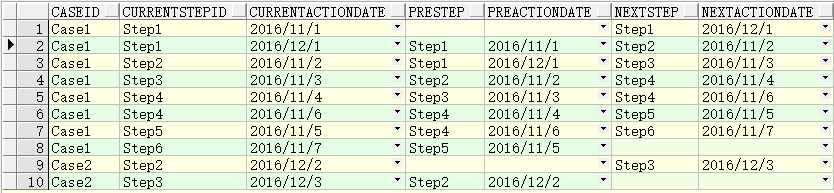
select a.caseid,
a.stepid as currentStepID,
a.actiondate as currentActionDate,
lag(stepid) over(partition by a.caseid order by a.stepid) preStep,
lag(actiondate) over(partition by a.caseid order by a.stepid) preActionDate,
lead(stepid) over(partition by a.caseid order by a.stepid) nextStep,
lead(actiondate) over(partition by a.caseid order by a.stepid) nextActionDate
from lead_table a;

 浙公网安备 33010602011771号
浙公网安备 33010602011771号