hive 中删除字段/去掉字段
Hive中没有直接删除字段的操作,只有 Add/Replace
做个测试:
1)建表操作
create table if not exists temp.test1( applseq string comment '申请号' ,data_dt string comment '日期' ,flag string comment '标识' ,age decimal(20,6) comment '年龄' ,money_all decimal(20,6) comment 'money' ) comment '测试表temp1' partitioned by ( table_name varchar(50) comment '表名称' ,dt varchar(8) comment '数据日期' ) stored as textfile;
2)用Hive查看表结构
hive> desc temp.test1; applseq string data_dt string flag string age decimal(20,6) money_all decimal(20,6) table_name varchar(50) dt varchar(8)
3)往表里插入数据
insert into temp.test1 values('B20220125CDE','20220125','',25,999999999,'sh001_sh001_jiebei_test1','20220125');
4)查看具体文件内容
[zw@hadoop ~]$ hdfs dfs -cat /user/hive/warehouse/temp.db/test1/table_name=sh001_sh001_jiebei_test1/dt=20220125/000000_0 B20220125CDE2022012525.000000999999999.000000
5)修改字段(删除后两个字段)
alter table temp.test1 replace columns ( applseq string comment '申请号' ,data_dt string comment '日期' ,flag string comment '标识') ;
6)查看字段
hive> desc temp.test1; OK applseq string data_dt string flag string table_name varchar(50) dt varchar(8)
7)查询数据 (字段已经去掉)
hive> select * from temp.test1; OK B20220125CDE 20220125 sh001_sh001_jiebei_test1 20220125
8)查看具体文件内容(文件内容是没有变的)
[zw@hadoop ~]$ hdfs dfs -cat /user/hive/warehouse/shdata.db/sh001_sh001_jiebei_test1/table_name=sh001_sh001_jiebei_test1/dt=20220125/000000_0 B20220125CDE2022012525.000000999999999.000000
总结一下:
1)可以用Hive删除字段,会有很大的局限性:
只能删除最后的几个字段,这样不会错位
如果replace中间的字段,这样会错位
因为数据后台的数据文件不会改变,如果replace中间的字段,查询只会拉取对应字段个数的后台数据文件里的字段值
官方写的比较清楚:
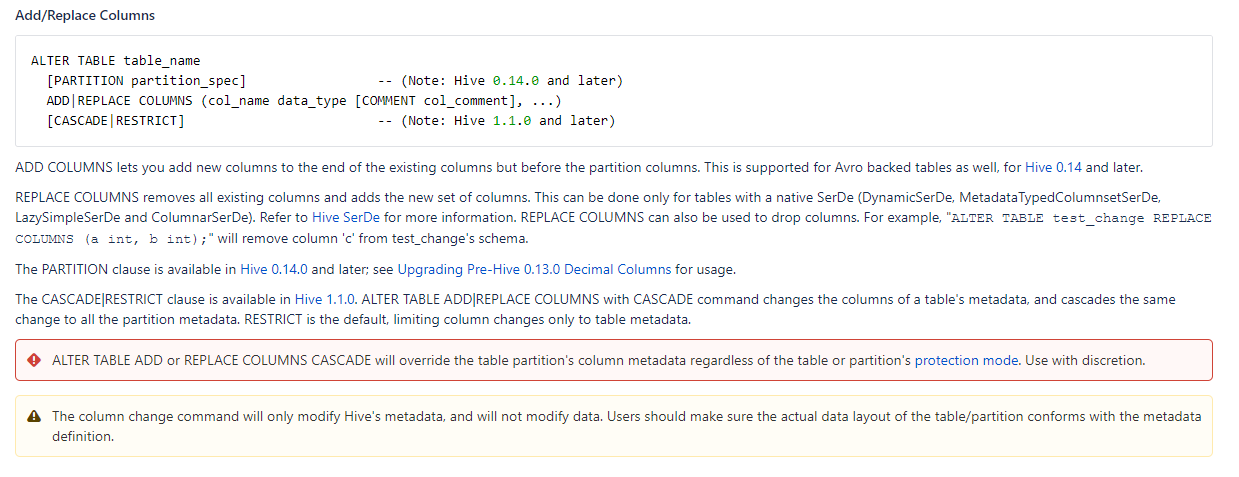
https://cwiki.apache.org/confluence/display/Hive/LanguageManual+DDL#LanguageManualDDL-Add/ReplaceColumns
天下难事,必作于易;天下大事,必作于细

