CHD-5.3.6集群安装
我是基于Apache-hadoop2.7.3版本安装成功后,已有的环境进行安装chd-5..6
已用的环境:
JDK版本:
java version "1.8.0_191" Java(TM) SE Runtime Environment (build 1.8.0_191-b12) Java HotSpot(TM) 64-Bit Server VM (build 25.191-b12, mixed mode)
三台机器已经免秘钥:
192.168.1.30 master 192.168.1.40 saver1 192.168.1.50 saver2
现有的安装包:
cdh5.3.6-snappy-lib-natirve.tar.gz hadoop-2.5.0-cdh5.3.6.tar.gz hive-0.13.1-cdh5.3.6.tar.gz sqoop-1.4.5-cdh5.3.6.tar.gz
开始安装:
1.上传上面的四个安装包到soft 目录
2.赋权
[hadoop@master soft]$ chmod 755 *
3.解压到指定目录
[hadoop@master soft]$ tar -xvf hadoop-2.5.0-cdh5.3.6.tar.gz -C /home/hadoop/CDH5.3.6 tar -xvf hive-0.13.1-cdh5.3.6.tar.gz -C /home/hadoop/CDH5.3.6
4.配置hadoop-env.sh
export JAVA_HOME=/usr/local/jdk1.8
5.配置mapred-env.sh
export JAVA_HOME=/usr/local/jdk1.8
6.配置core-sit.xml
<configuration>
<!-- 指定hdfs的nameservice为ns1 -->
<property>
<name>fs.defaultFS</name>
<value>hdfs://192.168.1.30:9000</value>
</property>
<!-- Size of read/write buffer used in SequenceFiles. -->
<property>
<name>io.file.buffer.size</name>
<value>131072</value>
</property>
<!-- 指定hadoop临时目录,自行创建 -->
<property>
<name>hadoop.tmp.dir</name>
<value>//home/hadoop/CDH5.3.6/hadoop-2.5.0-cdh5.3.6/data/tmp</value>
</property>
<property>
<name>hadoop.proxyuser.hadoop.groups</name>
<value>*</value>
</property>
<property>
<name>hadoop.proxyuser.hadoop.hosts</name>
<value>*</value>
</property>
</configuration>
7.配置hdfs-site.xml
<configuration>
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>192.168.1.30:50090</value>
</property>
<property>
<name>dfs.replication</name>
<value>3</value>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>file:/home/hadoop/CDH5.3.6/hadoop-2.5.0-cdh5.3.6/hdfs/name</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>file:/home/hadoop/CDH5.3.6/hadoop-2.5.0-cdh5.3.6/hdfs/data</value>
</property>
<property>
<name>dfs.webhdfs.enabled</name>
<value>true</value>
</property>
</configuration>
8.配置slaves
master
saver1
saver2
9.拷贝到其他节点
scp -r /home/hadoop/CDH5.3.6 hadoop@saver1:/home/hadoop/ scp -r /home/hadoop/CDH5.3.6 hadoop@saver2:/home/hadoop/
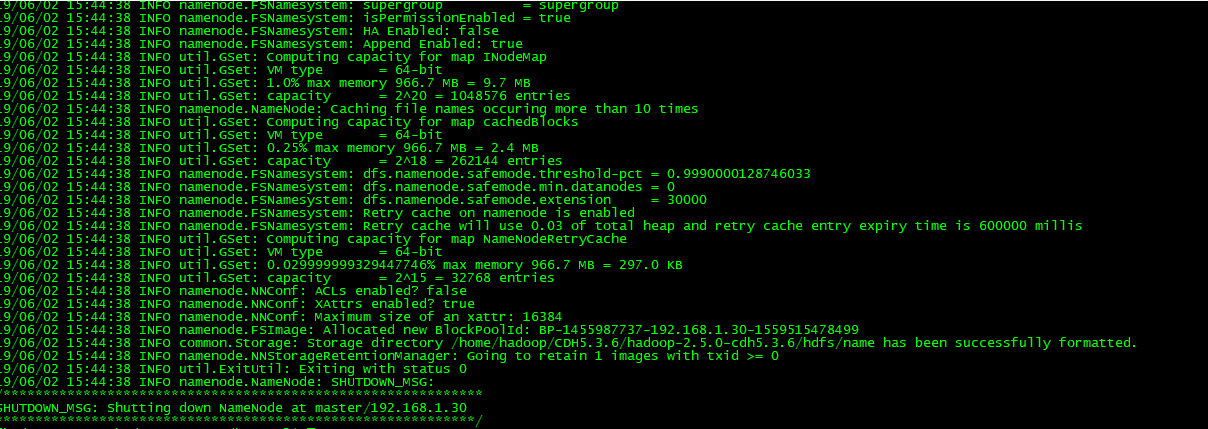
10.格式化hadoop
[hadoop@master hadoop-2.5.0-cdh5.3.6]$ bin/hdfs namenode -format
出现错误:
Error: Could not find or load main class org.apache.hadoop.hdfs.server.namenode.NameNode
解决方法:
因为没有HADOOP_HOME/share/hadoop/hdfs/× 这个路径,所以我在hadoop-XX\libexec\hadoop-config.sh最后自己加上
## 因为它的classpath中没有hdfs的路径,所以手动添加
CLASSPATH=${CLASSPATH}:$HADOOP_HDFS_HOME'/share/hadoop/hdfs/*'
成功格式化:
11.配置yarn-site.xml
<configuration>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.nodemanager.aux-services.mapreduce.shuffle.class</name>
<value>org.apache.hadoop.mapred.ShuffleHandler</value>
</property>
<property>
<name>yarn.resourcemanager.address</name>
<value>192.168.1.30:8032</value>
</property>
<property>
<name>yarn.resourcemanager.scheduler.address</name>
<value>192.168.1.30:8030</value>
</property>
<property>
<name>yarn.resourcemanager.resource-tracker.address</name>
<value>192.168.1.30:8031</value>
</property>
<property>
<name>yarn.resourcemanager.admin.address</name>
<value>192.168.1.30:8033</value>
</property>
<property>
<name>yarn.resourcemanager.webapp.address</name>
<value>192.168.1.30:8088</value>
</property>
</configuration>
12.配置mapred-site.xml
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<property>
<name>mapreduce.jobhistory.address</name>
<value>192.168.1.30:10020</value>
</property>
<property>
<name>mapreduce.jobhistory.webapp.address</name>
<value>192.168.1.30:19888</value>
</property>
</configuration>
13,重启系统
14.启动服务:
[hadoop@master hadoop-2.5.0-cdh5.3.6]$ sbin/hadoop-daemon.sh start namenode starting namenode, logging to /home/hadoop/CDH5.3.6/hadoop-2.5.0-cdh5.3.6/logs/hadoop-hadoop-namenode-master.out [hadoop@master hadoop-2.5.0-cdh5.3.6]$ sbin/hadoop-daemon.sh start datanode starting datanode, logging to /home/hadoop/CDH5.3.6/hadoop-2.5.0-cdh5.3.6/logs/hadoop-hadoop-datanode-master.out [hadoop@master hadoop-2.5.0-cdh5.3.6]$ sbin/yarn-daemon.sh start resourcemanager starting resourcemanager, logging to /home/hadoop/CDH5.3.6/hadoop-2.5.0-cdh5.3.6/logs/yarn-hadoop-resourcemanager-master.out [hadoop@master hadoop-2.5.0-cdh5.3.6]$ sbin/yarn-daemon.sh start nodemanager starting nodemanager, logging to /home/hadoop/CDH5.3.6/hadoop-2.5.0-cdh5.3.6/logs/yarn-hadoop-nodemanager-master.out [hadoop@master hadoop-2.5.0-cdh5.3.6]$ sbin/mr-jobhistory-daemon.sh start historyserver starting historyserver, logging to /home/hadoop/CDH5.3.6/hadoop-2.5.0-cdh5.3.6/logs/mapred-hadoop-historyserver-master.out
15.查看服务
[hadoop@master hadoop-2.5.0-cdh5.3.6]$ jps 3269 NodeManager 3414 JobHistoryServer 3447 Jps 2922 DataNode 3021 ResourceManager 2831 NameNode
天下难事,必作于易;天下大事,必作于细

