关于索引我能说的那些事儿
本文是自己对MySQL的
InnoDB索引的理解,如有错误,还望不吝指出。
1 索引
索引这两个字着实有些太泛,而在我的理解中,其就是一个查字典的过程,比方说现在我们要从一本字典中查一个牛字,那么我们可以从目录中的n字母找到这个牛字,发现在164页,然后翻到164页就可以看到关于牛这个的解释、用法等。
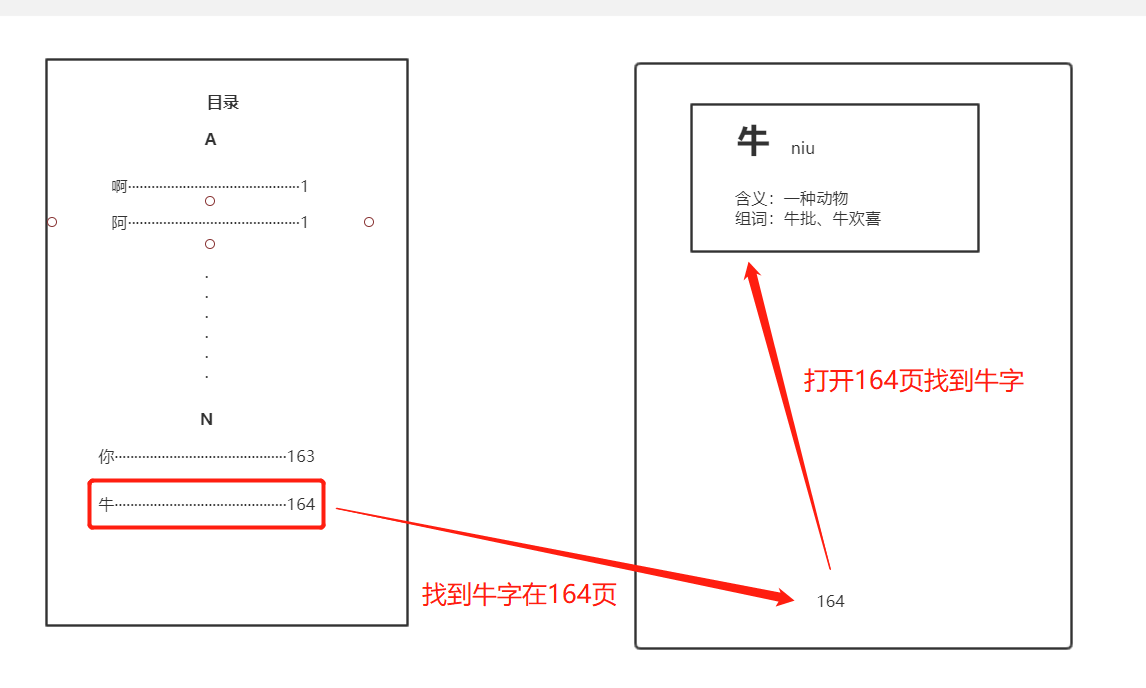
可以看到我们不是从第一页开始一页一页的找,而是先从目录中根据拼音开头找,找到之后翻到其对应的页数就找到了我们所需要的牛字。在这整个过程中,这个目录的字母就是我们所说的索引。我们查找数据的时候先通过这个目录找到对应记录的地址,再去这个地址找到我们所需要的数据,这个过程相比我们从头找到尾的效率要高许多,这就是索引的作用——提高性能。
接下来所讲的内容如果没有备注则都是以InnoDB为主。
2 索引的类型
在MySQL的InnoDB引擎中,最常见的索引就是B-Tree索引和Hash索引。
-
B-Tree索引:B-Tree索引是一种通用的叫法,在不同的储存引擎中可能有不同的实现方式,而在InnoDB中则是用B+Tree来实现,跟普通的的B-Tree不同的是B+Tree只有在叶子节点才存放数据,在非叶子节点中只是存放一个Key值和节点的引用,具体关B+Tree索引我们放在下面详细讲,普通的索引用的就是B+Tree。(以前会把B-Tree读成B减树,暴露了自己文盲的事实,正确的读法应该是B树,中间的-是杠不是减,B+Tree则是读成B加树) -
Hash索引:意思就是讲字段的值经过一个Hash算法之后得到一个Hash值,再将这个Hash值以K-V的形式写入到一个Hash表中,key就是这个hash值,value则是我们所需要的数据链表,类似于Java中HashMap的实现,使用链表的原因是因为可能算法的一些问题而导致哈希冲突的问题。这种索引是十分迅速的,相对于B+Tree中依赖树高度的O(logN),其时间复杂度为O(1),既然如此迅速,为什么InnoDB还是选择B+Tree作为默认的索引类型?因为其虽然快速,但是还是有许多缺点:- 需要额外的列来储存
hash值:比方说我们在表中有url列,用普通索引满足不了性能要求,我们可以使用hash索引,增加一个url_hash列来储存其hash值,那么每次我们查询的时候就会变成where url_hash = hash("www.baidu.com") and url = www.baidu.com,这样的查询效率可以有很大的提升,但是付出的代价是多一列的维护空间。 - 不能使用例如
limit,order by等数据范围操作:因为中间还要经过一个hash算法,所以这种索引在这些方面的表现十分不理想,在这方面B+Tree的表现则十分的优异,平均性能来说还是B+Tree更高,况且对于平常的需求来说范围数据的查询要更多一些。
- 需要额外的列来储存
这两种算是比较常见的索引类型,除此之外还有一种全文索引,可以实现搜索引擎类似的功能,但还没见人用过,便不加了解。
3 B+Tree的结构
首先先看看B+Tree是怎么出现的。
在一开始的时候使用的是平衡二叉树作为索引树,但是随着数据量的增大二叉树的表现有点疲软,后来便出现的一种新的结构叫作B-Tree,这种数据结构有多个子节点(不再是固定两个),而在每个节点上面都存着数据和其他节点的引用,很大程度上解决了二叉树带来的效率问题,然而时间再次推进,B-Tree的表现也逐渐下滑,此时则出现了一种新的实现方式——B+Tree。
关于B+Tree,我们先看一个图。
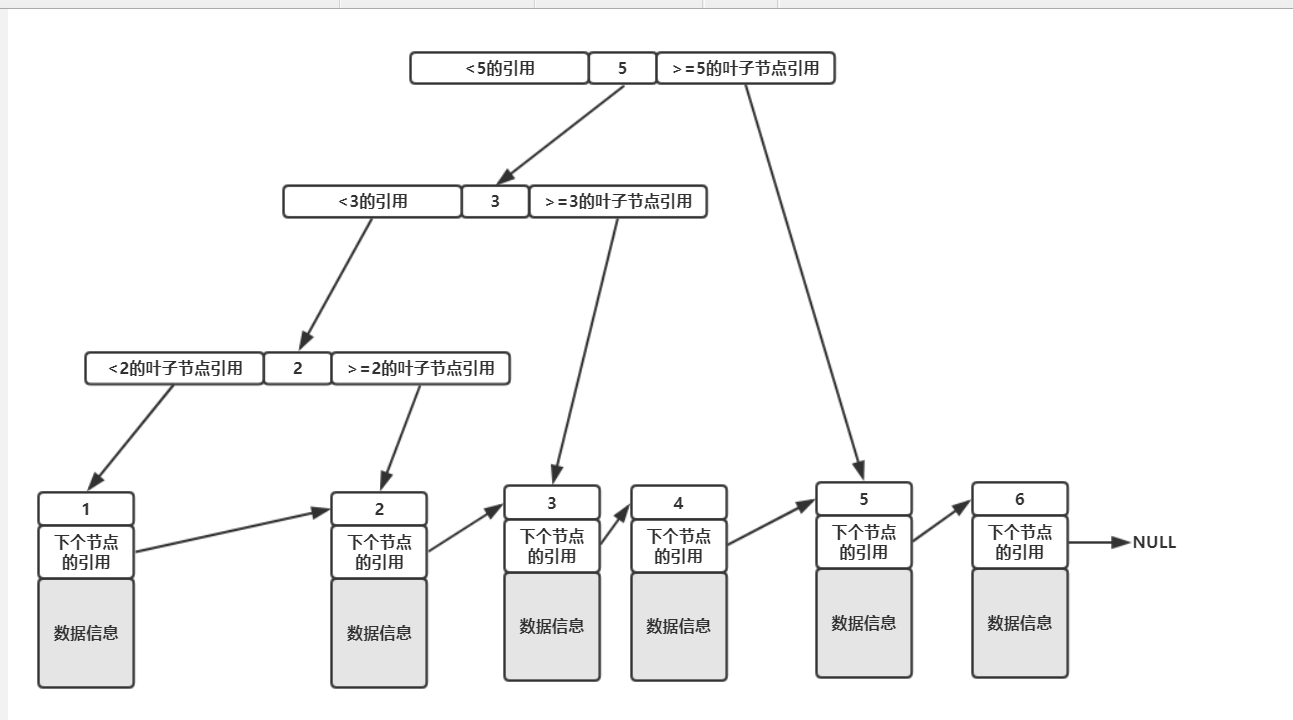
如上图,我们存储的数据是1、2、3、4、5、6,所有的数据都在叶子节点中,所谓的叶子节点就是上图中最下层真正存放数据的节点,而上面那些只存了key和引用的则称之为非叶子节点。
这里需要注意的是,在InnoDB中,只有主键索引的叶子节点存放才是真正的数据信息,其他列的索引在叶子节点中存放的数据信息是主键的值,也就是说如果我们使用的是普通的索引,那么其查找的过程为:
在使用的索引树(有多少个索引就有多少棵树)中进行查找,找到了对应的叶子节点之后拿到其储存的主键值,再去主键索引树中查找对应主键的叶子节点的数据信息,而一般把这种行为称作'回表'。
主键索引和普通索引可以结合下图理解
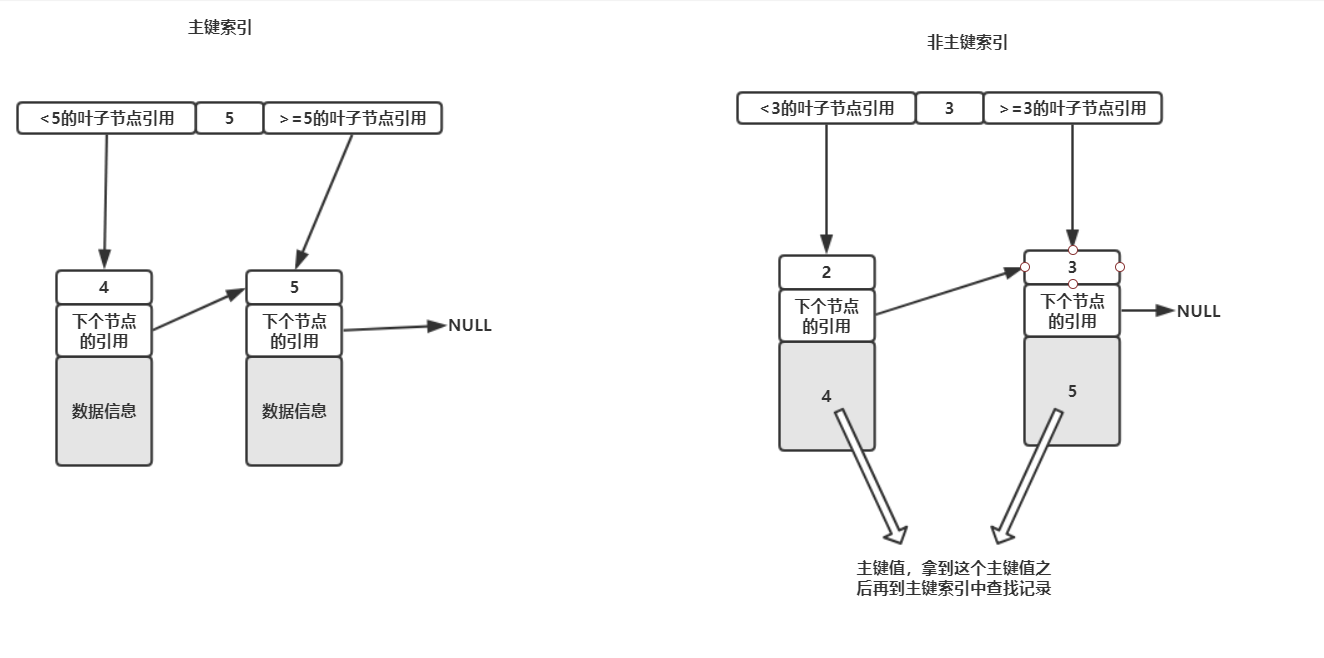
这就是InnoDB中B+Tree的实现方式,跟普通的B-Tree相比有了稳定的性能,并且在范围查询(比方说id<10)方面表现的更加优异。
而B-Tree的结构直接把数据的信息放在节点中,没有是否叶子节点之分,查到之后就立马返回,如下: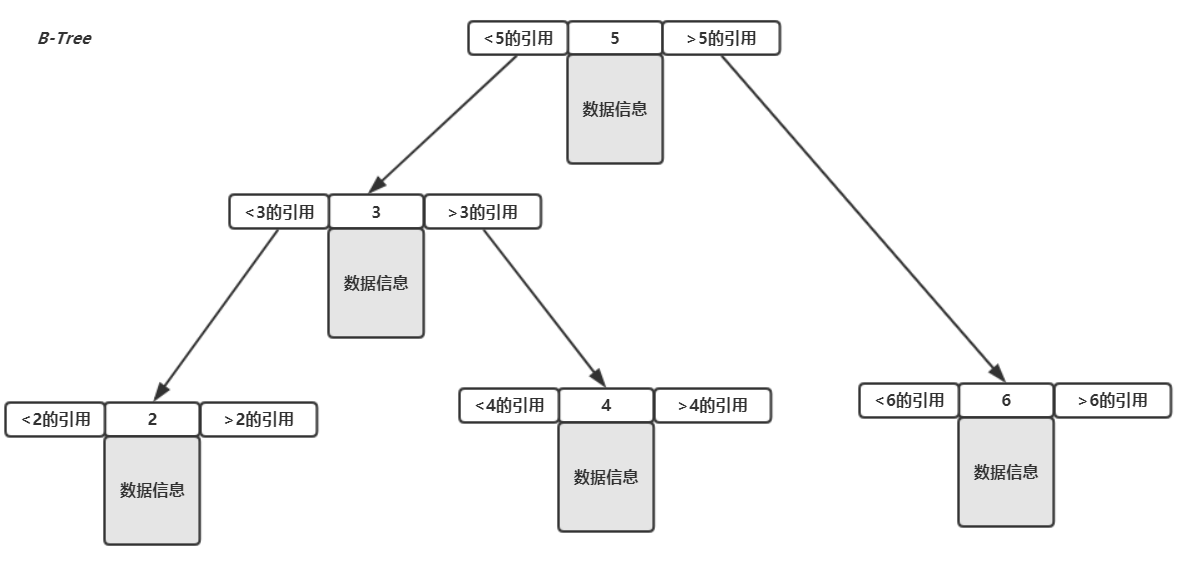
4 聚簇索引和非聚簇索引
聚簇索引并非一种索引类型而是一种储存方式,表示索引的键值对和临近的数据行储存在一起,在物理的储存顺序是有序的,在InooDB中,主键索引就是聚簇索引的实现。
由于数据行只有一颗索引树有存,所以也就只有一个聚簇索引,也就是说除了主键索引是聚簇索引之外,其他列的索引都是非聚簇索引。而聚簇索引的储存特性也就决定了我们在查到范围数据比如limit 10这种操作的时候能够进行顺序IO而非随机IO从而提升了查找的效率。
当然有优必有劣,聚簇索引的储存方式也就决定了主键只有在递增的时候发挥得比较好,主键是递增的,每次插入时往上次插入位置的下一个位置插入就行(因为新增的主键一定比之前的大),如果页满了就插入下一页,但是如果主键是不规则的,譬如UUID来做主键,由于其每次插入的主键不一定比之前的大,那么则要进行比较从而进行数据的移动,需要花费的时间和空间要更多一些,并且如果插入一个饱满的页中就会引发列分裂从而造成空间碎片。
5 复合索引和覆盖索引
首先我们得知道这两个不是同一个概念。
-
复合索引:表示在一个索引中使用到了多个列,这个索引在内存中的排序则是依照列在索引的顺序来决定的。比方说复合索引
('user_id', 'sex', 'age'),我们在使用where user_id = '1'的时候会到user_id的索引,使用where user_id = '1' and sex = '1'的时候会用到user_id和sex两个列的索引,也就是说只有当前缀列出现了再用此列索引才有效,而没有使用前缀列的条件如where sex = '1'或者where sex = '1' and age = '11'都不会用到索引,因为当前的前缀列是user_id。 -
覆盖索引:指的是当某个索引包含查询所需要的所有字段的时候,这个时候找到记录之后则不再去主键树中查找数据,而是直接返回索引包含的字段,只在内存操作而不进行IO,可以很大程度上提升效率,使用覆盖索引的时候
explain中的extra会出现using index,如下图。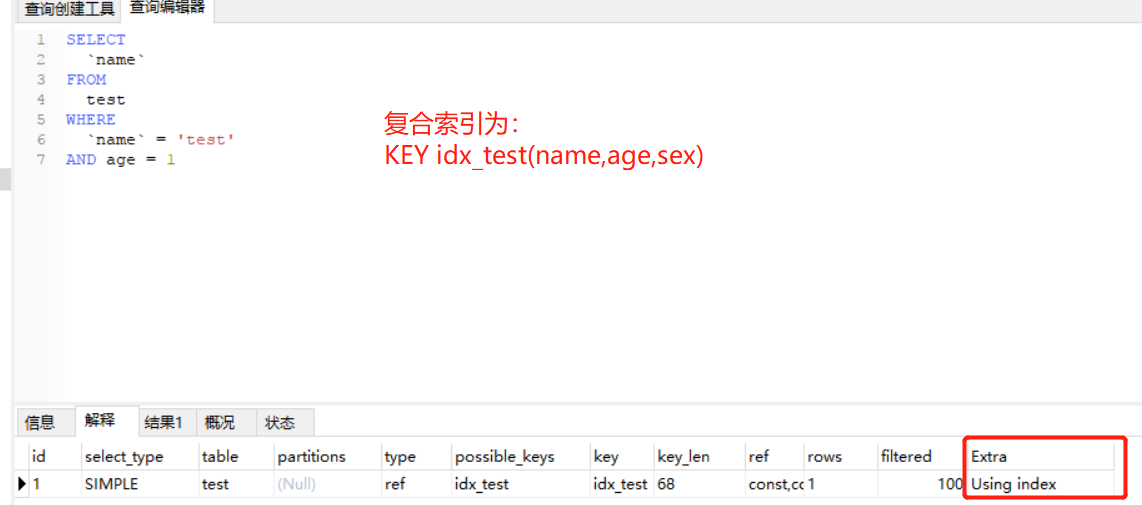
另外,使用覆盖索引可以实现延迟关联,从而提升查询的效率(前提是使用覆盖索引过滤的数据足够多),比方说现在有一个SQL:
select * from user_info where user_number = '123' and user_name like '%三%';
在user_info表中有复合索引(user_number, user_name),上面的写法的执行过程为:
- 从索引树中找到
user_number='123'的所有主键(user_name为全模糊,不会用到索引),注意这里还没执行user_name like '%三%'的操作。- 根据这些主键从主键索引中找到对应的数据行,将这些数据行从磁盘加载到内存中
- 加载完成之后,从这些数据行中筛选出
user_name like '%三%'的数据,将这些数据返回
这是正常的执行过程,但是我们可以改写这个SQL,让其变成使用覆盖索引的形式:
SELECT
*
FROM
user_info
INNER JOIN (
SELECT
id
FROM
user_info
WHERE
user_number = '123'
AND user_name LIKE '%三%'
) t ON user_info.id = t.id;
这样临时表t则是使用覆盖索引生成的记录,是在内存操作,注意由于索引的叶子节点存储的是主键值,所以使用主键值的话也能用到覆盖索引。
这个写法跟上面不同的地方在于,由于使用了覆盖索引,所以对于user_number和user_name的条件过滤都是在内存中进行的,在内存过滤完成之后将拿到的主键值再去主键索引取数据行。跟第一种写法的效率区别则是在于覆盖索引能够过滤多少条数据。
拿这两个SQL举个例子,假设在user_info表中user_number='123'的数据有10W条,user_name中包含'三'的数据有200条,那么如果是第一种写法,则有:
从索引中拿到
10W条user_number='123'的主键值到主键索引中拿到10W条数据行然后加载到内存中,再从内存中的10W条数据中找出user_name包含'三'的200条数据。
而如果是第二种写法,则变成了:
先在索引中找到
user_number='123'的节点,然后再从这些节点中找出user_name包含'三'的200个主键值,注意到目前为止都是内存操作还没进行IO,然后根据这200个主键值从磁盘加载200条数据数据行到内存中返回。
对比可以清楚的看到,第一种写法进行了10W数据的IO再过滤,而使用覆盖索引的方式则只进行200条数据的IO,性能的提升肯定是非常大的,这种使用覆盖索引来提升性能的方式就叫做'延迟关联'。当然,性能的提升决定于覆盖索引能够过滤的数据行数,如果上面的例子中user_name包含'三'的记录有9W条,那么此时'延迟关联'的写法提升就没那么明显了。
6 Extra中的一些信息
最后讲下MySQL的explain中Extra的using where、using index和using index condition。
-
using where:表示使用到了除使用索引列外的条件进行过滤,需要注意的是如果使用的是复合索引,那么条件中不是该复合索引的列的话则
extra中会出现using where,即便后面的条件也是一个索引(但在当前查询中没有使用到)。
另外,using where不一定会进行回表,例如using where;using index同时出现的时候则表示,用到了覆盖索引,并且where的条件中还有该覆盖索引的其他列,但不是前导列,此时会在覆盖索引的返回数据上进行过滤,而不再访问数据行,这种情况下不会进行回表。 -
using index:表示用到了覆盖索引。 -
using index condition:表示不使用到覆盖索引的情况下,用到了复合索引中的其他非前导列作为查询的条件。比方说复合索引为(user_id, name, age),SQL为:select * from user where user_id = 1 and age = 1 and sex = 1;
此时由于age不是前导列,但为复合索引的其中一列,并且查询的是所有列,并不会用到覆盖索引,所以是index condition;using where而不是或者using index,其中using where是因为 sex = 1这个条件,如果没有的话则只有using index condition。
注意:using index condition用索引非前导列的条件(比方说上方的age)时,这部分的条件筛选是在内存中进行,而不是回表返回数据行之后再执行这个过滤条件。如上方的sql中,其顺序就是先找到user_id = 1的索引记录,然后在这些记录中过滤出age = 1的记录,到这里都是内存操作,再通过回表返回的数据行中过滤sex = 1的数据,所以using index condition的过滤时间是发生在回表之前。
参考:《高性能MySQL》第三版

