
Day7 模块
一、模块定义、导入、优化详解
1.定义
模块:本质上就是 .py结尾的python文件,(文件test.py对应的模块名为test)
用来从逻辑上组织python代码(变量、函数、类、逻辑:实现一个功能)。
包: 本质上就是一个目录(一个必须有__init__.py文件的目录)
用来从逻辑上组织模块。
2.导入方法
import module_ztian import module1_ztian,module2_ztian #导入多个模块 from module_ztian import * #导入所有,但不建议使用 from module_ztian import logger #导入指定部分 from module_ztian import logger as logger_ztian #换名
若所需模块不在当前目录下:
a:利用 os.path.abspath(__file__) 得到当前文件的绝对路径;
b:利用 os.path.dirname(os.path.abspath(__file__) 得到当前文件所处的目录名,每多调用一次 os.path.dirname() ,目录回退一级;
c:利用 sys.path.append() 将达到的目录添加到环境变量中;
d:import入所需模块。
#若所需模块不在当前目录下,需将模块的路径添加进去 #import module_ztian -》module_ztian.py-》module_ztian.py的路径-》sys.path >>> import sys >>> sys.path [ '', #第一个元素为空,代表当前路径 'F:\\Python\\Python36\\python36.zip', 'F:\\Python\\Python36\\DLLs', 'F:\\Python\\Python36\\lib', 'F:\\Python\\Python36', 'F:\\Python\\Python36\\lib\\site-packages' ]
3.import本质
导入模块的本质就是把python文件解释一遍。
import module_ztian # 将模块module_ztian中所有代码解释一遍,相当于module_ztian = all code 。调用模块中的内容:module_ztian.name ;module_ztian.logger() from module_ztian import logger #将模块module_ztian中logger解释一遍,相当于将要导入的那部分直接复制过去
导入包的本质就是把该包下的__init__.py文件解释一遍。
4.导入优化小技巧
1 import module_better 2 3 def logger(): 4 module_better.test_better() 5 print("in the logger") 6 7 def search(): 8 module_better.test_better() #每次都要先找module_better再test_better 9 print("in the search")
可优化为:
1 from module_better import test_better 2 3 def logger(): 4 test_better() 5 print("in the logger") 6 7 def search(): 8 test_better() 9 print("in the search")
二、常用模块
模块通常分为三种:
标准库(内置模块):time和datetime
开源模块(第三方模块)
自定义模块
1.time和datetime模块
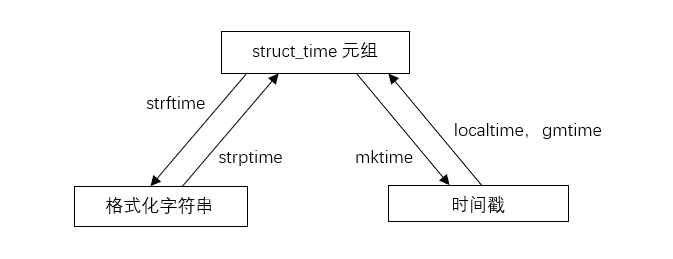
三种形式:时间戳;元组struct_time;格式化的字符串。这三种形式可以相互转换。
1 >>> import time 2 3 #时间戳 4 >>> time.time() 5 1518239905.471463 6 7 #将时间戳转换为struct_time形式 8 >>> time.localtime() #struct_time 本地时间(中国UTC+8) 9 time.struct_time(tm_year=2018, tm_mon=2, tm_mday=10, tm_hour=13, tm_min=18, tm_sec=32, tm_wday=5, tm_yday=41, tm_isdst=0) 10 >>> time.gmtime() #struct_time UTC时间 11 time.struct_time(tm_year=2018, tm_mon=2, tm_mday=10, tm_hour=5, tm_min=18, tm_sec=39, tm_wday=5, tm_yday=41, tm_isdst=0) 12 >>> time.localtime(234241) 13 time.struct_time(tm_year=1970, tm_mon=1, tm_mday=4, tm_hour=1, tm_min=4, tm_sec=1, tm_wday=6, tm_yday=4, tm_isdst=0) 14 >>> time.gmtime(567890) 15 time.struct_time(tm_year=1970, tm_mon=1, tm_mday=7, tm_hour=13, tm_min=44, tm_sec=50, tm_wday=2, tm_yday=7, tm_isdst=0) 16 17 #将struct_time转换为时间戳 18 >>> time.mktime(time.localtime(345678)) 19 345678.0 20 21 #将struct_time转换成格式化的字符串 22 >>> time.strftime("%Y-%m-%d %H:%M:%S",time.localtime()) 23 '2018-02-10 13:20:52' 24 #将格式化的字符串转换成struct_time 25 >>> time.strptime('2018-02-10 13:20:52',"%Y-%m-%d %H:%M:%S") 26 time.struct_time(tm_year=2018, tm_mon=2, tm_mday=10, tm_hour=13, tm_min=20, tm_sec=52, tm_wday=5, tm_yday=41, tm_isdst=-1) 27 28 #将struct_time转换为字符串 29 >>> time.asctime() 30 'Sat Feb 10 13:25:54 2018' 31 #将时间戳转换成字符串 32 >>> time.ctime() 33 'Sat Feb 10 13:26:09 2018'

格式化字符串符号:
%Y Year with century as a decimal number.
%m Month as a decimal number [01,12].
%d Day of the month as a decimal number [01,31].
%H Hour (24-hour clock) as a decimal number [00,23].
%M Minute as a decimal number [00,59].
%S Second as a decimal number [00,61].
%z Time zone offset from UTC.
%a Locale's abbreviated weekday name.
%A Locale's full weekday name.
%b Locale's abbreviated month name.
%B Locale's full month name.
%c Locale's appropriate date and time representation.
%I Hour (12-hour clock) as a decimal number [01,12].
%p Locale's equivalent of either AM or PM.
常用方法:
1 >>> time.timezone #返回当前时区距UTC的偏移秒数 2 -28800 3 >>> 28800/3600 4 8.0 5 >>> time.altzone #返回当前时区距UTC夏令时的偏移秒数 6 -32400 7 >>> time.daylight #当前时区是否夏令时 8 0 9 >>> time.localtime().tm_year #获取struct_time中的值 10 2018 11 >>> time.sleep(3) #程序睡3秒
1 >>> import datetime 2 3 >>> datetime.datetime.now() 4 datetime.datetime(2018, 2, 10, 14, 0, 18, 188770) 5 >>> datetime.date.fromtimestamp(time.time()) #时间戳转换为日期格式 6 datetime.date(2018, 2, 10) 7 >>> datetime.datetime.now() + datetime.timedelta(3) #当前时间+3天 8 datetime.datetime(2018, 2, 13, 14, 1, 52, 147687) 9 >>> datetime.datetime.now() + datetime.timedelta(-3) #当前时间+3天 10 datetime.datetime(2018, 2, 7, 14, 2, 10, 508443) 11 >>> datetime.datetime.now() + datetime.timedelta(hours=3) #当前时间+3小时 12 datetime.datetime(2018, 2, 10, 17, 2, 31, 195177) 13 >>> datetime.datetime.now() + datetime.timedelta(minutes=-30) #当前时间-30分钟 14 datetime.datetime(2018, 2, 10, 13, 32, 50, 428909)
2.random模块
1 >>> import random 2 3 >>> random.random() #产生一个在[0,1)的浮点数 4 0.0071548601217746866 5 >>> random.uniform(1,10) #产生一个[1,10]的浮点数 6 8.268538968586677 7 8 >>> random.randint(1,5) #产生[1,5]的整数 9 4 10 >>> random.randrange(1,10) #产生[0,10)的整数,顾头不顾尾 11 8 12 13 >>> random.choice("hello random") #从给定序列中随机选一个 14 'o' 15 >>> random.choice([1,2,3,4]) 16 2 17 >>> random.choice((1,2,3,4)) 18 4 19 20 >>> random.sample("hello random",2) #从给定序列中随机选指定个 21 ['r', 'o'] 22 23 >>> l = [1,2,3,4,5,6] 24 >>> random.shuffle(l) #洗牌,只能洗list 25 >>> l 26 [2, 3, 1, 4, 6, 5]
随机验证码:
1 import random 2 3 checkcode = '' 4 5 for i in range(4): 6 current = random.randrange(0,4) 7 if current == i: 8 temp = chr(random.randint(65,90)) 9 else: 10 temp = random.randint(0,9) 11 checkcode += str(temp) 12 print(checkcode)
3.os模块
1 os.getcwd() 获取当前工作目录,即当前python脚本工作的目录路径 2 os.chdir("dirname") 改变当前脚本工作目录;相当于shell下cd 3 os.curdir 返回当前目录: ('.') 4 os.pardir 获取当前目录的父目录字符串名:('..') 5 os.makedirs('dirname1/dirname2') 可生成多层递归目录 6 os.removedirs('dirname1') 若目录为空,则删除,并递归到上一级目录,如若也为空,则删除,依此类推 7 os.mkdir('dirname') 生成单级目录 8 os.rmdir('dirname') 删除单级空目录,若目录不为空则无法删除,报错 9 os.listdir('dirname') 列出指定目录下的所有文件和子目录,包括隐藏文件,并以列表方式打印 10 os.remove() 删除一个文件 11 os.rename("oldname","newname") 重命名文件/目录 12 os.stat('path/filename') 获取文件/目录信息 13 os.sep 输出操作系统特定的路径分隔符,win下为"\\",Linux下为"/" 14 os.linesep 输出当前平台使用的行终止符,win下为"\t\n",Linux下为"\n" 15 os.pathsep 输出用于分割文件路径的字符串 16 os.name 输出字符串指示当前使用平台。win->'nt'; Linux->'posix' 17 os.system("bash command") 运行shell命令,直接显示 18 os.environ 获取系统环境变量,返回一个字典 19 os.path.abspath(path) 返回path规范化的绝对路径 20 os.path.split(path) 将path分割成目录和文件名二元组返回 21 os.path.dirname(path) 返回path的目录。其实就是os.path.split(path)的第一个元素 22 os.path.basename(path) 返回path最后的文件名。如何path以/或\结尾,那么就会返回空值。即os.path.split(path)的第二个元素 23 os.path.exists(path) 如果path存在,返回True;如果path不存在,返回False 24 os.path.isabs(path) 如果path是绝对路径,返回True 25 os.path.isfile(path) 如果path是一个存在的文件,返回True。否则返回False 26 os.path.isdir(path) 如果path是一个存在的目录,则返回True。否则返回False 27 os.path.join(path1[, path2[, ...]]) 将多个路径组合后返回,第一个绝对路径之前的参数将被忽略 28 os.path.getatime(path) 返回path所指向的文件或者目录的最后存取时间 29 os.path.getmtime(path) 返回path所指向的文件或者目录的最后修改时间
4.sys模块
5.json和pickle模块
json:用于python中简单数据类型和字符串之间相互转换。可用于不同语言之间的数据交换。
1 import json #json只能支持简单的数据类型,不支持函数 2 3 # def sayhi(name): 4 # print("hello",name) 5 6 info = { 7 'name':'ztian', 8 'age':18, 9 # 'func':sayhi 10 } 11 12 f = open("test",'w') 13 #print(json.dumps(info)) 14 # f.write(json.dumps(info)) #将字典转化成字符串写入文件 15 json.dump(info,f) #相当于f.write(json.dumps(info)) 16 17 f.close()
1 import json 2 3 f = open("test",'r') 4 # data = json.loads(f.read()) 5 data = json.load(f) #相当于data = json.loads(f.read()) 6 print(data['age'])
pickle:用于python特有的类型和python的数据类型之间相互转换。
1 import pickle 2 3 def sayhi(name): 4 print("hello",name) 5 6 info = { 7 'name':'ztian', 8 'age':18, 9 'func':sayhi 10 } 11 12 f = open("test",'wb') 13 # f.write(pickle.dumps(info)) #将字典转换成二进制写入文件 14 pickle.dump(info,f) #相当于f.write(pickle.dumps(info)) 15 f.close()
1 import pickle 2 3 def sayhi(name): 4 print("hello2",name) 5 6 f = open("test",'rb') 7 # data = pickle.loads(f.read()) #pickel得到的函数sayhi和写入的只是名字相同 8 data = pickle.load(f) #相当于data = pickle.loads(f.read()) 9 print(data['age'])
6.shelve模块
shelve是一个简单的key-value的将内存数据通过文件持久化的模块,是对pickle更上层的封装。
1 import shelve 2 import datetime 3 4 d = shelve.open('shelve_test') # 打开一个文件 5 6 info = {'age':18,'job':'IT'} 7 name = ["alex", "rain", "test"] 8 9 d["name"] = name # 持久化列表 10 d["info"] = info # 持久化字典 11 d["date"] = datetime.datetime.now() 12 13 d.close()
1 import shelve 2 3 d = shelve.open('shelve_test') # 打开一个文件 4 print(d.get('name')) 5 print(d.get('info')) 6 print(d.get('date'))
7.xml模块
在json还没有诞生的时候用xml来进行不同语言或程序之间的数据交互。
xml格式:
1 <?xml version="1.0"?> 2 <data> 3 <country name="Liechtenstein"> 4 <rank updated="yes">2</rank> 5 <year>2008</year> 6 <gdppc>141100</gdppc> 7 <neighbor name="Austria" direction="E"/> 8 <neighbor name="Switzerland" direction="W"/> 9 </country> 10 <country name="Singapore"> 11 <rank updated="yes">5</rank> 12 <year>2011</year> 13 <gdppc>59900</gdppc> 14 <neighbor name="Malaysia" direction="N"/> 15 </country> 16 <country name="Panama"> 17 <rank updated="yes">69</rank> 18 <year>2011</year> 19 <gdppc>13600</gdppc> 20 <neighbor name="Costa Rica" direction="W"/> 21 <neighbor name="Colombia" direction="E"/> 22 </country> 23 </data>
在python中操作xml文件
查:
1 import xml.etree.ElementTree as ET 2 3 tree = ET.parse("xmltest.xml") 4 root = tree.getroot() 5 print(root) 6 print(root.tag) 7 8 # 遍历xml文档 9 for child in root: 10 print('分割线'.center(50,'-')) 11 print(child.tag, child.attrib) 12 for i in child: 13 print(i.tag, i.text) 14 15 print("\n") 16 17 # 只遍历year 节点 18 for node in root.iter('year'): 19 print(node.tag, node.text)
修改:
1 import xml.etree.ElementTree as ET 2 3 tree = ET.parse("xmltest.xml") 4 root = tree.getroot() 5 6 # 修改 7 for node in root.iter('year'): 8 new_year = int(node.text) + 1 9 node.text = str(new_year) 10 node.set("updated", "yes") 11 12 tree.write("xmltest.xml")
删除:
import xml.etree.ElementTree as ET tree = ET.parse("xmltest.xml") root = tree.getroot() # 删除node for country in root.findall('country'): rank = int(country.find('rank').text) if rank > 50: root.remove(country) tree.write('output.xml')
创建:
1 import xml.etree.ElementTree as ET 2 3 new_xml = ET.Element("namelist") 4 personinfo1 = ET.SubElement(new_xml, "personinfo1", attrib={"enrolled": "yes"}) 5 name = ET.SubElement(personinfo1,"name") 6 age = ET.SubElement(personinfo1, "age", attrib={"checked": "no"}) 7 sex = ET.SubElement(personinfo1, "sex") 8 name.text = 'ztian' 9 age.text = '18' 10 personinfo2 = ET.SubElement(new_xml, "personinfo2", attrib={"enrolled": "no"}) 11 name = ET.SubElement(personinfo2,"name") 12 age = ET.SubElement(personinfo2, "age") 13 name.text = 'laoz' 14 age.text = '19' 15 16 et = ET.ElementTree(new_xml) # 生成文档对象 17 et.write("test.xml", encoding="utf-8", xml_declaration=True) 18 19 ET.dump(new_xml) # 打印生成的格式
8.hashlib模块
python3中用hashlib模块来代替md5模块和sha模块来进行加密,提供SHA1,SHA224,SHA256,SHA384,SHA512,MD5算法。
1 import hashlib 2 3 m = hashlib.md5() 4 m.update(b"Hello") 5 m.update(b"World") 6 print(m.digest()) #结果为HelloWorld的md5加密 7 m.update(b"Hellp Python") 8 9 print(m.digest()) # 2进制格式hash 10 print(m.hexdigest()) # 16进制格式hash 11 print(len(m.hexdigest()))
9.re模块
常用匹配方法
1 re.match #从字符串头开始匹配 2 re.search #从字符串中匹配 3 re.findall #匹配所有要匹配的字符,以列表返回 4 re.splitall #把匹配到的字符当做列表分隔符 5 re.sub #匹配字符并替换
常用正则表达式符号
'.' 默认匹配除\n之外的任意一个字符,若指定flag DOTALL,则匹配任意字符,包括换行 '^' 从字符串头开始匹配,若指定flags MULTILINE,这种也可以匹配上(r"^a","\nabc\neee",flags=re.MULTILINE) '$' 字符串结尾确定,或e.search("foo$","bfoo\nsdfsf",flags=re.MULTILINE).group()也可以 '*' 匹配*号前的字符0次或多次,re.findall("ab*","cabb3abcbbac") 结果为['abb', 'ab', 'a'] '+' 匹配前一个字符1次或多次,re.findall("ab+","ab+cd+abb+bba") 结果['ab', 'abb'] '?' 匹配前一个字符1次或0次 '{m}' 匹配前一个字符m次 '{n,m}' 匹配前一个字符n到m次,re.findall("ab{1,3}","abb abc abbcbbb") 结果'abb', 'ab', 'abb'] '|' 匹配|左或|右的字符,re.search("abc|ABC","ABCBabcCD").group() 结果'ABC' '(...)' 分组匹配,re.search("(abc){2}a(123|456)c", "abcabca456c").group() 结果 abcabca456c '\A' 只从字符开头匹配,re.search("\Aabc","alexabc") 是匹配不到的,同^ '\Z' 匹配字符结尾,同$ '\d' 匹配数字0-9 '\D' 匹配非数字 '\w' 匹配[A-Za-z0-9] '\W' 匹配非[A-Za-z0-9] 's' 匹配空白字符、\t、\n、\r , re.search("\s+","ab\tc1\n3").group() 结果 '\t' '(?P<name>...)' 分组匹配 re.search("(?P<province>[0-9]{2})(?P<city>[0-9]{2})(?P<county>[0-9]{2})(?P<birthday>[0-9]{4})","245356199502152354").groupdict("city") 结果{'province': '24', 'city': '53', 'county' :'56' 'birthday': '1995'}
常用匹配模式
re.I(re.IGNORECASE): 忽略大小写(括号内是完整写法,下同) M(MULTILINE): 多行模式,改变'^'和'$'的行为 S(DOTALL): 点任意匹配模式,改变'.'的行为
