【LeetCode】哈希表 hash_table(共88题)
【1】Two Sum (2018年11月9日,k-sum专题,算法群衍生题)
给了一个数组 nums, 和一个 target 数字,要求返回一个下标的 pair, 使得这两个元素相加等于 target 。
题解:我这次最大范围的优化代码, hash-table + one pass,时间复杂度 O(N),空间复杂度 O(N)。重点在于动态找,一边生成hash-table的同时去找答案,不是先生成hash-table再开始找答案。


1 //这种类似 hash 的能用 unordered_map 就不要用 map, hash-table + one pass 2 class Solution { 3 public: 4 vector<int> twoSum(vector<int>& nums, int target) { 5 const int n = nums.size(); 6 unordered_map<int, int> mp; 7 vector<int> ans(2); 8 for (int i = 0; i < n; ++i) { 9 int key = target - nums[i]; 10 if (mp.find(key) != mp.end()) { 11 ans[0] = mp[key]; 12 ans[1] = i; 13 break; 14 } 15 mp[nums[i]] = i; 16 } 17 return ans; 18 } 19 };
【3】Longest Substring Without Repeating Characters (2019年1月19日,谷歌决战复习,sliding window)
给了一个字符串 s, 返回最长的没有重复字符子串长度。
题解:sliding window, O(N)的算法,同 438题,有一个 unordered_map, 一个 begin,一个end, 开始数就行了。
1 class Solution { 2 public: 3 int lengthOfLongestSubstring(string s) { 4 const int n = s.size(); 5 int begin = 0, end = 0; 6 int ret = 0; 7 unordered_map<char, int> mp; 8 while (end < n) { 9 char c = s[end]; 10 mp[c]++; 11 while (mp[c] > 1) { 12 char tempc = s[begin]; 13 mp[tempc]--; 14 begin++; 15 } 16 ret = max(end - begin + 1, ret); 17 end++; 18 } 19 return ret; 20 } 21 };
【18】4Sum (2018年11月9日,k-sum专题,算法群衍生题)
【30】Substring with Concatenation of All Words (2019年1月19日,谷歌决战复习,sliding window)(提出了一种新的想法)
给了一个 string s,一个 words list, 里面每个 word 一样长,找出 s 中所有子串的位置,子串需要包含 list 中的每个单词。(任意顺序)
Example 1: Input: s = "barfoothefoobarman", words = ["foo","bar"] Output: [0,9] Explanation: Substrings starting at index 0 and 9 are "barfoor" and "foobar" respectively. The output order does not matter, returning [9,0] is fine too. Example 2: Input: s = "wordgoodgoodgoodbestword", words = ["word","good","best","word"] Output: []
题解:sliding window, 用个map记录单词出现的次数。用2 pointers来滑动窗口。遍历 s 数组,O(N * M) 的复杂度
1 class Solution { 2 public: 3 vector<int> findSubstring(string s, vector<string>& words) { 4 const int n = s.size(), m = words.size(); 5 if (n == 0 || m == 0) { return vector<int>(); } 6 const int size = words[0].size(); 7 if (n < m * size) {return vector<int>();} 8 unordered_map<string, int> mp; 9 for (auto w : words) { 10 mp[w]++; 11 } 12 vector<int> ret; 13 for (int i = 0; i + m * size <= n; ++i) { 14 unordered_map<string, int> mpcopy = mp; 15 int k = 0; 16 int start = i; 17 while (k < m) { 18 string str = s.substr(start, size); 19 if (mpcopy.find(str) == mpcopy.end() || mpcopy[str] < 1) { 20 break; 21 } 22 mpcopy[str]--; 23 ++k; 24 start += size; 25 } 26 if (k == m) { 27 ret.push_back(i); 28 } 29 } 30 return ret; 31 } 32 };
【36】Valid Sudoku
【37】Sudoku Solver
【49】Group Anagrams (2019年1月23日,谷歌tag复习)
给了一个单词列表,给所有的异构词分组。
Input: ["eat", "tea", "tan", "ate", "nat", "bat"],
Output:
[
["ate","eat","tea"],
["nat","tan"],
["bat"]
]
题解:我的解法,hashmap + sort。不是最优秀的解法。还有什么用 26个素数代替法,这个更快吧。
代码不贴了。
【76】Minimum Window Substring (2018年1月19日,谷歌决战复习,sliding window)
给了两个字符串,一个 S,一个T,在 S 中找一个子串,包含t中所有的字符,除了包含t中所有的字符之外,还可以用冗余的字符。
Example: Input: S = "ADOBECODEBANC", T = "ABC" Output: "BANC"
题解:还是 hash-map + sliding window,模版套路,先init一个unordered_map, 然后用begin,end,count 这三个变量搞一搞。
1 class Solution { 2 public: 3 string minWindow(string s, string t) { 4 const int ssize = s.size(), tsize = t.size(); 5 if (tsize > ssize) {return "";} 6 unordered_map<char, int> mp; 7 for (auto c : t) { 8 mp[c]++; 9 } 10 int count = 0; 11 int begin = 0, end = 0; 12 string ret = ""; 13 int len = INT_MAX; 14 while (end < ssize) { 15 char tempc = s[end]; 16 if (mp.find(tempc) == mp.end()) { 17 ++end; continue; 18 } 19 mp[tempc]--; 20 if (mp[tempc] == 0) { 21 count++; 22 } 23 while (count == mp.size()) { 24 len = end - begin + 1; 25 string tempAns = s.substr(begin, len); 26 if (ret.empty() || len < ret.size()) { 27 ret = tempAns; 28 } 29 char c = s[begin]; 30 if (mp.find(c) == mp.end()) { 31 ++begin; continue; 32 } 33 mp[c]++; 34 if (mp[c] > 0) { 35 count--; 36 } 37 begin++; 38 } 39 ++end; 40 } 41 return ret; 42 } 43 };
【85】Maximal Rectangle
【94】Binary Tree Inorder Traversal
【136】Single Number
【138】Copy List with Random Pointer
【149】Max Points on a Line (2018年11月10号,算法群)
给了 2D 平面上的 n 个点,两个点能组成一条直线,返回一条直线上最多能有几个点。
题解:本题在数学分类上有,不再这里重复写。math:https://www.cnblogs.com/zhangwanying/p/9790007.html
【159】Longest Substring with At Most Two Distinct Characters (2019年1月19日,谷歌决战复习,sliding window)
给了一个字符串 s,返回一个最长的子串,里面最多包含两个unique的字符。
Example 1: Input: "eceba" Output: 3 Explanation: t is "ece" which its length is 3. Example 2: Input: "ccaabbb" Output: 5 Explanation: t is "aabbb" which its length is 5.
题解:unordered_map + sliding window, 依旧是 一个unordered_map, 三个变量, begin, end, cnt
1 class Solution { 2 public: 3 int lengthOfLongestSubstringTwoDistinct(string s) { 4 const int n = s.size(); 5 if (n <= 2) { return n; } 6 unordered_map<char, int> mp; 7 int begin = 0, end = 0, cnt = 0; 8 int ret = 2; 9 while (end < n) { 10 char c = s[end]; 11 mp[c]++; 12 if (mp[c] == 1) { 13 cnt++; 14 } 15 while (cnt > 2) { 16 char t = s[begin]; //这里写的是t,下面写成了c,debug了好久好久啊,哭死 17 mp[t]--; 18 if (mp[t] == 0) { 19 cnt--; 20 } 21 ++begin; 22 } 23 int len = end - begin + 1; 24 ret = max(len, ret); 25 end++; 26 } 27 return ret; 28 } 29 };
【166】Fraction to Recurring Decimal
【170】Two Sum III - Data structure design
【187】Repeated DNA Sequences
【202】Happy Number
【204】Count Primes
【205】Isomorphic Strings
【217】Contains Duplicate
【219】Contains Duplicate II
【242】Valid Anagram
【244】Shortest Word Distance II
【246】Strobogrammatic Number
给了一个字符串代表一个数字,返回这个数字 upside down 之后是不是和原来数字一样。(返回布尔类型)
Example 1: Input: "69" Output: true Example 2: Input: "88" Output: true Example 3: Input: "962" Output: false
题解:用个 map 表示数字字符上下颠倒后的对应数字字符。务必写全:mp['0'] = '0', mp['1'] = '1', mp['6'] = '9', mp['8'] = '8', mp['9'] = '6';
1 class Solution { 2 public: 3 bool isStrobogrammatic(string num) { 4 map<char, char> mp; 5 mp['0'] = '0', mp['1'] = '1', mp['6'] = '9', mp['8'] = '8', mp['9'] = '6'; 6 string temp = num; 7 reverse(temp.begin(), temp.end()); 8 for (auto& p : temp) { 9 if (mp.find(p) == mp.end()) {return false;} 10 p = mp[p]; 11 } 12 return temp == num; 13 } 14 };
【249】Group Shifted Strings
【266】Palindrome Permutation
【274】H-Index
【288】Unique Word Abbreviation
【290】Word Pattern
【299】Bulls and Cows
【311】Sparse Matrix Multiplication
【314】Binary Tree Vertical Order Traversal
【325】Maximum Size Subarray Sum Equals k
【336】Palindrome Pairs
【340】Longest Substring with At Most K Distinct Characters
【347】Top K Frequent Elements
【349】Intersection of Two Arrays (2018年11月6日,算法群相关题)
给了两个数组,返回他们交叠的元素,如果有重复元素的话,只返回一个就行了。
题解:直接用 set 解了。
1 //题意是给了两个数组,返回他们的重复元素. 2 //我是用了两个set去重,然后O(n) 的时间复杂度遍历出结果。 3 class Solution { 4 public: 5 vector<int> intersection(vector<int>& nums1, vector<int>& nums2) { 6 set<int> st1(nums1.begin(), nums1.end()), st2(nums2.begin(), nums2.end()); 7 vector<int> ans; 8 for (auto num : st1) { 9 if (st2.find(num) != st2.end()) { 10 ans.push_back(num); 11 } 12 } 13 return ans; 14 } 15 };
【350】Intersection of Two Arrays II (2018年11月6日,算法群)
给了两个数组,返回他们所有交叠的元素,元素可以任意顺序返回,但是如果一个元素在A,B数组中都出现多次,需要返回公共的多次。
Example 1: Input: nums1 = [1,2,2,1], nums2 = [2,2] Output: [2,2] Example 2: Input: nums1 = [4,9,5], nums2 = [9,4,9,8,4] Output: [4,9]
题解:用两个map记录每个数组的元素和元素个数,然后遍历一个map,对于两个数组都存在的元素t, 在ret数组里面插入 min(cnt1[t], cnt2[t]). 时间复杂度是 O(N),肯定是线性的。
1 class Solution { 2 public: 3 vector<int> intersect(vector<int>& nums1, vector<int>& nums2) { 4 vector<int> ans; 5 cnt1 = genMap(nums1); 6 cnt2 = genMap(nums2); 7 for (auto p : cnt1) { 8 int t = p.first, times = min(cnt1[t], cnt2[t]); 9 for (int i = 0; i < times; ++i) { 10 ans.push_back(t); 11 } 12 } 13 return ans; 14 } 15 map<int, int> genMap(vector<int>& nums) { 16 map<int, int> ret; 17 for (auto p : nums) { 18 ret[p]++; 19 } 20 return ret; 21 } 22 map<int, int> cnt1, cnt2; 23 };
还有一种方法就是用元素比较少的数组建立map,然后O(N)的遍历另外一个数组。
1 class Solution { 2 public: 3 vector<int> intersect(vector<int>& nums1, vector<int>& nums2) { 4 const int n = nums1.size(), m = nums2.size(); 5 map<int, int> cnt = n <= m ? genMap(nums1) : genMap(nums2); 6 vector<int> ans = n > m ? genAns(nums1, cnt) : genAns(nums2, cnt); 7 return ans; 8 } 9 map<int, int> genMap(const vector<int>& nums) { 10 map<int, int> ret; 11 for (auto p : nums) { 12 ret[p]++; 13 } 14 return ret; 15 } 16 vector<int> genAns(const vector<int>& nums, map<int, int>& cnt) { 17 vector<int> ans; 18 for (auto p : nums) { 19 if (cnt.find(p) != cnt.end() && cnt[p] > 0) { 20 cnt[p]--; 21 ans.push_back(p); 22 } 23 } 24 return ans; 25 } 26 };
本题还有三个follow up:
(1)What if the given array is already sorted? How would you optimize your algorithm?
如果数组已经排好序了,我就不用map了,每个数组用一个指针遍历,相同元素就加到ans数组中。时间复杂度O(N + M),省掉了map。
(2)What if nums1's size is small compared to nums2's size? Which algorithm is better?
如果nums1的size很小,那我就用nums1建立map,然后遍历nums2,往答案数组里面加元素。
(3)What if elements of nums2 are stored on disk, and the memory is limited such that you cannot load all elements into the memory at once?
nums2用数据流读出来(或者 read chunks of array that fit the memory),nums1计算一个map出来,每次nums2中有个元素在map1中对应,就把map1[x]--。
discuss:如果两个array都巨大,memory读不出来,那就先external sort indivisually,每次从排序好的数组里面读出来两个元素,交叠。就和 follow-up1 一样。
【355】Design Twitter
【356】Line Reflection
【358】Rearrange String k Distance Apart
【359】Logger Rate Limiter
【380】Insert Delete GetRandom O(1)
【381】Insert Delete GetRandom O(1) - Duplicates allowed
【387】First Unique Character in a String
【389】Find the Difference
【409】Longest Palindrome (2018年11月14日,为了冲题数做的简单题)(2019年2月18日打卡群复习)
给了一个字符串包含大小写的英文字母(区分大小写,相当于两个字母),问用这个字符串里面的这些字母最长能组成多长的回文串。
题解:我用了一个 map 记录每个字母出现了几次,如果出现了偶数次就直接加次数,出现了奇数次就加奇数次减一。此外,如果有奇数次的话, 最后答案要加1,因为那个字母可以放中心。
1 class Solution { 2 public: 3 int longestPalindrome(string s) { 4 const int n = s.size(); 5 unordered_map<int, int> mp; 6 for (auto c : s) { mp[c]++; } 7 int ret = 0; 8 int add1 = 0; 9 for (auto p : mp) { 10 if (p.second % 2) { 11 add1 = 1; 12 ret += p.second - 1; 13 } else { 14 ret += p.second; 15 } 16 } 17 ret += add1; 18 return ret; 19 } 20 };
【438】Find All Anagrams in a String (2018年1月19日,谷歌决战复习,sliding window)
类似的题目有:
3. Longest Substring Without Repeating Characters
30. Substring with Concatenation of All Words
76. Minimum Window Substring
159. Longest Substring with At Most Two Distinct Characters
438. Find All Anagrams in a String
给了一个字符串 s 和字符串 p,找出 s 中的所有子串,和字符串 p 异构。返回所有满足条件的 s 子串的begin index数组。
题解:这个题暴力解法 tle,我们想一个 O(N+M)的方法。主要就是用类似于一个 sliding window 的写法。
我们用一个 map 存储所有 p 的字符和对应的个数。然后用两个变量 begin 和 end 当作 2 pointers,用 count 变量记录当前子串中已经符合的字符数量。当count == mp.size的时候,我们考虑往前移动 begin 指针。
1 //O(N) 2 class Solution { 3 public: 4 vector<int> findAnagrams(string s, string p) { 5 vector<int> ans; 6 if (s.empty() || p.empty()) { 7 return ans; 8 } 9 const int n = s.size(), m = p.size(); 10 unordered_map<char, int> mp; 11 for (auto c : p) { 12 mp[c]++; 13 } 14 int count = 0; 15 int begin = 0, end = 0; 16 while (end < n) { 17 char c = s[end++]; 18 if (mp.find(c) != mp.end()) { 19 mp[c]--; 20 if(mp[c] == 0) { 21 count++; 22 } 23 } 24 while (count == mp.size()) { 25 char e = s[begin]; 26 if (end - begin == m) { 27 ans.push_back(begin); 28 } 29 if (mp.find(e) != mp.end()) { 30 mp[e]++; 31 if (mp[e] >= 1) { 32 count--; 33 } 34 } 35 begin++; 36 } 37 } 38 return ans; 39 } 40 };
【447】Number of Boomerangs
【451】Sort Characters By Frequency (2018年11月14日,为了冲刺题数)
给了一个字符串 S, 要求给它重新排序,排序的规则是出现次数多的字母堆在一起放前面。
题解:无,我是用了两个map。(有没有更优解不知道,有点不用脑子做题了快)
1 class Solution { 2 public: 3 string frequencySort(string s) { 4 int n = s.size(); 5 unordered_map<char, int> mp; 6 for (auto c : s) { 7 mp[c]++; 8 } 9 map<int, vector<char>> mp2; 10 for (auto p : mp) { 11 mp2[p.second].push_back(p.first); 12 } 13 string ret = ""; 14 for (auto p : mp2) { 15 int cnt = p.first; vector<char> vec = p.second; 16 for (auto e : vec) { 17 ret = string(cnt, e) + ret; 18 } 19 } 20 return ret; 21 } 22 };
【454】4Sum II (2018年11月9日,算法群)
给了四个长度一样的数组A,B,C,D,问从这四个数组中每个数组都选出一个数,这四个数加起来为 0 的种数一共有多少种。
题解:早上无聊看了qc的极客时间,他也就总结了两种有效的方法对于【15】3 Sum这种题型。具体可以看 数组 或者 2 pointers 的专题。不过我觉着都一样吧。
本题就是 hash, 把A,B数组任意两个数的和存在一个 unordered_map 里面,然后遍历 C,D 数组,选择两个元素相加,看在 hash 里面能不能找到这两个数和的相反数。时间复杂度是 O(N^2)。但是需要注意的是 map 这题要 200+ms, unordered_map 只需要 100+ ms。
1 //unordered_map beats 90%+, map beats 30%+ 2 class Solution { 3 public: 4 int fourSumCount(vector<int>& A, vector<int>& B, vector<int>& C, vector<int>& D) { 5 unordered_map<int, int> mapAB = genMap(A, B); 6 int ans = 0; 7 for (int i = 0; i < C.size(); ++i) { 8 for (int j = 0; j < D.size(); ++j) { 9 int value = C[i] + D[j]; 10 if (mapAB.find(-value) != mapAB.end()) { 11 ans += mapAB[-value]; 12 } 13 } 14 } 15 return ans; 16 } 17 unordered_map<int, int> genMap(const vector<int>& A, const vector<int>& B) { 18 unordered_map<int, int> cnt; 19 for (int i = 0; i < A.size(); ++i) { 20 for (int j = 0; j < B.size(); ++j) { 21 int summ = A[i] + B[j]; 22 cnt[summ]++; 23 } 24 } 25 return cnt; 26 } 27 28 };
【463】Island Perimeter (计算岛的周长)(2018年11月13日,为了冲点题数做的)(2019年2月4日,算法群打卡)
给了一个二维的grid,里面是 0/ 1 矩阵, 0代表水,1代表陆地。一个小方块的边长是 1。 问陆地组成的岛的周长是多少。
Input: [[0,1,0,0], [1,1,1,0], [0,1,0,0], [1,1,0,0]] Output: 16 Explanation: The perimeter is the 16 yellow stripes in the image below:
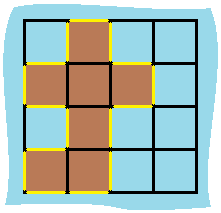
题解:我直接二维数组遍历了,没用搜索。
1 class Solution { 2 public: 3 int islandPerimeter(vector<vector<int>>& grid) { 4 int ret = 0; 5 int n = grid.size(), m = grid[0].size(); 6 for (int i = 0; i < n; ++i) { 7 for (int j = 0; j < m; ++j) { 8 int temp = 0; 9 if (grid[i][j] == 1) { 10 if (i == 0) {temp += 1;} 11 if (i == n - 1) {temp += 1;} 12 if (j == 0) {temp += 1;} 13 if (j == m - 1) {temp += 1;} 14 for (int k = 0; k < 4; ++k) { 15 int newx = i + dirx[k], newy = j + diry[k]; 16 if (newx < 0 || newx >= n || newy < 0 || newy >= m) {continue;} 17 if (grid[newx][newy] == 0) {temp += 1;} 18 } 19 } 20 ret += temp; 21 } 22 } 23 return ret; 24 } 25 int dirx[4] = {-1, 0, 1, 0}; 26 int diry[4] = {0, -1, 0, 1}; 27 28 };
2019年2月4日更新。看了花花酱的视频感觉和我一开始想的差不多。时间复杂度都是 O(N^3)
1 class Solution { 2 public: 3 int islandPerimeter(vector<vector<int>>& grid) { 4 int ret = 0; 5 int n = grid.size(), m = grid[0].size(); 6 for (int i = 0; i < n; ++i) { 7 for (int j = 0; j < m; ++j) { 8 if (grid[i][j] == 1) { 9 ret += 4; 10 if (i > 0 && grid[i-1][j]) { --ret; } 11 if (i < n-1 && grid[i+1][j]) { --ret; } 12 if (j > 0 && grid[i][j-1]) { --ret; } 13 if (j < m-1 && grid[i][j+1]) { --ret; } 14 } 15 } 16 } 17 return ret; 18 } 19 20 };
【500】Keyboard Row
【508】Most Frequent Subtree Sum
【525】Contiguous Array (2019年1月9日,算法群)
给了一个0/1数组,返回最长的子数组长度,要求是子数组里面的0和1的个数相等。
题解:先求前缀和,对于元素0,碰到了要当成-1。 这样如果一个子数组里面刚好有相同个数的0和1的话,他们的和就是0。用一个hash-map保存前缀和第一次出现的位置。下次如果遇到了前面已经出现过的前缀和,就说明这个区间里面元素和为0。更新结果。
1 class Solution { 2 public: 3 int findMaxLength(vector<int>& nums) { 4 const int n = nums.size(); 5 vector<int> summ(n+1, 0); 6 unordered_map<int, int> hash; 7 hash[0] = 0; 8 int ans = 0; 9 for (int i = 1; i < n+1; ++i) { 10 summ[i] = summ[i-1] + (nums[i-1] == 0 ? -1 : nums[i-1]); 11 if (hash.find(summ[i]) != hash.end()) { 12 ans = max(ans, i - hash[summ[i]]); 13 } else { 14 hash[summ[i]] = i; 15 } 16 } 17 return ans; 18 } 19 };
【535】Encode and Decode TinyURL (2019年2月11日,谷歌tag题)
实现两个方法,string encode(string longUrl), string decode(string shortUrl) 。
题解:我是用了一个map,base62编码,用一个count变量用来生成key,map的结构是 key -> longUrl。 这样的缺点是如果一个longUrl访问多次,会多次占用count和map空间。可以搞成两个map。
1 class Solution { 2 public: 3 const string vars = "0123456789abcdefghijklmnopqrstuvwxyzABCDEFGHIJKLMNOPQRSTUVWXYZ"; 4 // Encodes a URL to a shortened URL. 5 string encode(string longUrl) { 6 string key = getKey(); 7 mp[key] = longUrl; 8 return "http://tinyurl.com/" + key; 9 } 10 // Decodes a shortened URL to its original URL. 11 string decode(string shortUrl) { 12 int pos = shortUrl.find_last_of('/'); 13 string key = shortUrl.substr(pos+1); 14 return mp[key]; 15 } 16 string getKey() { 17 int number = count; 18 string key = ""; 19 while (number > 0) { 20 key = key + string(1, vars[number % 62]); 21 number /= 62; 22 } 23 ++count; 24 return key; 25 } 26 int count = 1; 27 unordered_map<string, string> mp; 28 }; 29 30 // Your Solution object will be instantiated and called as such: 31 // Solution solution; 32 // solution.decode(solution.encode(url));
【554】Brick Wall
【560】Subarray Sum Equals K
【575】Distribute Candies
【594】Longest Harmonious Subsequence
【599】Minimum Index Sum of Two Lists (2018年11月27日)
给了两个字符串数组,每个字符串数组代表一个人的最喜欢的饭馆的名字,返回两个人都喜欢的饭馆,并且这两个饭馆字符串的下标和最小的饭馆名称。
题解:用了unordered_map直接解答了。
1 class Solution { 2 public: 3 vector<string> findRestaurant(vector<string>& list1, vector<string>& list2) { 4 unordered_map<string, int> mp; 5 for (int i = 0; i < list1.size(); ++i) { 6 mp[list1[i]] = i; 7 } 8 int minSum = list1.size() + list2.size(); 9 unordered_map<int, vector<string>> record; 10 for (int i = 0; i < list2.size(); ++i) { 11 string word = list2[i]; 12 if (mp.find(word) == mp.end()) {continue;} 13 if (minSum == mp[word] + i) { 14 record[minSum].push_back(word); 15 } else if (minSum > mp[word] + i) { 16 minSum = mp[word] + i; 17 record[minSum].push_back(word); 18 } 19 } 20 return record[minSum]; 21 } 22 };
【609】Find Duplicate File in System
【624】Maximum Distance in Arrays
【632】Smallest Range
【645】Set Mismatch
【648】Replace Words
【676】Implement Magic Dictionary (2019年3月13日,google tag)
设计一个魔法字典,完成两个 api。
Implement a magic directory with buildDict, and search methods.
For the method buildDict, you'll be given a list of non-repetitive words to build a dictionary.
For the method search, you'll be given a word, and judge whether if you modify exactly one character into another character in this word, the modified word is in the dictionary you just built.
Example 1:
Input: buildDict(["hello", "leetcode"]), Output: Null
Input: search("hello"), Output: False
Input: search("hhllo"), Output: True
Input: search("hell"), Output: False
Input: search("leetcoded"), Output: False
Note:
- You may assume that all the inputs are consist of lowercase letters
a-z. - For contest purpose, the test data is rather small by now. You could think about highly efficient algorithm after the contest.
- Please remember to RESET your class variables declared in class MagicDictionary, as static/class variables are persisted across multiple test cases. Please see here for more details.
题解:用一个set存储 wordlist,用另外一个存储邻居,比如 apple 的邻居可以是 *pple, a*ple, ap*le, app*e, appl*, 这五个。
在search中对于输入的单词,先把每个字母都先隐藏一下看能不能变成邻居的set中的元素。如果能的话,看是不是wordlist中的单词,如果是的话,那么需要 neighbors.count(word) >= 2 才行。
1 //build time: O(NM), space: O(NM) 2 //search: time O(N) 3 class MagicDictionary { 4 public: 5 /** Initialize your data structure here. */ 6 MagicDictionary() { 7 8 } 9 10 /** Build a dictionary through a list of words */ 11 void buildDict(vector<string> dict) { 12 stdict = unordered_set(dict.begin(), dict.end()); 13 for (auto& word: dict) { 14 for (int i = 0; i < word.size(); ++i) { 15 string s = word; 16 s[i] = '*'; 17 neighbors.insert(s); 18 } 19 } 20 } 21 22 /** Returns if there is any word in the trie that equals to the given word after modifying exactly one character */ 23 bool search(string word) { 24 for (int i = 0; i < word.size(); ++i) { 25 string s = word; 26 s[i] = '*'; 27 if (neighbors.count(s) >= 1 && stdict.count(word) == 0) {return true;} 28 if (neighbors.count(s) > 1 && stdict.count(word) == 1) {return true;} 29 } 30 return false; 31 } 32 unordered_set<string> stdict; 33 multiset<string> neighbors; 34 }; 35 36 /** 37 * Your MagicDictionary object will be instantiated and called as such: 38 * MagicDictionary obj = new MagicDictionary(); 39 * obj.buildDict(dict); 40 * bool param_2 = obj.search(word); 41 */
【690】Employee Importance
【692】Top K Frequent Words
【694】Number of Distinct Islands
【705】Design HashSet (2019年2月12日)
设计一个hashset。
题解:用个1D-array或者一个 2D-array。时间复杂度分析:三个接口都是 O(1),空间复杂度分析,最差O(N)。
1 class MyHashSet { 2 public: 3 /** Initialize your data structure here. */ 4 MyHashSet() { 5 data.resize(1000); 6 } 7 8 void add(int key) { 9 int r = key % 1000, c = key / 1000; 10 if (data[r].empty()) { 11 data[r] = vector<bool>(1000, false); 12 } 13 data[r][c] = true; 14 } 15 16 void remove(int key) { 17 int r = key % 1000, c = key / 1000; 18 if (data[r].empty()) {return;} 19 data[r][c] = false; 20 } 21 22 /** Returns true if this set contains the specified element */ 23 bool contains(int key) { 24 int r = key % 1000, c = key / 1000; 25 if (data[r].empty()) {return false;} 26 return data[r][c]; 27 } 28 vector<vector<bool>> data; 29 }; 30 31 /** 32 * Your MyHashSet object will be instantiated and called as such: 33 * MyHashSet obj = new MyHashSet(); 34 * obj.add(key); 35 * obj.remove(key); 36 * bool param_3 = obj.contains(key); 37 */
【706】Design HashMap (2019年2月12日)
设计一个hashmap。
题解:用个1D-array或者一个 2D-array。时间复杂度分析 三个接口都是 O(1),空间复杂度分析,最差O(N)。
1 class MyHashMap { 2 public: 3 /** Initialize your data structure here. */ 4 MyHashMap() { 5 data.resize(1000); 6 } 7 8 /** value will always be non-negative. */ 9 void put(int key, int value) { 10 int r = key % 1000, c = key / 1000; 11 if (data[r].empty()) { 12 data[r] = vector<int>(1000, -1); 13 } 14 data[r][c] = value; 15 } 16 17 /** Returns the value to which the specified key is mapped, or -1 if this map contains no mapping for the key */ 18 int get(int key) { 19 int r = key % 1000, c = key / 1000; 20 if (data[r].empty()) {return -1;} 21 return data[r][c]; 22 } 23 24 /** Removes the mapping of the specified value key if this map contains a mapping for the key */ 25 void remove(int key) { 26 int r = key % 1000, c = key / 1000; 27 if (data[r].empty()) {return;} 28 data[r][c] = -1; 29 } 30 vector<vector<int>> data; 31 }; 32 33 /** 34 * Your MyHashMap object will be instantiated and called as such: 35 * MyHashMap obj = new MyHashMap(); 36 * obj.put(key,value); 37 * int param_2 = obj.get(key); 38 * obj.remove(key); 39 */
【710】Random Pick with Blacklist
【711】Number of Distinct Islands II
【718】Maximum Length of Repeated Subarray
【720】Longest Word in Dictionary
【726】Number of Atoms
【734】Sentence Similarity
【739】Daily Temperatures
【748】Shortest Completing Word
【760】Find Anagram Mappings
【770】Basic Calculator IV
【771】Jewels and Stones
【781】Rabbits in Forest
【811】Subdomain Visit Count
【846】Hand of Straights(不好意思,本来是map分类,然鹅map分类一共就两个题,我就放在了这里orz)
小红有一堆纸牌,每张纸牌上有一个数字,问能不能把纸牌均匀的分成每组 W 张,每组的数字都是连续递增 1 的。
Example 1: Input: hand = [1,2,3,6,2,3,4,7,8], W = 3 Output: true Explanation: Alice's hand can be rearranged as [1,2,3],[2,3,4],[6,7,8]. Example 2: Input: hand = [1,2,3,4,5], W = 4 Output: false Explanation: Alice's hand can't be rearranged into groups of 4. 1 <= hand.length <= 10000 0 <= hand[i] <= 10^9 1 <= W <= hand.length
题解:我本来想排序之后二分的,但是点了下tag,tag 写的是 map, 我就往 map 上面想了。用了 map 能 AC 但是时间上比较差。还要看别人的题解,要记得看discuss。
1 class Solution { 2 public: 3 bool isNStraightHand(vector<int>& hand, int W) { 4 const int n = hand.size(); 5 if (n % W != 0) {return false;} 6 map<int, int> mp; 7 for (auto p : hand) { 8 mp[p]++; 9 } 10 int cnt(0); 11 while (cnt < n / W) { 12 int begin; 13 for (auto ele : mp) { 14 if (ele.second > 0) { 15 begin = ele.first; 16 break; 17 } 18 } 19 int num = begin; 20 for (; num < begin + W; ++num) { 21 if (mp.find(num) == mp.end() || mp[num] <= 0) { 22 return false; 23 } 24 mp[num]--; 25 } 26 cnt++; 27 } 28 return true; 29 } 30 };
【884】Uncommon Words from Two Sentences
【895】Maximum Frequency Stack

 浙公网安备 33010602011771号
浙公网安备 33010602011771号