
ptmalloc2
本文参考华庭(庄明强)的ptmalloc2 源码剖析
- 简介:
ptmalloc实现了malloc(),free()以及一组其他函数,以提供动态内存管理,同时支持多线程。分配器处于用户空间和内核空间之间,响应用户的分配请求,向操作系统申请内存。总体思想是先“批发”一块大内存,而后“零售”给用户,同时也实现了高效的回收机制。
- Main_area / non_main_area(主分配区和非主分配区):
在linux之前版本使用的内存分配机制只有一个主分配区,然而多线程下访问要加锁,所以在ptmalloc中区分出了主分区和非主分区。主分区只有一个,而非主分区可以有多个,分区一旦增加就不会减少。
主分区可以访问heap和memory mapping segment(可调用brk()/sbrk()/mmap()),而非主分区只能访问memory mapping segment(只可以调用mmap())。
- chunk组织
ptmalloc通过chunk来管理内存,给User data前存储了一些信息,使用边界标记区分各个chunk。
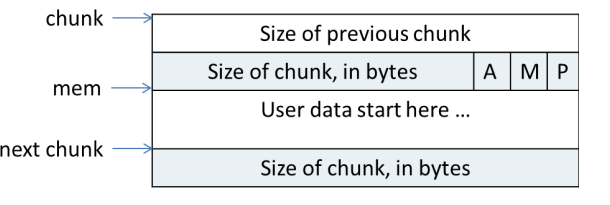
这个是一个使用中的chunk,返回给用户的指针是上图的mem,在mem上方分别存放了前一个chunk的大小和本chunk的大小,chunk对齐(alignment = 2 ^n; n>=3),对于默认8字节对齐后10个bit为一定为0,则可以用后3个bit存储其他信息。
A:1表示主分配区 0表示非主分配区
M:表示是否使用mmap()直接从进程mmap映射区域分配, 1表示是, 0表示不是。(ptmalloc认为长生命周期的大内存使用mmap,回收一个由mmap直接映射的内存时会更改mmap分配和收缩阈值,因为如果频繁使用mmap()分配内存,每次mmap映射物理页需要将物理页清零,浪费系统资源)。
p:1表示前一个chunk正在使用,0表示前一个chunk为空闲。
- chunk的空间复用和边界标记法
对于空闲的chunk增加了额外的指针
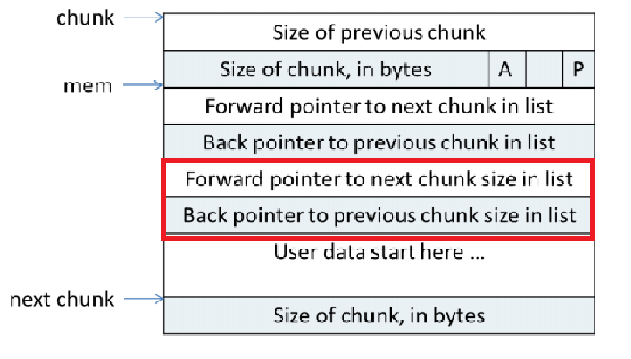
红色框住的只有在较大的chunk中才存在。
为了使chunk所占空间最小,使用了空间复用
由于对于ptmalloc来说每次都是向操作系统申请一大块内存,然后分割成不同的chunk,所以对于查找上一个chunk直接可以用chunk指针减去前一个的大小,查找下一个也是同样的道理,只用计算指针就方便的多。同时在后面的合并中也只用改结构体中相应的值即可。
p位标识了前一个chunk是否空闲,如果p为1时(前一块正在使用),Sizeof previous chunk就没有意义,而这块空间就可以被上一块有数据的chunk使用。下图简单地表示了chunk的空间复用
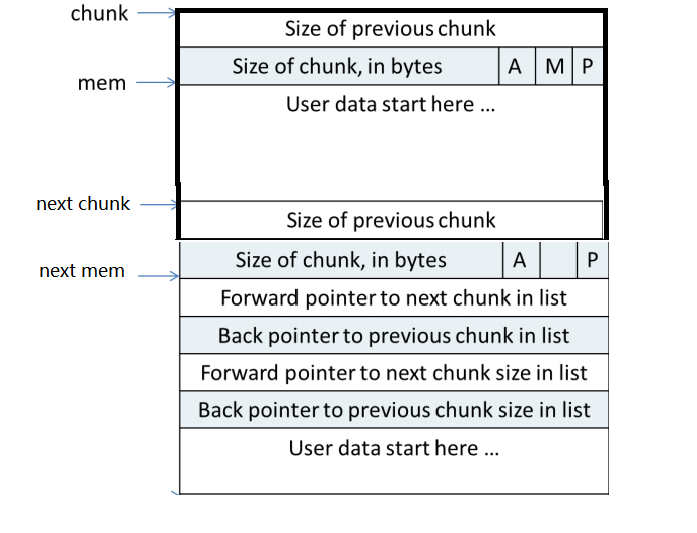
所以对于此处的next chunk中的prev域虽然是属于他的,但里面内容却存放的是上一个chunk的User data,而上一个chunk的size 应该为 (data + 8 - 4)align to 8B,这个就是实际分配的内存大小。
边界标记法:简单来说类似于循环首次适应算法,因为空闲的chunk组成了一个双向循环链表,确保了内存分配不会因为首次适应积攒在头部。
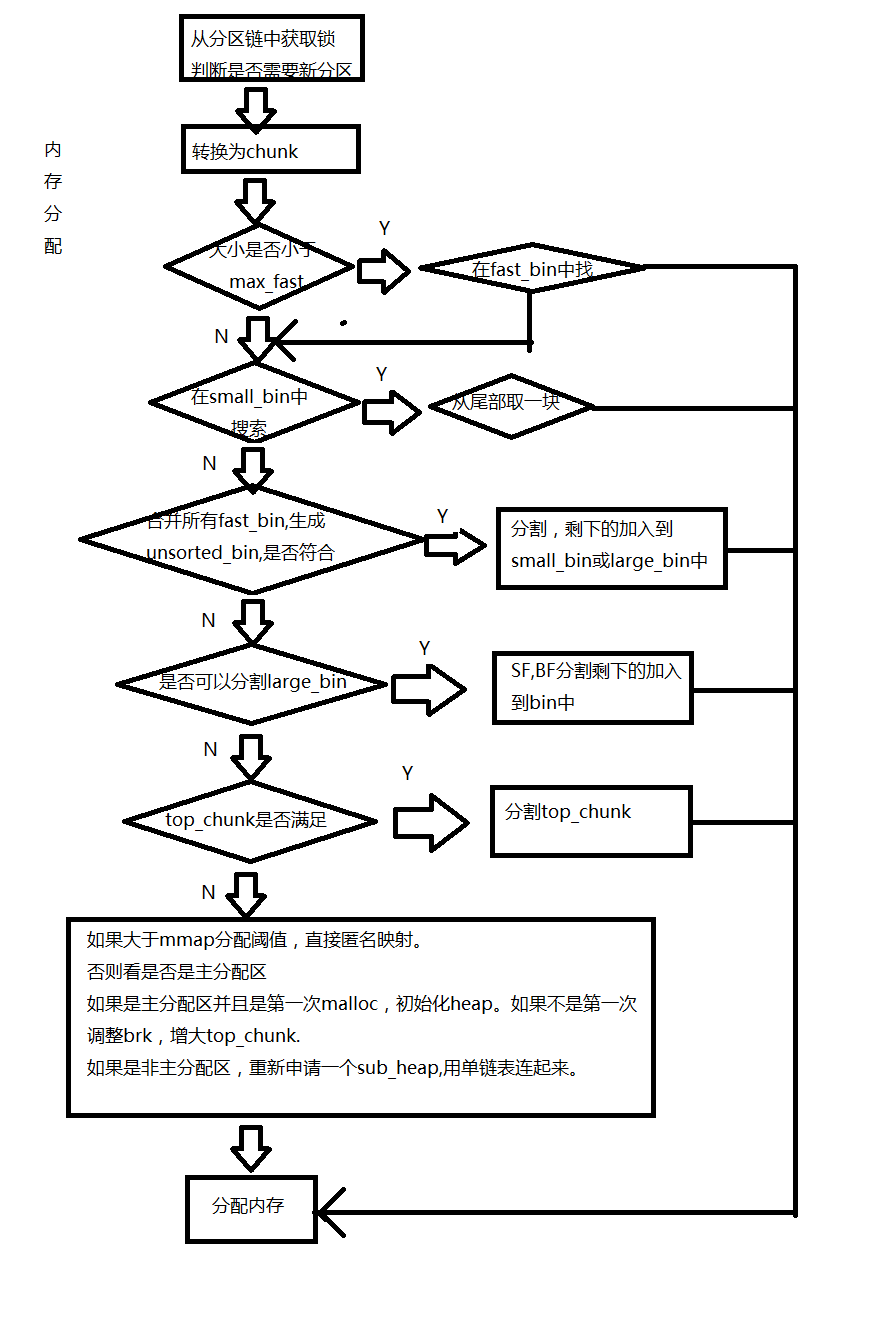
- 内存分配过程:(分配回收过程文档中有详细说明)
- 内存回收过程
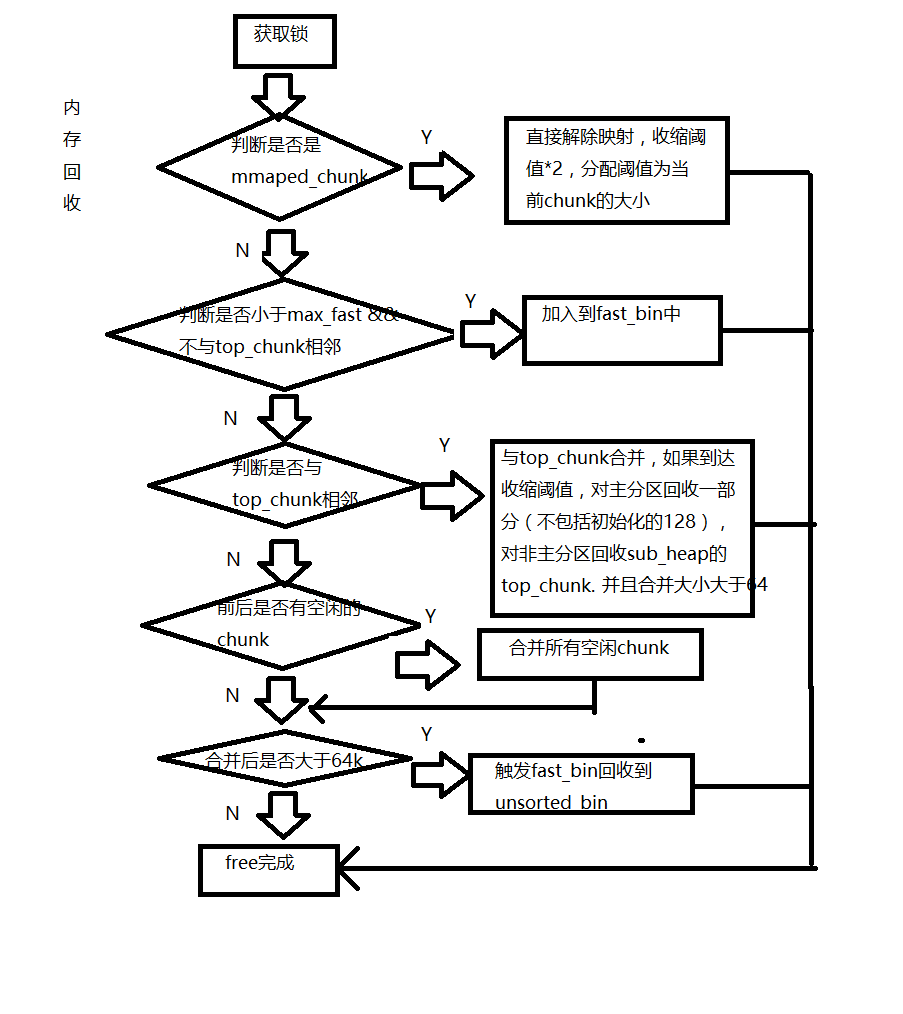
- 配置选项
- M_MXFAST:设置fast bin中最大大小。多使用fast bin效率很高但设置的过大会导致内存随便过多,频繁清理合并fast bin会因加锁而影响效率。
- M_TRIM_THRESHOLD:设置mmap收缩阈值,-1关闭收缩
- M_MMAP_THRESHOLD:设置mmap分配阈值,默认128k
- M_MMAP_MAX:设置使用mmap分配内存的最大块数,默认64k
- 避免Glibc内存暴增
- 后分配的先释放,因为ptmalloc收缩内存只能够从top chunk开始,所以当离top chunk最近的那一块内存没有释放时,ptmalloc是不会释放收缩的。
- 防止内存泄漏,如果泄露的刚好是top chunk最近的内存,则无法收缩
- 不合适管理长生命周期的内存
- 可以通过优化配置按照实际情况优化
- 多线程不适合 对于非主分区一旦增加不会减少,所以在对锁竞争激烈时,会快速的增加非主分配去,当到达最大值时,无法增加非主分配区从而降低了效率。
- 对于小块的内存需要精确匹配,而对于large bin中则需要切割,多线程下由于不断的分割会产生很多内存碎片,对内存碎片的清理要加锁,会降低效率。

