


机器学习(二) 机器学习基础
一、机器学习世界的数据
机器学习基础概念
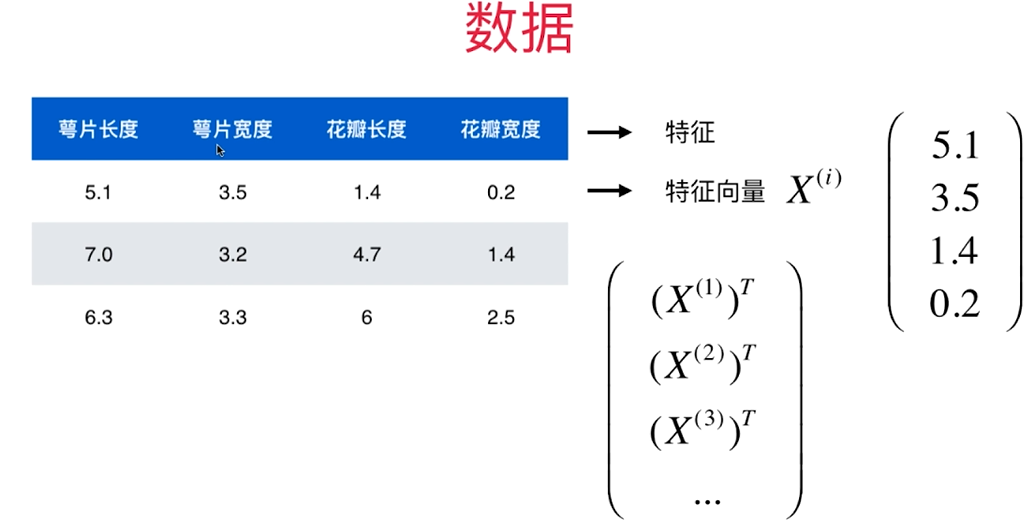
关于数据

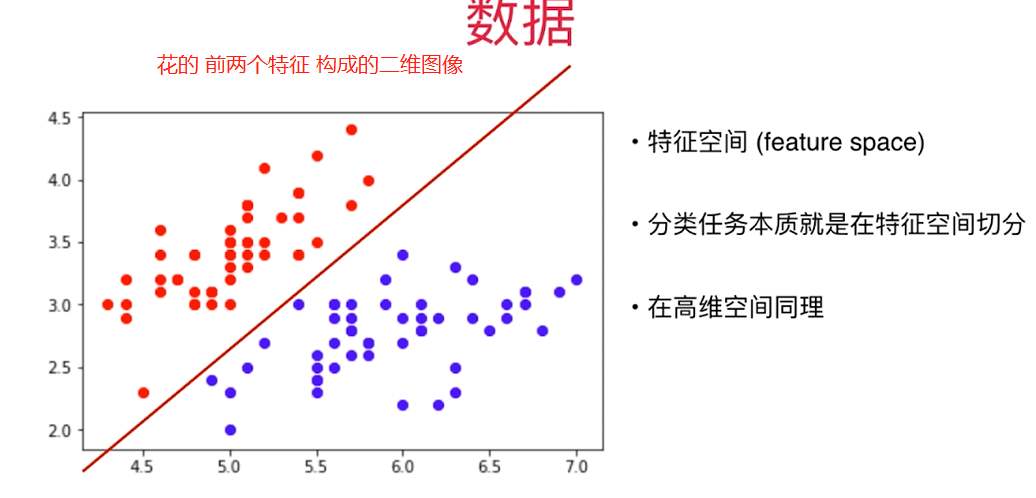

二、机器学习的主要任务
监督学习: 机器学习的基本任务,具体可以做什么?
1.分类任务。
二分类,多分类:识别图片,数字识别等
2.回归任务。
结果是一个连续数字的值,而非一个类别;
回归任务可以划分成分类任务。
三、监督学习,非监督学习、半监督学习和增强学习
监督学习:
给机器的训练数据拥有‘标记’或者‘答案’。
例如:
1.图像已经拥有了标定信息
2.银行已经积累了一定的客户信息和他们信用卡的信用情况
3.医院已经积累了一定的病人信息和他们最终确诊是否患病的情况
4.市场积累了房屋的基本信息和最终成交的金额
...
我接下来写的基本都是监督学习的算法:
K邻近
线性回归和多项式回归
逻辑回归
SVM
决策树和随机森林
非监督学习:
给机器的训练数据没有任何‘标记’或者‘答案’。
例如:

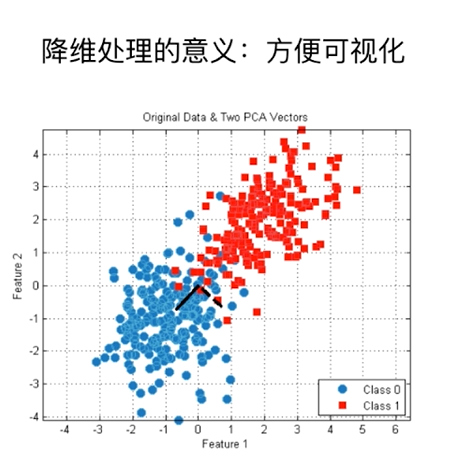
对数据进行降维处理
特征提取:信用卡的信用评级和人的胖瘦无关?
特征压缩:PCA(在尽量少的损失信息的情况下将高维的特征想想压缩成低维的特征向量)
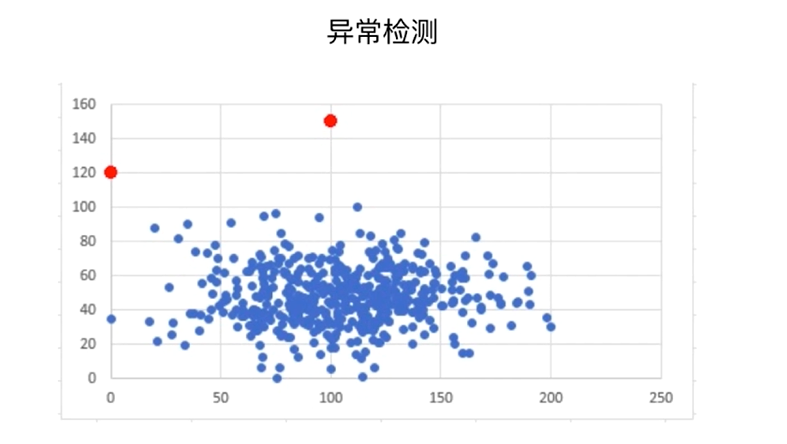
半监督学习:
一部分数据有‘标记’或者‘答案’,另一部分数据没有。
更常见:各种原因产生的标记缺失。
通常都是先使用无监督学习手段对数据做处理,之后用监督学习手段做模型的训练的预测。
增强学习:

无人驾驶、机器人。
监督学习和半监督学习是基础。
四、批量学习、在线学习、参数学习和非参数学习
1.批量学习 Batch Learning
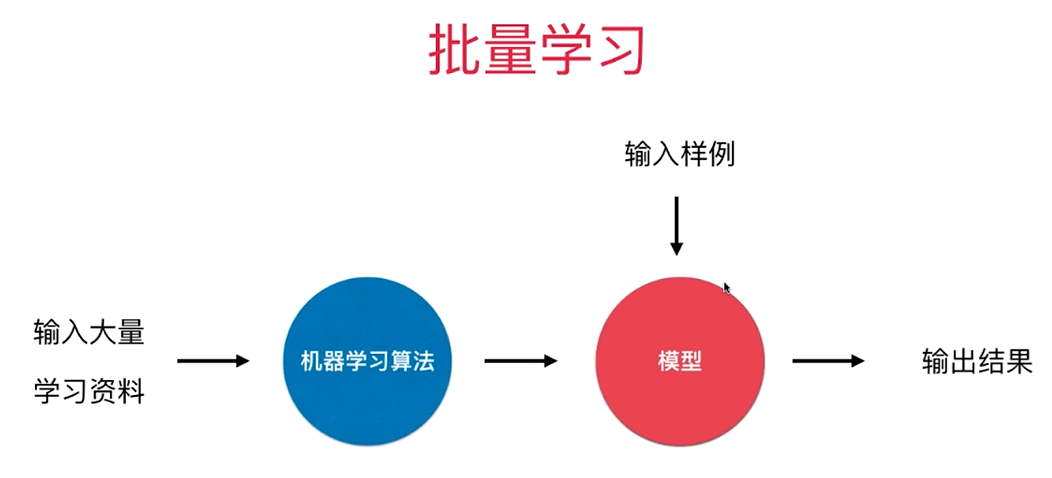
优点:简单
问题:如何适应环境变化?
解决方案:定时重新批量学习。
缺点:每次重新批量学习,运算巨大,在某些环境变化非常快的情况下,甚至不可能的。
2.在线学习 Online Learning
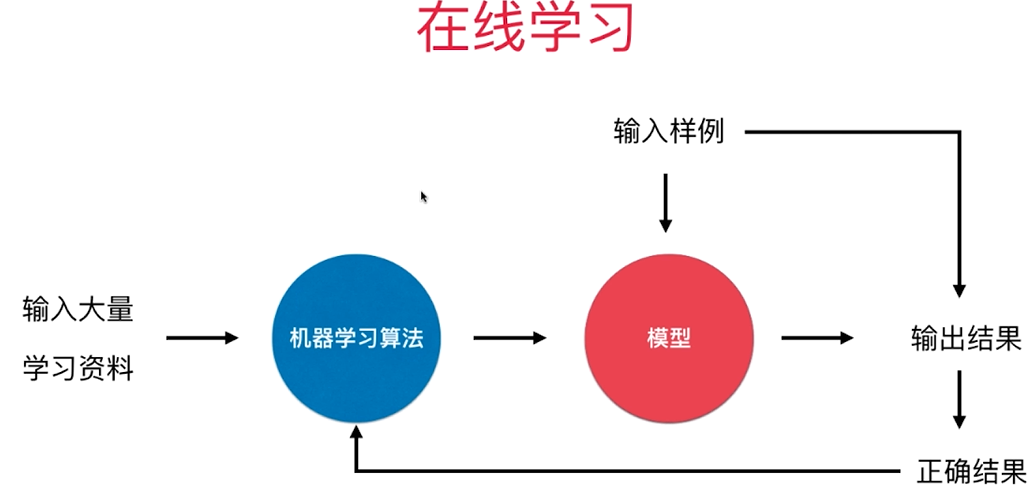
优点:即使反映新的环境变化。
问题:新的数据带来不好的变化?
解决方案:需要加强对数据进行监控。
其他:也适用于数据量巨大,完全无法批量学习的环境。
3.参数学习 Parametric Learning
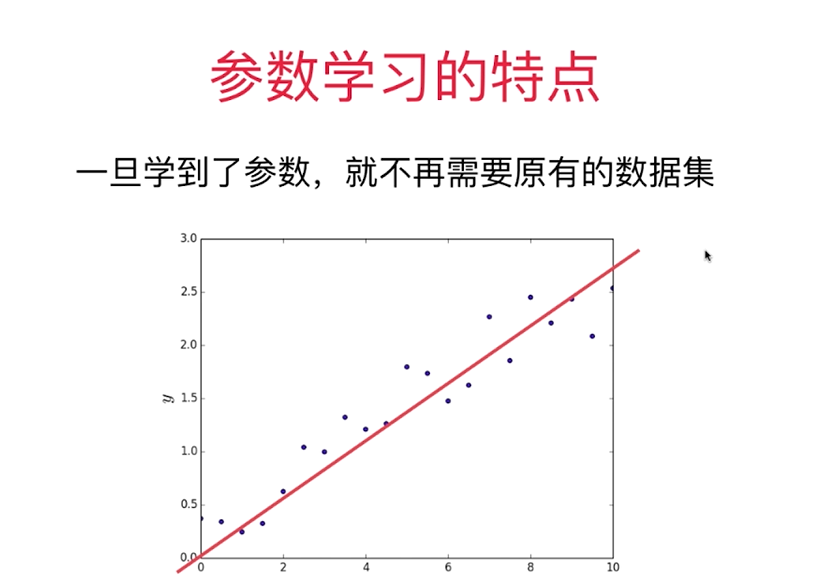
利用原有数据集,找到参数,求得方程,不需要原来参数。
4.非参数学习 Nonparametric Lrearning
1. 不对模型进行过多假设。
2.非参数不等于没参数。
五、和机器学习相关的‘哲学’思想
数据即算法?
1.数据确实非常重要。
2.数据驱动
收集更多的数据
提高数据质量
提高数据的代表性
研究更重要的特征
奥卡姆的剃刀:
简单的就好。
到底在机器学习领域,什么叫做‘简单’
没有免费的午餐定理:
可以严格地数学推导出:任意两个算法,他们的期望性能事相同的!
具体到某个特定问题,有些算法可能更好。
但是没有一种算法,绝对比另一种算法好。
脱离具体问题,谈哪个算法好是没有意义的。
在面对一个具体问题的时候,尝试使用多种算法进行对比试验,是必要的。
其他思考?
面对不确定的世界,怎么看待使用机器学习进行预测的结果?
六、环境搭建
ANACONDA python一键安装环境
https://www.anaconda.com/ 官网 免费下载
IDE Pycharm
github.com/liuyubobobo/Play-with-Machine-Learning-Algorithms
我写的文章只是我自己对bobo老师讲课内容的理解和整理,也只是我自己的弊见。bobo老师的课 是慕课网出品的。欢迎大家一起学习。

