
TCP/IP协议栈在Linux内核中的运行时序分析
1 调研要求
在深入理解Linux内核任务调度(中断处理、softirg、tasklet、wq、内核线程等)机制的基础上,分析梳理send和recv过程中TCP/IP协议栈相关的运行任务实体及相互协作的时序分析。
编译、部署、运行、测评、原理、源代码分析、跟踪调试等。
应该包括时序。
2 Linux内核
2.1 Linux系统层次结构
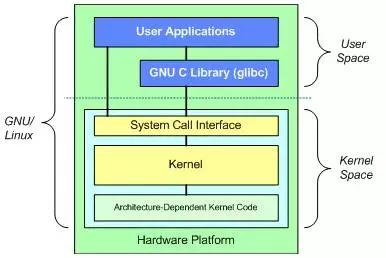
图1 Linux系统层次结构
Linux系统包含两部分,用户空间和内核空间。
最上面是用户(或应用程序)空间。这是用户应用程序执行的地方。用户空间之下是内核空间,Linux 内核正是位于这里。GNU C Library (glibc)也在这里。它提供了连接内核的系统调用接口,还提供了在用户空间应用程序和内核之间进行转换的机制。这点非常重要,因为内核和用户空间的应用程序使用的是不同的保护地址空间。每个用户空间的进程都使用自己的虚拟地址空间,而内核则占用单独的地址空间。
Linux 内核可以进一步划分成 3 层。最上面是系统调用接口,它实现了一些基本的功能,例如 read 和 write。系统调用接口之下是内核代码,可以更精确地定义为独立于体系结构的内核代码。这些代码是 Linux 所支持的所有处理器体系结构所通用的。在这些代码之下是依赖于体系结构的代码,构成了通常称为 BSP(Board Support Package)的部分。这些代码用作给定体系结构的处理器和特定于平台的代码。
Linux 内核实现了很多重要的体系结构属性。在或高或低的层次上,内核被划分为多个子系统。Linux 也可以看作是一个整体,因为它会将所有这些基本服务都集成到内核中。这与微内核的体系结构不同,后者会提供一些基本的服务,例如通信、I/O、内存和进程管理,更具体的服务都是插入到微内核层中的。每种内核都有自己的优点,不过这里并不对此进行讨论。
2.2 Linux内核体系结构
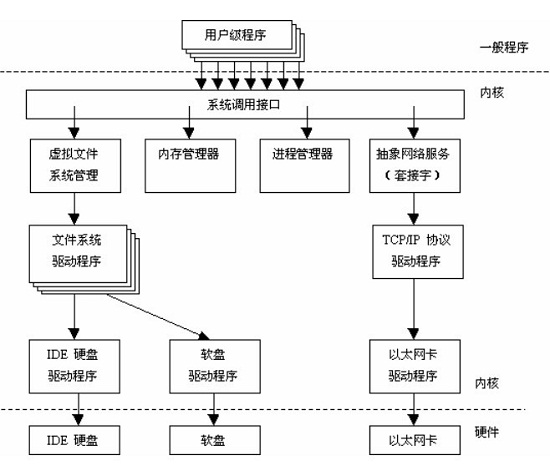
图2 Linux内核体系结构
Linux内核的主要组件有:系统调用接口、进程管理、内存管理、虚拟文件系统、网络堆栈、设备驱动程序、硬件架构的相关代码。
(1) 系统调用接口
SCI 层提供了某些机制执行从用户空间到内核的函数调用。SCI 实际上是一个非常有用的函数调用多路复用和多路分解服务。在 ./linux/kernel 中可以找到 SCI 的实现,并在 ./linux/arch 中找到依赖于体系结构的部分。
(2)进程管理
进程管理的重点是进程的执行。在内核中,这些进程称为线程,代表了单独的处理器虚拟化(线程代码、数据、堆栈和 CPU 寄存器)。内核通过 SCI 提供了一个应用程序编程接口(API)来创建一个新进程(fork、exec 或 Portable Operating System Interface [POSIX] 函数),停止进程(kill、exit),并在它们之间进行通信和同步(signal 或者 POSIX 机制)。可以在 ./linux/kernel 中找到进程管理的源代码,在 ./linux/arch 中可以找到依赖于体系结构的源代码
(3)内存管理
内核所管理的另外一个重要资源是内存。为了提高效率,内存是按照所谓的内存页方式进行管理的(对于大部分体系结构来说都是 4KB)。Linux 包括了管理可用内存的方式,以及物理和虚拟映射所使用的硬件机制。内存管理的源代码可以在 ./linux/mm 中找到。
(4)虚拟文件系统
虚拟文件系统(VFS)是 Linux 内核中非常有用的一个方面,因为它为文件系统提供了一个通用的接口抽象。VFS 在 SCI 和内核所支持的文件系统之间提供了一个交换层。文件系统的源代码可以在 ./linux/fs 中找到。
(5)网络堆栈
网络堆栈在设计上遵循模拟协议本身的分层体系结构。Internet Protocol (IP) 是传输协议(TCP)下面的核心网络层协议。TCP 上面是 socket 层,它是通过 SCI 进行调用的。socket 层是网络子系统的标准 API,它为各种网络协议提供了一个用户接口。从原始帧访问到 IP 协议数据单元(PDU),再到 TCP 和 User Datagram Protocol (UDP),socket 层提供了一种标准化的方法来管理连接,并在各个终点之间移动数据。内核中网络源代码可以在 ./linux/net 中找到。
(6)设备驱动程序
Linux 内核中有大量代码都在设备驱动程序中,它们能够运转特定的硬件设备。Linux 源码树提供了一个驱动程序子目录,这个目录又进一步划分为各种支持设备,例如 Bluetooth、I2C、serial 等。设备驱动程序的代码可以在 ./linux/drivers 中找到。
(7)依赖体系结构的代码
尽管 Linux 很大程度上独立于所运行的体系结构,但是有些元素则必须考虑体系结构才能正常操作并实现更高效率。./linux/arch 子目录定义了内核源代码中依赖于体系结构的部分。
2.3 Linux内核的调度机制
(1)进程状态
进程状态分为运行状态,睡眠状态,停止状态,死亡状态,它们之间有复杂的转化关系。
R运行状态(runing): 表明进程要么在运行中要么在运行队列里,并不意味着进程一定在运行中。
S睡眠状态(sleeping):意味着进程在等待事件的完成(这里的睡眠有时候也叫做可中断睡眠)
D磁盘睡眠状态(Disk sleep): 有时候也叫做不可中断睡眠,在这个状态的进程通常会等待IO的结束
T停止状态(stopped):可以通过发送SIGSTOP信号给进程来停止(T)进程。这个被暂停的进程可以通过发送SIGCNT信号让进程继续运行。
X死亡状态(dead):这个状态只是一个返回状态,你不会在任务列表里看到这个状态。
Z僵尸进程(zombie):
1.僵尸状态是一个比较特殊的状态。当进程退出并且父进程没有读取到子进程退出的返回代码时就会产生僵尸进程
2.僵尸进程会以终止状态保持在进程表中,并且会一直等待父进程读取退出状态代码
3.所以,只要子进程退出,父进程还在运行,但父进程没有读取子进程的状态,子进程就进去僵尸状态
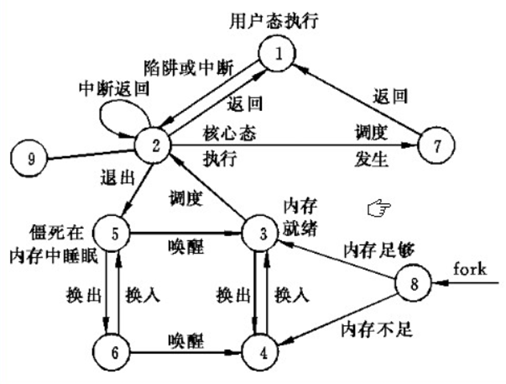
图3 进程状态转换图
(2) 调度策略
传统的Unix操作系统必须实现几个目标,于是引入调度策略:
l 进程响应时间尽可能快
l 后台作业的吞吐量尽可能高
l 尽可能避免进程的饥饿现象
l 低优先级和高优先级进程的需要尽可能调和等等
根据进程的不同分类Linux采用不同的调度策略。inux将进程和线程调度视为一个, 因此进程调度也包含了线程调度的功能。
对于实时进程,采用FIFO(先入先出)或者Round Robin(轮询)的调度策略。因为实时进程只要求尽可能快的被响应。每个进程根据它重要程度的不同被赋予不同的优先级,调度器在每次调度时, 总选择优先级最高的进程开始执行。低优先级不可能抢占高优先级, 因此FIFO或者Round Robin的调度策略即可满足实时进程调度的需求。
普通进程的调度策略就比较麻烦了, 因为普通进程不能简单的只看优先级, 必须公平的占有CPU, 否则很容易出现进程饥饿, 这种情况下用户会感觉操作系统很卡, 响应总是很慢。
(3)中断机制
进程的调度是有专门的调度程序来实现的,里面会根据优先级等调度策略实现进程的分时调度功能(linux实际上核心功能就是多进程分时调度的系统);
对于单cpu,内核同一个时间点只会运行一个进程,可以防止并发导致的条件竞争问题,当进程运行计时器到点了,或者由于一些IO操作、wait其他进程操作等进入睡眠状态,则内核会进行进程的上下文切换,去调度另一个进程来执行。
进程之间的同步:进程之间虽然没有条件竞争(同一时间只有一个进程执行),但是仍然可能有同步的需求。当某个条件没有满足时进入睡眠,不占用cpu资源,直到这个条件被满足才唤醒。cpu硬件提供的这种睡眠、唤醒的机制,很大程度上提升了程序的可能性,系统的吞吐量大大提升。
中断处理程序:中断本质上就是突然来了一个高优先级的任务,这个时候临时的停止手头工作,先到预设的中断处理程序进行处理,处理完毕后再返回。需要注意的是中断本身并不导致进程的切换,最多是执行态的切换.
例如一个系统调用,我们可以触发一个软中断,类似于一个更高优先级的任务,内核处理该中断的处理函数就是system_call,从而实现了从用户态到内核态的切换。
中断执行过程其实类似于切换进程的过程,如果系统调用触发了中断,很有可能导致之前的进程上下文中的一些数据被中断处理程序访问到,或者被修改,导致数据一致性问题,这个时候,提供的是临界区提权的方案,即当进入到某些临界区的时候,会将进程的执行优先级提升,以屏蔽中断(中断由于优先级不比当前进程高,会在队列中等待)当退出临界区的时候,恢复原来的优先级,中断处理再执行。但是这个过程实际上会造成中断处理的延迟,会影响系统的吞吐量,所以临界区要尽量的最小化。
(4)内核线程
通常一个进程中可以包含若干个线程,线程是cpu调度和执行的单位
线程就是独立的执行路径。在程序运行时,即使没有自己创建线程,后台也会有多个线程,例如主线程,gc线程。main()称之为主线程,为系统的入口,用于执行整个程序。在一个进程中开辟了多个线程,线程的运行由调度器安排调度,调度器是与操作系统紧密相关的,先后顺序是不能人为干预的。
对同一份资源操作时,会存在资源抢夺问题,需要加入并发控制。线程会带来额外的开销,如cpu调度时间,并发控制开销。每个线程在自己的工作内存交互,内存控制不当会造成数据不一致
kthread_create创建线程,kthread_run()负责内核线程的创建,kthread_stop:通过发送信号给线程,使之退出。
2.4 Linux网络栈
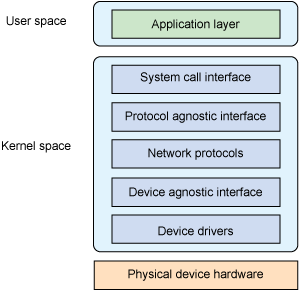
图4 Linux 高级网络栈架构
最上面是用户空间层,或称为应用层,其中定义了网络栈的用户。底部是物理设备,提供了对网络的连接能力(串口或诸如以太网之类的高速网络)。中间是内核空间,即网络子系统。流经网络栈内部的是 socket 缓冲区(sk_buffs),它负责在源和汇点之间传递报文数据。您很快就将看到 sk_buff 的结构。
系统调用接口
系统调用接口可以从两个角度进行描述。用户发起网络调用时,通过系统调用接口进入内核的过程应该是多路的。最后调用 ./net/socket.c 中的 sys_socketcall 结束该过程,然后进一步将调用分路发送到指定目标。系统调用接口的另一种描述是使用普通文件操作作为网络 I/O。
协议无关接口
socket 层是一个协议无关接口,它提供了一组通用函数来支持各种不同协议。socket 层不但可以支持典型的 TCP 和 UDP 协议,而且还可以支持 IP、裸以太网和其他传输协议,例如 SCTP(Stream Control Transmission Protocol)。
通过网络栈进行的通信都需要对 socket 进行操作。Linux 中的 socket 结构是 struct sock,这个结构是在 linux/include/net/sock.h 中定义的。这个巨大的结构中包含了特定 socket 所需要的所有状态信息,其中包括 socket 所使用的特定协议和在 socket 上可以执行的一些操作。
网络协议
网络协议这一节对一些可用的特定网络协议作出了定义(例如 TCP、UDP 等)。它们都是在 linux/net/ipv4/af_inet.c 文件中一个名为 inet_init 的函数中进行初始化的(因为 TCP 和 UDP 都是 inet 簇协议的一部分)。 inet_init 函数使用 proto_register 函数来注册每个内嵌协议。这个函数是在 linux/net/core/sock.c 中定义的,除了可以将这个协议添加到活动协议列表中之外,如果需要,该函数还可以选择分配一到多个 slab 缓存。
设备无关接口
协议层下面是另外一个无关接口层,它将协议与具有很多各种不同功能的硬件设备连接在一起。这一层提供了一组通用函数供底层网络设备驱动程序使用,让它们可以对高层协议栈进行操作。
设备驱动程序
网络栈底部是负责管理物理网络设备的设备驱动程序。例如,包串口使用的 SLIP 驱动程序以及以太网设备使用的以太网驱动程序都是这一层的设备。设备驱动程序在 dev 结构中配置好自己的接口之后,调用 register_netdevice 便可以使用该配置。在 linux/drivers/net 中可以找出网络设备专用的驱动程序。
3 TCP/IP协议栈
3.1 网络协议栈简述

图5 3种网络协议栈
网络协议栈对复杂的网络通信进行抽象,每层协议职责分明解决其需要应对的具体问题。层与层之间以服务的方式屏蔽底层复杂度。
TCP/IP协议族由5层组成:物理层、数据链路层、网络层、运输层和应用层。前四层与OSI模型的前四层相对应,提供物理标准、网络接口、网际互联、以及运输功能。而应用层与OSI模型中最高的三层相对应。
3.2 socket套接字
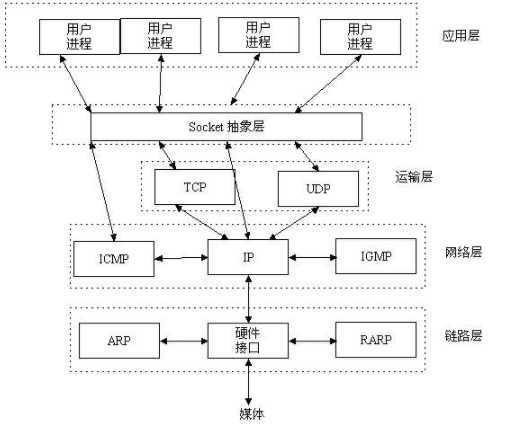
图6 socket抽象层
Socket是应用层与TCP/IP协议族通信的中间软件抽象层,它是一组接口。
在设计模式中,Socket其实就是一个门面模式,它把复杂的TCP/IP协议族隐藏在Socket接口后面,对用户来说,一组简单的接口就是全部。

图7 服务器,客户端交互流程图
服务器socket准备工作:
1.初始化socket
2.执行bind绑定操作,将服务器的服务绑定在一个ip地址和一个特定的端口上
3.执行listen操作,将原先的socket转化为服务端的socket
4.执行accept操作,将进程阻塞在accept方法上,等待客户端的连接
客户端初始化一个socket后,可以直接调用connet方法连接服务端的socket,经过著名的TCP三次握手,客户端和服务器建立连接,进入数据传输状态。
客户端发起write写操作,服务器通过read接收数据,然后write到客户端,客户端用read接收数据,当客户端和服务器交互完成之后,客户端发起close操作,发送一个FIN包通知服务器关闭链接。
4 TCP栈相关代码分析
下文将从send和recv过程两个方面,从套接字接口层,传输层,网络层,链路层分析TCP栈相关的代码。send()和recv()函数如下:
ssize_t send(int sockfd, const void *buf, size_t len, int flags) ssize_t recv(int sockfd, void *buf, size_t len, int flags)
4.1 套接字接口层
socketcall系统调用
在Linux内核中只有一个系统调用sys_socketcall 完成用户程序对所有套接字操作的调用,这需要以不同的参数来决定如何处理用户程序的调用。传给sys_socketcall函数的第一个参数是一个数字常数,sys_socketcall 以该常数为索引选择需要调用的实际函数。
sys_socketcall 函数主要完成两个功能:
(1)将从用户地址空间传来的每一个地址映射到内核地址空间。该功能通过调用copy_from_user函数完成。
(2)将应用层套接字的API函数映射到内核实现函数上。
sys_socketcall函数首先检查函数调用索引号是否正确,其后调用copy_from_user函数将用户地址空间参数复制到内核地址空间。最后switch词句根据系统调用函数索引号,实现套接字分路器的功能,将来自应用程序的系统调用转到内核实现函数sys_xxx 上。
asmlinkage long sys_socketcall(int call, unsigned long __user *args) { unsigned long a[6]; unsigned long a0,a1; int err; if(call<1||call>SYS_RECVMSG) return -EINVAL; /* copy_from_user should be SMP safe. */ if (copy_from_user(a, args, nargs[call])) return -EFAULT; a0=a[0]; a1=a[1]; switch(call) { case SYS_SOCKET: err = sys_socket(a0,a1,a[2]); break; case SYS_BIND: err = sys_bind(a0,(struct sockaddr __user *)a1, a[2]); break; case SYS_CONNECT: err = sys_connect(a0, (struct sockaddr __user *)a1, a[2]); break; case SYS_LISTEN: err = sys_listen(a0,a1); break; case SYS_ACCEPT: err = sys_accept(a0,(struct sockaddr __user *)a1, (int __user *)a[2]); break; case SYS_GETSOCKNAME: err = sys_getsockname(a0,(struct sockaddr __user *)a1, (int __user *)a[2]); break; case SYS_GETPEERNAME: err = sys_getpeername(a0, (struct sockaddr __user *)a1, (int __user *)a[2]); break; case SYS_SOCKETPAIR: err = sys_socketpair(a0,a1, a[2], (int __user *)a[3]); break; case SYS_SEND: err = sys_send(a0, (void __user *)a1, a[2], a[3]); break; case SYS_SENDTO: err = sys_sendto(a0,(void __user *)a1, a[2], a[3], (struct sockaddr __user *)a[4], a[5]); break; case SYS_RECV: err = sys_recv(a0, (void __user *)a1, a[2], a[3]); break; case SYS_RECVFROM: err = sys_recvfrom(a0, (void __user *)a1, a[2], a[3], (struct sockaddr __user *)a[4], (int __user *)a[5]); break; case SYS_SHUTDOWN: err = sys_shutdown(a0,a1); break; case SYS_SETSOCKOPT: err = sys_setsockopt(a0, a1, a[2], (char __user *)a[3], a[4]); break; case SYS_GETSOCKOPT: err = sys_getsockopt(a0, a1, a[2], (char __user *)a[3], (int __user *)a[4]); break; case SYS_SENDMSG: err = sys_sendmsg(a0, (struct msghdr __user *) a1, a[2]); break; case SYS_RECVMSG: err = sys_recvmsg(a0, (struct msghdr __user *) a1, a[2]); break; default: err = -EINVAL; break; } return err; }
4.2 传输层
send过程
TCP协议实现的传送功能是指将从应用层通过打开的套接字写入的数据移入内核,通过TCP/IP协议栈,最终通过网络设备发送到远端接收主机。一旦应用层打开一个SOCK_STREAM类型的套接字,并发出写数据请求,就会调用TCP协议实现的传送例程tcp_sendmsg来处理所有从打开的套接字上传来的写数据请求。
tcp_sendmsg 函数是TCP协议初始化时在协议函数块中注册发送函数,该函数给sk加锁后调用tcp_sendmsg_locked函数。完成的功能为:
(1)将数据复制到Socket Buffer 中。
(2)把Socket Buffer放入发送队列。
(3)设置TCP控制块结构,用于构造TCP协议发送方的头信息。
int tcp_sendmsg_locked(struct sock *sk, struct msghdr *msg, size_t size) { struct tcp_sock *tp = tcp_sk(sk); struct ubuf_info *uarg = NULL; struct sk_buff *skb; struct sockcm_cookie sockc; int flags, err, copied = 0; int mss_now = 0, size_goal, copied_syn = 0; int process_backlog = 0; bool zc = false; long timeo; flags = msg->msg_flags; if (flags & MSG_ZEROCOPY && size && sock_flag(sk, SOCK_ZEROCOPY)) { skb = tcp_write_queue_tail(sk); uarg = sock_zerocopy_realloc(sk, size, skb_zcopy(skb)); if (!uarg) { err = -ENOBUFS; goto out_err; } zc = sk->sk_route_caps & NETIF_F_SG; if (!zc) uarg->zerocopy = 0; } if (unlikely(flags & MSG_FASTOPEN || inet_sk(sk)->defer_connect) && !tp->repair) { err = tcp_sendmsg_fastopen(sk, msg, &copied_syn, size, uarg); if (err == -EINPROGRESS && copied_syn > 0) goto out; else if (err) goto out_err; } timeo = sock_sndtimeo(sk, flags & MSG_DONTWAIT); //超时标记 tcp_rate_check_app_limited(sk); /* is sending application-limited? */ /* Wait for a connection to finish. One exception is TCP Fast Open * (passive side) where data is allowed to be sent before a connection * is fully established. */ if (((1 << sk->sk_state) & ~(TCPF_ESTABLISHED | TCPF_CLOSE_WAIT)) && !tcp_passive_fastopen(sk)) { err = sk_stream_wait_connect(sk, &timeo); if (err != 0) goto do_error; } if (unlikely(tp->repair)) { if (tp->repair_queue == TCP_RECV_QUEUE) { copied = tcp_send_rcvq(sk, msg, size); goto out_nopush; } err = -EINVAL; if (tp->repair_queue == TCP_NO_QUEUE) goto out_err; /* 'common' sending to sendq */ } sockcm_init(&sockc, sk); if (msg->msg_controllen) { err = sock_cmsg_send(sk, msg, &sockc); if (unlikely(err)) { err = -EINVAL; goto out_err; } } /* This should be in poll */ sk_clear_bit(SOCKWQ_ASYNC_NOSPACE, sk); /* Ok commence sending. */ copied = 0; restart: mss_now = tcp_send_mss(sk, &size_goal, flags); err = -EPIPE; if (sk->sk_err || (sk->sk_shutdown & SEND_SHUTDOWN)) goto do_error; while (msg_data_left(msg)) { int copy = 0; skb = tcp_write_queue_tail(sk); if (skb) copy = size_goal - skb->len; if (copy <= 0 || !tcp_skb_can_collapse_to(skb)) { bool first_skb; new_segment: if (!sk_stream_memory_free(sk)) goto wait_for_sndbuf; if (unlikely(process_backlog >= 16)) { process_backlog = 0; if (sk_flush_backlog(sk)) goto restart; } first_skb = tcp_rtx_and_write_queues_empty(sk); skb = sk_stream_alloc_skb(sk, 0, sk->sk_allocation, first_skb); if (!skb) goto wait_for_memory; process_backlog++; skb->ip_summed = CHECKSUM_PARTIAL; skb_entail(sk, skb); copy = size_goal; /* All packets are restored as if they have * already been sent. skb_mstamp_ns isn't set to * avoid wrong rtt estimation. */ if (tp->repair) TCP_SKB_CB(skb)->sacked |= TCPCB_REPAIRED; } /* Try to append data to the end of skb. */ if (copy > msg_data_left(msg)) copy = msg_data_left(msg); /* Where to copy to? */ if (skb_availroom(skb) > 0 && !zc) { /* We have some space in skb head. Superb! */ copy = min_t(int, copy, skb_availroom(skb)); err = skb_add_data_nocache(sk, skb, &msg->msg_iter, copy); if (err) goto do_fault; } else if (!zc) { bool merge = true; int i = skb_shinfo(skb)->nr_frags; struct page_frag *pfrag = sk_page_frag(sk); if (!sk_page_frag_refill(sk, pfrag)) goto wait_for_memory; if (!skb_can_coalesce(skb, i, pfrag->page, pfrag->offset)) { if (i >= sysctl_max_skb_frags) { tcp_mark_push(tp, skb); goto new_segment; } merge = false; } copy = min_t(int, copy, pfrag->size - pfrag->offset); if (!sk_wmem_schedule(sk, copy)) goto wait_for_memory; err = skb_copy_to_page_nocache(sk, &msg->msg_iter, skb, pfrag->page, pfrag->offset, copy); if (err) goto do_error; //更新skb if (merge) { skb_frag_size_add(&skb_shinfo(skb)->frags[i - 1], copy); } else { skb_fill_page_desc(skb, i, pfrag->page, pfrag->offset, copy); page_ref_inc(pfrag->page); } pfrag->offset += copy; } else { err = skb_zerocopy_iter_stream(sk, skb, msg, copy, uarg); if (err == -EMSGSIZE || err == -EEXIST) { tcp_mark_push(tp, skb); goto new_segment; } if (err < 0) goto do_error; copy = err; } if (!copied) TCP_SKB_CB(skb)->tcp_flags &= ~TCPHDR_PSH; WRITE_ONCE(tp->write_seq, tp->write_seq + copy); TCP_SKB_CB(skb)->end_seq += copy; tcp_skb_pcount_set(skb, 0); copied += copy; if (!msg_data_left(msg)) { if (unlikely(flags & MSG_EOR)) TCP_SKB_CB(skb)->eor = 1; goto out; } if (skb->len < size_goal || (flags & MSG_OOB) || unlikely(tp->repair)) continue; if (forced_push(tp)) { tcp_mark_push(tp, skb); __tcp_push_pending_frames(sk, mss_now, TCP_NAGLE_PUSH); } else if (skb == tcp_send_head(sk)) tcp_push_one(sk, mss_now); continue; wait_for_sndbuf: set_bit(SOCK_NOSPACE, &sk->sk_socket->flags); wait_for_memory: if (copied) tcp_push(sk, flags & ~MSG_MORE, mss_now, TCP_NAGLE_PUSH, size_goal); err = sk_stream_wait_memory(sk, &timeo); if (err != 0) goto do_error; mss_now = tcp_send_mss(sk, &size_goal, flags); } out: if (copied) { tcp_tx_timestamp(sk, sockc.tsflags); tcp_push(sk, flags, mss_now, tp->nonagle, size_goal); } out_nopush: sock_zerocopy_put(uarg); return copied + copied_syn; do_error: skb = tcp_write_queue_tail(sk); do_fault: tcp_remove_empty_skb(sk, skb); if (copied + copied_syn) goto out; out_err: sock_zerocopy_put_abort(uarg, true); err = sk_stream_error(sk, flags, err); /* make sure we wake any epoll edge trigger waiter */ if (unlikely(tcp_rtx_and_write_queues_empty(sk) && err == -EAGAIN)) { sk->sk_write_space(sk); tcp_chrono_stop(sk, TCP_CHRONO_SNDBUF_LIMITED); } return err; } EXPORT_SYMBOL_GPL(tcp_sendmsg_locked);
调试结果
recv过程
tcp_sendmsg将数据从用户地址空间复制到内核空间,最终所有这些从用户地址空传来的数据包,都是通过tcp_write_xmit函数调用 tcp_transmit_skb函数向IP层传送的。
tcp_transmit_skb是tcp发送数据位于传输层的最后一步,这里首先对TCP数据段的头部进行了处理,然后调用了网络层提供的发送接口icsk->icsk_af_ops->queue_xmit(sk, skb, &inet->cork.f1);实现了数据的发送,自此,数据离开了传输层,传输层的任务也就结束了。
tcp_transmit_skb函数发送过程主要如下:
(1)tcp_transmit_skb函数初始化
(2)确定TCP数据段协议头包含的内容
(3)发送数据,调用实际传送函数将该数据段传送给IP层。
static int __tcp_transmit_skb(struct sock *sk, struct sk_buff *skb, int clone_it, gfp_t gfp_mask, u32 rcv_nxt) { skb_push(skb, tcp_header_size); skb_reset_transport_header(skb); ...... /* 构建TCP头部和校验和 */ th = (struct tcphdr *)skb->data; th->source = inet->inet_sport; th->dest = inet->inet_dport; th->seq = htonl(tcb->seq); th->ack_seq = htonl(rcv_nxt); tcp_options_write((__be32 *)(th + 1), tp, &opts); skb_shinfo(skb)->gso_type = sk->sk_gso_type; if (likely(!(tcb->tcp_flags & TCPHDR_SYN))) { th->window = htons(tcp_select_window(sk)); tcp_ecn_send(sk, skb, th, tcp_header_size); } else { /* RFC1323: The window in SYN & SYN/ACK segments * is never scaled. */ th->window = htons(min(tp->rcv_wnd, 65535U)); } ...... icsk->icsk_af_ops->send_check(sk, skb); if (likely(tcb->tcp_flags & TCPHDR_ACK)) tcp_event_ack_sent(sk, tcp_skb_pcount(skb), rcv_nxt); if (skb->len != tcp_header_size) { tcp_event_data_sent(tp, sk); tp->data_segs_out += tcp_skb_pcount(skb); tp->bytes_sent += skb->len - tcp_header_size; } if (after(tcb->end_seq, tp->snd_nxt) || tcb->seq == tcb->end_seq) TCP_ADD_STATS(sock_net(sk), TCP_MIB_OUTSEGS, tcp_skb_pcount(skb)); tp->segs_out += tcp_skb_pcount(skb); /* OK, its time to fill skb_shinfo(skb)->gso_{segs|size} */ skb_shinfo(skb)->gso_segs = tcp_skb_pcount(skb); skb_shinfo(skb)->gso_size = tcp_skb_mss(skb); /* Leave earliest departure time in skb->tstamp (skb->skb_mstamp_ns) */ /* Cleanup our debris for IP stacks */ memset(skb->cb, 0, max(sizeof(struct inet_skb_parm), sizeof(struct inet6_skb_parm))); err = icsk->icsk_af_ops->queue_xmit(sk, skb, &inet->cork.fl); //调用网络层的发送接口 ...... }
4.3 网络层
send过程
首先,当调用send()函数时,内核封装send()为sendto(),然后发起系统调用。send()就是sendto()的一种特殊情况,而sendto()在内核的系统调用服务程序为sys_sendto。
__sys_sendto函数做了3件事:
1.通过fd获取了对应的struct socket。
2.创建了用来描述要发送的数据的结构体struct msghdr。
3.调用了sock_sendmsg来执行实际的发送。继续追踪这个函数,会看到最终调用的是sock->ops->sendmsg(sock,msg,msg_data_left(msg));,即socket在初始化时复制给结构体struct proto tcp_prot的函数tcp_sendmsg。
int __sys_sendto(int fd, void __user *buff, size_t len, unsigned int flags, struct sockaddr __user *addr, int addr_len) { struct socket *sock; struct sockaddr_storage address; int err; struct msghdr msg; struct iovec iov; int fput_needed; err = import_single_range(WRITE, buff, len, &iov, &msg.msg_iter); if (unlikely(err)) return err; sock = sockfd_lookup_light(fd, &err, &fput_needed); if (!sock) goto out; msg.msg_name = NULL; msg.msg_control = NULL; msg.msg_controllen = 0; msg.msg_namelen = 0; if (addr) { err = move_addr_to_kernel(addr, addr_len, &address); if (err < 0) goto out_put; msg.msg_name = (struct sockaddr *)&address; msg.msg_namelen = addr_len; } if (sock->file->f_flags & O_NONBLOCK) flags |= MSG_DONTWAIT; msg.msg_flags = flags; err = sock_sendmsg(sock, &msg); out_put: fput_light(sock->file, fput_needed); out: return err; }
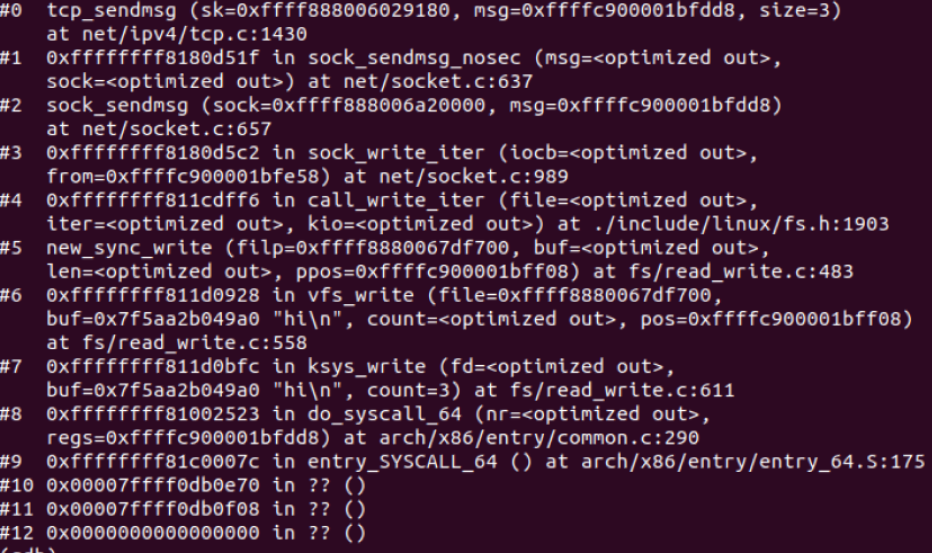
调试结果
recv过程
对于recv函数,与send类似,调用的是__sys_recvfrom,整个函数的调用路径与send非常类似。
__sys_recvfrom调用了sock_recvmsg来接收数据,整个函数实际调用的是sock->ops->recvmsg(sock, msg, msg_data_left(msg), flags);,同样,根据tcp_prot结构的初始化,调用的其实是tcp_rcvmsg。接受函数比发送函数要复杂得多,因为数据接收不仅仅只是接收,tcp的三次握手也是在接收函数实现的,所以收到数据后要判断当前的状态,是否正在建立连接等,根据发来的信息考虑状态是否要改变,在这里,我们仅仅考虑在连接建立后数据的接收。
int __sys_recvfrom(int fd, void __user *ubuf, size_t size, unsigned int flags, struct sockaddr __user *addr, int __user *addr_len) { ...... err = import_single_range(READ, ubuf, size, &iov, &msg.msg_iter); if (unlikely(err)) return err; sock = sockfd_lookup_light(fd, &err, &fput_needed); ..... msg.msg_control = NULL; msg.msg_controllen = 0; /* Save some cycles and don't copy the address if not needed */ msg.msg_name = addr ? (struct sockaddr *)&address : NULL; /* We assume all kernel code knows the size of sockaddr_storage */ msg.msg_namelen = 0; msg.msg_iocb = NULL; msg.msg_flags = 0; if (sock->file->f_flags & O_NONBLOCK) flags |= MSG_DONTWAIT; err = sock_recvmsg(sock, &msg, flags); if (err >= 0 && addr != NULL) { err2 = move_addr_to_user(&address, msg.msg_namelen, addr, addr_len); ..... }
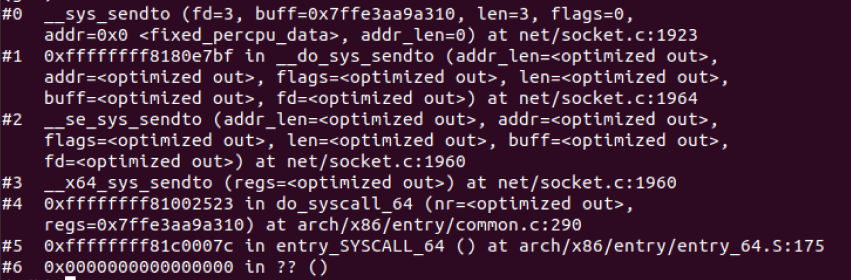
调试结果
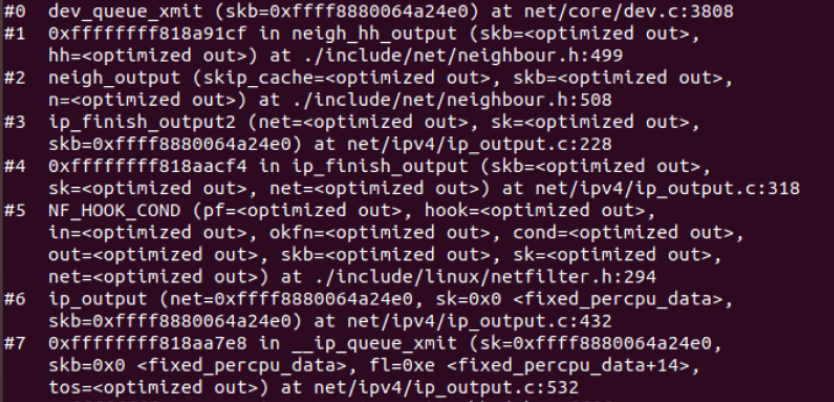
4.4 链路层
send过程
当所有的信息都准备好了之后,就会调用dev.c文件中的dev_queue_xmin函数,该函数是设备驱动程序执行传输的接口。也就是所有的数据包在填充完成后,最终发送数据时,都会调用该函数。
Dev_queue_xmit函数只接收一个skb_buff结构作为输入的值。此数据结构包含了此函数所需要的一切信息。Skb->dev是出口设备,skb->data为有效的载荷的开头,其长度为skb->len。
int dev_queue_xmit(struct sk_buff *skb) { struct net_device *dev = skb->dev; struct netdev_queue *txq; struct Qdisc *q; int rc = -ENOMEM; /* GSO will handle the following emulations directly. */ if (netif_needs_gso(dev, skb)) goto gso; //首先判断skb是否被分段,如果分了段并且网卡不支持分散读的话需要将所有段重新组合成一个段 //这里__skb_linearize其实就是__pskb_pull_tail(skb, skb->data_len),这个函数基本上等同于pskb_may_pull //pskb_may_pull的作用就是检测skb对应的主buf中是否有足够的空间来pull出len长度, //如果不够就重新分配skb并将frags中的数据拷贝入新分配的主buff中,而这里将参数len设置为skb->datalen, //也就是会将所有的数据全部拷贝到主buff中,以这种方式完成skb的线性化 if (skb_shinfo(skb)->frag_list && !(dev->features & NETIF_F_FRAGLIST) && __skb_linearize(skb)) goto out_kfree_skb; /* Fragmented skb is linearized if device does not support SG, * or if at least one of fragments is in highmem and device * does not support DMA from it. */ //如果上面已经线性化了一次,这里的__skb_linearize就会直接返回 //注意区别frags和frag_list, //前者是将多的数据放到单独分配的页面中,sk_buff只有一个。而后者则是连接多个sk_buff if (skb_shinfo(skb)->nr_frags && (!(dev->features & NETIF_F_SG) || illegal_highdma(dev, skb)) && __skb_linearize(skb)) goto out_kfree_skb; /* 如果此包的校验和还没有计算并且驱动不支持硬件校验和计算,那么需要在这里计算校验和*/ if (skb->ip_summed == CHECKSUM_PARTIAL) { skb_set_transport_header(skb, skb->csum_start - skb_headroom(skb)); if (!dev_can_checksum(dev, skb) && skb_checksum_help(skb)) goto out_kfree_skb; } gso: /* Disable soft irqs for various locks below. Also * stops preemption for RCU. */ rcu_read_lock_bh(); //选择一个发送队列,如果设备提供了select_queue回调函数就使用它,否则由内核选择一个队列 //大部分驱动都不会设置多个队列,而是在调用alloc_etherdev分配net_device时将队列个数设置为1 //也就是只有一个队列 txq = dev_pick_tx(dev, skb); //从netdev_queue结构上取下设备的qdisc q = rcu_dereference(txq->qdisc); #ifdef CONFIG_NET_CLS_ACT skb->tc_verd = SET_TC_AT(skb->tc_verd,AT_EGRESS); #endif //上面说大部分驱动只有一个队列,但是只有一个队列也不代表设备准备使用它 //这里检查这个队列中是否有enqueue函数,如果有则说明设备会使用这个队列,否则需另外处理 //关于enqueue函数的设置,我找到dev_open->dev_activate中调用了qdisc_create_dflt来设置, //不知道一般驱动怎么设置这个queue //需要注意的是,这里并不是将传进来的skb直接发送,而是先入队,然后调度队列, //具体发送哪个包由enqueue和dequeue函数决定,这体现了设备的排队规则 if (q->enqueue) { spinlock_t *root_lock = qdisc_lock(q); spin_lock(root_lock); if (unlikely(test_bit(__QDISC_STATE_DEACTIVATED, &q->state))) { kfree_skb(skb); rc = NET_XMIT_DROP; } else { //将skb加入到设备发送队列中,然后调用qdisc_run来发送 rc = qdisc_enqueue_root(skb, q); qdisc_run(q); //下面看 } spin_unlock(root_lock); goto out; } //下面是处理不使用发送队列的情况,注意看下面一段注释 /* The device has no queue. Common case for software devices: loopback, all the sorts of tunnels... Really, it is unlikely that netif_tx_lock protection is necessary here. (f.e. loopback and IP tunnels are clean ignoring statistics counters.) However, it is possible, that they rely on protection made by us here. Check this and shot the lock. It is not prone from deadlocks. Either shot noqueue qdisc, it is even simpler 8) */ //要确定设备是开启的,下面还要确定队列是运行的。启动和停止队列由驱动程序决定 //详见ULNI中文版P251 //如上面英文注释所说,设备没有输出队列典型情况是回环设备 //我们所要做的就是直接调用驱动的hard_start_xmit将它发送出去 //如果发送失败就直接丢弃,因为没有队列可以保存它 if (dev->flags & IFF_UP) { int cpu = smp_processor_id(); /* ok because BHs are off */ if (txq->xmit_lock_owner != cpu) { HARD_TX_LOCK(dev, txq, cpu); if (!netif_tx_queue_stopped(txq)) { rc = 0; //对于loopback设备,它的hard_start_xmit函数是loopback_xmit //我们可以看到,在loopback_xmit末尾直接调用了netif_rx函数 //将带发送的包直接接收了回来 //这个函数下面具体分析,返回0表示成功,skb已被free if (!dev_hard_start_xmit(skb, dev, txq)) { HARD_TX_UNLOCK(dev, txq); goto out; } } HARD_TX_UNLOCK(dev, txq); if (net_ratelimit()) printk(KERN_CRIT "Virtual device %s asks to " "queue packet!\n", dev->name); } else { /* Recursion is detected! It is possible, * unfortunately */ if (net_ratelimit()) printk(KERN_CRIT "Dead loop on virtual device " "%s, fix it urgently!\n", dev->name); } } rc = -ENETDOWN; rcu_read_unlock_bh(); out_kfree_skb: kfree_skb(skb); return rc; out: rcu_read_unlock_bh(); return rc; }
调试结果
recv过程
netif_rx是目前大多数网络设备驱动程序将数据帧复制到Socket Buffer 后,调用的数据链路层方法。它通知内核接收到了网络数据帧;标记网络接收软件中断,执行接收数据帧的后续处理。这种机制每接收一个数据帧会产生一个接收中断。
netif_rx函数由常规网络设备驱动程序在接收中断中调用,它的任务就是把输入数据帧放入CPU的输入队列中,随后标记软件中断来处理后续上传数据帧给TCP/IP协议栈功能。
napi_schedule函数是_napi_schedule函数的包装函数,_napi_schedule完成的功能就是将struct napi_struct 数据结构实例放入CPU的poll_list队列,挂起网络接收软件中断NET_RX_SOFTIRQ。这样推送数据帧给上层协议实例的处理函数,就会在内核调度的网络接收软件中断处理程序的net_rx _action函数中被执行。
网络接收软件中断(NET_RX_SOFTIRQ)的处理程序net_rx_action是接收网络数据中断的后半段。引起net_rx _action函数执行的是网络设备产生的接收数据硬件中断,它通知内核收到了网络数据帧,触发内核调度接收中断的后半段。net_rx_action函数的任务就是将设备收到的数据帧上传给TCP/IP 协议栈的上层协议处理。
int netif_rx(struct sk_buff *skb) { struct softnet_data *queue; unsigned long flags; //netpoll是否会使用此skb if (netpoll_rx(skb)) return NET_RX_DROP; //设置包接收的时间戳 if (!skb->tstamp.tv64) net_timestamp(skb); //禁止本地cpu中断 local_irq_save(flags); /* 获取当前CPU的 softnet_data 数据 */ queue = &__get_cpu_var(softnet_data); //更新统计信息 接收帧的总数 __get_cpu_var(netdev_rx_stat).total++; //netdev_max_backlog输入队列最大长度 在此2.6.32版本默认为1000 if (queue->input_pkt_queue.qlen <= netdev_max_backlog) { //队列是否为空 if (queue->input_pkt_queue.qlen) { enqueue: //将数据包加入到接收队列中 __skb_queue_tail(&queue->input_pkt_queue, skb); //回复本地cpu中断 local_irq_restore(flags); return NET_RX_SUCCESS; } //触发NET_RX_SOFTIRQ类型软中断 net_rx_action //只有当队列为空的时候才会调度 是由于队列不为空 接收软中断已经被调用一次,没必要在调用一次 napi_schedule(&queue->backlog); goto enqueue; } //增加统计信息报丢弃的数量 __get_cpu_var(netdev_rx_stat).dropped++; //恢复本地cou中断 local_irq_restore(flags); //处理完后释放skb kfree_skb(skb); return NET_RX_DROP; }
6 时序图
服务器到客户端传输数据调用函数时序图。

