Empowering Data Management, Diagnosis, and Visualization of Cloud-Resolving Models (CRM) by Cloud Library upon Spark and Hadoop
主要有用的有以下几块:
1、Develop Super Cloud Library (SCL) supporting Cloud Resolving Model using Spark on Hadoop.
• Create cloud data files• Develop data model and Hadoop format transformer• Develop dynamic transfer tool to Hadoop• Develop subset and visualization APIs (Application Programming Interfaces)• Develop Web User Interface
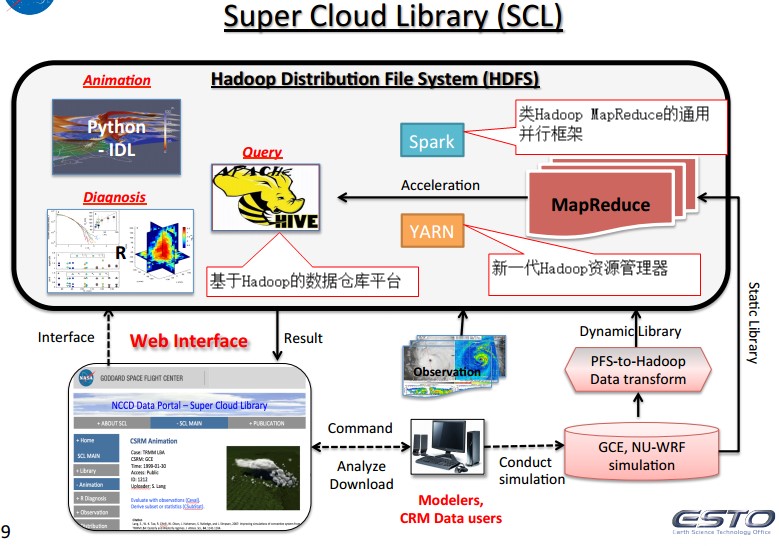
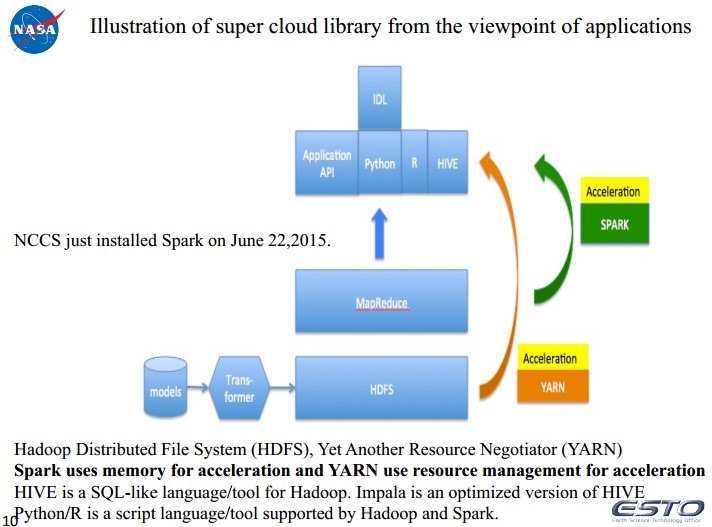
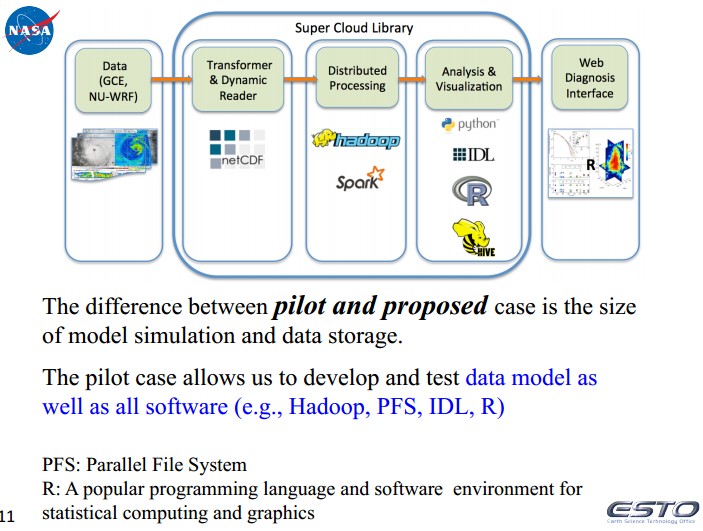
2、数据模型
将NU-WRF的netcdf数据和GCE的二进制数据输出为CSV格式。
例如:
NU-WRF (1 km and 48 h simulation): IPHEX; 10 output variables. Hourly output in a text (CSV) format has 465GB
GIGALES, 4096x4096x104, 2-3 day simulation: Single output data size ~2.5TB; Total output data size ~125TB
3、IDL+Hadoop
48个1GB大小的WRF模拟数据的动画生成,能够从原来的17分钟改进为14分钟。
Developed an animation/movie of 48 text files from NU-WRF Pilot simulations. Each file has ~1GB
4、基于Hadoop的动态读取系统。– 14 minutes for IDL with Hadoop streaming• NCCS Hadoop cluster has 34 nodes• IDL is on one Hadoop node and can run with multiple instances simultaneously• Files stored in Hadoop file system (HDFS)• 15 seconds for reading each file out of HDFS– 17 minutes for IDL with NCCS Discover GPFS file system• IDL is on one NCCS Dali compute node• Files stored in NCCS GPFS file system




Job trackers and task trackers run on the master node, and task trackers and map tasks run on slave nodes. Virtual blocks are managed in the virtual block table in namenode. A task tracker initiates the PFS prefetcher thread to get data directly from a remote PFS. Map tasks initiate the PFS reader threads to import data directly from the remote PFS.
5、 各个技术使用场景的统计
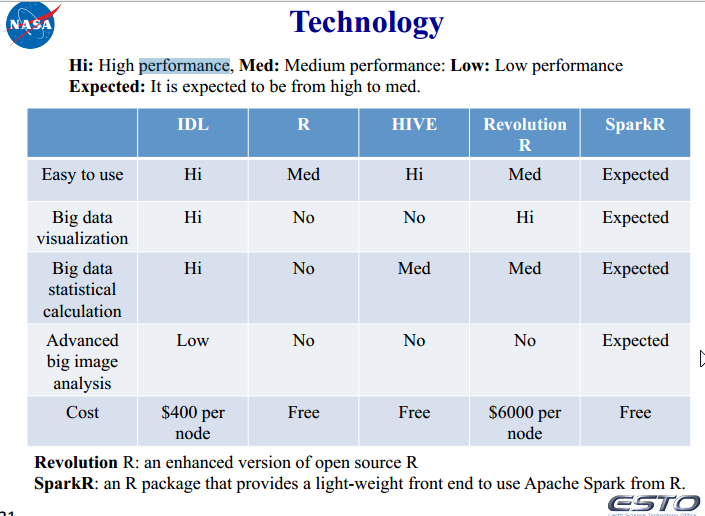

 浙公网安备 33010602011771号
浙公网安备 33010602011771号