线程池学习笔记
摘要:本文介绍了线程池源代码的剖析,并结合一些实例给出了线程池使用可能会遇到的问题。
🐬为什么需要线程池🐬
线程池,自然和多线程的应用场景有关,假如我们希望有一组相互独立的任务,希望通过多线程并行化来取得效率上的提升,也就是说,能最大限度的提高CPU的利用率。我们可以通过创建很多的线程来实现么,显然是不能的。过多的创建线程,会带来两个方面的负面影响,首先,假如创建出的线程全部都参加线程的调度,操作系统在进行线程切换时是要消耗资源的,这些资源既包括存储资源,也包括CPU资源。其次,假如这些被创建的的线程本身是一些纯过程时,换句话说,他仅仅起到一个对数据进行处理的作用,而没有取占用一些内存资源,例如对图片进行模糊化处理的任务,或者对文件进行加密的任务,那么创建多个线程对系统的影响影响不是很大。但是假如这些线程在初始化同样申请了一部分内存资源,那么创建过多的线程很可能引发OOM这样的异常。总之一句话,创建过多的线程会引发两个问题:
- 过多的线程去争夺CPU资源,使得系统的吞吐率反而降低
- 创建了过多的需占有内存资源的线程有可能会引发OOM
再谈论线程池之前,我们先想一下假如没有线程池我们需要在怎么做,既然是由于开启了过多的线程,我们就通过“某种策略”控制线程的创建数量,这里说的控制是两个方面的,第一,某些大量创建的任务我们仅仅是将其初始化,而不参与线程的调度,也就是说,仅仅占用一部分的存储资源,而不是去抢夺CPU资源,这样的好处是,我们能始终保持合适熟练的线程数参与调度,提高系统的吞吐量。第二,当条件再严苛一些,我们严格控制创建的任务的初始化数量,防止大量的任务堆积,将我们的内存资源消耗尽。
线程池实际就是通过复用线程的思想集合生产者消费者模式来解决了上述问题。
🤗线程池的参数&设计模式🤗
java提供的线程池ThreadPoolExcutor封装在java.uitl.concurrent包里,我们首先摘录下官方提供的说明: An ExecutorService that executes each submitted task using one of possibly several pooled threads, normally configured using Executors factory methods。一段简短的介绍,设计了好几个概念。首先官方说明了他是ExecutorService的具体实现类,对于java来说再普通不过了,就是使用了模板模式。后面紧跟着说明了他的功能:使用几个可能的池化的线程来执行每一个提交到线程池里的任务。实际上可以将其看成线程的消费者,而作为提交的任务的我们,自然就是生产者的角色。最后一句实际是上也牵扯到一个知识点:工厂方法。因为线程池的使用场景包含很多,因此我们需要灵活的配置手段(初始化手段)。所以特意为我们提供了工厂方法来满足我们不同的使用要求。这里需要注意的是,实际上工厂方法在java中非常常见,由于java不提供默认参数,因此要想灵活的初始化就会遇到很多不方便,所以就大量使用了工厂方法这一设计模式来弥补。
不熟悉工厂方法这一模式的小伙伴我可以做一个简短的介绍,他要解决地问题就是,假如我们有一系列相关联的产品,(可能是功能上比较类似,通常是继承自同意抽象类,或者实现了同一接口)。我们在客户端的使用方想达到尽可能灵活的配置,也就是说我们不想写出下面的代码:
//at product designer side
interface Product{
void use();
}
class ProductA implements Product{
void use(){
}
}
class ProductB implements Product{
void use(){
}
}
//at product use side
public static void main(String[] args) {
Product p;
p = new ProductA();
p.use();
}
但是这样假如我们变更了需求,我们需要产品B来完成服务,这个时候我们需要重新修改我们的代码,重新编译我们的代码,这样显然是不太灵活的方式。我们希望能通过写配置这样的方式,以最小的侵入方式来完成客户端的调用。工厂方法就是为了解决这个问题而产生的。通过工厂方法,上述的代码变为了下面的方式:
interface Product{
void use();
}
class ProductA implements Product{
void use(){
}
}
class ProductB implements Product{
void use(){
}
}
class ProductFactory {
public static newProduct(String productName){
if("PrudctA".equals(productName)) {
return new ProductA();
}
else if("ProductB".equals(productName)) {
return new ProductB();
}
else {
throw new Exception("unkown product type");
}
}
}
//in client side
public static void main(String[] args) {
String configure = args[0];
Configure c = Confiure.read(configure);
String productName = c.getProductName();
Pruduct p = ProdectFactory.newProduct(productName);
p.use();
}
将产品的创建移交至工厂统一管理,然后通过写配置类控制产品的生产及使用的方式便称为工厂方法。其实java核心库大量使用了工厂方法,只不过表现形式上有所差异。例如常用的一些静态方法:newXXInstance便是工厂方法的变种。这样变化的好处时,通过名称便可以推断出生产出的实例是具备怎样的性质,代码的维护性也就比较高。例如Excutors便是线程池工厂(方法),里面提供的几个主要方法:
- newFixedThreadPool
- newCacheThreadPool
- newSingleThreadExcutor
讲清楚以上细节,我们再来从使用者的角度来观察下线程池的几个主要使用参数:
- corePoolSize:int
- maxPoolSize:int
- keepAliveTime:long
- workQueue:BlockQueue
首先看一下newFixedThreadPool是如何封装配置的:
public static ExecutorService newFixedThreadPool(int nThreads) {
return new ThreadPoolExecutor(nThreads, nThreads,
0L, TimeUnit.MILLISECONDS,
new LinkedBlockingQueue<Runnable>());
}
我们来分析一下,在原始的ThreadPoolExcutor的构造方法中,前两个整数型的参数分别代表corePoolSize和maxPoolSize。也就是说,FixedThreadPool将两个参数设置为同等大小,然后我们再来看workQueue,发现使用了LinkedBolckingQueue,这里需要注意的是,这是一个无界队列,也就是说,当提交任务到该队列时,永远不会被阻塞。
好了,现在讲解corePoolSize的含义,所谓的corePoolSize也就是线程池内允许活动的,这里的活动是指可以去参与CPU的调度,抢夺CPU资源的基本线程数量。而后者,是指线程池所允许的最大的可以活动的线程数量。
下面通过一幅图来说明提交线程池是涉及到的基本执行逻辑:
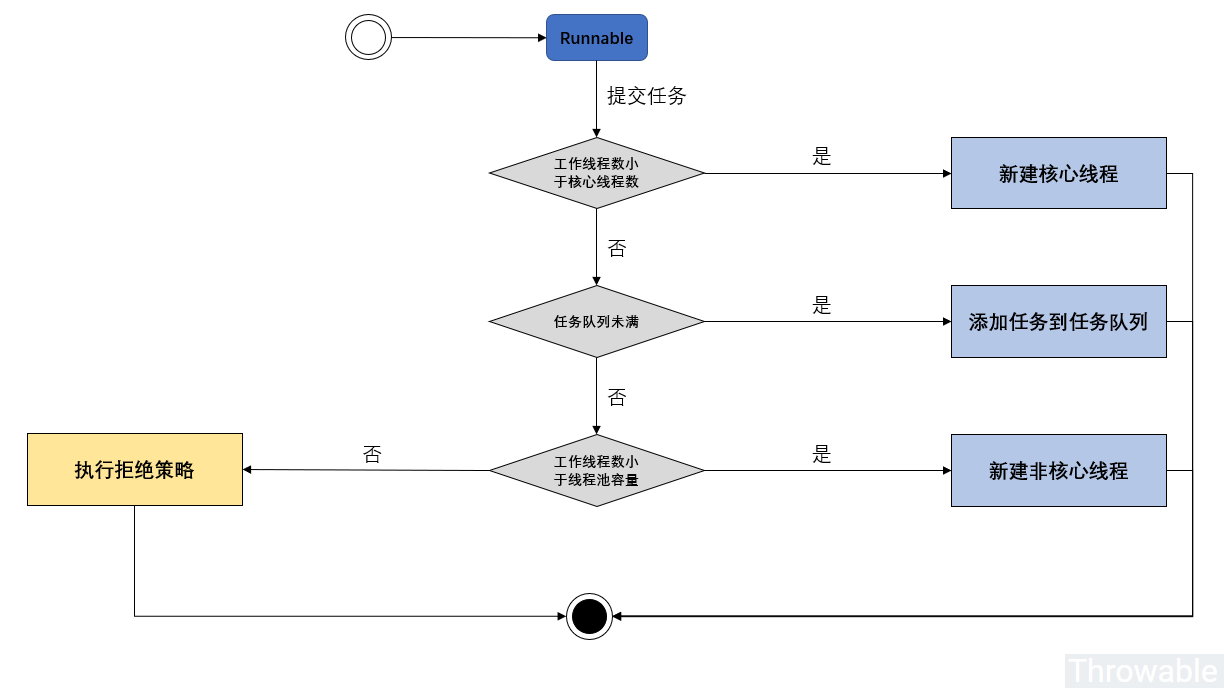
也就是说,当线程池提交的任务数小于核心线程数时,线程池直接创建新的线程来执行任务,而当提交的任务大于核心线程数时,这是为了保证过多的线程争夺CPU资源引发的吞吐量降低,将提交的线程放置到任务队列进行托管。假如此时用户此时还在继续的提交,此时会触发最大线程数的判断,实际上这个最大线程数和核心线程数的数量差可以理解为系统的备用资源,所谓备用资源,就是进行一些高峰期的容纳处理。到这里不知道大家有没有疑惑,为什么一开始不进行最大线程数的判断,而是等到任务队列满了之后再进行判断,那这样的话,尽管有些线程要早提交,反而到了线程池里排队,而有些线程池晚到,因为触发了任务队列已满这一条件,反而得到了优先执行的机会(因为此时若活动线程数小于最大线程数,新提交的线程会直接被执行)。这样看来,命运的不公真的体现在各个方面啊😢
😏线程池的一些坑😏
下面我们来验证一下我们的想法,我们创建一个核心线程数为2,最大线程数为4,阻塞队列大小为8的队列。然后连续向线程池里提交30个任务,观察运行结果:
public class Main {
public static void main(String[] args) {
ExecutorService pool = new ThreadPoolExecutor(2,4,3000,TimeUnit.MICROSECONDS,
new ArrayBlockingQueue<Runnable>(4));
for(int i = 0; i <30; i++) {
try {
pool.execute(new Task(String.format("task:%d",i+1)));
}
catch(RejectedExecutionException e) {
//e.printStackTrace();
}
}
pool.shutdown();
}
}
class Task implements Runnable{
String name;
int byteNum = 1024*1024*40;
byte[] hugeArr;
public Task(String name) {
//hugeArr = new byte[byteNum];
this.name = name;
}
public void run() {
try {
for(int i = 0; i < 3; i++) {
if(i == 0) System.out.printf("%s task in init\n",name);
else System.out.printf("%s task is executing\n",name);
Thread.sleep(1000);
}
}
catch (InterruptedException e) {
e.printStackTrace();
}
}
}
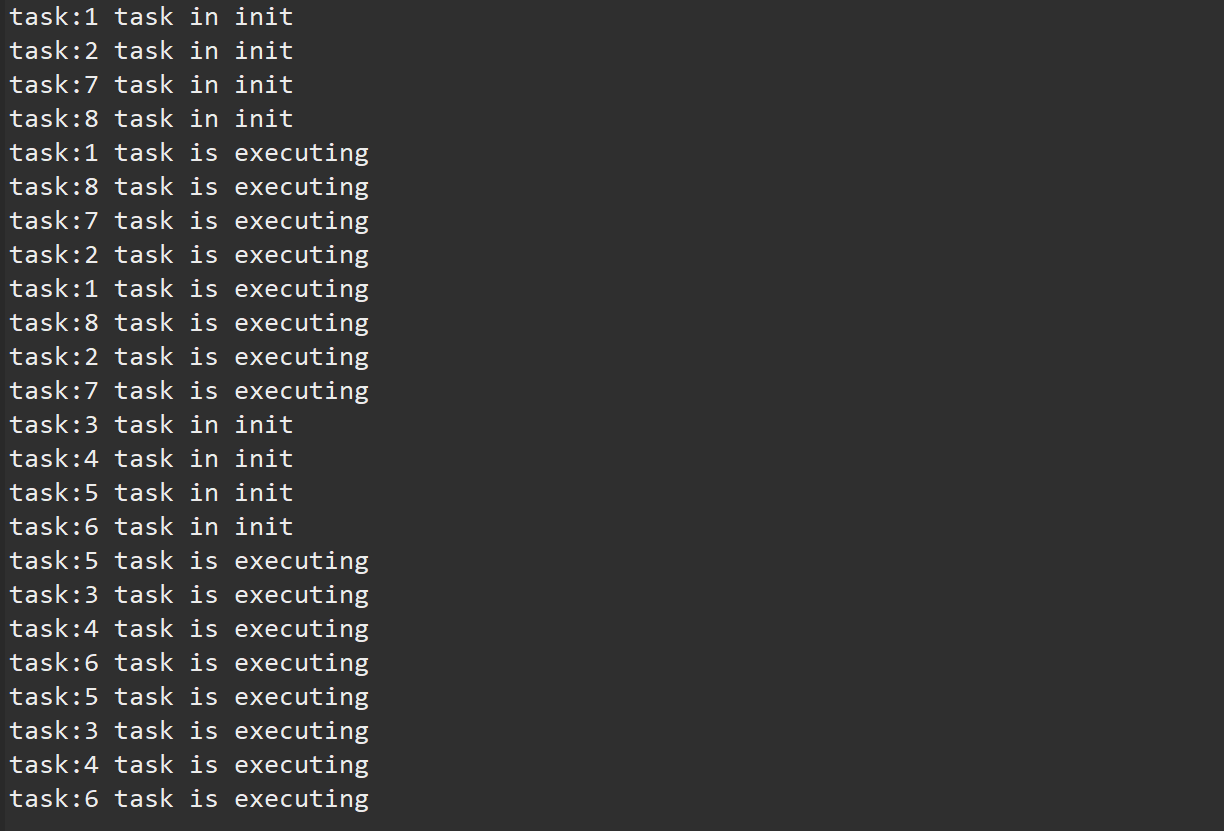
这里我们采用了简单地丢弃任务的拒绝策略,所以执行过程为1,2任务提交后立即被执行,3,4,5,6在任务队列中等待,7,8任务触发了任务队列满这一条件,由于此时的活动线程数少于最大线程数,7,8任务直接被执行。所以我们观察到,一开始的时候1,2,7,8这四个任务在进行CPU资源的抢夺。后面再提交的任务被简单地丢弃掉了。
{{uploading-image-284641.png(uploading...)}}
再回到我们newFixedThreadPool这个线程池,我们分析一下可能会引发什么问题,注意到核心线程数的大小同最大线程数,也就是说没有备用的线程可供我们用,任务队列选用了无界队列,也就是永远不会进行任务的丢弃,只要有新的任务提交,核心线程数以满时,便将任务放置到工作队列中等待。
我们思考一下这样一个问题,假如提交的任务会有一部分的内存申请操作,当我们对newFixedThreadPool大量提交任务时会发生什么状况呢?
下面我们来做一个实验,假设我们的任务在每次执行前,都会产生40M的内存占用,当我们大量提交任务时,会发生什么情况:
public class Main {
public static void main(String[] args) {
ExecutorService pool = Executors.newFixedThreadPool(4);
for(int i = 0; i <200; i++) {
try {
pool.execute(new Task(String.format("task:%d",i+1)));
}
catch(RejectedExecutionException e) {
//e.printStackTrace();
}
}
pool.shutdown();
}
}
class Task implements Runnable{
String name;
int byteNum = 1024*1024*40;
byte[] hugeArr;
public Task(String name) {
hugeArr = new byte[byteNum];
this.name = name;
}
public void run() {
try {
for(int i = 0; i < 3; i++) {
if(i == 0) System.out.printf("%s task in init\n",name);
else System.out.printf("%s task is executing\n",name);
Thread.sleep(1000);
}
}
catch (InterruptedException e) {
e.printStackTrace();
}
}
}
运行结果如下:

我们发现,当大量提交任务时,由于提交到无界队列中,所以不会产生对任务的拒绝。因此很快将触发了OOM的异常。这也是为什么当并发程度很高的场景下,不建议使用newFixedThreadPool这个工厂方法来创建线程池的原因。