链路追踪系统:云原生比赛分析
摘要
本人近日在参加阿里云原生的链路追踪系统设计比赛,在比赛中感觉收获颇多,包括一些工具框架的使用,例如okhttp以及springboot,同时也对于如何使用springboot有了更进一步的认识。本博客就自己的收获以及对于赛题进行简单的梳理。比赛的详细介绍详见比赛首页
链路追踪
本次比赛是需要实现链路追踪系统,关于链路追踪的详细介绍可参加官网的详细介绍,本人简单说一下我的理解,在本赛题中,链路实际上就是多个同处一个事务或流程中的http调用。因为对于网络系统编程(或者云原生or分布式),单个事务的执行势必涉及到多个不同系统,而体现在具体执行中,就是一个个不同的http调用组成了一个事务的执行。本质上,同属一个调用链路的http span组成了一个有向无环图,本次比赛为了简化,直接将同属相同调用链路的http span用全局唯一的traceId进行了标识,也就是不需要参赛选手进行调用链路的组建,只需要将数据流中所关心的调用链路给出即可。
数据格式
比赛中给出的http span是以http流给出的,每条http span占据一行,数据格式如下:
traceId | startTime | spanId | parentSpanId | duration | serviceName | spanName | host | tags
具体各字段意义解释如下的:
- traceId:全局唯一的Id,用作整个链路的唯一标识与组装
- startTime:调用的开始时间
- spanId: 调用链中某条数据(span)的id
- parentSpanId: 调用链中某条数据(span)的父亲id,头节点的span的parantSpanId为0
- duration:调用耗时
- serviceName:调用的服务名
- spanName:调用的埋点名
- host:机器标识,比如ip,机器名
- tags: 链路信息中tag信息,存在多个tag的key和value信息。格式为key1=val1&key2=val2&key3=val3 比如 http.status_code=200&error=1
比赛给了两条http流,而且为了简化比赛,假定相同traceId的span前后不会超过2万条。
赛题分析
在不考虑数据量的条件下,最朴素的解决方法当然就是在客户端将http流全部缓存下来,然后存入HashMap<String,List<String>>中,其中Key是符合上报条件的traceId,Value是与之对应的所有http span,再按照http span中startTime属性升序排序即可。由于数据量庞大,显然这样的方案不可行,但是我们注意到题目中给出的提示,假定相同traceId的span前后不会超过2万条,这样我们实际上就可以将庞大的数据流分割成基本单位为2万大小的batch来逐步的处理,为了说明方便,给出如下的示意图:
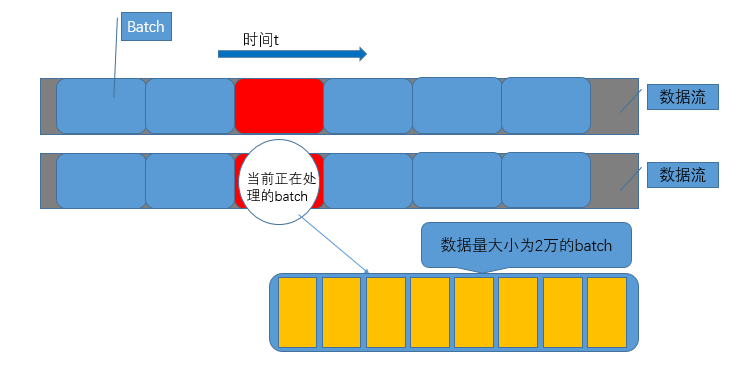
如上图所示,我们将数据流按照上述形式进行了分割以后,实际上就可以转化为朴素的解法了,处理红色batch时,需要将前后各一个batch进行汇总,共同计算结果,这是由于相同的traceId有可能横跨两个batch,但是出现在前面还是后面是不确定的,因此需要一起计算。需要注意的是,由于相同的调用链路有可能出现在不同的数据流中,我们需要将当前batch多个数据流中有问题的traceId全部汇总以后,在进行汇总计算。说明了整体的算法思路之后,我们分析一下时间复杂度,假设总的数据量为N,由于每个batch都需要重复计算前后各一个batch,那么总的复杂度为3N。
赛题交互逻辑设计
由于比赛要求实现客户端和服务端,实际上就是将过滤和计算模块解耦,方便以后的系统设计。客户端需要进行存在问题的traceId过滤汇报以及数据的缓存服务,后端则负责将客户端上报过来的有问题的traceId拉取客户端当前缓存的数据,然后在进行汇总以及最终的上报。由于涉及到复杂的http交互,绘制如下的示意图明确交互过程:
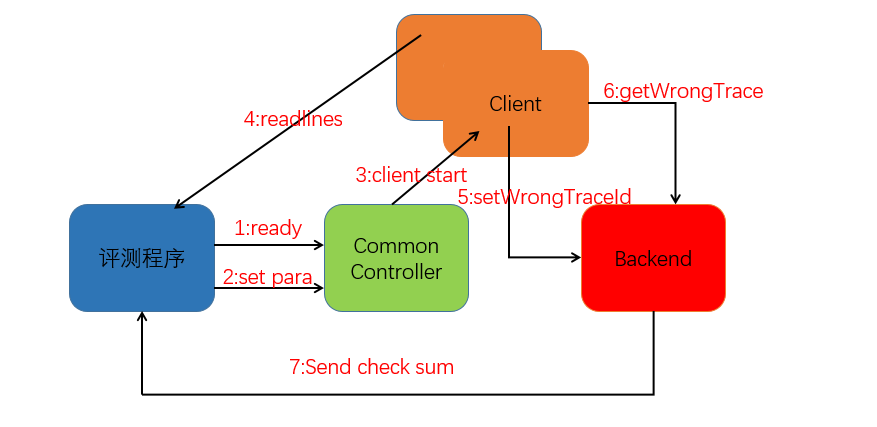
赛题具体实现
整体设计流程基本上都体现在上图中了,然后下面阐述实现中的几个关键点:
-
由于调用链路并行存在多条数据流中,我们根据过滤出的
traceId后端进行计算时,一定要拿到多条数据流的汇总结果,这样才能保证结果的正确性。还有就是当客户端将当前batch和下一个batch过滤结果都汇总完毕时,才可以进行最终结果的汇总。其目的是为了保证traceId出现在不同的batch这一现象。 -
前后端传递数据使用
okhttp模块和fastjson,分别为我们提供了http通信和对象的序列化服务,而http的请求处理我们使用springboot来完成。 -
为了方便客户端和后端的交互,我们设计了
TraceIdBatch类,方便我们判断前后端的状态。其UML图如下:

其中batchPos是为了标记backend正在处理的batch序号,processCount用来标记已汇总数据里的个数,当已汇总的数据流大于等于提供的数据流条数,标志着客户端当前batch过滤汇报的完成,backend就可以根据汇总的结果向client拉取结果,进行计算。

