
正则表达式学习
正则在线匹配的网站:https://regex101.com/
1.所谓的元字符就是指那些在正则表达式中具有特殊意义的专用字符,比如\d 表示的就是数字,正则就是由一系列的元字符组成的。
2.按照分类来记忆元字符:特殊字符、空白符、范围、量词、断言
2.1 特殊字符:
. 表示换行以外的任意字符
\d 任意数字 \D 任意非数字
\w 任意字母数字下划线 \W任意非字母数字下划线
\s 任意空白符 \S 任意非空白符
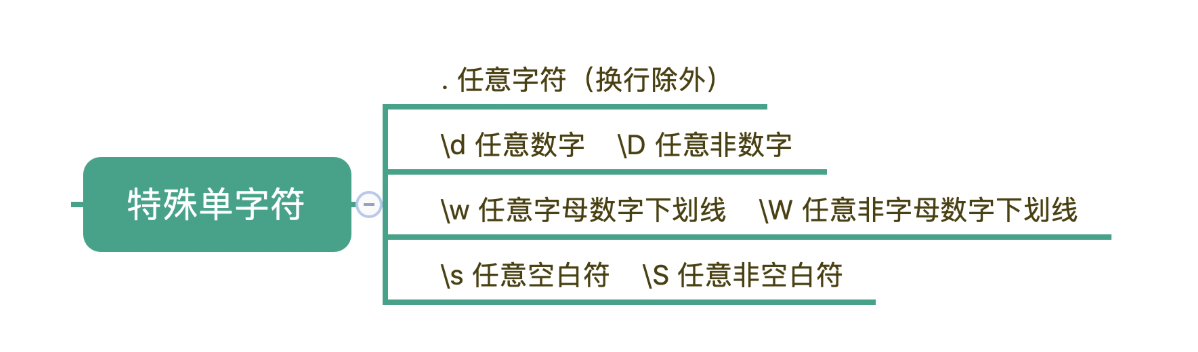

\s能匹配上各种空白符号,也可以匹配上空格,换行有专门的表示方式,在正则中,空格就是用普通的字符英文的空格来表示
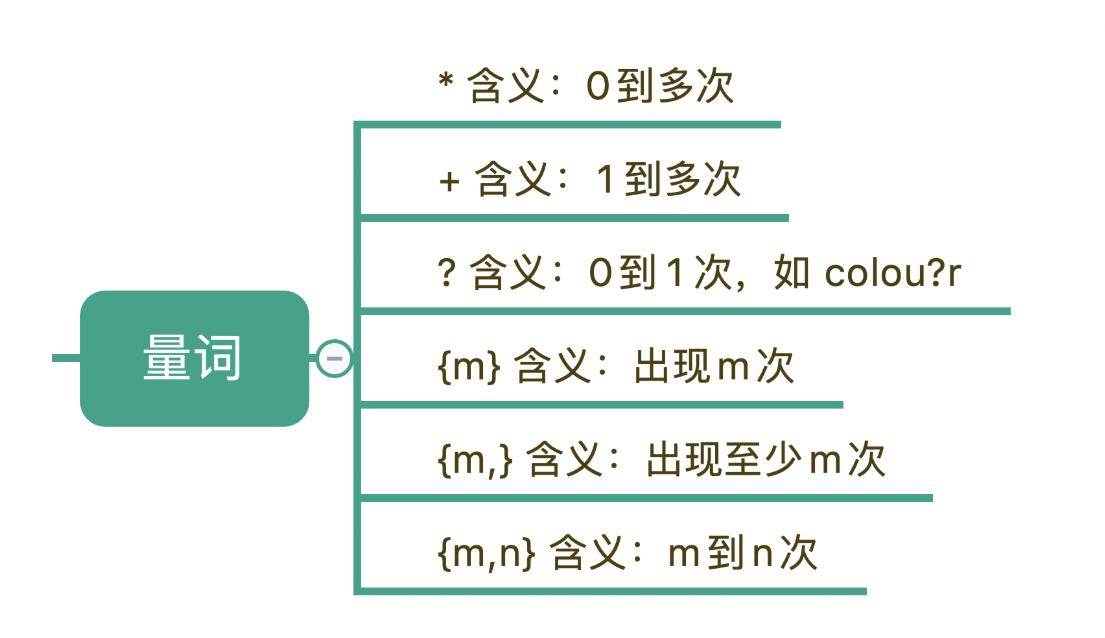
3.量词
基础元字符,空白符,它们都只能匹配单个字符,比如\d只能匹配一个数字,但有的时候,我们需要匹配单个字符,或者某个部分"重复N次" "至少出现一次" "最多出现三次"等等这样的字符,
在正则中,* 表示出现0到多次,加号(+)代表1到多次,问号(?)表示0到1次,{m,n}代表m到n次
4.范围

二:正则中的三种模式:贪婪匹配、非贪婪匹配、独占模式。比如匹配一次到多次的时候,匹配长度是尽可能长还是尽可能短呢?如果不知道贪婪模式和非贪婪模式,我们就不知道我们写的正则表达式是否正确
贪婪模式:简单说就是尽可能进行最长匹配;非贪婪模式:则会尽可能进行最短的匹配
在正则中,表示次数的量词默认是贪婪的,在贪婪模式下,会尝试尽可能最大长度去匹配
如何将贪婪模式变成非贪婪模式呢?可以在量词后面加上英文的问好(?),例如a*?
不管是贪婪模式,还是非贪婪模式,都需要发生回溯才能完成相应的功能,但是一些场景下,我们不需要回溯,匹配不上返回失败就好
独占模式和贪婪模式很像,独占模式会尽可能多地去匹配,如果匹配失败就结束,不会进行回溯,这样的话就比较节省时间,具体的方法是在量词后面加上(+)
三:总结:如果只是判断文本是否符合规则,则可以使用独占模式;如果需要获取匹配的结果,则根据需要使用贪婪或非贪婪模式
四:在大多数的正则实现中,多分枝的选择都是左边优先
五:括号在正则中的功能就是用于分组。简单来理解就是,由多个元字符组成某个部分,应该被看成一个整体的时候,可以用括号括起来表示一个整体,这是括号的一个重要功能
六:什么是不保存子组?我们可以理解成,括号只用于归组,把某个部分当成“单个元素”,不分配编号,后面不会再进行这部分的引用
七:分组引用:在知道了分组引用的编号(number)之后,大部分情况下,我们就可以使用“反斜杠+编号”,即\number的方式来进行引用,而JavaScript中是通过$编号来引用,如$1
八:查找重复出现的单词,我们使用正则可以很方便的使:"前面出现的单词再次出现", 用 \w+ 来表示一个单词,所以 (\w+) \1 就能匹配到重复的单词,这是为什么呢?
因为分组后,后面可以用分组编号引用,这样就是重复出现的意思

九:课后练习题:

解题的思路是:\w+ 用于选中出现一次到多次的字母,由于默认贪婪匹配最长,所以能选中每个单词,由于是要找出重复的单词,所以要用第一次匹配成功的结果即使用分组 (\w+) \1,到此可以拿到重复两次场景的结果,对于重复两次以上的结果,需要重复刚刚的行为,但是不能一直叠加 \1 ,自然想到了 +,得到了 (\w+) (\1)+,发现匹配不成功,在这里卡壳了一段时间没想明白,翻到别人的答案才猛然想起来单词之间应该有空隙,(\1)+不能表示空隙,用\s代替敲出来的空格最终得到 (\w+)(\s+\1)+
十:正则中的匹配模式:指的就是正则中一些改变元字符匹配行为的方式,比如匹配时不区分英文字母大小写,常见的匹配模式有4种:分别是不区分大小写模式、点号通配模式、多行模式和注释模式
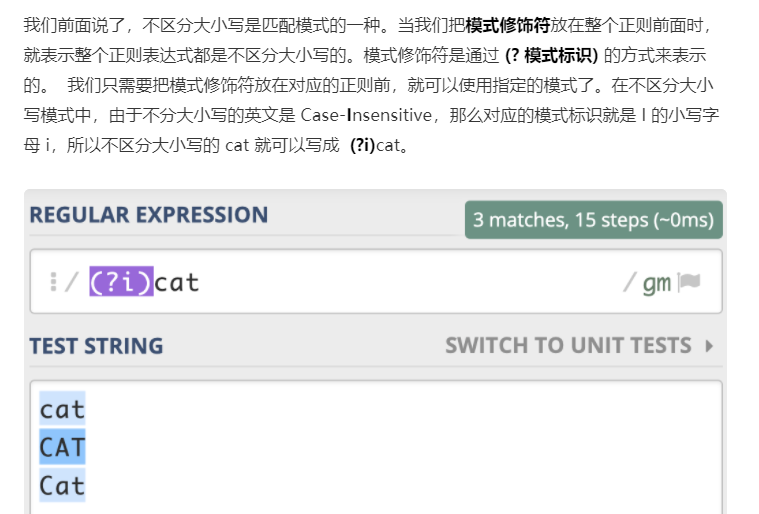
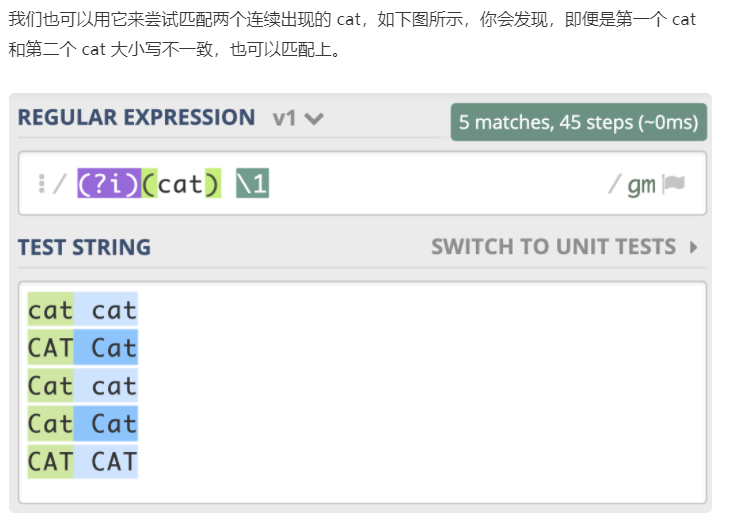
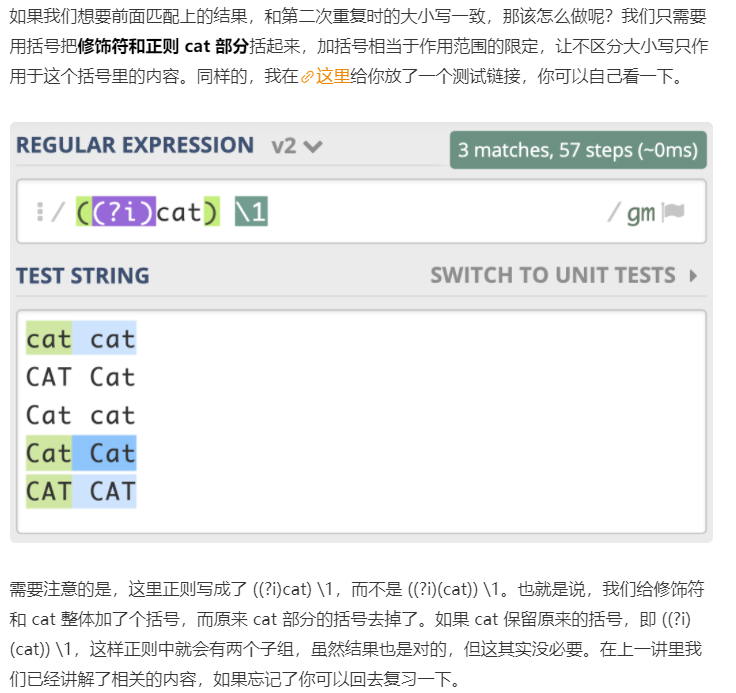
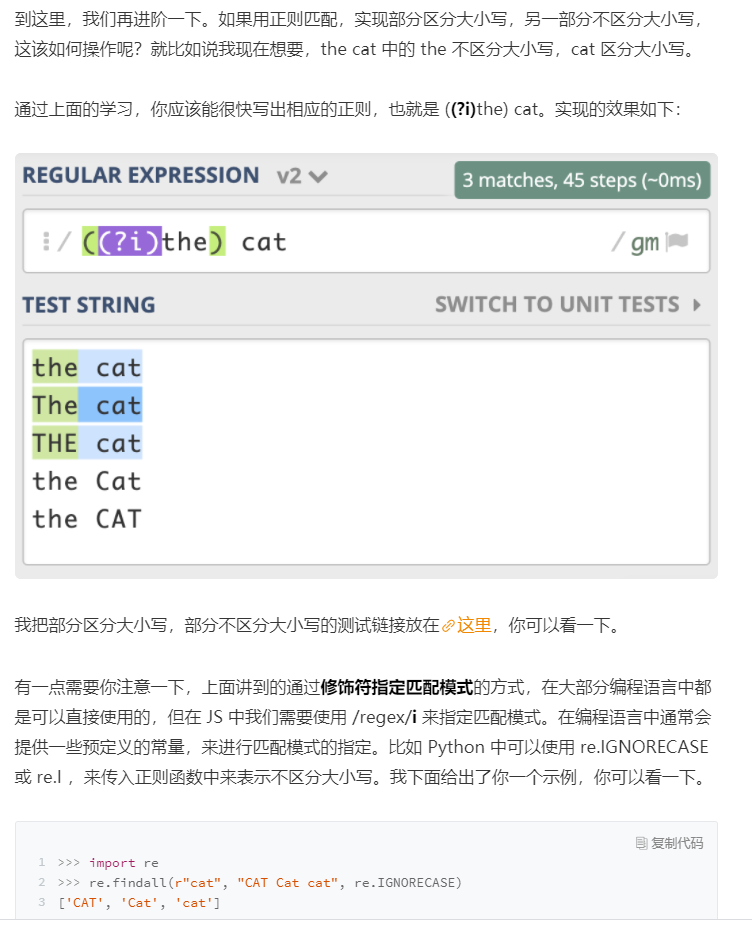
总结一下不区分大小写模式的知识点:
1. 不区分大小写模式的指定方式,使用模式修饰符(?i)
2.修饰符如果在括号内,作用范围是这个括号内的正则,而不是整个正则
3.使用编程语言时可以使用预定义好的常量来指定匹配模式
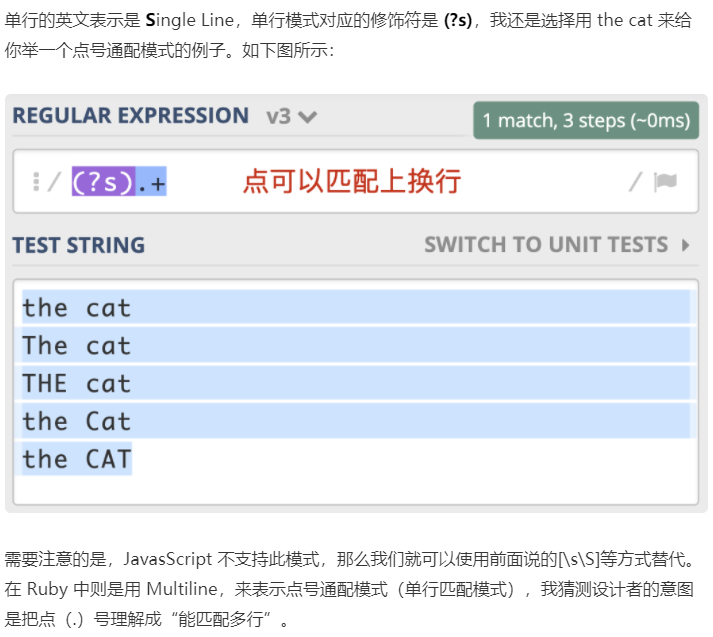
十一:点号通配模式:最直观的解释是之前的元字符.能匹配上所有的字符,但是匹配不了换行,现在是需要让.也能匹配上换行,那就需要用点号通配模式:(?s)
其实目的就是能匹配多行

十二:多行匹配模式
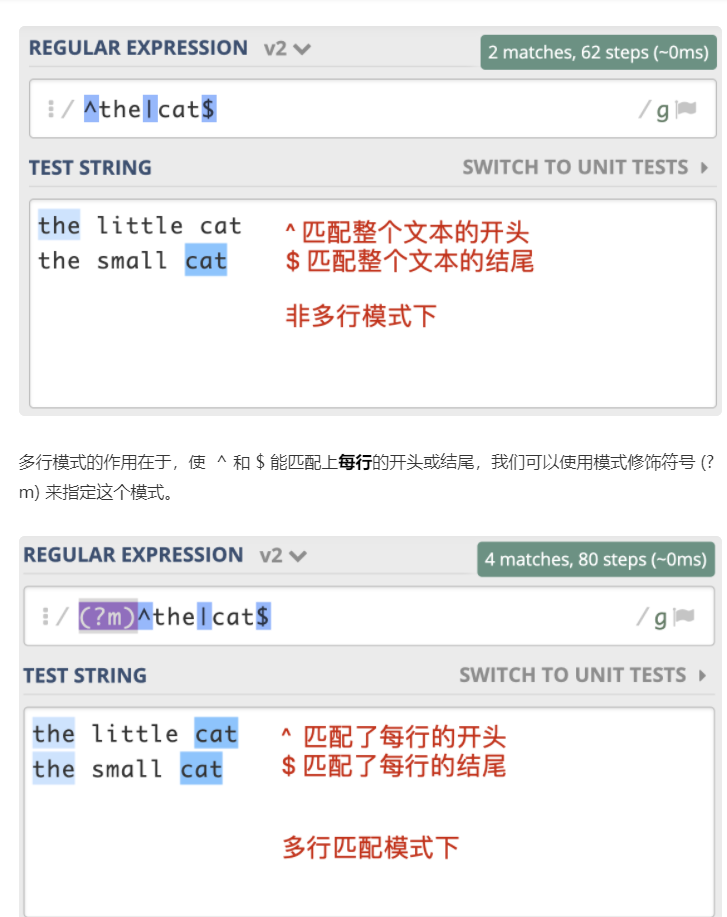
这个多行匹配模式的作用:在处理日志时,如果日志以时间开头,有一些日志打印了堆栈信息,占用了多行,我们就可以使用多行匹配模式,在日志中匹配到以时间开头的每一行日志
这个是正则表达式的模式修饰符。
(?i)即匹配时不区分大小写。表示匹配时不区分大小写。
(?s)即Singleline(单行模式)。表示更改.的含义,使它与每一个字符匹配(包括换行 符\n)。
(?m)即Multiline(多行模式) 。 表示更改^和$的 含义,使它们分别在任意一行的行首和行尾匹配,而不仅仅在整个字符串的开头和结尾匹配。(在此模式下,$的 精确含意是:匹配\n之前的位置以及字符串结束前的位置.)
(?x):表示如果加上该修饰符,表达式中的空白字符将会被忽略,除非它已经被转义。
(?e):表示本修饰符仅仅对于replacement有用,代表在replacement中作为PHP代码。
(?A):表示如果使用这个修饰符,那么表达式必须是匹配的字符串中的开头部分。比如说"/a/A"匹配"abcd"。
(?E):与"m"相反,表示如果使用这个修饰符,那么"$"将匹配绝对字符串的结尾,而不是换行符前面,默认就打开了这个模式。
(?U):表示和问号的作用差不多,用于设置"贪婪模式"。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号