DRF简单复习
DRF
上周回顾
1.web开发模型: 混合开发 前后端分离
2.web api : 前后端传输的媒介(接口)json格式
3.postman使用 : 测接口 很多软件 非必须使用这个
4.# restful规范十条(面试很大可能会问)
5.djangorestframework :django的第三方插件(也叫app),常用的第三方插件 内置的:auth、分页器、froms。 第三方:djangorestframework
6.drf好几大组件
请求(apiview源码,request对象)和响应(response)
序列化(重点)
视图(第二重要)
路由(手动写,自动生成)
action装饰器
解析器(DEFAULT_PARSER_CLASSES、全局配置、局部配置)
响应器(DEFAULT_RENDERER_CLASSES、全局配置、局部配置)
认证:验证是否登录(有内置、自定义、全局配置、局部配置)
权限:是否有权限访问某些接口(有内置、自定义、全局配置、局部配置)
频率:限制访问接口的访问频次(有内置、自定义、全局配置、局部配置、可以根据用户id或者ip)
过滤:筛选符合条件的 #他其实不算内置的组件
排序:对结果进行排序 #他其实不算内置的组件
异常:全局异常(自定义,全局配)
分页器:顾名思义,进行分页
下面的不属于drf内置组件
文档生成
jwt认证
x
1.DRF简单复习
1.1DRF创建类
from django.db import models
# Create your models here.
class BaseModel(models.Model):
is_delete = models.BooleanField(default=False)
create_time = models.DateTimeField(auto_now_add=True, verbose_name='创建时间')
last_update_time = models.DateTimeField(auto_now=True, verbose_name='最后登录或修改时间')
class Meta:
# 单个字段有索引,有唯一
# 多个字段,有联合索引,联合唯一
abstract = True # 抽象表,不在数据库建表
class Book(BaseModel):
id = models.AutoField(primary_key=True)
#verbose_name:中文显示 help_text:输入框的一个小注释
title = models.CharField(max_length=32, verbose_name='书名',help_text='这里填书名')
price = models.DecimalField(max_digits=5, decimal_places=2, verbose_name='价格')
# 关联字段写在多的一方,to_field默认不用写 关联表的字段
# db_constraint=False:逻辑上和Publish有关联,增删不受外键影响,orm查询不影响,本质就是保留跨表查询的便利(双下划线跨表查询```),但是不用约束字段了,一般公司都用false,这样就省的报错,因为没有了约束(Field字段对象,既约束,又建立表与表之间的关系)
Publish = models.ForeignKey(to='Publish', on_delete=models.CASCADE, db_constraint=False, verbose_name='出版社')
# 自动:第三张表只有关联字段 手动:可以进行扩展
# 不能写on_delete 因为是第三张表
authors = models.ManyToManyField(to='Author', db_constraint=False, verbose_name='作者')
class Meta:
# admin中的表名中文显示
verbose_name_plural = '书籍表'
def __str__(self):
return self.title
class Publish(BaseModel):
id = models.AutoField(primary_key=True)
name = models.CharField(max_length=32, verbose_name='出版社名称')
addr = models.CharField(max_length=32, verbose_name='出版社详情')
class Meta:
verbose_name_plural = '出版社'
def __str__(self):
return self.name
class Author(BaseModel):
name = models.CharField(max_length=32, verbose_name='作者名字')
gender = models.IntegerField(choices=((1, '男'), (2, '女')), verbose_name='性别')
# 一对一 写在任意一方 OneToOneField本质其实就是foreignkey加unique
authordetail = models.OneToOneField(to='AuthorDetail', db_constraint=False, on_delete=models.CASCADE)
class Meta:
verbose_name_plural = '作者表'
def __str__(self):
return self.name
class AuthorDetail(BaseModel):
mobile = models.CharField(max_length=32, verbose_name='电话号')
class Meta:
verbose_name_plural = '作者详情'
def __str__(self):
return self.mobile
#迁移数据库 makemigrations migrate 创建超级用户 creatsuperuser
1.2DRF序列化类
from rest_framework import serializers
#如果序列化的是数据库的表,尽量用ModelSerializer
# 声明序列化器,所有的序列化器都要直接或者间接继承于 Serializer
# 其中,ModelSerializer是Serializer的子类,ModelSerializer在Serializer的基础上进行了代码简化
from api import models
class BookModelSerialzer(serializers.ModelSerializer):
#解决多表联合显示问题
#第一种方案 序列化可以 反序列化有问题
# publish=serializers.CharField(source='publish.name')
#第二种方案models中写方法 加上一个@property 这里调用
class Meta:
model = models.Book #跟那个表建立关系
#fields = '__all__' #序列化的字段
#depth = 1 #表关联 1:查询关联的表的信息, 0:还是只显示id
fields = ('title','price','authors','publish','publish_name','authors_list')
#我们可以使用extra_kwargs参数为ModelSerializer添加或修改原有的选项参数
extra_kwargs={
'publish':{'write_only': True},
'publish_name':{'read_only':True},
'authors':{'write_only': True},
'authors_list':{'read_only':True},
}
1.3路由分法
1.总路由
from django.contrib import admin
from django.urls import path,include
urlpatterns = [
path('admin/', admin.site.urls),
#路由分法
path('api/', include('api.urls')),
]
2.分路由
from django.urls import path
from api import views
urlpatterns = [
path('books/', views.BookAPIView.as_view()),
]
1.4admin配置
from django.contrib import admin
# Register your models here.
from api import models
#为了让admin页面可以显示这几张表
admin.site.register(models.Book)
admin.site.register(models.Publish)
admin.site.register(models.Author)
admin.site.register(models.AuthorDetail)
1.5settings配置

1.6启动测试
发现路由分发起了作用
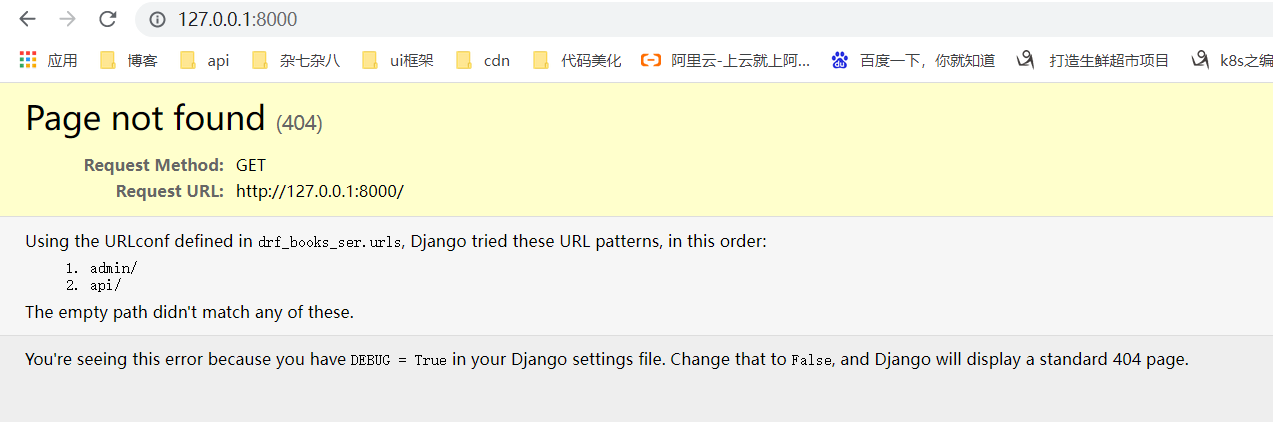
1.7加上之后的呢
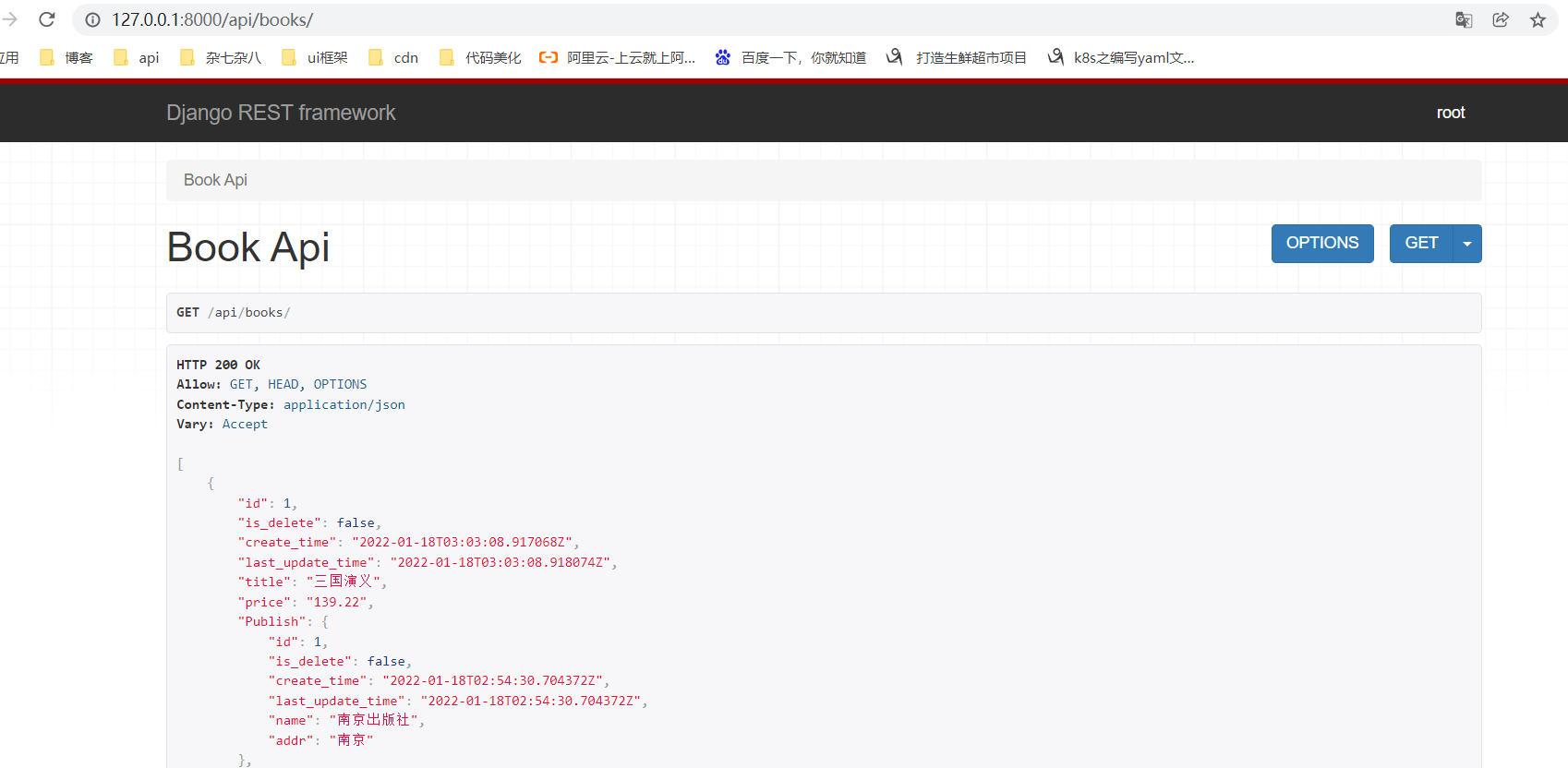
1.8views视图
class BookAPIView(APIView):
def get(self,request,*args,**kwargs):
#获取图书全部列表
book_list=models.Book.objects.all().filter(is_delete=False)
#获取数据
book_list_ser=ser.BookModelSerialzer(instance=book_list,many=True)
print(book_list_ser.data)
return Response(data=book_list_ser.data)
1.8.1但是还有一些问题,查询时候外键显示的有问题
#序列化类BookModelSerialzer 加一些东西
class BookModelSerialzer(serializers.ModelSerializer):
#解决多表联合显示问题
#第一种方案 序列化可以 反序列化有问题
# publish=serializers.CharField(source='publish.name')
#第二种方案models中写方法 加上一个@property 这里调用
class Meta:
model = models.Book
# fields = '__all__'
# depth = 1
fields = ('title','price','authors','publish','publish_name','authors_list')
#我们可以使用extra_kwargs参数为ModelSerializer添加或修改原有的选项参数
extra_kwargs={
'publish':{'write_only': True},
'publish_name':{'read_only':True},
'authors':{'write_only': True},
'authors_list':{'read_only':True},
}
###########################models类##################
class Book(BaseModel):
id = models.AutoField(primary_key=True)
#verbose_name:中文显示 help_text:输入框的一个小注释
title = models.CharField(max_length=32, verbose_name='书名',help_text='这里填书名')
price = models.DecimalField(max_digits=5, decimal_places=2, verbose_name='价格')
# 关联字段写在多的一方,to_field默认不用写 关联表的字段
# db_constraint=False:逻辑上和Publish有关联,增删不受外键影响,orm查询不影响,本质就是保留跨表查询的便利(双下划线跨表查询```),但是不用约束字段了,一般公司都用false,这样就省的报错,因为没有了约束(Field字段对象,既约束,又建立表与表之间的关系)
publish = models.ForeignKey(to='Publish', on_delete=models.CASCADE, db_constraint=False, verbose_name='出版社')
# 自动:第三张表只有关联字段 手动:可以进行扩展
# 不能写on_delete 因为是第三张表
authors = models.ManyToManyField(to='Author', db_constraint=False, verbose_name='作者')
class Meta:
# admin中的表名中文显示
verbose_name_plural = '书籍表'
def __str__(self):
return self.title
#让他前端显示publish.name
@property
def publish_name(self):
return self.publish.name
#显示作者列表
def authors_list(self):
authors_list=self.authors.all()
# get_xxx_display 获取CharField choices 对应的值
ll =[{'name':author.name,'gender':author.get_gender_display()} for author in authors_list]
return ll
1.8.2目前结果如下图
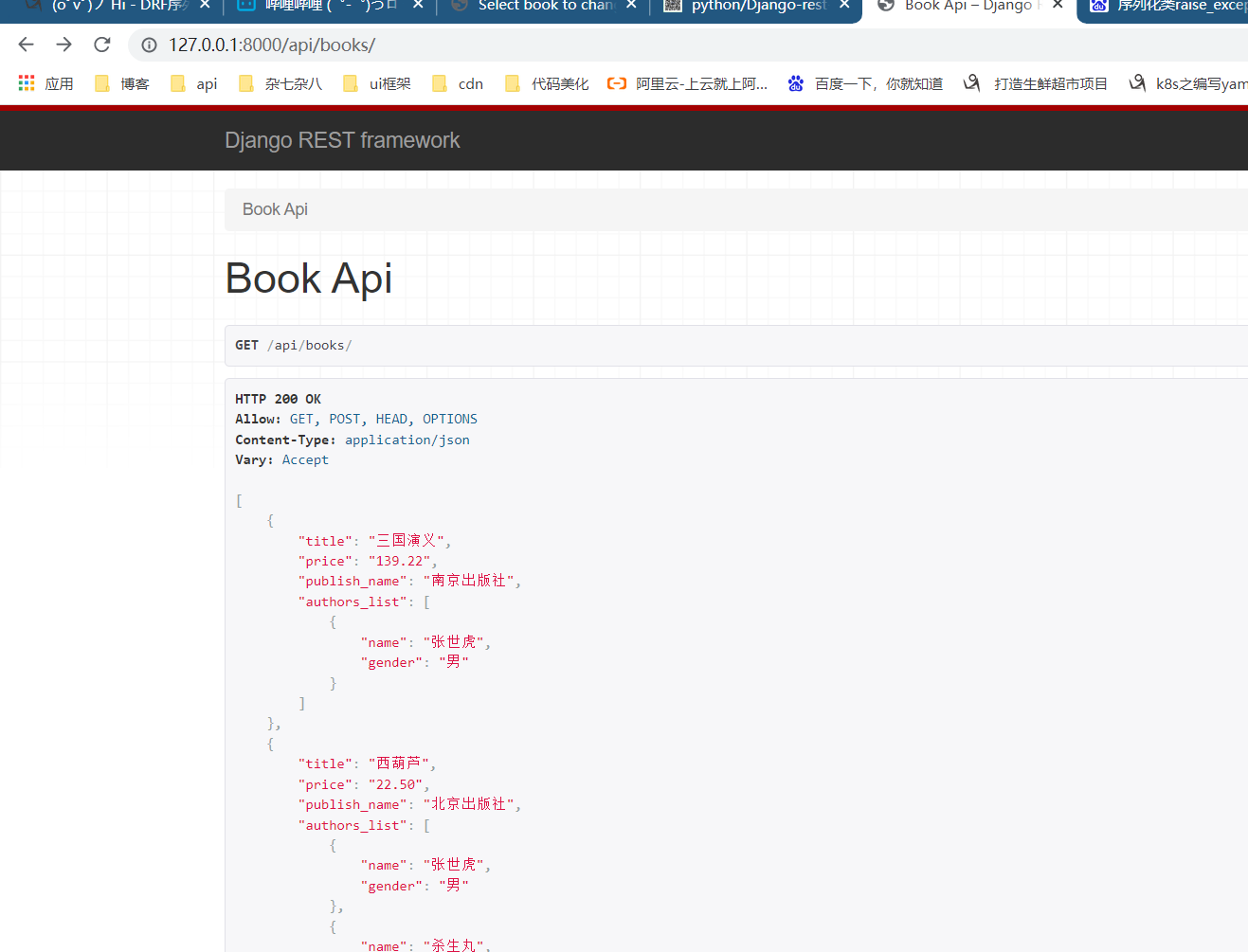
2.post请求插入数据 (单条数据)
#在views视图加入post方法
class BookAPIView(APIView):
def get(self,request,*args,**kwargs):
#获取图书全部列表
book_list=models.Book.objects.all().filter(is_delete=False)
#获取数据
book_list_ser=ser.BookModelSerialzer(instance=book_list,many=True)
print(book_list_ser.data)
return Response(data=book_list_ser.data)
def post(self, request, *args, **kwargs):
# 1.反序列化接受的参数 前端传入的数据,在request.data中,是个字典
book_ser = ser.BookModelSerialzer(data=request.data)
print(book_ser)
# 2.数据校验:如果是True,表示校验通过,直接保存,raise_exception等于True会主动抛出异常
book_ser.is_valid(raise_exception=True)
book_ser.save() # 调用保存,但是有问题,保存不了,一定要在序列化类中重写某个方法
#返回前端
return Response(data=book_ser.data)
3.post请求插入数据 (多条数据)
#判断request.data是字典还是列表 就可以分辨是单条数据还是多条数据
def post(self, request, *args, **kwargs):
#函数来判断一个对象是否是一个已知的类型
if isinstance(request.data,dict): #如果是一个字典 单条数据
# 1.反序列化接受的参数 前端传入的数据,在request.data中,是个字典
book_ser = ser.BookModelSerialzer(data=request.data)
print(book_ser)
# 2.数据校验:如果是True,表示校验通过,直接保存,raise_exception等于True会主动抛出异常
book_ser.is_valid(raise_exception=True)
book_ser.save() # 调用保存,但是有问题,保存不了,一定要在序列化类中重写某个方法
#返回前端增加的数据
return Response(data=book_ser.data)
elif isinstance(request.data,list):#如果是一个列表 多条数据
# 1.反序列化接受的参数 前端传入的数据,在request.data中,是个字典
#现在book_ser 是listSerializer
book_ser = ser.BookModelSerialzer(data=request.data,many=True)
print(book_ser)
# 2.数据校验:如果是True,表示校验通过,直接保存,raise_exception等于True会主动抛出异常
book_ser.is_valid(raise_exception=True)
#调用的是是listSerializer的save方法 所以可以批量增
book_ser.save() # 调用保存,但是有问题,保存不了,一定要在序列化类中重写某个方法
#返回前端增加的数据
return Response(data=book_ser.data)
4.修改单条数据
5.修改多条数据
序列化类里面
Meta里面
# 声明这句 调用save 会走自己设置的方法
list_serializer_class = MyListSerializer
#重写一个类 继承ListSerializer,重写update方法
class MyListSerializer(serializers.ListSerializer):
# validated_data校验过后的数据
# def create(self, validated_data):
# print(validated_data)
# return super().create(validated_data)
# instance
def update(self, instance, validated_data):
print(instance)
print(validated_data)
#保存数据
#self.child是BookModelSerialzer对象
return [
# 修改的是数据对象 key value 通过for循环得到 enumerate 循环结果为key+value
self.child.update(instance[i],attrs) for i,attrs in enumerate (validated_data)
]
#视图类里
def put(self,request,*args,**kwargs):
#修改单个
if kwargs.get('pk',None):
book=models.Book.objects.filter(pk=kwargs.get('pk')).first()
book_ser=ser.BookModelSerialzer(data=request.data)
book_ser.is_valid(raise_exception=True)
book_ser.save()
return Response(data=book_ser.data)
else:
#修改多个
#处理前端传过来的数据[{boo1},{book2}] 列表套子典
book_list=[]
modify_data=[]
#循环传过来的数据
for item in request.data:
#pop 删除item里面的id 并把id的值赋值给pk
pk=item.pop('id')
book = models.Book.objects.get(pk=pk)
book_list.append(book)
modify_data.append(item)
#instance对象列表 data要修改的数据列表
# 第一种方案for循环的方式
for i,si_data in enumerate(modify_data):
#序列化
book_ser = ser.BookModelSerialzer(instance=book_list[i],data=si_data)
book_ser.is_valid(raise_exception=True)
book_ser.save()
return Response(data='成功')
# 第二种方案
book_ser=ser.BookModelSerialzer(instance=book_list,data=modify_data,many=True)
book_ser.is_valid(raise_exception=True)
book_ser.save() #调用自己的update方法
return Response(data=book_ser.data)
#总结:就是把传入的数据变成循环出来

