事务索引等
事务索引等
pymysql 模块
import pymysql
conn=pymysql.connect(
host='127.0.0.1',
port=3306,
user='账户名',
passwd='密码',
database='数据库名称'
charset='utf8',
autocommit=True
)
cursor=conn.cursor(cursor=pymysql.cursors.DictCursor)#制作游标对象
sql='select * from userinfo'#编写sql语句
#执行sql语句
cursor.execute(sql)
cursor.executemany(sql,[(),()])#多个sql语句列表里套元组
#获取执行结果
cursor.fetchall #所有
cursor.fetchone #第一个
cursor.fetchmany #多个
注册登录功能
def register(cursor):
username=input('输入你要注册的用户').strip()
sql = 'select * from userinfo where name=%s'
cursor.execute(sql,(username))
res=cursor.fetchall()
if not res:
password=input('请输入密码').strip()
sql1='insert into userinfo(name,password) values(%s,%s)'
cursor.execute(sql1,(username,password))
print('用户%s注册成功'%username)
else:
print('用户已存在')
def login(cursor):
username=input('请输入你要登录的用户').strip()
sql='select * from userinfo where name=%s'
cursor.execute(sql,(username))
res=cursor.fetchall()
if res :
password=input('请输入密码').strip()
# print(res)
dict_name=res[0] #列表套字典
if str(dict_name.get('password'))==password:
print('登陆成功')
else:
print('密码错误')
else:
print('账户不存在')
def loginout(cursor):
cursor.close
print('退出成功')
exit()
def get_conn():
import pymysql
conn=pymysql.connect(
host='127.0.0.1',
port=3306,
user='root',
password='123',
charset='utf8',
database='db5_1',
autocommit=True
)
cursor=conn.cursor(cursor=pymysql.cursors.DictCursor)
return cursor
func_dic={'1':register,'2':login ,'3':loginout}
while True:
cursor=get_conn()
print('''
1.注册功能
2.登录功能
3.退出
''')
choise=input('请输入你要选择的编号').strip()
if choise in func_dic:
func_name=func_dic.get(choise)
func_name(cursor)
else:
print('输入有误,请从新输入')
- 视图(了解)
- 触发器(了解,但是比视图有用)
- 存储过程(了解)
- 流程控制(了解)
- 内置函数
- 事务(重点)
- 索引(二叉树、b树、b+树、b*树)与慢查询优化(explain语句)
视图(view)
将SQL语句的查询结果当做虚拟表实体化保存起来,以后可以反复使用 #(一般不使用因为在cmd它显示是个表,其实本质在Navicat里看是view视图)
create view teacher2course as
select * from teacher inner join course on teacher.tid = course.teacher_id;
drop view teacher2course;
# 视图使用频率不高
触发器(了解)trigger
满足特定条件执行 类似于crontab(定时器)
#在mysql中只有满足
#三大类 :
增加
删除
修改
#六小类:
增加前,增加后
删除前,删除后
修改前,修改后
#语法结构 befor:之前 after:之后 for each row:每一行
create trigger 触发器的名字 before/after insert/update/delete on 表名 for each row
begin
sql语句
end
#命名规则
tri_after_insere_t1
触发器_之前/之后_插入/修改/删除_表名
#修改sql语句结束符 之前是; 修改为$$
delimiter $$ 临时修改
# 在MySQL中NEW特指数据对象可以通过点的方式获取字段对应的数据
#添加一条数据
id name pwd hobby
1 zzz 123 read
NEW.name >>> zzz
#触发器实例
CREATE TABLE cmd (
id INT PRIMARY KEY auto_increment,
USER CHAR (32),
priv CHAR (10),
cmd CHAR (64),
sub_time datetime, #提交时间
success enum ('yes', 'no') #0代表执行失败
);
CREATE TABLE errlog (
id INT PRIMARY KEY auto_increment,
err_cmd CHAR (64),
err_time datetime
);
delimiter $$ # 将mysql默认的结束符由;换成$$
create trigger tri_after_insert_cmd after insert on cmd for each row
begin
if NEW.success = 'no' then # 新记录都会被MySQL封装成NEW对象 new.字段名 拿到添加的字段数据
insert into errlog(err_cmd,err_time) values(NEW.cmd,NEW.sub_time);
end if;
end $$
delimiter ; # 结束之后记得再改回来,不然后面结束符就都是$$了
#往表cmd中插入记录,触发触发器,根据IF的条件决定是否插入错误日志
INSERT INTO cmd (
USER,
priv,
cmd,
sub_time,
success
)
VALUES
('tony','0755','ls -l /etc',NOW(),'yes'),
('tony','0755','cat /etc/passwd',NOW(),'no'),
('tony','0755','useradd xxx',NOW(),'no'),
('tony','0755','ps aux',NOW(),'yes');
# 查询errlog表记录
select * from errlog;
# 查看触发器
show triggers\G;
# 删除触发器
drop trigger tri_after_insert_cmd;
存储过程(了解)
# 类似于python中的自定义函数 定义个函数
#存储过程在哪个库下面创建的只能在对应的库下面使用
# 1.无参存储过程
delimiter $$ #修改默认结束符,临时修改
create procedure p1()
begin
select * from user;
end $$
delimiter ;
# 调用函数
call p1()
----------------------------------------------------
# 2.有参存储过程
set @res =10 #定义变量
select @res #查看变量 res=10
delimiter $$
create procedure p2(
in m int, # in表示这个参数必须只能是传入不能被返回出去
in n int,
out res int # out表示这个参数可以被返回出去,还有一个inout表示即可以传入也可以被返回出去
)
begin
select * from user where id > m and id < n;
set res=0; # 用来标志存储过程是否执行
end $$
delimiter ;
#调用
call p2(2,4,10) #报错
call p2(2,4,@res);
select @res #发现变为0因为存储过程里把res修改成0了
#查看存储过程具体信息
show create procedure 函数名;
#查看所有存储过程
show procedure status;
#删除存储过程
drop procedure 函数名;
------------------------------------------------------------------------------------------
# 代码操作存储过程
import pymysql
conn = pymysql.connect(
host='127.0.0.1',
port=3306,
user='root',
passwd='123',
db='db6',
charset='utf8',
autocommit=True
)
cursor = conn.cursor(cursor=pymysql.cursors.DictCursor)
cursor.callproc('p2',(1,3,10))
# @_p1_0=1,@_p1_1=3,@_p1_2=10; 上面对应的那三个数字变形成下面这个
print(cursor.fetchall())
流程控制(了解)
# if判断
if 条件 then
子代码;
#不满足条件会执行下面的
elseif 条件1 then
子代码;
else #上面都不满足
子代码
endif
-----------------------------------------------------------------
if i = 1 THEN
SELECT 1;
ELSEIF i = 2 THEN
SELECT 2;
ELSE
SELECT 7;
END IF;
# while循环
while 条件 do
满足执行这个;
改变条件;
end while
SET num = 0 ;
WHILE num < 10 DO
SELECT
num ;
SET num = num + 1 ;
END WHILE ;
内置函数
#只能在sql语句中使用 不能单独调用
#help 内置函数名 可以查看内置函数怎么用
help trim
mysql> SELECT TRIM(' bar ');
-> 'bar'
mysql> SELECT TRIM(LEADING 'x' FROM 'xxxbarxxx');
-> 'barxxx'
mysql> SELECT TRIM(BOTH 'x' FROM 'xxxbarxxx');
-> 'bar'
mysql> SELECT TRIM(TRAILING 'xyz' FROM 'barxxyz');
-> 'barx'
# 1.移除指定字符
Trim、LTrim、RTrim
# 2.大小写转换
Lower、Upper
mysql> SET @str = BINARY 'New York';
mysql> SELECT LOWER(@str), LOWER(CONVERT(@str USING latin1));
mysql> SELECT UPPER('Hej');
-> 'HEJ'
# 3.获取左右起始指定个数字符
Left、Right
mysql> SELECT LEFT('foobarbar', 5);
-> 'fooba'
mysql> SELECT RIGHT('foobarbar', 4);
-> 'rbar'
# 4.返回读音相似值(对英文效果)
Soundex #目前只对英文有效
"""
eg:客户表中有一个顾客登记的用户名为J.Lee
但如果这是输入错误真名其实叫J.Lie,可以使用soundex匹配发音类似的
##### where Soundex(name)=Soundex('J.Lie')
"""
# 5.日期格式:date_format
'''在MySQL中表示时间格式尽量采用2022-11-11形式'''
#创建blog表 添加数据
CREATE TABLE blog (
id INT PRIMARY KEY auto_increment,
NAME CHAR (32),
sub_time datetime
);
INSERT INTO blog (NAME, sub_time)
VALUES
('第1篇','2015-03-01 11:31:21'),
('第2篇','2015-03-11 16:31:21'),
('第3篇','2016-07-01 10:21:31'),
('第4篇','2016-07-22 09:23:21'),
('第5篇','2016-07-23 10:11:11'),
('第6篇','2016-07-25 11:21:31'),
('第7篇','2017-03-01 15:33:21'),
('第8篇','2017-03-01 17:32:21'),
('第9篇','2017-03-01 18:31:21');
#按照年月分组
Y m d H M S X
年 月 日 时 分 秒 时分秒
select date_format(sub_time,'%Y-%m'),count(id) from blog group by date_format(sub_time,'%Y-%m');
1.where Date(sub_time) = '2015-03-01' #where 年月日等于
2.where Year(sub_time)=2016 AND Month(sub_time)=07;
# 更多日期处理相关函数
adddate 增加一个日期
addtime 增加一个时间
datediff计算两个日期差值
...
事务(重点)
四大特性(ACID)
A:原子性
每个事务都是不可分割的最小单位,同一个事务内的多个操作 要么同时成功,要么同时失败
C:一致性
执行完事务之后,数据库数据的状态从一个一致性状态变为另一个一致性状态(一致性与原子性是密切相关的)
I:隔离性(也可以叫独立性)
事务与事务彼此之间不干扰,每个事务都是彼此独立的
D:持久性(也叫永久性)
一个事务一旦提交,他对数据库中数据的改变应该是永久性的
# 如何开启事务
start transaction;
开始执行操作数据库代码 #开启事务之后操作数据库代码 没有写入到硬盘 写入到内存 需要commit才可以
# 如何回滚
rollback; #回滚之后 事务就结束了 如果还需要事务需要在启动
# 如何确认
commit; #commit之后 事务也结束了
索引与慢查询优化
#什么是索引
简单理解为:加快数据查询速度的工具,也可以比喻成书的目录
让获取的数据更有目的性,从而提高数据库检索数据的性能
#索引内部基于算法构造出来的 什么是算法
算法:解决事物的办法
入门级算法:二分法(不能算算法的算法) 前提必须有序
[1,2,3,4,5,6...1000000] 找8888
比较中间的 判断数据在那面 然后再对半分比较中间的 以此类推
python 实现二分法
l =[1,12,21,31,41,51,61,71,81,91]
def dichotomy(nums,find_nums):
print(nums)
if len(nums)==0:
print('不存在')
return
mid_nums=len(nums)//2 #求中间值索引
if find_nums>nums[mid_nums]:#要查找的数字大于中间的数字,左面的肯定不是 取右面的
dichotomy(nums[mid_nums+1:],find_nums) # 在调用这个方法,通过中间值取右面的值
elif find_nums<nums[mid_nums]:#要查找的数字小于中间的数字,右面的肯定不是 取左面的
dichotomy(nums[:mid_nums],find_nums)
else:
print('你要找的数字为:',nums[mid_nums])
dichotomy(l,41)
数据结构:二叉树:每个节点只能分两个叉
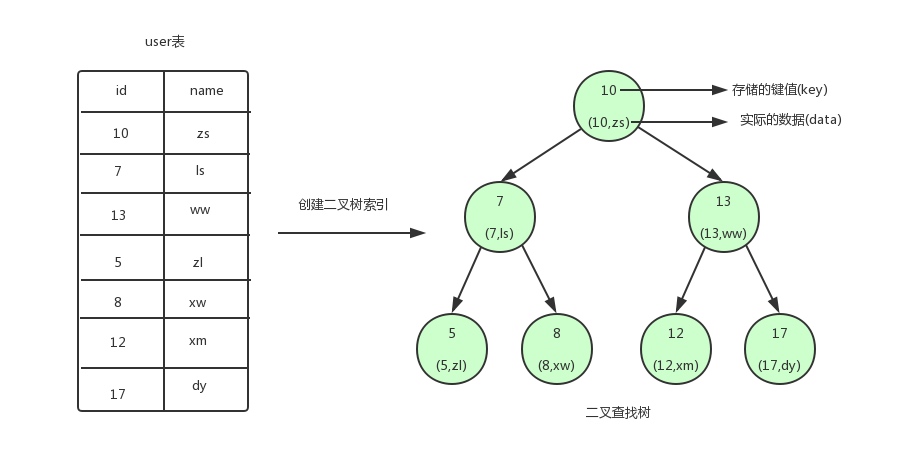
数据结构:b树

查找一个精确数字 :需要三次
查找一个范围数字 :次数由树的高度决定 次数为 层数的倍数
查找完小于xxx的 再回到开始再找大于yyy的
数据结构:b+树(为了解决范围查找)

在叶子层加了索引直接到另一个叶子层
数据结构:b*树

#总结
二叉树(只能分两个叉)
b树 b+树(叶子节点添加了指针) b*树(枝节点也添加了指针)
# 添加指针是为了加快范围查询的速度
将某个字段添加成索引就相当于依据该字段建立了一颗b+树从而加快查询速度
如果某个字段没有添加索引 那么依据该字段查询数据会非常的慢(一行行查找)
索引的分类
1.primary key
主键索引除了有加速查询的效果之外 还具有一定的约束条件
2.unique key
唯一键索引 除了有加速查询的效果之外 还具有一定的约束条件
3.index key
普通索引 只有加速查询的效果 没有额外约束
4.foreign key
# 注意外键不是索引 它仅仅是用来创建表与表之间关系的
数据库设计三大范式
第一范式
要求确保表中每列的原子性,也就是不可拆分
第二范式
要求确保表中每列与主键相关,而不能只与主键的某部分相关(主要针对联合主键),主键列与非主键列遵循完全函数依赖关系,也就是完全依赖; 表里的数据都应该和主键有直接关系 完全依赖
第三范式
确保主键列之间没有传递函数依赖关系,也就是消除传递依赖。确保数据表中的每一列数据都和主键直接相关,而不能间接相关,属性不依赖于其他非主属性
范式优点
结构合理
冗余较小
尽量避免插入删除修改异常
范式缺点
性能降低
多表查询比单表查询速度慢
数据库的设计应该根据当前情况和需求做出灵活的处理
在实际设计中,要整体遵循范式理论
如果在某些特定的情况下还死死遵循范式也是不可取的,因为可能降低数据库的效率,此时可以适当增加冗余而提高性能。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号