
Redis
一 什么是Redis:
REmote DIctionary Server(Redis) 是一个由Salvatore Sanfilippo写的key-value存储系统。遵守BSD协议,是一个高性能的key-value数据库。
Redis是一个开源的使用ANSI C语言编写、遵守BSD协议、支持网络、可基于内存亦可持久化的日志型、Key-Value数据库,并提供多种语言的API。
它通常被称为数据结构服务器,因为值(value)可以是 字符串(String), 哈希(Map), 列表(list), 集合(sets) 和 有序集合(sorted sets)等类型。
二 Redis与Memcached:
在此基础上,redis支持各种不同方式的排序。与memcached一样,为了保证效率,
数据都是缓存在内存中。区别的是redis会周期性的把更新的数据写入磁盘或者把修改操作写入追加的记录文件,并且在此基础上实现了master-slave(主从)同步。
Memcached是一个自由开源的,高性能,分布式内存对象缓存系统。
Memcached是以LiveJournal旗下Danga Interactive公司的Brad Fitzpatric为首开发的一款软件。现在已成为mixi、hatena、Facebook、Vox、LiveJournal等众多服务中提高Web应用扩展性的重要因素。
Memcached是一种基于内存的key-value存储,用来存储小块的任意数据(字符串、对象)。这些数据可以是数据库调用、API调用或者是页面渲染的结果。
Memcached简洁而强大。它的简洁设计便于快速开发,减轻开发难度,解决了大数据量缓存的很多问题。它的API兼容大部分流行的开发语言。
本质上,它是一个简洁的key-value存储系统。
一般的使用目的是,通过缓存数据库查询结果,减少数据库访问次数,以提高动态Web应用的速度、提高可扩展性。
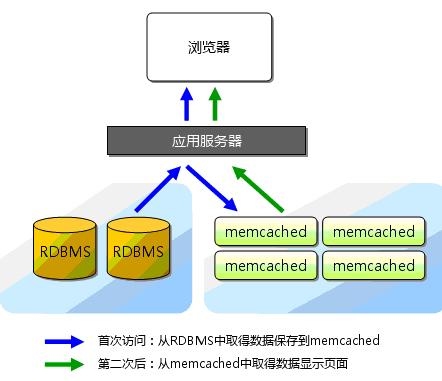
三 redis 持久化功能:
1、RDB
RDB是基于快照的一种持久化功能,保存某个时间点的,key:value状态。
dbfilename dump.rdb
dir /data/redis
save 900 1 --------》保存快照的频率,第一个数字表示多长时间,第二个表示执行多少次操作。
save 300 10
save 60 10000
优点:
快速持久化,周期性的把数据存到写入磁盘。
占用磁盘空间少,所以占用的磁盘空间少。
一般备份是通过RDB实现的,
主从复制功能也是通RDB功能实现的。
缺点:
当断电,重启时,RDB会丢失少部分数据,还是会有部分的数据丢失。
2、AOF :
AOF(append only file)持久化:以独立日志的方式记录每次写命令,重启时再重新执行AOF文件中命令达到恢复数据的目的。AOF的主要作用是解决了数据持久化的实时性,目前已经是Redis持久化的主流方式。
appendonly LogFile,追加模式的日志记录持久化方式。会记录redis中所有变更类的命令。
appendonly yes -------》不要立刻刷,只有在操作系统需要刷的时候再刷。比较快。
appendfsync always ---》每次写操作都立刻写入到aof文件。慢,但是最安全。
appendfsync everysec--》每秒写一次。折中方案。
优点:相对RDB来讲,更加安全了。
缺点:持久化速度相对较慢,需要更多的存储空间。

四 数据类型:
string
hash
list
set
sorted set (有序集合)
(redis目前提供四种数据类型:string,list,set及zset(sorted set)和Hash。
string是最简单的类型,你可以理解成与Memcached一模一个的类型,一个key对应一个value,其上支持的操作与Memcached的操作类似。但它的功能更丰富。
list是一个链表结构,主要功能是push、pop、获取一个范围的所有值等等。操作中key理解为链表的名字。
set是集合,和我们数学中的集合概念相似,对集合的操作有添加删除元素,有对多个集合求交并差等操作。操作中key理解为集合的名字。
zset是set的一个升级版本,他在set的基础上增加了一个顺序属性,这一属性在添加修改元素的时候可以指定,每次指定后,zset会自动重新按新的值调整顺序。
可以理解了有两列的mysql表,一列存value,一列存顺序。操作中key理解为zset的名字。
Hash数据类型允许用户用Redis存储对象类型,Hash数据类型的一个重要优点是,当你存储的数据对象只有很少几个key值时,
数据存储的内存消耗会很小.更多关于Hash数据类型的说明请见: http://code.google.com/p/redis/wiki/Hashes)
key:value
key的通用操作:
KEYS * 查看KEY支持通配符
DEL 删除给定的一个或多个key
EXISTS 检查是否存在
RENAME 变更KEY名
TYPE 返回键所存储值的类型
EXPIRE\ PEXPIRE 以秒\毫秒设定生存时间
TTL\ PTTL 以秒\毫秒为单位返回生存时间
PERSIST 取消生存实现设置
STRING
计数器的实现:
incr num 每次累计加1 decr num 每次累计减1 incrby num 10000 累计加10000 decrby num 10000 累计减10000
普通键值对操作:
127.0.0.1:6379> set name zhangsan OK 127.0.0.1:6379> 127.0.0.1:6379> 127.0.0.1:6379> get name "zhangsan" 127.0.0.1:6379> mset id 101 name zhangsan age 20 gender m OK 127.0.0.1:6379> keys * 1) "name" 2) "id" 3) "xyz" 4) "jishu" 5) "age" 6) "gender" 127.0.0.1:6379> mget id name age gender 1) "101"
增
set mykey "test" 为键设置新值,并覆盖原有值 getset mycounter 0 设置值,取值同时进行 setex mykey 10 "hello" 设置指定 Key 的过期时间为10秒,在存活时间可以获取value setnx mykey "hello" 若该键不存在,则为键设置新值 mset key3 "zyx" key4 "xyz" 批量设置键
删
del mykey 删除已有键
改
append mykey "hello" 若该键并不存在,返回当前 Value 的长度 该键已经存在,返回追加后 Value的长度 incr mykey 值增加1,若该key不存在,创建key,初始值设为0,增加后结果为1 decrby mykey 5 值减少5 setrange mykey 20 dd 把第21和22个字节,替换为dd, 超过value长度,自动补0
查
exists mykey 判断该键是否存在,存在返回 1,否则返回0 get mykey 获取Key对应的value strlen mykey 获取指定 Key 的字符长度 ttl mykey 查看一下指定 Key 的剩余存活时间(秒数) getrange mykey 1 20 获取第2到第20个字节,若20超过value长度,则截取第2个和后面所有的 mget key3 key4 批量获取键
Hash类型(字典)
hmset stu id 101 name zhangsan age 20 gender m
hgetall stu
hmget stu id name
HVALS stu
增
hset myhash field1 "s" 若字段field1不存在,创建该键及与其关联的Hashes, Hashes中,key为field1 ,并设value为s ,若存在会覆盖原value hsetnx myhash field1 s 若字段field1不存在,创建该键及与其关联的Hashes, Hashes中,key为field1 ,并设value为s, 若字段field1存在,则无效 hmset myhash field1 "hello" field2 "world 一次性设置多个字段 删
hdel myhash field1 删除 myhash 键中字段名为 field1 的字段 del myhash 删除键 改
hincrby myhash field 1 给field的值加1 查
hget myhash field1 获取键值为 myhash,字段为 field1 的值 hlen myhash 获取myhash键的字段数量 hexists myhash field1 判断 myhash 键中是否存在字段名为 field1 的字段 hmget myhash field1 field2 field3 一次性获取多个字段 hgetall myhash 返回 myhash 键的所有字段及其值 hkeys myhash 获取myhash 键中所有字段的名字 hvals myhash 获取 myhash 键中所有字段的值
List 列表
127.0.0.1:6379> lpush wechat "today is nice day!" (integer) 1 127.0.0.1:6379> lpush wechat "today is bad day!" (integer) 2 127.0.0.1:6379> lpush wechat "today is good day!" (integer) 3 127.0.0.1:6379> lpush wechat "today is abc day!" (integer) 4 127.0.0.1:6379> lpush wechat "today is xyz day!" 127.0.0.1:6379> LRANGE wechat 0 -1 1) "today is xyz day!" 2) "today is abc day!" 3) "today is good day!" 4) "today is bad day!" 5) "today is nice day!" 127.0.0.1:6379> LRANGE wechat -1 -2 (empty list or set) 127.0.0.1:6379> LRANGE wechat -2 -3 (empty list or set) 127.0.0.1:6379> LRANGE wechat -2 -1 1) "today is bad day!" 2) "today is nice day!" 127.0.0.1:6379> LRANGE wechat -2 -2 1) "today is bad day!" 127.0.0.1:6379> 127.0.0.1:6379> LINDEX wechat 2 "today is bad day!" 127.0.0.1:6379> 127.0.0.1:6379> LPOP wechat "today is xyz day!"
增 lpush mykey a b 若key不存在,创建该键及与其关联的List,依次插入a ,b, 若List类型的key存在,则插入value中 lpushx mykey2 e 若key不存在,此命令无效, 若key存在,则插入value中 linsert mykey before a a1 在 a 的前面插入新元素 a1 linsert mykey after e e2 在e 的后面插入新元素 e2 rpush mykey a b 在链表尾部先插入b,在插入a rpushx mykey e 若key存在,在尾部插入e, 若key不存在,则无效 rpoplpush mykey mykey2 将mykey的尾部元素弹出,再插入到mykey2 的头部(原子性的操作) 删 del mykey 删除已有键 lrem mykey 2 a 从头部开始找,按先后顺序,值为a的元素,删除数量为2个,若存在第3个,则不删除 ltrim mykey 0 2 从头开始,索引为0,1,2的3个元素,其余全部删除 改 lset mykey 1 e 从头开始, 将索引为1的元素值,设置为新值 e,若索引越界,则返回错误信息 rpoplpush mykey mykey 将 mykey 中的尾部元素移到其头部 查 lrange mykey 0 -1 取链表中的全部元素,其中0表示第一个元素,-1表示最后一个元素。 lrange mykey 0 2 从头开始,取索引为0,1,2的元素 lrange mykey 0 0 从头开始,取第一个元素,从第0个开始,到第0个结束 lpop mykey 获取头部元素,并且弹出头部元素,出栈 lindex mykey 6 从头开始,获取索引为6的元素 若下标越界,则返回nil
set 集合
127.0.0.1:6379> sadd lxl jnl pg ms mr abc xyz baoqiang yf (integer) 8 127.0.0.1:6379> sadd jnl baoqiang yf xyz mr lxl (integer) 5 127.0.0.1:6379> SINTER lxl jnl 1) "mr" 2) "baoqiang" 3) "xyz" 4) "yf" 127.0.0.1:6379> SDIFF lxl jnl 1) "jnl" 2) "abc" 3) "ms" 4) "pg" 127.0.0.1:6379> SDIFF jnl lxl 1) "lxl" 127.0.0.1:6379> 127.0.0.1:6379> 127.0.0.1:6379> 127.0.0.1:6379> SUNION jnl lxl 1) "baoqiang" 2) "pg" 3) "xyz" 4) "yf" 5) "lxl" 6) "mr" 7) "jnl" 8) "ms" 9) "abc" 127.0.0.1:6379> SINTERSTORE gthy lxl jnl (integer) 4 127.0.0.1:6379> SMEMBERS gthy 1) "mr" 2) "baoqiang" 3) "yf" 4) "xyz" 127.0.0.1:6379>
有序集合
zset -----》(sortedset)
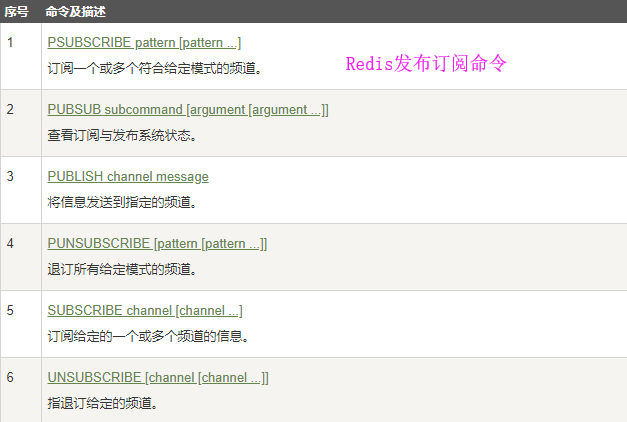
发布订阅:
Redis 发布订阅(pub/sub)是一种消息通信模式:发送者(pub)发送消息,订阅者(sub)接收消息。
Redis 客户端可以订阅任意数量的频道。
下图展示了频道 channel1 , 以及订阅这个频道的三个客户端 —— client2 、 client5 和 client1 之间的关系:
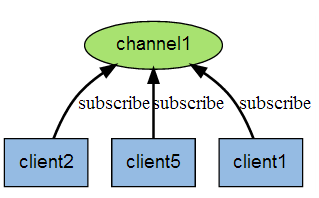
当有新消息通过 PUBLISH 命令发送给频道 channel1 时, 这个消息就会被发送给订阅它的三个客户端:

订阅实例:
窗口1: redis-cli -a 123 SUBSCRIBE fm1039 订阅单个频道 PSUBSCRIBE fm* 订阅多个频道 窗口2: 127.0.0.1:6379> PUBLISH fm1039 "hi!" (integer) 1 127.0.0.1:6379> PUBLISH fm1039 "hi!" (integer) 1 127.0.0.1:6379> PUBLISH fm1038 "hi!" (integer) 1 127.0.0.1:6379> PUBLISH fm1037 "hi!" (integer) 1 127.0.0.1:6379>
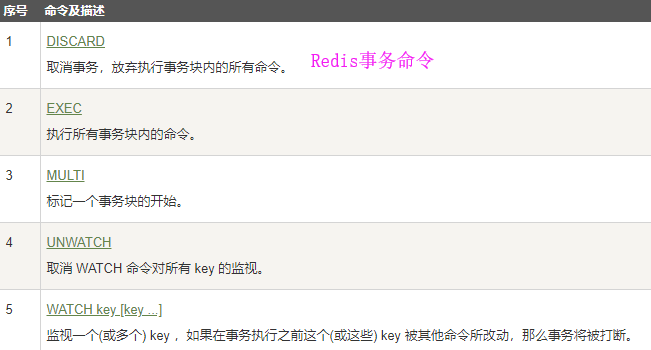
Redis事务:
Redis 事务可以一次执行多个命令, 并且带有以下两个重要的保证:
- 批量操作在发送 EXEC 命令前被放入队列缓存。
- 收到 EXEC 命令后进入事务执行,事务中任意命令执行失败,其余的命令依然被执行。
- 在事务执行过程,其他客户端提交的命令请求不会插入到事务执行命令序列中。
一个事务从开始到执行会经历以下三个阶段:
- 开始事务。
- 命令入队。
- 执行事务。
实例:
以下是一个事务的例子, 它先以 MULTI 开始一个事务, 然后将多个命令入队到事务中, 最后由 EXEC 命令触发事务, 一并执行事务中的所有命令:
redis 127.0.0.1:6379> MULTI OK redis 127.0.0.1:6379> SET book-name "Mastering C++ in 21 days" QUEUED redis 127.0.0.1:6379> GET book-name QUEUED redis 127.0.0.1:6379> SADD tag "C++" "Programming" "Mastering Series" QUEUED redis 127.0.0.1:6379> SMEMBERS tag QUEUED redis 127.0.0.1:6379> EXEC 1) OK 2) "Mastering C++ in 21 days" 3) (integer) 3 4) 1) "Mastering Series" 2) "C++" 3) "Programming"
单个 Redis 命令的执行是原子性的,但 Redis 没有在事务上增加任何维持原子性的机制,所以 Redis 事务的执行并不是原子性的。
事务可以理解为一个打包的批量执行脚本,但批量指令并非原子化的操作,中间某条指令的失败不会导致前面已做指令的回滚,也不会造成后续的指令不做。
Redis服务器:
以下实例演示了如何获取 redis 服务器的统计信息:


redis 127.0.0.1:6379> INFO # Server redis_version:2.8.13 redis_git_sha1:00000000 redis_git_dirty:0 redis_build_id:c2238b38b1edb0e2 redis_mode:standalone os:Linux 3.5.0-48-generic x86_64 arch_bits:64 multiplexing_api:epoll gcc_version:4.7.2 process_id:3856 run_id:0e61abd297771de3fe812a3c21027732ac9f41fe tcp_port:6379 uptime_in_seconds:11554 uptime_in_days:0 hz:10 lru_clock:16651447 config_file: # Clients connected_clients:1 client-longest_output_list:0 client-biggest_input_buf:0 blocked_clients:0 # Memory used_memory:589016 used_memory_human:575.21K used_memory_rss:2461696 used_memory_peak:667312 used_memory_peak_human:651.67K used_memory_lua:33792 mem_fragmentation_ratio:4.18 mem_allocator:jemalloc-3.6.0 # Persistence loading:0 rdb_changes_since_last_save:3 rdb_bgsave_in_progress:0 rdb_last_save_time:1409158561 rdb_last_bgsave_status:ok rdb_last_bgsave_time_sec:0 rdb_current_bgsave_time_sec:-1 aof_enabled:0 aof_rewrite_in_progress:0 aof_rewrite_scheduled:0 aof_last_rewrite_time_sec:-1 aof_current_rewrite_time_sec:-1 aof_last_bgrewrite_status:ok aof_last_write_status:ok # Stats total_connections_received:24 total_commands_processed:294 instantaneous_ops_per_sec:0 rejected_connections:0 sync_full:0 sync_partial_ok:0 sync_partial_err:0 expired_keys:0 evicted_keys:0 keyspace_hits:41 keyspace_misses:82 pubsub_channels:0 pubsub_patterns:0 latest_fork_usec:264 # Replication role:master connected_slaves:0 master_repl_offset:0 repl_backlog_active:0 repl_backlog_size:1048576 repl_backlog_first_byte_offset:0 repl_backlog_histlen:0 # CPU used_cpu_sys:10.49 used_cpu_user:4.96 used_cpu_sys_children:0.00 used_cpu_user_children:0.01 # Keyspace db0:keys=94,expires=1,avg_ttl=41638810 db1:keys=1,expires=0,avg_ttl=0 db3:keys=1,expires=0,avg_ttl=0
BGREWRITEAOF 异步执行一个 AOF(AppendOnly File) 文件重写操作 2 BGSAVE 在后台异步保存当前数据库的数据到磁盘 3 CLIENT KILL [ip:port] [ID client-id] 关闭客户端连接 4 CLIENT LIST 获取连接到服务器的客户端连接列表 5 CLIENT GETNAME 获取连接的名称 6 CLIENT PAUSE timeout 在指定时间内终止运行来自客户端的命令 7 CLIENT SETNAME connection-name 设置当前连接的名称 8 CLUSTER SLOTS 获取集群节点的映射数组 9 COMMAND 获取 Redis 命令详情数组 10 COMMAND COUNT 获取 Redis 命令总数 11 COMMAND GETKEYS 获取给定命令的所有键 12 TIME 返回当前服务器时间 13 COMMAND INFO command-name [command-name ...] 获取指定 Redis 命令描述的数组 14 CONFIG GET parameter 获取指定配置参数的值 15 CONFIG REWRITE 对启动 Redis 服务器时所指定的 redis.conf 配置文件进行改写 16 CONFIG SET parameter value 修改 redis 配置参数,无需重启 17 CONFIG RESETSTAT 重置 INFO 命令中的某些统计数据 18 DBSIZE 返回当前数据库的 key 的数量 19 DEBUG OBJECT key 获取 key 的调试信息 20 DEBUG SEGFAULT 让 Redis 服务崩溃 21 FLUSHALL 删除所有数据库的所有key 22 FLUSHDB 删除当前数据库的所有key 23 INFO [section] 获取 Redis 服务器的各种信息和统计数值 24 LASTSAVE 返回最近一次 Redis 成功将数据保存到磁盘上的时间,以 UNIX 时间戳格式表示 25 MONITOR 实时打印出 Redis 服务器接收到的命令,调试用 26 ROLE 返回主从实例所属的角色 27 SAVE 同步保存数据到硬盘 28 SHUTDOWN [NOSAVE] [SAVE] 异步保存数据到硬盘,并关闭服务器 29 SLAVEOF host port 将当前服务器转变为指定服务器的从属服务器(slave server) 30 SLOWLOG subcommand [argument] 管理 redis 的慢日志 31 SYNC 用于复制功能(replication)的内部命令
vim Linux文本编辑工具
1、命令模式:
G 光标到达最后一行 10G 光标到到10行 3yy 复制3行 3dd 删除(剪切) p 粘贴 dG 删除所有行 u 撤销到上次操作 ^ 光标到达行首 $ 光标到达行尾 / 查找关键字
2、编辑模式(插入模式)
a i o
3、末行模式(冒号模式)
Esc
:wq
主从复制实现:
1、环境:
准备两个或两个以上redis实例 mkdir /data/638{0..2} 配置文件示例: vim /data/6380/redis.conf port 6380 daemonize yes pidfile /data/6380/redis.pid loglevel notice logfile "/data/6380/redis.log" dbfilename dump.rdb dir /data/6380 protected-mode no vim /data/6381/redis.conf port 6381 daemonize yes pidfile /data/6381/redis.pid loglevel notice logfile "/data/6381/redis.log" dbfilename dump.rdb dir /data/6381 protected-mode no vim /data/6382/redis.conf port 6382 daemonize yes pidfile /data/6382/redis.pid loglevel notice logfile "/data/6382/redis.log" dbfilename dump.rdb dir /data/6382 protected-mode no
启动:
redis-server /data/6380/redis.conf redis-server /data/6381/redis.conf redis-server /data/6382/redis.conf
主节点:6380
从节点:6381、6382
2、开启主从:
6381/6382命令行: redis-cli -p 6381 SLAVEOF 127.0.0.1 6380 redis-cli -p 6382 SLAVEOF 127.0.0.1 6380
3、查询主从状态
从库:
[root@db01 ~]# redis-cli -p 6382 127.0.0.1:6382> info replication [root@db01 ~]# redis-cli -p 6381 127.0.0.1:6381> info replication
redis-sentinel(哨兵)
1、监控 2、自动选主,切换(6381 slaveof no one) 3、2号从库(6382)指向新主库(6381)
sentinel搭建过程
mkdir /data/26380 cd /data/26380 vim sentinel.conf port 26380 dir "/data/26380" sentinel monitor mymaster 127.0.0.1 6380 1 sentinel down-after-milliseconds mymaster 5000
启动:
redis-sentinel /data/26380/sentinel.conf &
windows安装redis新驱动
cd d: d: D:\>cd redis D:\redis>python3 setup.py install sentinel模式: >>> from redis.sentinel import Sentinel >>> sentinel = Sentinel([('127.0.0.1', 26379)], socket_timeout=0.1) >>> sentinel.discover_master('mymaster') >>> sentinel.discover_slaves('mymaster') >>> master = sentinel.master_for('mymaster', socket_timeout=0.1) >>> slave = sentinel.slave_for('mymaster', socket_timeout=0.1) >>> master.set('foo', 'bar') >>> slave.get('foo') 'bar'
redis cluster 特性:
高性能: 1、在多分片节点中,将16384个槽位,均匀分布到多个分片节点中 2、存数据时,将key做crc16(key),然后和16384进行取模,得出槽位值(0-16383之间) 3、根据计算得出的槽位值,找到相对应的分片节点的主节点,存储到相应槽位上 4、如果客户端当时连接的节点不是将来要存储的分片节点,分片集群会将客户端连接切换至真正存储节点进行数据存储 高可用: 在搭建集群时,会为每一个分片的主节点,对应一个从节点,实现slaveof的功能,同时当主节点down,实现类似于sentinel的自动failover的功能。 规划、搭建过程: 6个redis实例,一般会放到3台硬件服务器 注:在企业规划中,一个分片的两个分到不同的物理机,防止硬件主机宕机造成的整个分片数据丢失。 端口号:7000-7005
1、安装集群插件:
EPEL源安装ruby支持 yum install ruby rubygems -y 使用国内源 gem sources -l gem sources -a http://mirrors.aliyun.com/rubygems/ gem sources --remove http://rubygems.org/ gem install redis -v 3.3.3 gem sources -l 或者: gem sources -a http://mirrors.aliyun.com/rubygems/ --remove http://rubygems.org/
2、集群节点准备
mkdir /data/700{0..5}
vim /data/7000/redis.conf
port 7000
daemonize yes
pidfile /data/7000/redis.pid
loglevel notice
logfile "/data/7000/redis.log"
dbfilename dump.rdb
dir /data/7000
protected-mode no
cluster-enabled yes
cluster-config-file nodes.conf
cluster-node-timeout 5000
appendonly yes
vim /data/7001/redis.conf
port 7001
daemonize yes
pidfile /data/7001/redis.pid
loglevel notice
logfile "/data/7001/redis.log"
dbfilename dump.rdb
dir /data/7001
protected-mode no
cluster-enabled yes
cluster-config-file nodes.conf
cluster-node-timeout 5000
appendonly yes
vim /data/7002/redis.conf
port 7002
daemonize yes
pidfile /data/7002/redis.pid
loglevel notice
logfile "/data/7002/redis.log"
dbfilename dump.rdb
dir /data/7002
protected-mode no
cluster-enabled yes
cluster-config-file nodes.conf
cluster-node-timeout 5000
appendonly yes
vim /data/7003/redis.conf
port 7003
daemonize yes
pidfile /data/7003/redis.pid
loglevel notice
logfile "/data/7003/redis.log"
dbfilename dump.rdb
dir /data/7003
protected-mode no
cluster-enabled yes
cluster-config-file nodes.conf
cluster-node-timeout 5000
appendonly yes
vim /data/7004/redis.conf
port 7004
daemonize yes
pidfile /data/7004/redis.pid
loglevel notice
logfile "/data/7004/redis.log"
dbfilename dump.rdb
dir /data/7004
protected-mode no
cluster-enabled yes
cluster-config-file nodes.conf
cluster-node-timeout 5000
appendonly yes
vim /data/7005/redis.conf
port 7005
daemonize yes
pidfile /data/7005/redis.pid
loglevel notice
logfile "/data/7005/redis.log"
dbfilename dump.rdb
dir /data/7005
protected-mode no
cluster-enabled yes
cluster-config-file nodes.conf
cluster-node-timeout 5000
appendonly yes
启动节点:
redis-server /data/7000/redis.conf redis-server /data/7001/redis.conf redis-server /data/7002/redis.conf redis-server /data/7003/redis.conf redis-server /data/7004/redis.conf redis-server /data/7005/redis.conf
[root@db01 ~]# ps -ef |grep redis root 8854 1 0 03:56 ? 00:00:00 redis-server *:7000 [cluster] root 8858 1 0 03:56 ? 00:00:00 redis-server *:7001 [cluster] root 8860 1 0 03:56 ? 00:00:00 redis-server *:7002 [cluster] root 8864 1 0 03:56 ? 00:00:00 redis-server *:7003 [cluster] root 8866 1 0 03:56 ? 00:00:00 redis-server *:7004 [cluster] root 8874 1 0 03:56 ? 00:00:00 redis-server *:7005 [cluster]
3、将节点加入集群管理
redis-trib.rb create --replicas 1 127.0.0.1:7000 127.0.0.1:7001 \ 127.0.0.1:7002 127.0.0.1:7003 127.0.0.1:7004 127.0.0.1:7005 redis的多API支持 python为例 tar xf Python-3.5.2.tar.xz cd Python-3.5.2 ./configure make && make install https://redis.io/clients 下载redis-py-master.zip unzip redis-py-master.zip cd redis-py-master python3 setup.py install 安装redis-cluser的客户端程序 cd redis-py-cluster-unstable python3 setup.py install
1、对redis的单实例进行连接操作
python3 >>>import redis >>>r = redis.StrictRedis(host='localhost', port=6379, db=0,password='123') >>>r.set('foo', 'bar') True >>>r.get('foo') 'bar'
2、sentinel集群连接并操作
[root@db01 ~]# redis-server /data/6380/redis.conf [root@db01 ~]# redis-server /data/6381/redis.conf [root@db01 ~]# redis-server /data/6382/redis.conf [root@db01 ~]# redis-sentinel /data/26380/sentinel.conf & ## 导入redis sentinel包 >>> from redis.sentinel import Sentinel ##指定sentinel的地址和端口号 >>> sentinel = Sentinel([('localhost', 26380)], socket_timeout=0.1) ##测试,获取以下主库和从库的信息 >>> sentinel.discover_master('mymaster') >>> sentinel.discover_slaves('mymaster') ##配置读写分离 #写节点 >>> master = sentinel.master_for('mymaster', socket_timeout=0.1) #读节点 >>> slave = sentinel.slave_for('mymaster', socket_timeout=0.1) ###读写分离测试 key >>> master.set('oldboy', '123') >>> slave.get('oldboy') '123' redis cluster的连接并操作(python2.7.2以上版本才支持redis cluster,我们选择的是3.5) https://github.com/Grokzen/redis-py-cluster
3、python连接rediscluster集群测试
使用python3 >>> from rediscluster import StrictRedisCluster >>> startup_nodes = [{"host": "127.0.0.1", "port": "7000"}] ### Note: decode_responses must be set to True when used with python3 >>> rc = StrictRedisCluster(startup_nodes=startup_nodes, decode_responses=True) >>> rc.set("foo", "bar") True >>> print(rc.get("foo")) 'bar'

 浙公网安备 33010602011771号
浙公网安备 33010602011771号