Kubernetes集群部署关键知识总结
Kubernetes集群部署需要安装的组件东西很多,过程复杂,对服务器环境要求很苛刻,最好是能连外网的环境下安装,有些组件还需要连google服务器下载,这一点一般很难满足,因此最好是能提前下载好准备的就尽量下载好。
Kubernetes集群部署要求
- 服务器必须是Centos 7.2及以上
- Kubernetes 采用1.12版本
- Docker-ce v17.03.2
- Etcd 3.2.9
- Flanneld v0.7.0-amd64
- TLS 认证通信(所有组件,如etcd、kubernetes master 和node)
- RBAC 授权
- kubedns、dashboard、heapster等插件
- harbor,使用nfs后端存储
……
部署方式
- Minikube 快速搭建单节点Kubenetes集群的工具,只能用作学习实践。
- kubeadm是Kubernetes官方提供的用于快速安装Kubernetes集群的工具
- 使用Rancher部署K8S集群,布署在Docker环境中,方便快捷。
- Ansible脚本安装K8S集群
如果对Rancher吃不透的话还是推荐使用Ansible脚本安装K8S集群,Ansible脚本将安装的流程都封装到了脚本里,只需更改安装主机服务器地址和环境就能实现一键布署。
推荐使用github上的 kubeasz ,能简化很多流程。
kubeasz致力于提供快速部署高可用k8s集群的工具, 并且也努力成为k8s实践、使用的参考书;基于二进制方式部署和利用ansible-playbook实现自动化:即提供一键安装脚本, 也可以分步执行安装各个组件, 同时讲解每一步主要参数配置和注意事项。集群特性:
TLS双向认证、RBAC授权、多Master高可用、支持Network Policy、备份恢复
布署关键点
为了初次安装顺利,关闭防火墙。
确保各节点时区设置一致、时间同步。
无法访问公网情况下,请下载离线docker镜像完成集群安装。
从国内下载docker官方仓库镜像非常缓慢,所以对于k8s集群来说配置镜像加速非常重要,配置 /etc/docker/daemon.json,若访问不了外网就要配置局域网的镜像仓库地址。
docker要开启docker远程API 修改docker配置文件docker.service 在ExecStart这一行后面加上 -H tcp://0.0.0.0:2375 -H unix:///var/run/docker.sock
docker 从 1.13 版本开始,将iptables 的filter 表的FORWARD 链的默认策略设置为DROP,从而导致 ping 其它 Node 上的 Pod IP 失败,因此必须在 filter 表的FORWARD 链增加一条默认允许规则 iptables -I FORWARD -s 0.0.0.0/0 -j ACCEPT
后续calico网络、kube-proxy等将大量使用 iptables规则,要维护好服务器本身的iptables规则。
网络组件
Kubernetes中网络是最复杂的,虽然从架构图上看是很清楚的,但实际操作起来还是到处报错,涉及到防火墙,iptables规则,服务器间的网络,网络组件的配置、容器与容器间的访问,容器与服务器的互相访问等等。
推荐flannel ,这里参考其它博文着重介绍下:
Flannel的功能是让集群中的不同节点主机创建的Docker容器都具有全集群唯一的虚拟IP地址。
Flannel实质上是一种“覆盖网络(overlay network)”,也就是将TCP数据包装在另一种网络包里面进行路由转发和通信,Flannel的设计目的就是为集群中的所有节点重新规划IP地址的使用规则,从而使得不同节点上的容器能够获得“同属一个内网”且”不重复的”IP地址,并让属于不同节点上的容器能够直接通过内网IP通信。
默认的节点间数据通信方式是UDP转发,在Flannel的GitHub页面有如下的一张原理图:

1. 数据从源容器中发出后,经由所在主机的docker0虚拟网卡转发到flannel0虚拟网卡,这是个P2P的虚拟网卡,flanneld服务监听在网卡的另外一端。 Flannel也是通过修改Node的路由表实现这个效果的。
2. 源主机的flanneld服务将原本的数据内容UDP封装后根据自己的路由表投递给目的节点的flanneld服务,数据到达以后被解包,然后直接进入目的节点的flannel0虚拟网卡,然后被转发到目的主机的docker0虚拟网卡,最后就像本机容器通信一样由docker0路由到达目标容器。
3. 使每个结点上的容器分配的地址不冲突。Flannel通过Etcd分配了每个节点可用的IP地址段后,再修改Docker的启动参数。“--bip=X.X.X.X/X”这个参数,它限制了所在节点容器获得的IP范围。
flannel 使用 vxlan 技术为各节点创建一个可以互通的 Pod 网络,使用的端口为 UDP 8472,需要开放该端口。
kube-apiserver的高可用
keepalived+haproxy配置多个后端真实kube-apiserver的endpoints,并启用存活监测后端kube-apiserver,保证kube-apiserver的高可用。
dashboard
dashboard 1.7 以后默认开启了自带的登陆验证机制,1.7 开始,dashboard 只允许通过 https 访问,如果使用 kube proxy 则必须监听 localhost 或 127.0.0.1,对于 NodePort 没有这个限制,但是仅建议在开发环境中使用。
对于不满足这些条件的登录访问,在登录成功后浏览器不跳转,始终停在登录界面。
参考: https://github.com/kubernetes/dashboard/wiki/Accessing-Dashboard---1.7.X-and-abovehttps://github.com/kubernetes/dashboard/issues/2540
- kubernetes-dashboard 服务暴露了 NodePort,可以使用
https://NodeIP:NodePort地址访问 dashboard; - 通过 kube-apiserver 访问 dashboard;
- 通过 kubectl proxy 访问 dashboard:
Ingress
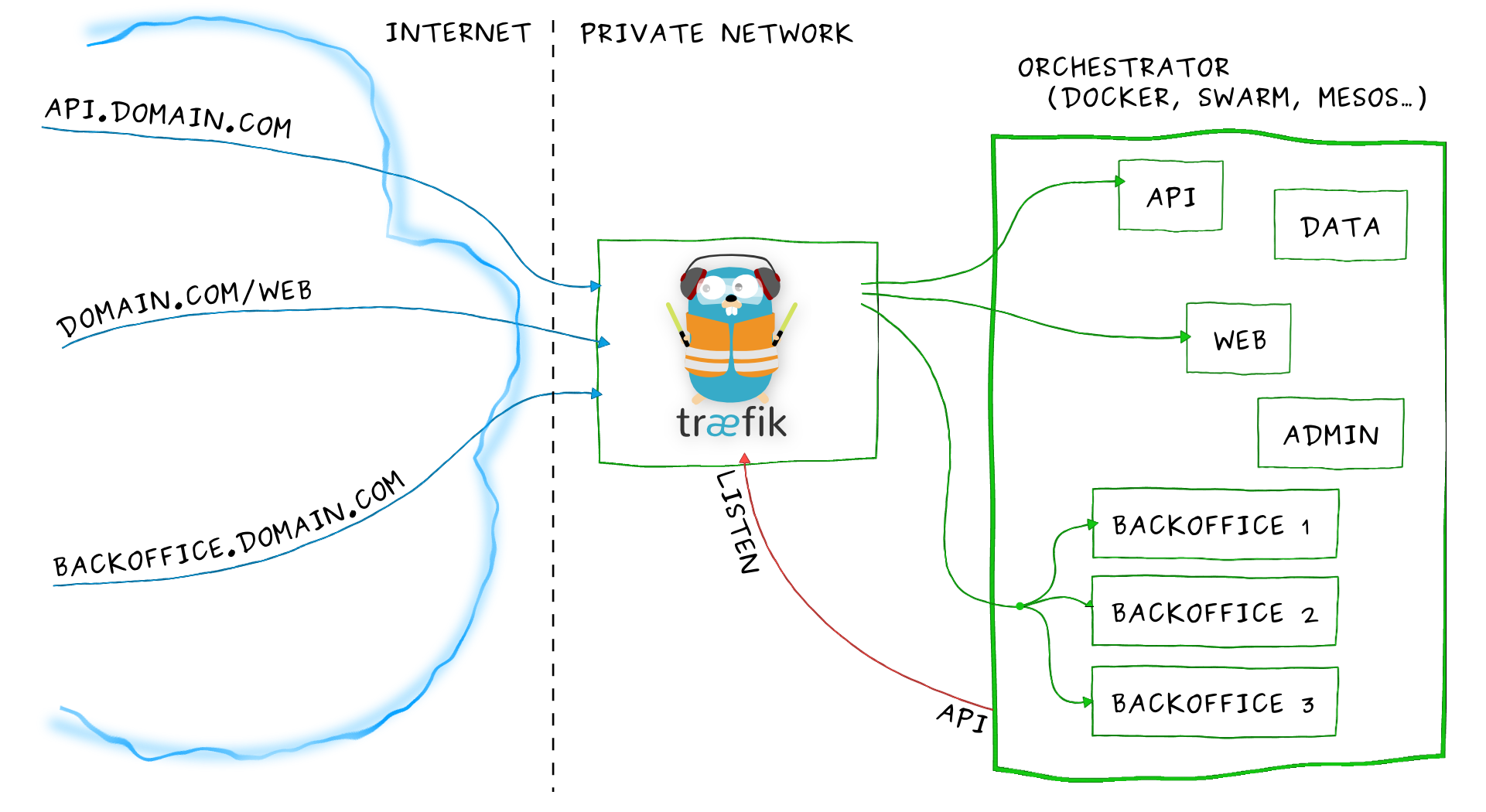
Ingress其实就是从kuberenets集群外部访问集群的一个入口,将外部的请求转发到集群内不同的Service 上,其实就相当于nginx、apache 等负载均衡代理服务器,再加上一个规则定义,路由信息的刷新需要靠Ingress controller来提供。
Ingress controller可以理解为一个监听器,通过不断地与kube-apiserver打交道,实时的感知后端service、pod 等的变化,当得到这些变化信息后,Ingress controller再结合Ingress的配置,更新反向代理负载均衡器,达到服务发现的作用。其实这点和服务发现工具consul的consul-template非常类似。
未配置ingress:
集群外部 -> NodePort -> K8S Service
配置了ingress:
集群外部 -> Ingress -> K8S Service
注意:ingress 本身也需要部署Ingress controller时暴露NodePort让外部访问;如果你集群支持,可以方便地使用LoadBalancer地址暴露ingress服务。
Traefik 提供了一个简单好用 Ingress controller,是一款开源的反向代理与负载均衡工具。它最大的优点是能够与常见的微服务系统直接整合,可以实现自动化动态配置。
如果采用Rancher部署会有从k8s.gcr.io拉取镜像失败问题
新版本的Kubernetes在安装部署中,需要从k8s.grc.io仓库中拉取所需镜像文件,但由于国内网络防火墙问题导致无法正常拉取。
解决方案
docker.io仓库对google的容器做了镜像,可以通过下列命令下拉取相关镜像:
docker pull mirrorgooglecontainers/kube-apiserver:v1.12.0
docker pull mirrorgooglecontainers/kube-controller-manager:v1.12.0
docker pull mirrorgooglecontainers/kube-scheduler:v1.12.0
docker pull mirrorgooglecontainers/kube-proxy:v1.12.0
docker pull mirrorgooglecontainers/pause:3.1
docker pull mirrorgooglecontainers/etcd:3.2.24
docker pull coredns/coredns:1.2.2
版本信息需要根据实际情况进行相应的修改。通过docker tag命令来修改镜像的标签:
docker tag docker.io/mirrorgooglecontainers/kube-proxy:v1.12.0 k8s.gcr.io/kube-proxy:v1.12.0
docker tag docker.io/mirrorgooglecontainers/kube-scheduler:v1.12.0 k8s.gcr.io/kube-scheduler:v1.12.0
docker tag docker.io/mirrorgooglecontainers/kube-apiserver:v1.12.0 k8s.gcr.io/kube-apiserver:v1.12.0
docker tag docker.io/mirrorgooglecontainers/kube-controller-manager:v1.12.0 k8s.gcr.io/kube-controller-manager:v1.12.0
docker tag docker.io/mirrorgooglecontainers/etcd:3.2.24 k8s.gcr.io/etcd:3.2.24
docker tag docker.io/mirrorgooglecontainers/pause:3.1 k8s.gcr.io/pause:3.1
docker tag docker.io/coredns/coredns:1.2.2 k8s.gcr.io/coredns:1.2.2
使用docker rmi删除不用的镜像
dashboard无法显示监控图
dashboard 和heapster influxdb都部署完成后 dashboard依旧无法显示监控图 通过排查 heapster log有超时错误
$ kubectl logs -f pods/heapster-2882613285-58d9r -n kube-system
E0630 17:23:47.339987 1 reflector.go:203] k8s.io/heapster/metrics/sources/kubelet/kubelet.go:342: Failed to list *api.Node: Get http://kubernetes.default/api/v1/nodes?resourceVersion=0: dial tcp: i/o timeout E0630 17:23:47.340274 1 reflector.go:203] k8s.io/heapster/metrics/heapster.go:319: Failed to list *api.Pod: Get http://kubernetes.default/api/v1/pods?resourceVersion=0: dial tcp: i/o timeout E0630 17:23:47.340498 1 reflector.go:203] k8s.io/heapster/metrics/processors/namespace_based_enricher.go:84: Failed to list *api.Namespace: Get http://kubernetes.default/api/v1/namespaces?resourceVersion=0: dial tcp: lookup kubernetes.default on 10.254.0.2:53: dial udp 10.254.0.2:53: i/o timeout E0630 17:23:47.340563 1 reflector.go:203] k8s.io/heapster/metrics/heapster.go:327: Failed to list *api.Node: Get http://kubernetes.default/api/v1/nodes?resourceVersion=0: dial tcp: lookup kubernetes.default on 10.254.0.2:53: dial udp 10.254.0.2:53: i/o timeout E0630 17:23:47.340623 1 reflector.go:203] k8s.io/heapster/metrics/processors/node_autoscaling_enricher.go💯 Failed to list *api.Node: Get http://kubernetes.default/api/v1/nodes?resourceVersion=0: dial tcp: lookup kubernetes.default on 10.254.0.2:53: dial udp 10.254.0.2:53: i/o timeout E0630 17:23:55.014414 1 influxdb.go:150] Failed to create infuxdb: failed to ping InfluxDB server at "monitoring-influxdb:8086" - Get http://monitoring-influxdb:8086/ping: dial tcp: lookup monitoring-influxdb on 10.254.0.2:53: read udp 172.30.45.4:48955->10.254.0.2:53: i/o timeout`
我是docker的systemd Unit文件忘记添加
ExecStart=/root/local/bin/dockerd --log-level=error $DOCKER_NETWORK_OPTIONS
后边的$DOCKER_NETWORK_OPTIONS,导致docker0的网段跟flannel.1不一致。
kube-proxy报错kube-proxy[2241]: E0502 15:55:13.889842 2241 conntrack.go:42] conntrack returned error: error looking for path of conntrack: exec: “conntrack”: executable file not found in $PATH
导致现象:kubedns启动成功,运行正常,但是service 之间无法解析,kubernetes中的DNS解析异常
解决方法:CentOS中安装conntrack-tools包后重启kubernetes 集群即可。
Unable to access kubernetes services: no route to host
导致现象: 在POD 内访问集群的某个服务的时候出现no route to host
$ curl my-nginx.nx.svc.cluster.local
curl: (7) Failed connect to my-nginx.nx.svc.cluster.local:80; No route to host
解决方法:清除所有的防火墙规则,然后重启docker 服务
$ iptables --flush && iptables -tnat --flush
$ systemctl restart docker
使用NodePort 类型的服务,只能在POD 所在节点进行访问
导致现象: 使用NodePort 类型的服务,只能在POD 所在节点进行访问,其他节点通过NodePort 不能正常访问
解决方法: kube-proxy 默认使用的是proxy_model就是iptables,正常情况下是所有节点都可以通过NodePort 进行访问的,我这里将阿里云的安全组限制全部去掉即可,然后根据需要进行添加安全限制。
公众号【一个码农的日常】 技术群:319931204 1号群: 437802986 2号群: 340250479
出处:http://zhangs1986.cnblogs.com/
码云:https://gitee.com/huanzui
本文版权归作者和博客园共有,欢迎转载,但未经作者同意必须保留此段声明,且在文章页面明显位置给出原文连接,否则保留追究法律责任的权利。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号