
在 CentOS7/CentOS8 上使用 cephadm 安装分布式存储系统 Ceph【转 https://www.koenli.com/ef5921b8.html】
Cephadm 介绍
官方文档:https://docs.ceph.com/en/latest/cephadm/
cephadm 用于部署和管理 Ceph 集群,它通过 SSH 将 manager 守护进程连接到主机来实现这一点。manager 守护进程支持添加、删除和更新 Ceph 容器。cephadm 不依赖外部配置工具,例如 Ansible、Rook 和 Salt。
cephadm 管理 Ceph 集群的整个生命周期。此生命周期从引导过程开始,cephadm 在单个节点上创建一个小型 Ceph 集群。此集群由一个监视器(MON)和一个管理器(MGR)组成。然后,cephadm 使用编排接口扩展集群,添加所有主机并提供所有 Ceph 守护进程和服务。此生命周期的管理可以通过 Ceph 命令行接口或仪表盘(Dashboard)执行。
说明:
cephadm是 Ceph v15.2.0(Octopus)中的新功能,不支持旧版本的 Ceph。并且由于某些功能还在开发完善中,部署方式也会随着版本更新会有比较大的变化,建议多参考对应版本的官方文档
警告: Ceph Pacific 版本开始默认不提供 EL7 上的 RPM 源,只提供 EL8 上的
cephadm 正在积极开发中,兼容性与稳定性请关注官方说明
环境信息
| 主机名 | 配置 | 操作系统 | IP 地址 | 角色 | 磁盘 (除系统盘) |
|---|---|---|---|---|---|
| ceph-mon01 | 2 核 4G | CentOS7.5/CentOS8.3 | 10.211.55.7 | cephadm prometheus grafana MON OSD MGR MDS NFS ganesha RGW iSCSI rbd-mirror |
100G * 3 |
| ceph-mon02 | 2 核 4G | CentOS7.5/CentOS8.3 | 10.211.55.8 | MON OSD MGR MDS NFS ganesha RGW iSCSI rbd-mirror |
100G * 3 |
| ceph-mon03 | 2 核 4G | CentOS7.5/CentOS8.3 | 10.211.55.9 | MON OSD MGR MDS NFS ganesha RGW iSCSI rbd-mirror |
100G * 3 |
环境要求
- Python3
- 容器运行时,例如 Docker、Podman
- 所有节点之间保持时间同步,使用 chrony 或 NTP 服务
- 用于调配存储设备的 LVM2
初始化配置
说明:除非特别说明,否则本节操作在所有节点进行。
配置主机名
1
|
hostnamectl set-hostname <hostname>
|
关闭 SELINUX
1
|
sed -i 's/SELINUX=enforcing/SELINUX=disabled/g' /etc/selinux/config
|
关闭防火墙
1
|
systemctl stop firewalld
|
节点之间时间同步
server 端
任选一台机器作为 server 端;如果环境可以访问互联网,可以不需要自己搭建 server 端,参考后面的 client 端部分设置所有节点与公网 ntp 时间服务器 (例如 time1.cloud.tencent.com) 同步时间即可
CentOS7.x
1
|
# 设置时区为Asia/Shanghai
|
CentOS8.x
1
|
# 设置时区为Asia/Shanghai
|
client 端
CentOS7.x
1
|
# 设置时区为Asia/Shanghai
|
CentOS8.x
1
|
# 设置时区为Asia/Shanghai
|
配置 Host 解析
1
|
cat >> /etc/hosts << EOF
|
安装 LVM2
1
|
yum install lvm2 -y
|
安装 Python3
1
|
yum install python3 -y
|
安装 Docker
配置 docker-ce repository
1
|
# 安装所需要的包,yum-utils提供了yum-config-manager工具,device-mapper-persistent-data和lvm2是设备映射存储驱动所需要的
|
说明:若无法访问国外网站,可配置国内阿里云的 docker 源
1
|
yum install wget -y
|
配置好 Docker 仓库后,运行如下命令安装最新版 Docker
1
|
# 安装最新版本的docker-ce
|
说明:若要安装指定版本的 docker,按照如下步骤
1
|
# 列出repo仓库中可用的docker版本并降序排列
|
启动 Docker 并设置开机自启
1
|
systemctl start docker
|
设置阿里云镜像加速器(可选)
1
|
mkdir -p /etc/docker
|
安装 Cephadm
说明:本节操作在所有节点进行
使用 curl 获取 cephadm 脚本的最新版本。
1
|
cd /root/
|
赋予 cephadm 脚本可执行权限
1
|
chmod +x cephadm
|
尽管 cephadm 脚本足以启动集群,但在主机上安装 cephadm 命令还是比较方便的。运行以下命令安装提供 cephadm 命令的软件包
1
|
# ./cephadm add-repo --release <ceph_version,such as octopus>
|
确认 cephadm 是否已加入 PATH 环境变量
1
|
which cephadm
|
返回如下内容表示添加成功
1
|
/usr/sbin/cephadm
|
引导一个新集群
说明:本节操作在引导节点执行
说明:创建新 Ceph 集群的第一步是在 Ceph 集群的第一台主机上运行
cephadm bootstrap命令,在 Ceph 集群的第一台主机上运行cephadm bootstrap命令会创建 Ceph 集群的第一个 “监视器(MON)守护进程”,并且该监视器守护进程需要一个 IP 地址,因此需要知道该主机的 IP 地址。如果有多个网络和接口,请确保选择一个可供任何访问 Ceph 集群的主机访问的网络和接口。
说明:关于
cephadm bootstrap的更多自定义配置可查阅关于 CEPHADM 引导的更多信息
运行 ceph bootstrap 命令
1
|
# cephadm bootstrap --mon-ip *<mon-ip>*
|
该命令执行以下操作:
- 在本地主机上为新集群创建监视器(MON)和管理器(MGR)守护进程
- 为 Ceph 集群生成新的 SSH 密钥,并将其添加到 root 用户的
/root/.ssh/authorized_keys - 将公钥的副本写入
/etc/ceph/ceph.pub - 将最小配置文件写入
/etc/ceph/ceph.conf,与新集群通信需要此文件 - 将 client.admin 管理(特权)的密钥副本写入到
/etc/ceph/ceph.client.admin.keyring - 给引导主机添加
_admin标签,默认情况下,具有此标签的主机也将获得/etc/ceph/ceph.conf和/etc/ceph/ceph.client.admin.keyring的副本
出现如下信息表示引导成功
1
|
Creating directory /etc/ceph for ceph.conf
|
根据引导完成的提示信息使用浏览器访问 Dashboard (https://ceph-mon01:8443/),修改密码后登录到 Ceph Dashboard
说明:引导提示默认通过主机名访问,需在访问的机器上配置 HOST 解析或者改为 IP 地址访问
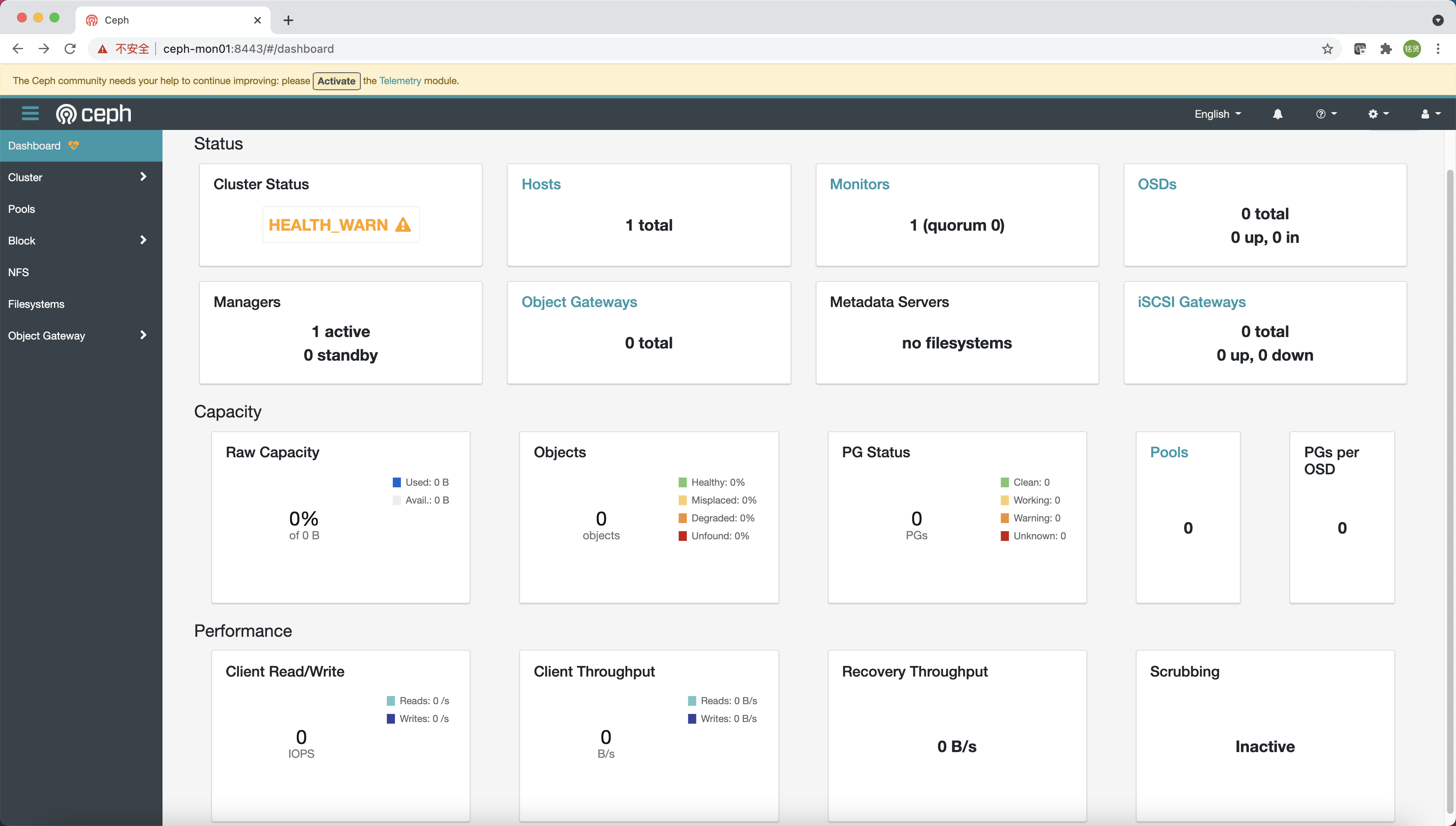
还有一个实时显示 Ceph 集群状态的 Grafana 展示页面(https://ceph-mon01:3000/)
查看当前配置文件
1
|
[root@ceph-mon01 ~]# ll /etc/ceph/
|
查看当前拉取的镜像及容器运行状态
1
|
[root@ceph-mon01 ~]# docker image ls
|
通过以上信息可知此时在引导节点上已经运行了以下组件:
mgr:Ceph 管理器(MGR)程序mon:Ceph 监视器crash:崩溃数据采集模块prometheus:prometheus 监控组件alertmanager:prometheus 告警组件node-exporter:prometheus 节点监控数据采集组件grafana:监控数据展示仪表盘 grafana
启用 Ceph 命令
说明:本节操作在所有节点进行
默认情况下 cephadm 不会在主机上安装任何 Ceph 软件包,需运行 cephadm shell 命令在安装了所有 Ceph 软件包的容器中启动 Bash Shell (运行 exit 可退出 Shell),在此特定的 Shell 中运行 Ceph 相关命令
说明:默认情况下,如果在主机上的
/etc/ceph中找到ceph.conf配置文件和ceph.client.admin.keyring文件,则会将它们传递到容器环境中,以便 Shell 能够完全正常工作。但若在 MON 主机上执行时,cephadm shell将从 MON 容器查找配置,而不是使用默认配置。
1
|
[root@ceph-mon01 ~]# cephadm shell
|
为了方便访问,我们可以在主机上安装 ceph-common 软件包,该软件包包含所有 Ceph 命令,包括 ceph、rbd、mount.ceph 等
1
|
cephadm install ceph-common
|
验证可通过本机的 Ceph 命令连接到集群
1
|
[root@ceph-mon01 ~]# ceph -v
|
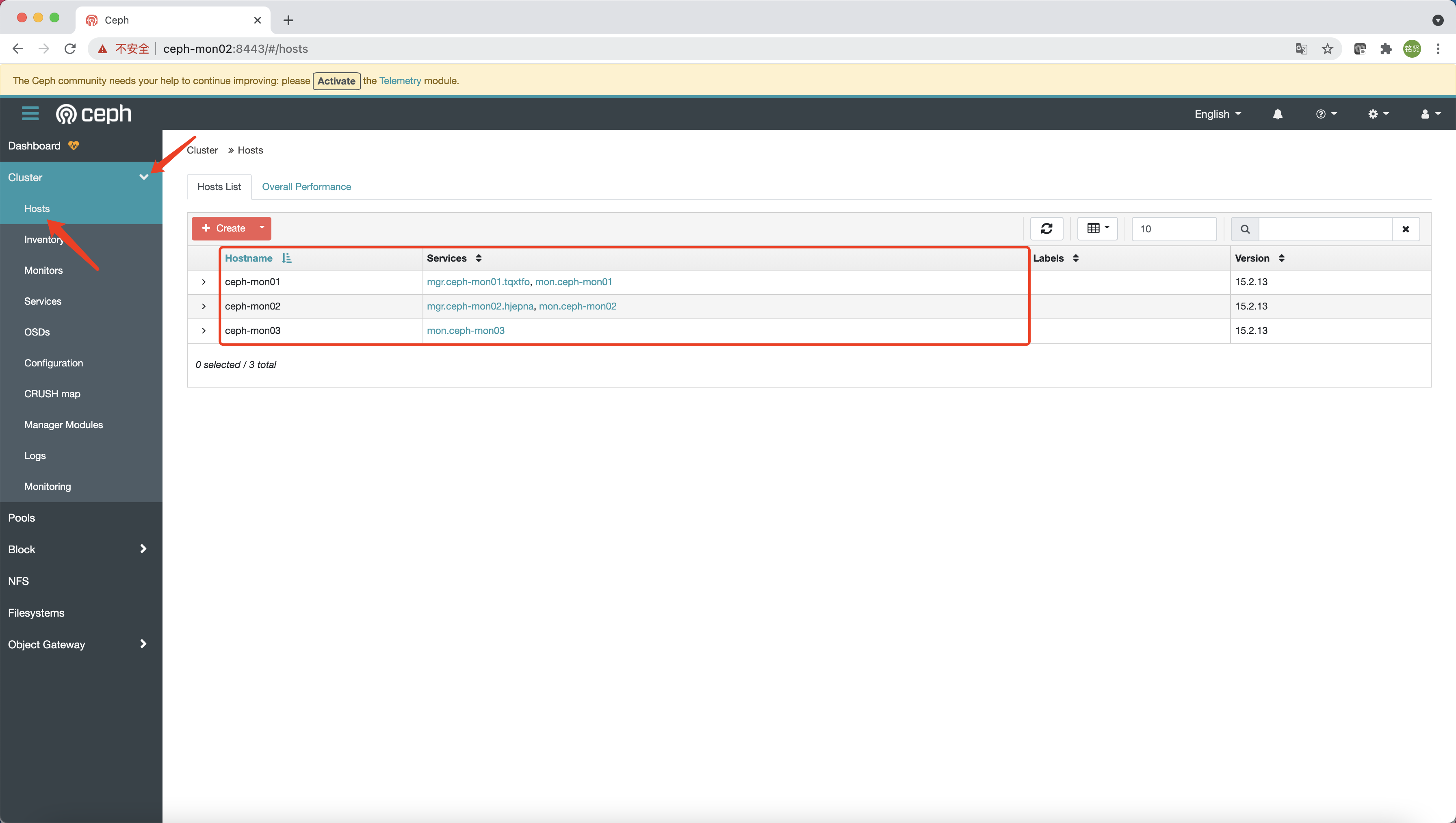
添加主机
说明:本节操作在引导节点执行
要列出当前与集群关联的主机,可运行如下命令:
1
|
ceph orch host ls
|
安装集群公钥
通过 ssh-copy-id 命令配置集群的公共 SSH 公钥至其它所有 Ceph 节点
1
|
# ssh-copy-id -f -i /etc/ceph/ceph.pub root@*<new-host>*
|
添加指定新节点
通过 ceph orch host add 命令添加新节点到 Ceph 集群中
1
|
# ceph orch host add *<newhost>* [*<ip>*] [*<label1> ...*]
|
说明:可明确提供主机 IP 地址。如果未提供 IP,则将立即通过 DNS 解析主机名,并使用该 IP。还可以包括一个或多个标签,以立即标记新主机。
1
|
# ceph orch host add *<newhost>* [*<ip>*] [*<label1> ...*]
|
验证
查看 Ceph 纳管的所有节点
1
|
[root@ceph-mon01 ~]# ceph orch host ls
|
说明:添加完成后 Ceph 会自动扩展 MON 和 MGR 到另外节点 (此过程时间可能会稍久,耐心等待),另外可用命令 (
ceph -s) 或 Ceph 的 Dashboard 页面查看添加情况
1
|
[root@ceph-mon01 ~]# ceph -s
|
部署其他 MON(可选)
说明:本节操作在引导节点执行
默认情况下,随着集群的增长,Ceph 会自动部署 MON 守护程序,而随着集群的缩小,Ceph 也会自动减少 MON 守护程序。此过程是自动的,就像在上节完成主机添加后,Ceph 立即自动扩展 MON 到另外的两台节点(最多自动添加到 5 个 MON)。如果要调整 5 个 MON 的默认值,可运行如下命令:
1
|
# ceph orch apply mon *<number-of-monitors>*
|
说明:典型的 Ceph 群集有三个或五个分布在不同主机上的 MON 守护进程。如果集群中有五个或更多节点,建议部署五个 MON。
如果要禁用 MON 的自动部署,可运行如下命令:
1
|
ceph orch apply mon --unmanaged
|
关于更多 MON 部署配置(例如指定子网部署)可参考官方文档 MON Service 章节
部署 MGR(可选)
说明:本节操作在引导节点执行
添加节点后,Ceph 会自动扩展 MGR 节点,可通过 ceph orch ls mgr 命令查看当前 MGR 数量
1
|
[root@ceph-mon01 ~]# ceph orch ls mgr
|
可以看到,默认会启动 2 个 MGR,若要查看具体运行 MGR 的节点可通过如下 ceph orch ps --daemon_type mgr 命令
1
|
[root@ceph-mon01 ~]# ceph orch ps --daemon_type mgr
|
可以看到,MGR 运行在 ceph-mon01 和 ceph-mon02 上,若想继续扩展 MGR 节点,可运行如下命令:
警告:指定的主机列表一定要包括原来的主机,有关指定守护进程位置的详细信息请见官网 Placement Specification
1
|
# ceph orch apply mgr *<host1,host2,host3,...>*
|
部署 OSD
说明:本节操作在引导节点执行
列出设备
ceph-volume 会不时扫描集群中的每个主机,以确定存在哪些设备以及这些设备是否可用做 OSD。要查看 cephadm 发现的设备列表,可运行以下命令:
1
|
# ceph orch device ls [--hostname=...] [--wide] [--refresh]
|
输出类似如下:
1
|
[root@ceph-mon01 ~]# ceph orch device ls
|
说明:使用
--wide选项提供与设备相关的所有详细信息,包括设备可能不适合用作 OSD 的任何原因
如果满足以下所有条件,则认为存储设备可用:
- 设备必须没有分区
- 设备不得具有任何 LVM 状态
- 设备必须没有被挂载
- 设备必须没有包含任何文件系统
- 设备不得包含 Ceph BlueStore OSD
- 设备必须大于 5GB
创建 OSD
有几种方式可以创建新的 OSD:
方式一(不推荐)
自动使用任何可用且未使用的存储设备
1
|
ceph orch apply osd --all-available-devices
|
运行上述命令后:
- 如果向集群中添加新硬盘,将自动用于创建新的 OSD
- 如果删除 OSD 并清理 LVM 物理卷,将自动创建新的 OSD
如果要禁用在可用设备上自动创建 OSD,可使用非托管参数
1
|
ceph orch apply osd --all-available-devices --unmanaged=true
|
方式二(推荐)
从指定的主机的指定设备创建 OSD
1
|
# ceph orch daemon add osd *<host>*:*<device-path>*
|
方式三(推荐)
可以使用高级 OSD 服务规范根据设备的属性对设备进行分类。这有助于更清楚地了解哪些设备可供消费。属性包括设备类型(SSD 或 HDD)、设备型号名称、大小以及设备所在的主机等
1
|
ceph orch apply -i spec.yml
|
检查 OSD 和集群状态
通过 ceph -s 确定 OSD 状态是否均处于 up 并 in 状态,集群状态是否为 HEALTH_OK
1
|
[root@ceph-mon01 ~]# ceph -s
|
也可通过 Dashboard 查看 OSD 和集群状态


使用 Ceph 集群提供块存储服务
说明:本节操作在引导节点执行
确认默认 pg_num 和副本数
- pg_num:根据
Total PGs = (#OSDs * 100) / pool size公式来决定pg_num(pgp_num 应该设成和 pg_num 一样),所以9*100/3=300,官方建议取最接近的 2 的指数倍数,比如 256。这是针对集群中所有 pool 的,每个 pool 的默认 pg_num 建议设置更小,比如 32 - 副本数:默认副本数建议为 3,最小副本数建议为 2
配置默认 pg_num 和副本数
动态更新配置
1
|
ceph tell mon.\* injectargs '--osd_pool_default_size=3'
|
创建块存储池
创建一个块存储池 koenli
1
|
# ceph osd pool create <poolname> <pg_num> <pgp_num>
|
创建完 pool 后再次查看集群状态,确认 pgs 均为 active+clean 状态,并且集群状态为 HEALTH_OK
1
|
[root@ceph-mon01 ~]# ceph -s
|
创建块并映射到本地
创建一个 10G 的块
1
|
# rbd create --size <size> <rbdname> --pool <poolname>
|
查看 rbd
1
|
# rbs ls <poolname> -l
|
将 rbd 块映射到本地
1
|
# rbd map <poolname>/<rbdname>
|
查看映射,可见 koenli/disk0 已经映射到本地,相当于本地的一块硬盘 /dev/rbd0,可对其进行分区、格式化、挂载等相关操作,此处不再赘述。
1
|
# rbd showmapped
|
取消映射并删除块
1
|
# rbd unmap <poolname>/<rbdname>
|
使用 Ceph 集群提供对象存储服务
说明:本节操作在引导节点执行
部署 RGW
Cephadm 将 radosgw 部署为守护进程的集合,这些守护进程管理单个集群或多站点(multisite)中的特定 realm 和 zone(有关 realm 和 zone 的更多信息可参见 Multi-Site)
说明:对于 cephadm,radosgw 守护进程是通过监视器配置数据库配置的,而不是通过 ceph.conf 或命令行配置的。如果该配置尚未就绪(通常在
client.rgw.<something>部分),那么 radosgw 守护进程将以默认设置启动(例如绑定到端口 80)。
要部署一组 radosgw 守护进程,请运行以下命令:
1
|
# 创建realm
|
说明:Pacific 版本版本创建 radosgw 守护进程的命令略有不同,需要指定一个
svc_id,可参考如下。Pacific 版本之后是否还有变化请参考官方文档
1
|
# ceph orch apply rgw <svc_id> [<realm_name>] [<zone_name>] [<port:int>] [--ssl] [<placement>] [--dry-run] [--format {plain|json|json-pretty|yaml}] [--unmanaged] [--no-overwrite]
|
通过 ceph -s 确定 RGW 是否 active,集群状态是否为 HEALTH_OK
1
|
[root@ceph-mon01 ~]# ceph -s
|
说明:如上输出所示,集群健康状态为
HEALTH_OK,不过下方的progress显示正在进行 PG 数量的调整,原因是 Ceph 在 Nautilus 版本中引入了 PG 的自动调整功能,待自动调整完成后即可。
配置 Dashboard(可选)
说明:Octopus 版本才需配置。
https://docs.ceph.com/en/octopus/mgr/dashboard/#enabling-the-object-gateway-management-frontend
由于 RGW 拥有自己的一套账号体系,所以为了能够使用 Dashboard 的对象存储网关管理功能,需要在 RGW 中创建一个 Dashboard 用的账号
1
|
# radosgw-admin user create --uid=<user_id> --display-name=<display_name> --system
|
通过如下命令导出
1
|
# radosgw-admin user info --uid=<user_id> | grep access_key | awk -F '"' '{print $4}' > /root/rgw-dashboard-access-key
|
最后将相关凭证配置到 Dashboard
1
|
# ceph dashboard set-rgw-api-access-key -i <file-containing-access-key>
|
配置完成后即可在 Dashboard 上使用对象存储网关的管理功能
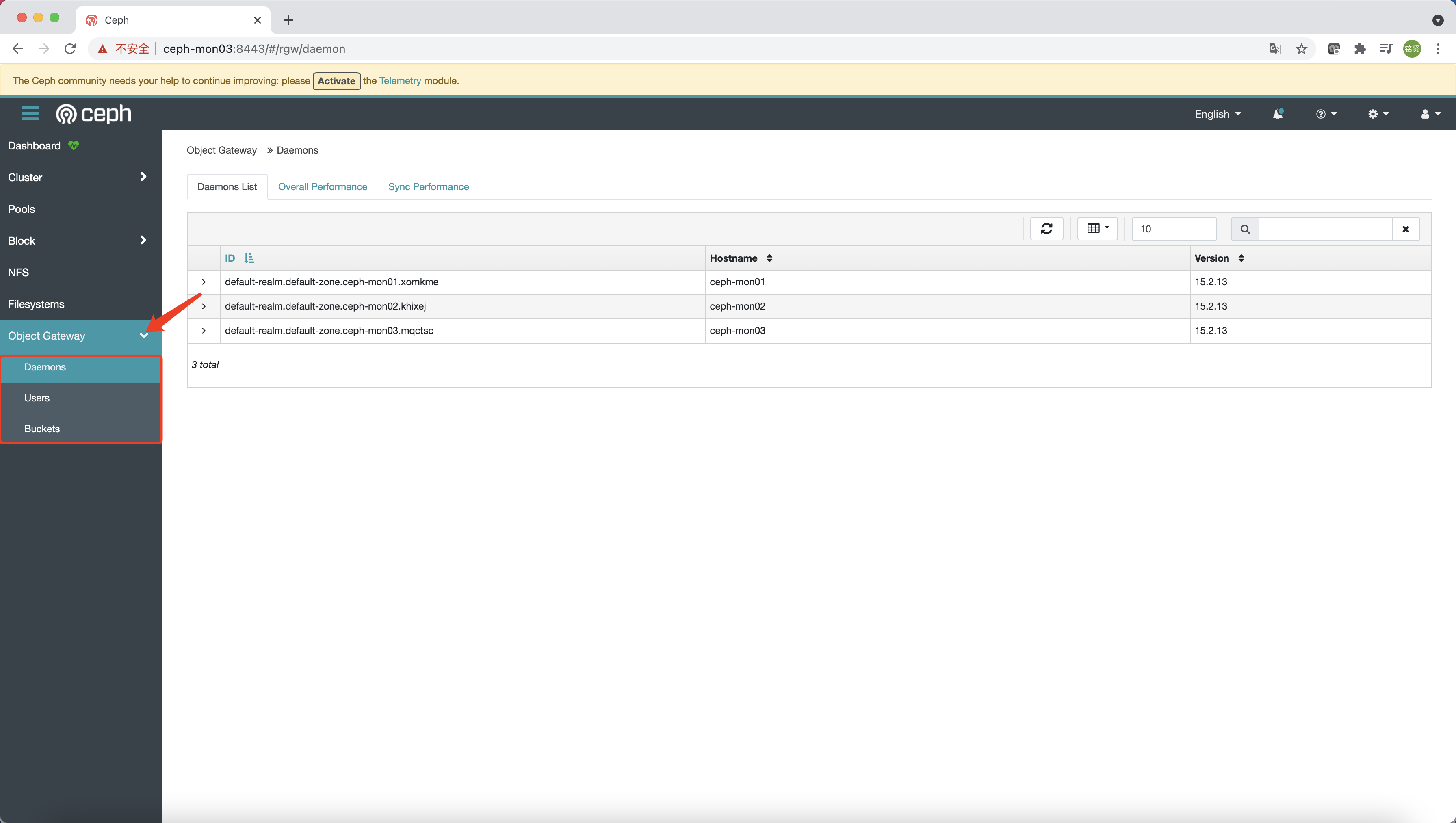
RGW 高可用
说明:在 Ceph Pacific(16.x)版本
cephadm新增了一个实现 RGW 服务高可用的功能
ingress 服务支持使用最少的一组配置为 RGW 服务创建高可用性端点(endpoint),orchestrator 将部署和管理 HAProxy 和 Keepalive 的组合,以在虚拟 IP 上为 RGW 提供负载平衡服务。
说明:如果要使用 SSL,则必须在 ingress 服务配置 SSL 而不是 RGW 本身

由上图可看到,有 N 台主机部署了 ingress 服务。每个主机都有一个 HAProxy 守护程序和一个 Keepalived 守护程序。一次只能在其中一台主机上自动配置虚拟 IP。
每个 Keepalived 守护程序每隔几秒钟检查一次同一主机上的 HAProxy 守护程序是否有响应。Keepalived 还将检查处于 MASTER 状态的 Keepalived 守护程序是否正常运行。如果处于 MASTER 状态的 Keepalived 守护程序或 HAProxy 没有响应,则在 BACKUP 模式下运行的其余 Keepalived 守护程序中的一个将被选举为 MASTER,虚拟 IP 也将移动到该节点。
HAProxy 就像负载平衡器一样,在所有可用的 RGW 守护进程之间分发所有 RGW 请求。
具体的部署请参考官方文档相关内容
使用 Ceph 集群提供文件存储服务
说明:除非特别说明,否则本节操作在引导节点执行
使用 CEPFS 文件系统需要一个或多个 MDS 守护进程。
创建文件存储池
创建两个存储池,cephfs_metadata 用于存文件系统元数据,cephfs_data 用于存文件系统数据
1
|
# ceph osd pool create <poolname> <pg_num> <pgp_num>
|
创建文件系统
1
|
# fs new <fsname> <metadata_pool> <data_pool>
|
部署 MDS
1
|
# ceph orch apply mds <fs_name> [<placement>] [--dry-run] [--unmanaged] [plain|json|
|
查看文件系统和 MDS 状态
1
|
# ceph fs ls
|
验证挂载
在要挂载的节点上安装 EPEL 软件源并配置对应版本的 Ceph 软件源
说明:如果挂载的节点为 Ceph 集群节点则跳过此步
CentOS7.x
1
|
# 安装EPEL软件源
|
CentOS8.x
1
|
# 安装EPEL软件源
|
在要挂载的节点上安装 ceph-fuse
1
|
yum install ceph-fuse -y
|
将引导节点 /etc/ceph 目录下的文件和 /var/lib/ceph/{fsid}/mon.{hostname}/config 文件拷贝到要挂载的节点上
说明:如果要挂载的节点为引导节点则忽略此步
1
|
scp -r /etc/ceph/* <client_ip>:/etc/ceph/
|
使用 ceph-fuse 命令挂载
说明:更多关于
ceph-fuse的使用说明可以参考官方文档
1
|
# ceph-fuse -n client.<username> -m <mon-ip1>:<mon-port>,<mon-ip2>:<mon-port>,<mon-ip3>:<mon-port> <mountpoint>
|
说明:若要开机自动挂载,需要在
/etc/fstab中添加如下相关条目
1
|
# none <mountpoint> fuse.ceph ceph.id=<username>,ceph.conf=<path/to/ceph.conf>,_netdev,defaults 0 0
|
卸载
1
|
# umount <mountpoint>
|
说明:若配置过开机自动挂载,还需删除
/etc/fstab中的对应挂载条目
部署 NFS ganesha 服务
说明:除非特别说明,否则本节操作在引导节点执行
说明:用户可以用 Ceph 提供的 ceph-fuse 挂载 CephFS 进行访问,也可以通过 Ceph 的内核模块进行挂载访问。但有时候,由于各种原因,一些系统无法通过这两种方法访问 CephFS,我们可以使用 NFS-ganesha 将 CephFS 通过 NFS 协议发布出去,用户可以通过 NFS 客户端挂载发布出去的 CephFS。
说明:Pacific 版本开始只支持 NFSv4
首先创建 nfs-ganesha 存储池
1
|
# ceph osd pool create <poolname> <pg_num> <pgp_num>
|
然后通过 cephadm 部署 NFS Ganesha 守护进程(或一组守护进程)。NFS 的配置存储在 nfs-ganesha 存储池中并且通过 ceph nfs export ... 命令或通过 Dashboard 仪表板管理服务暴露
说明:不同 Ceph 版本部署 NFS Ganesha 守护进程的命令可能有所差异,可查看对应版本的命令帮助说明
Octopus 版本
1
|
# ceph orch apply nfs *<svc_id>* *<pool>* *<namespace>* --placement="*<num-daemons>* [*<host1>* ...]"
|
Pacific 版本
1
|
# ceph orch apply nfs <svc_id> [<placement>] [<pool>] [<namespace>] [<port:int>] [--dry-run] [--unmanaged] [--no-overwrite]
|
检查 NFS Ganesha 守护进程状态
1
|
[root@ceph-mon01 ~]# ceph orch ls nfs
|
说明:Octopus 版本为了在 Dashboard 中启用对 NFS Ganesha 的管理,需要进行下面设置
1
|
# ceph dashboard set-ganesha-clusters-rados-pool-namespace <pool>[/<namespace>]
|
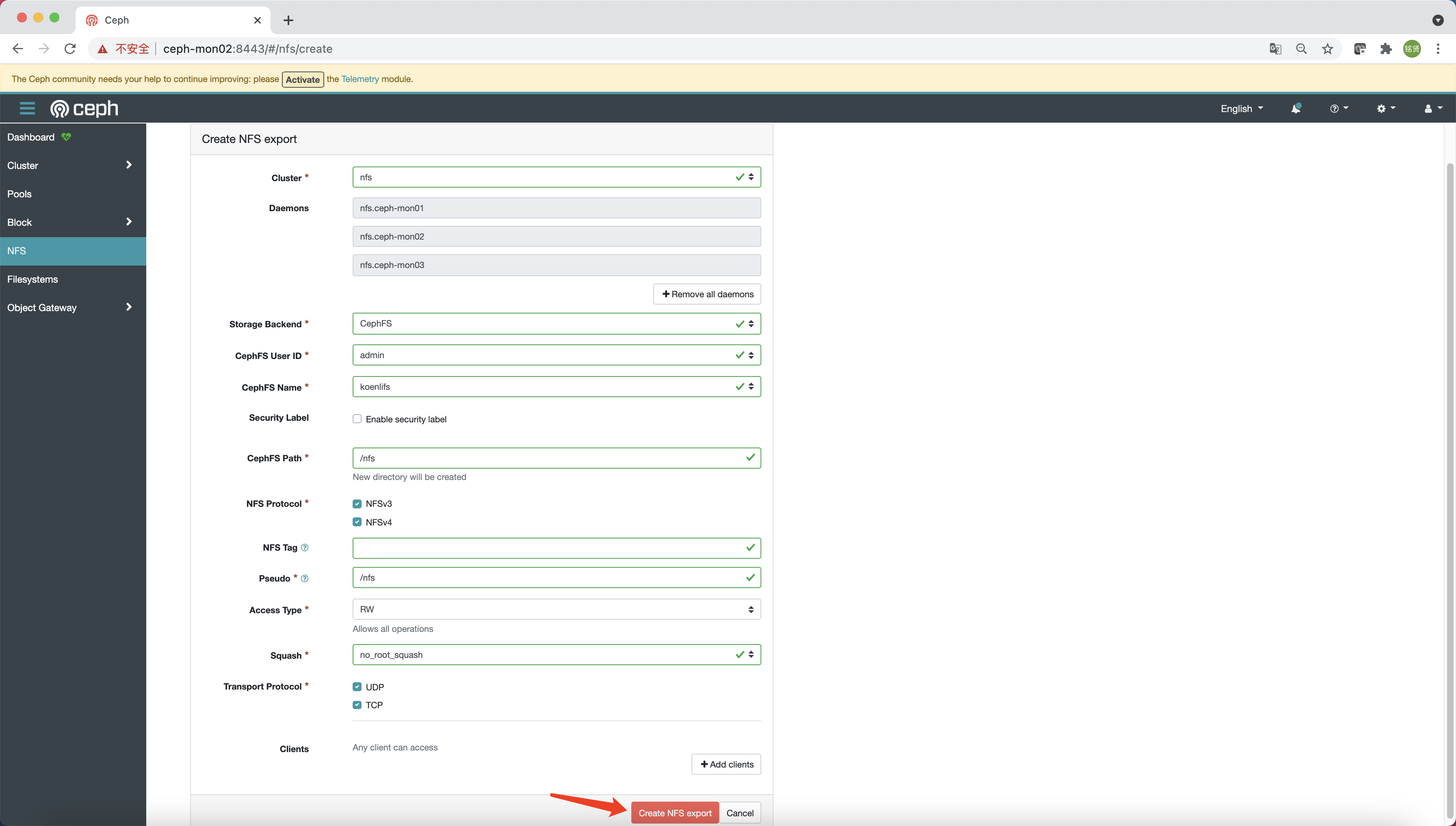
访问 Dashboard,选择 “NFS”,点击 “Create”

参考下图填写相关配置信息,最后点击 “Create NFS export”
说明:在 Pacific 版上可能会创建失败,提示没有权限创建
/nfs目录,则需先参考上面使用ceph-fuse命令挂载的步骤,在 cephfs 中创建nfs目录(目录名称与 CephFS Path 对应)后再次点击 “Create NFS export” 即可
在客户端节点验证 NFS 挂载
说明:
<daemon_ip>与创建 NFS export 时选择的 Daemons 主机 IP 匹配;<path>与创建 NFS export 时指定的 CephFS Path 对应
1
|
# 验证挂载
|
部署 iSCSI 服务
说明:本节操作在引导节点执行
创建 iSCSI 所需要的存储池
1
|
# ceph osd pool create <poolname> <pg_num> <pgp_num>
|
创建 iSCSI 的 yaml 文件
说明:更多配置请参考官方文档
1
|
cat > /root/iscsi.yaml << EOF
|
部署 iSCSI
1
|
ceph orch apply -i /root/iscsi.yaml
|
查看 iSCSI service 和 daemon 状态
1
|
[root@ceph-mon01 ~]# ceph orch ls iscsi
|
查看 Ceph Dashboard 状态

如何剔除 OSD
从集群中剔除 OSD 包括两个步骤:
- 从集群中撤出此 OSD 上所有的 PG
- 从集群中卸载无 PG 的 OSD
以下命令执行这两个步骤:
1
|
# ceph orch osd rm <osd_id(s)> [--replace] [--force]
|
可以使用 ceph orch osd rm status 命令查询 OSD 操作的状态
Troubleshooting
无法 rbd 映射到本地
问题现象
将 rbd 映射到本地时出现如下错误信息:
1
|
rbd: sysfs write failed
|
解决方法
因为 CentOS7 默认内核版本不支持 Ceph 的一些特性,需要手动禁用掉才能 map 成功
1
|
rbd feature disable koenli/disk01 object-map fast-diff deep-flatten
|
-------------------------------------------
个性签名:独学而无友,则孤陋而寡闻。做一个灵魂有趣的人!
如果觉得这篇文章对你有小小的帮助的话,记得在右下角点个“推荐”哦,在此感谢!


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· TypeScript + Deepseek 打造卜卦网站:技术与玄学的结合
· Manus的开源复刻OpenManus初探
· AI 智能体引爆开源社区「GitHub 热点速览」
· 从HTTP原因短语缺失研究HTTP/2和HTTP/3的设计差异
· 三行代码完成国际化适配,妙~啊~