
[转]storm的八种Grouping策略
在这里,将会提到storm的七种grouping策略,并且编码逐一实现。
首先,需要一个集群(希望尽量模仿真实环境,故就不用本地模式了)。
OK。现在有三个节点。一个作为nimbus,两个作为supervisor。到这里先介绍一下storm逻辑上有两个component,一个是Spout,另一个是Bolt。stream由Spout发出,在不同的Bolt之间进行处理,在其中传递的是storm的基本处理单位:Tuple。由Spout发出一个一个Tuple,然后Bolt接收Tuple进行各种各样的处理。这一整个过程构成一个DAG。在storm里面叫做Topology。当使用远程模式向集群提交一个Topology之后,如果不kill掉的话,将会一直运行到。。。我也不知道尽头。。貌似没有尽头。
好了,来看一个简单的Topology。将使用这个Topology来实现那几种Grouping策略。
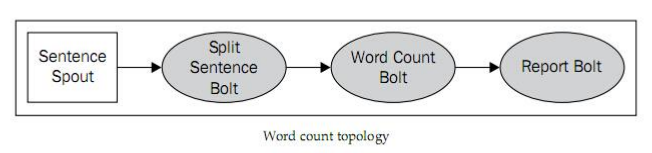
上图中spout的处理逻辑是将一句话发出给下一个Bolt,然后下一个Bolt做句子的单词分割,下一个做计数,最后的Bolt做汇总显示。这里可以有多个Bolt或者Spout进行并行处理。这是关于并行度的设置。
好了,所谓的grouping策略就是在Spout与Bolt、Bolt与Bolt之间传递Tuple的方式。总共有七种方式:
1)shuffleGrouping(随机分组)
2)fieldsGrouping(按照字段分组,在这里即是同一个单词只能发送给一个Bolt)
3)allGrouping(广播发送,即每一个Tuple,每一个Bolt都会收到)
4)globalGrouping(全局分组,将Tuple分配到task id值最低的task里面)
5)noneGrouping(随机分派)
6)directGrouping(直接分组,指定Tuple与Bolt的对应发送关系)
7)Local or shuffle Grouping
8)customGrouping (自定义的Grouping)
OK,下面逐个来试试!
首先是使用shuffleGrouping策略。

启动后所得的结果。
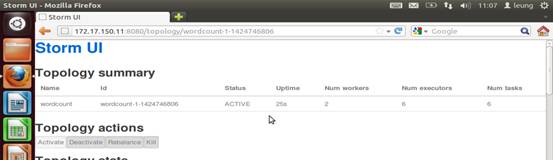
可以看到如storm这个单词被随机分配到了两个counter里面,分别是h2和h3两个节点里面。可再做一次提交,又会看到不一样的结果。将与下面的fieldGrouping形成对比。
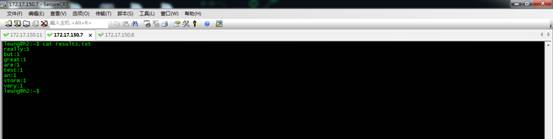
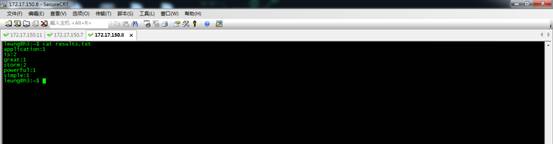
然后换成fieldsGrouping。
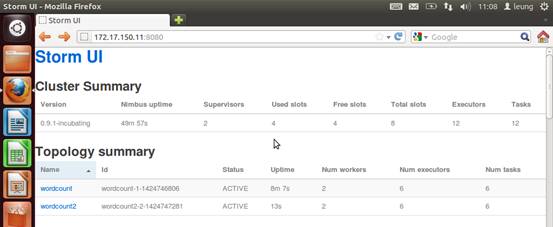
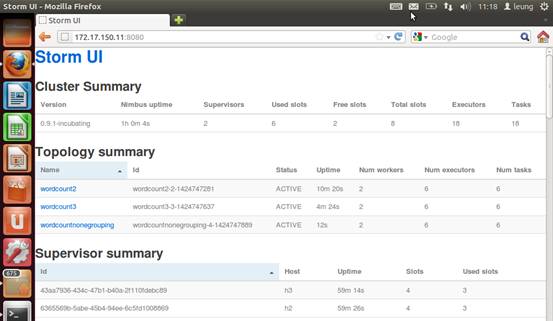
启动后的结果如图。图中wordcount2和wordcount3就是我两次提交的topology的名字。

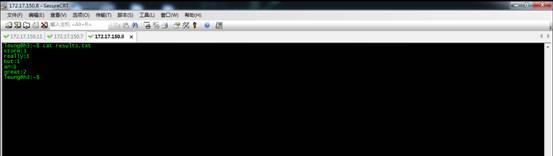
下面是两次提交的结果。可以看出,使用fieldsGrouping策略,被分配到每个wordcounterbolt的单词没有变化。
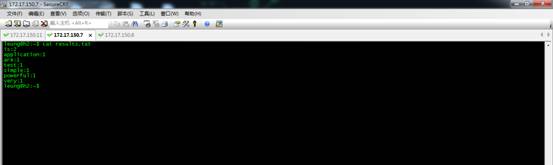
下面是第二次提交的结果。
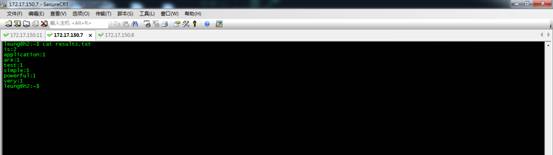
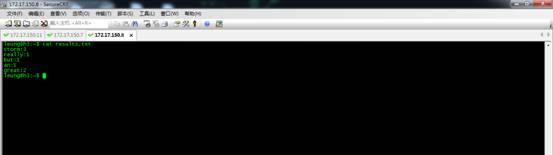
再换成noneGrouping策略。
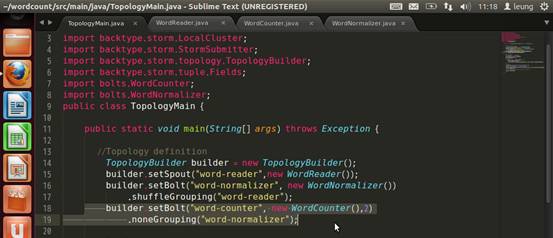
提交集群运行。
运行结果如图。noneGrouping和shuffleGrouping是基本一样的。都是随机的。

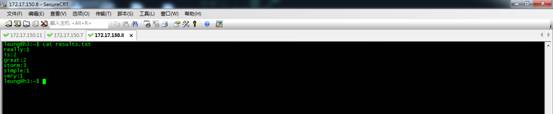
替换成allGrouping策略。
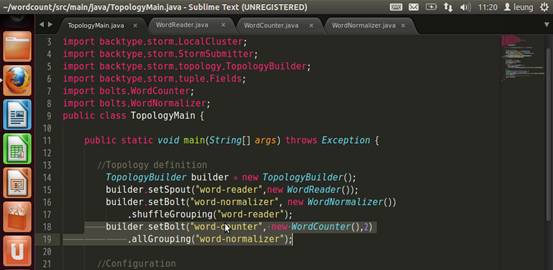
提交集群运行。
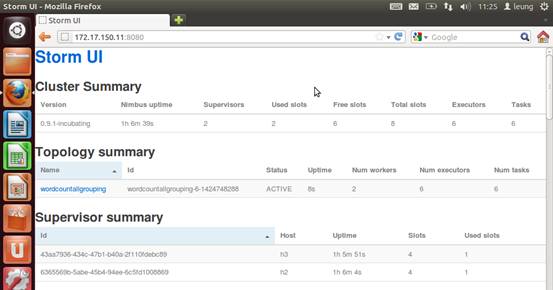
运行结果如图。可以看到。两个bolt所接收到的单词是一样的,都是全部的单词。

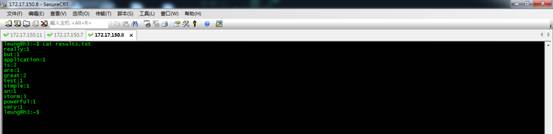
最后,替换成globalGrouping策略。
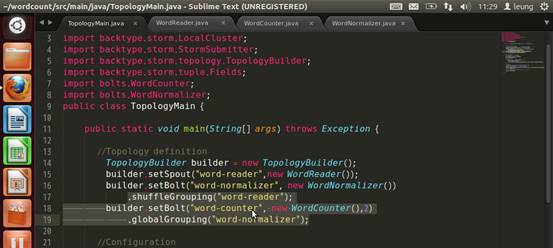
提交集群运行。
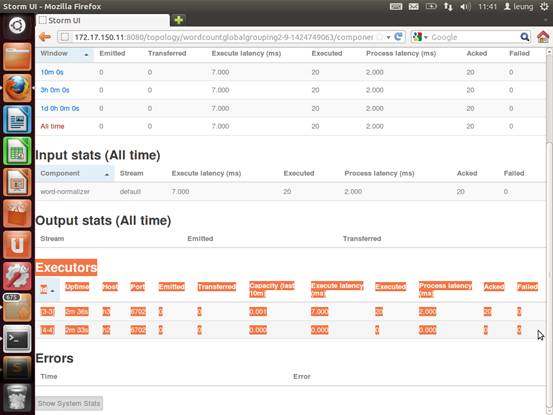
从上图可以看到,主要分配到了h3这个节点。从下面的结果得以验证。
-------------------------------------------
个性签名:独学而无友,则孤陋而寡闻。做一个灵魂有趣的人!
如果觉得这篇文章对你有小小的帮助的话,记得在右下角点个“推荐”哦,在此感谢!

