
Hive去除重复数据操作
Hive是基于Hadoop的一个数据仓库工具,可以将结构化的数据文件映射为一张数据库表,并提供类SQL查询功能
hive的元数据存储:通常是存储在关系数据库如 mysql(推荐) , derby(内嵌数据库)中
hive的组成部分 :解释器、编译器、优化器、执行器
hive具有sql数据库的外表,但应用场景完全不同,hive只适合用来做批量数据统计分析
hive中的数据表分为内部表、外部表
当删除内部表的时候,表中的数据会跟着一块删除
删除外部表时候,外部表会被删除,外部表的数据不会被删除
使用hive之前需要启动hadoop集群,因为hive需要依赖于hadoop集群进行工作(hive2.0之前)
以下是对hive重复数据处理
先创建一张测试表
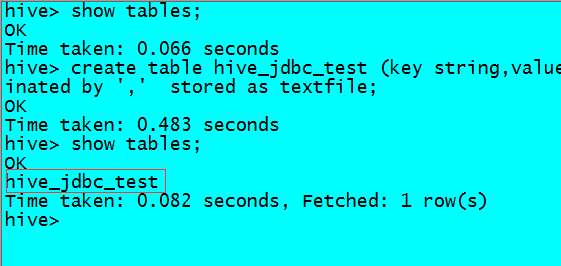
建表语句:create table hive_jdbc_test (key string,value string) partitioned by (day string) row format delimited fields terminated by ',' stored as textfile
准备的数据
uuid,hello=>0
uuid,hello=>0
uuid,hello=>1
uuid,hello=>1
uuid,hello=>2
uuid,hello=>2
uuid,hello=>3
把数据插入到2018-1-1分区
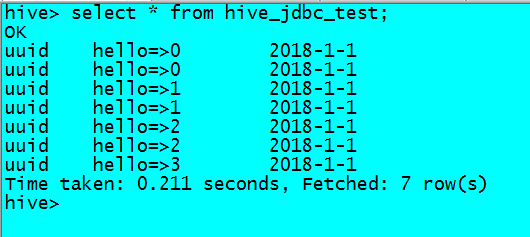
此时我们对hive表数据进行去重操作
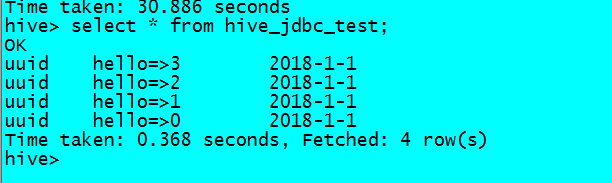
insert overwrite table hive_jdbc_test partition(day='2018-1-1')
select key,value
from (SELECT *, Row_Number() OVER (partition by key,value ORDER BY value desc) rank
FROM hive_jdbc_test where day='2018-1-1') t
where t.rank=1;

此时重复数据会被处理完毕
-------------------------------------------
个性签名:独学而无友,则孤陋而寡闻。做一个灵魂有趣的人!
如果觉得这篇文章对你有小小的帮助的话,记得在右下角点个“推荐”哦,在此感谢!


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 从 HTTP 原因短语缺失研究 HTTP/2 和 HTTP/3 的设计差异
· AI与.NET技术实操系列:向量存储与相似性搜索在 .NET 中的实现
· 基于Microsoft.Extensions.AI核心库实现RAG应用
· Linux系列:如何用heaptrack跟踪.NET程序的非托管内存泄露
· 开发者必知的日志记录最佳实践
· TypeScript + Deepseek 打造卜卦网站:技术与玄学的结合
· Manus的开源复刻OpenManus初探
· AI 智能体引爆开源社区「GitHub 热点速览」
· 从HTTP原因短语缺失研究HTTP/2和HTTP/3的设计差异
· 三行代码完成国际化适配,妙~啊~