
Spark Streaming中的基本操作函数实例
官网文档中,大概可分为这几个
Transformations
Window Operations
Join Operations
Output Operations
请了解一些基本信息:
DStream是Spark Streaming提供的基本抽象。它表示连续的数据流,可以是从源接收的输入数据流,也可以是通过转换输入流生成的已处理数据流。在内部,DStream由一系列连续的RDD表示,这是Spark对不可变分布式数据集的抽象。DStream中的每个RDD都包含来自特定时间间隔的数据。


Transformations 直达车
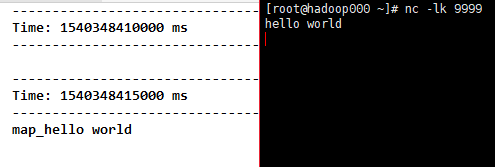
1)map(func),将func函数作用到每一个元素上并生成一个新的元素,得到一个新的的DStream对象,包含这些新的元素。
代码
object Map {
def main(args: Array[String]): Unit = {
val sparkConf = new SparkConf().setMaster("local[2]").setAppName("NetworkWordCount")
val ssc = new StreamingContext(sparkConf, Seconds(5))
ssc.sparkContext.setLogLevel("ERROR")
val lines = ssc.socketTextStream("192.168.31.30", 9999)
val mapLines = lines.map(word => "map_" + word)
mapLines.print()
ssc.start()
ssc.awaitTermination()
}
} 

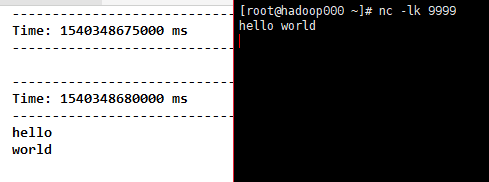
2)flatMap(func),将func函数作用到每一个元素上并生成0个或多个新的元素(例如下面的split就生成了>=0个新元素),得到一个新的DStream对象。包含这些新的元素。
代码
object FlatMap {
def main(args: Array[String]): Unit = {
val sparkConf = new SparkConf().setMaster("local[2]").setAppName("NetworkWordCount")
val ssc = new StreamingContext(sparkConf, Seconds(5))
ssc.sparkContext.setLogLevel("ERROR")
val lines = ssc.socketTextStream("192.168.31.30", 9999)
val fmapLines = lines.flatMap(_.split(" "))
fmapLines.print()
ssc.start()
ssc.awaitTermination()
}
} 

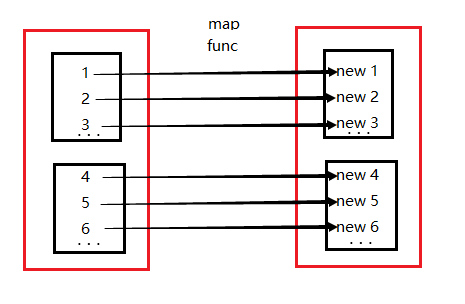
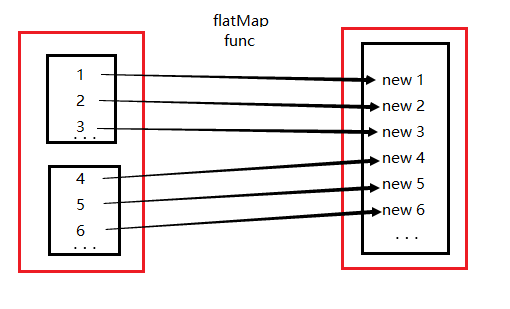
ps:Spark操作-map和flatMap,map的作用很容易理解就是对rdd之中的元素进行逐一进行函数操作映射为另外一个rdd。flatMap的操作是将函数应用于rdd之中的每一个元素,将返回的迭代器的所有内容构成新的rdd。通常用来切分单词。


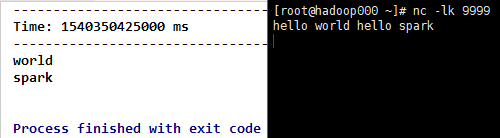
3)filter(func),对DStream每一个元素,应用func方法进行计算,如果func函数返回结果为true,则保留该元素,否则丢弃该元素,返回一个新的DStream。
代码
object Filter {
def main(args: Array[String]): Unit = {
val sparkConf = new SparkConf().setMaster("local[2]").setAppName("NetworkWordCount")
val ssc = new StreamingContext(sparkConf, Seconds(5))
ssc.sparkContext.setLogLevel("ERROR")
val lines = ssc.socketTextStream("192.168.31.30", 9999)
val filterLines = lines.flatMap(_.split(" "))
.filter(!StringUtils.equals(_, "hello"))
filterLines.print()
ssc.start()
ssc.awaitTermination()
}
} 

4)repartition(numPartitions),可自行操作
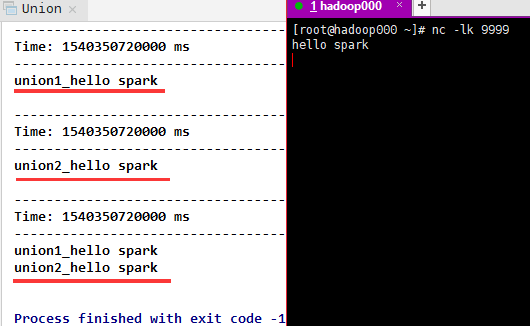
5)union(otherStream),返回一个新的DStream,它包含源DStream和otherDStream中元素的并集。
代码
def main(args: Array[String]): Unit = {
val sparkConf = new SparkConf().setMaster("local[2]").setAppName("NetworkWordCount")
val ssc = new StreamingContext(sparkConf, Seconds(5))
ssc.sparkContext.setLogLevel("ERROR")
val lines = ssc.socketTextStream("192.168.31.30", 9999)
val union1 = lines.map(word => "union1_" + word)
val union2 = lines.map(word => "union2_" + word)
val union1_2 = union1.union(union2)
union1.print()
union2.print()
union1_2.print()
ssc.start()
ssc.awaitTermination()
} 

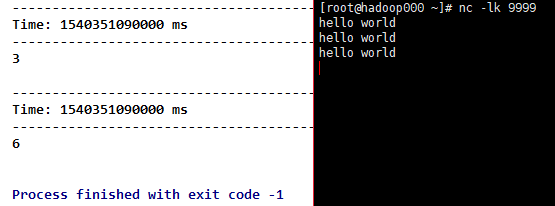
6)count(),通过计算源DStream的每个RDD中的元素数量,返回单个元素RDD的新DStream。
代码
object Count {
def main(args: Array[String]): Unit = {
val sparkConf = new SparkConf().setMaster("local[2]").setAppName("NetworkWordCount")
val ssc = new StreamingContext(sparkConf, Seconds(5))
ssc.sparkContext.setLogLevel("ERROR")
val lines = ssc.socketTextStream("192.168.31.30", 9999)
val mapLines = lines.map(_.split(" "))
val fmapLines = lines.flatMap(_.split(" "))
mapLines.count().print()
fmapLines.count().print()
ssc.start()
ssc.awaitTermination()
}
} 

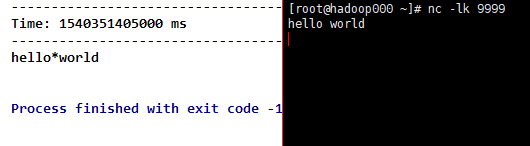
7)reduce(func),通过使用函数func(它接受两个参数并返回一个),其中两个参数(元素)两两计算,返回单个元素RDD的新DStream 。
代码
object Reduce {
def main(args: Array[String]): Unit = {
val sparkConf = new SparkConf().setMaster("local[2]").setAppName("NetworkWordCount")
val ssc = new StreamingContext(sparkConf, Seconds(5))
ssc.sparkContext.setLogLevel("ERROR")
val lines = ssc.socketTextStream("192.168.31.30", 9999)
val fmapLines = lines.flatMap(_.split(" "))
val result = fmapLines.reduce(_ + "*" + _)
//fmapLines.reduce((a, b) => a + "*" + b)
result.print()
ssc.start()
ssc.awaitTermination()
}
} 

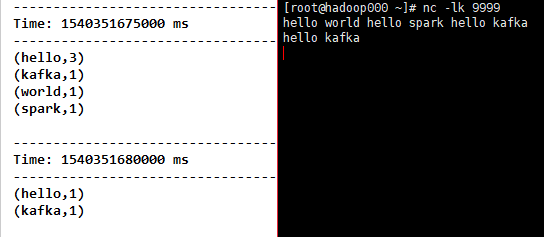
8)countByValue(),当在类型为K的DStream元素上调用时,返回新DStream的元素是(K,Long)对,其中每个键的值(Long)是其在源DStream的每个RDD中的频率。
代码
object countByValue {
def main(args: Array[String]): Unit = {
val sparkConf = new SparkConf().setMaster("local[2]").setAppName("NetworkWordCount")
val ssc = new StreamingContext(sparkConf, Seconds(5))
ssc.sparkContext.setLogLevel("ERROR")
val lines = ssc.socketTextStream("192.168.31.30", 9999)
val fmapLines = lines.flatMap(_.split(" "))
val countByKey = fmapLines.countByValue()
countByKey.print()
ssc.start()
ssc.awaitTermination()
}
} 

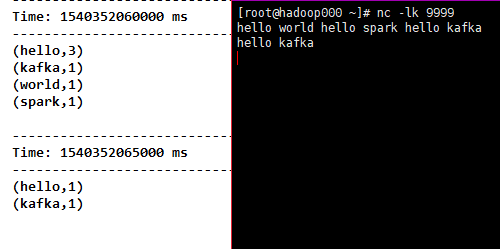
9)reduceByKey(func, [numTasks]),当在类型为(K,V)的DStream元素上调用时,返回(K,V)对的新DStream,其中K为原来的K,V是由K经过传入func计算得到的。
注意:默认情况下,这使用Spark的默认并行任务数(local模式下默认为2,在群集模式下,数量由config属性确定spark.default.parallelism)进行分组。
代码
object ReduceByKey {
def main(args: Array[String]): Unit = {
val sparkConf = new SparkConf().setMaster("local[2]").setAppName("NetworkWordCount")
val ssc = new StreamingContext(sparkConf, Seconds(5))
ssc.sparkContext.setLogLevel("ERROR")
val lines = ssc.socketTextStream("192.168.31.30", 9999)
val fmapLines = lines.flatMap(_.split(" "))
val tuple = fmapLines.map(word => (word, 1))
val reduceByKey = tuple.reduceByKey(_ + _)
reduceByKey.print()
ssc.start()
ssc.awaitTermination()
}
} 

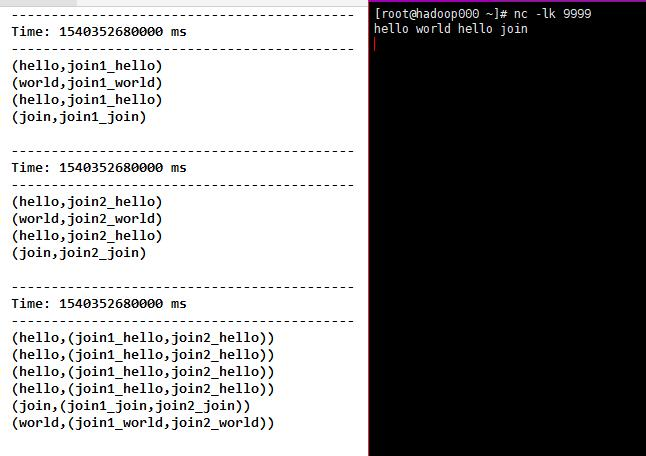
10)join(otherStream, [numTasks]),当在(K,V)和(K,W)对的两个DStream上调用时,返回新的DStream内容是(K,(V,W))对。numTasks并行度,可选
代码
object Join {
def main(args: Array[String]): Unit = {
val sparkConf = new SparkConf().setMaster("local[2]").setAppName("NetworkWordCount")
val ssc = new StreamingContext(sparkConf, Seconds(5))
ssc.sparkContext.setLogLevel("ERROR")
val lines = ssc.socketTextStream("192.168.31.30", 9999)
val words = lines.flatMap(_.split(" "))
val join1 = words.map(word => (word, "join1_" + word))
val join2 = words.map(word => (word, "join2_" + word))
val join1_2 = join1.join(join2)
join1.print()
join2.print()
join1_2.print()
ssc.start()
ssc.awaitTermination()
}
} 

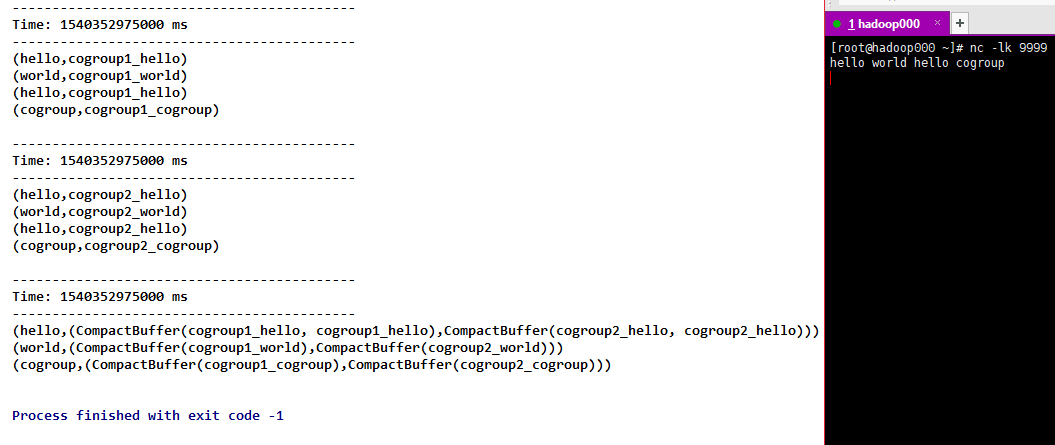
11)cogroup(otherStream, [numTasks]),当在(K,V)和(K,W)对的DStream上调用时,返回(K,Seq [V],Seq [W])元组的新DStream。numTasks并行度,可选
代码
object Cogroup {
def main(args: Array[String]): Unit = {
val sparkConf = new SparkConf().setMaster("local[2]").setAppName("NetworkWordCount")
val ssc = new StreamingContext(sparkConf, Seconds(5))
ssc.sparkContext.setLogLevel("ERROR")
val lines = ssc.socketTextStream("192.168.31.30", 9999)
val words = lines.flatMap(_.split(" "))
val cogroup1 = words.map(word => (word, "cogroup1_" + word))
val cogroup2 = words.map(word => (word, "cogroup2_" + word))
val cogroup1_2 = cogroup1.cogroup(cogroup2)
cogroup1.print()
cogroup2.print()
cogroup1_2.print()
ssc.start()
ssc.awaitTermination()
}
} 

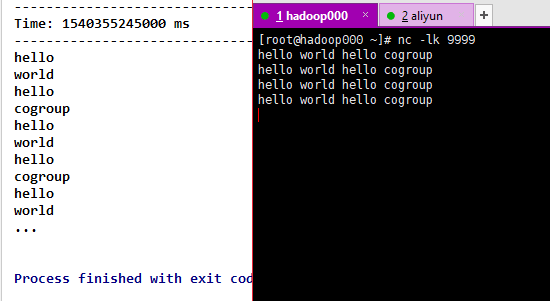
12)transform(func) 直达车,通过将RDD-to-RDD函数应用于源DStream的每个RDD来返回新的DStream。这可以用于在DStream上执行任意RDD操作。
代码
object Transform {
def main(args: Array[String]): Unit = {
val sparkConf = new SparkConf().setMaster("local[2]").setAppName("NetworkWordCount")
val ssc = new StreamingContext(sparkConf, Seconds(5))
ssc.sparkContext.setLogLevel("ERROR")
val lines = ssc.socketTextStream("192.168.31.30", 9999)
val words = lines.transform(rdd=>{
rdd.flatMap(_.split(" "))
})
words.print()
ssc.start()
ssc.awaitTermination()
}
} 
![]()
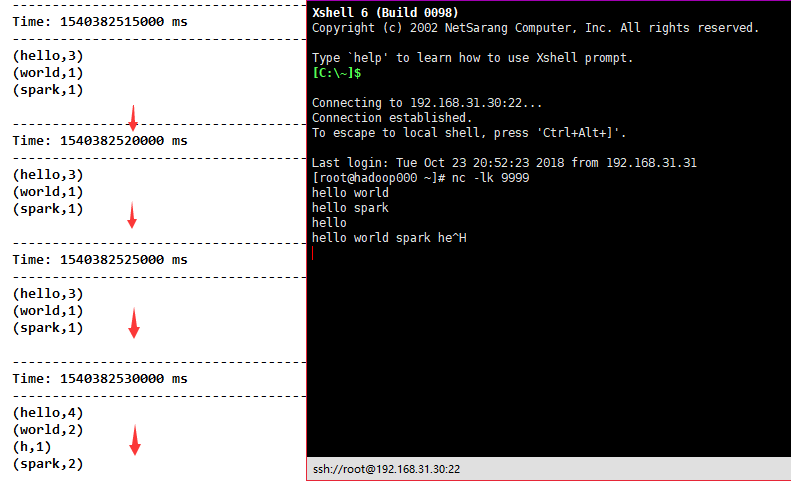
13)updateStateByKey(func)直达车,返回一个新的“状态”DStream,其中通过在键的先前状态和键的新值上应用给定函数来更新每个键的状态。这可用于维护每个密钥的任意状态数据。
代码
object UpdateStateByKey {
def main(args: Array[String]): Unit = {
val sparkConf = new SparkConf().setMaster("local[2]").setAppName("FileWordCount")
val ssc = new StreamingContext(sparkConf, Seconds(5))
ssc.sparkContext.setLogLevel("ERROR")
//请注意,使用updateStateByKey需要配置检查点目录
ssc.checkpoint("D:\\spark\\checkpoint")
val lines = ssc.socketTextStream("192.168.31.30", 9999)
val result = lines.flatMap(_.split(" ")).map((_, 1)).reduceByKey(_ + _)
val state = result.updateStateByKey[Int](updateFunction _)
state.print()
ssc.start()
ssc.awaitTermination()
}
/**
* 更新数据
* @param newValues
* @param runningCount
* @return
*/
def updateFunction(newValues: Seq[Int], runningCount: Option[Int]): Option[Int] = {
val current = newValues.sum
val pre = runningCount.getOrElse(0)
Some(current + pre)
}
} 


Window Operations 直达车
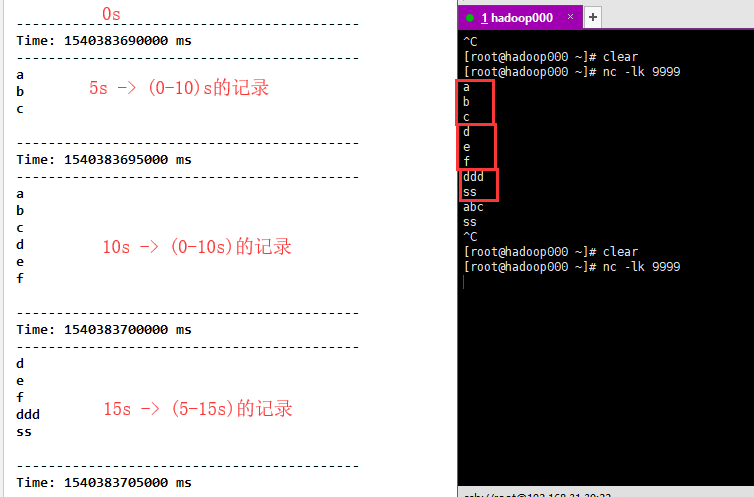
window:定时的进行一段时间内数据的操作
window length:窗口的长度
sliding interval:窗口的间隔
这两个参数和batch size是倍数关系,不是的话会报错
1)window(windowLength, slideInterval),将当前时刻当前长度窗口中的元素取出形成一个新的DStream。
代码
object Window {
def main(args: Array[String]): Unit = {
val sparkConf = new SparkConf().setMaster("local[2]").setAppName("NetworkWordCount")
val ssc = new StreamingContext(sparkConf, Seconds(5))
ssc.sparkContext.setLogLevel("ERROR")
val lines = ssc.socketTextStream("192.168.31.30", 9999)
val fmapLines = lines.flatMap(_.split(" "))
//每隔5秒去计算前10秒的结果
val window = fmapLines.window(Seconds(10), Seconds(5))
window.print()
ssc.start()
ssc.awaitTermination()
}
} 

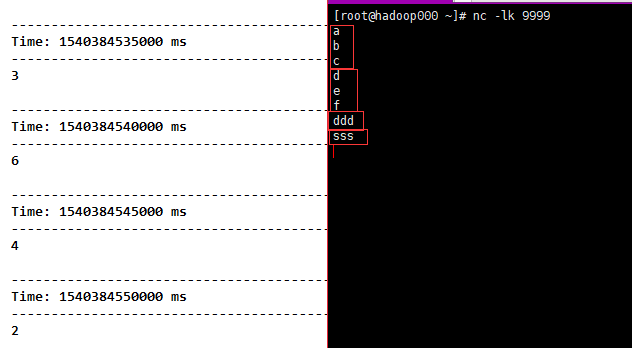
2)countByWindow(windowLength, slideInterval),和count类似,只不过Dstream是我们截取的。
代码
object CountByWindow {
def main(args: Array[String]): Unit = {
val sparkConf = new SparkConf().setMaster("local[2]").setAppName("NetworkWordCount")
val ssc = new StreamingContext(sparkConf, Seconds(5))
ssc.checkpoint("D:\\spark\\checkpoint")
ssc.sparkContext.setLogLevel("ERROR")
val lines = ssc.socketTextStream("192.168.31.30", 9999)
val fmapLines = lines.flatMap(_.split(" "))
//每隔5s统计当前10秒长度的时间窗口的DStream中元素的个数:
val countByWindow = fmapLines.countByWindow(Seconds(10), Seconds(5))
countByWindow.print()
ssc.start()
ssc.awaitTermination()
}
} 

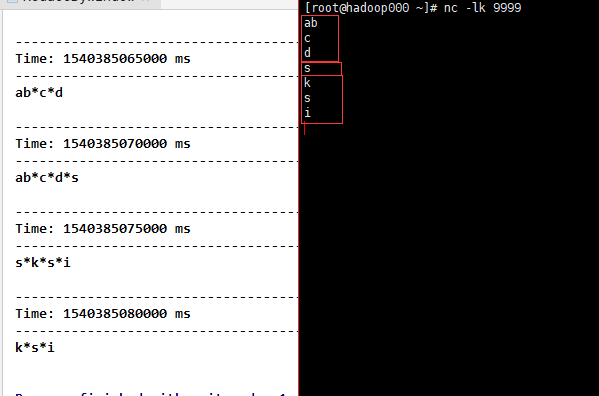
3)reduceByWindow(func, windowLength, slideInterval),和reduce类似,只不过Dstream是我们截取的。
代码
object ReduceByWindow {
def main(args: Array[String]): Unit = {
val sparkConf = new SparkConf().setMaster("local[2]").setAppName("NetworkWordCount")
val ssc = new StreamingContext(sparkConf, Seconds(5))
ssc.checkpoint("D:\\spark\\checkpoint")
ssc.sparkContext.setLogLevel("ERROR")
val lines = ssc.socketTextStream("192.168.31.30", 9999)
val fmapLines = lines.flatMap(_.split(" "))
val reduceByWindow = fmapLines.reduceByWindow(_ + "*" + _, Seconds(10), Seconds(5))
reduceByWindow.print()
ssc.start()
ssc.awaitTermination()
}
} 

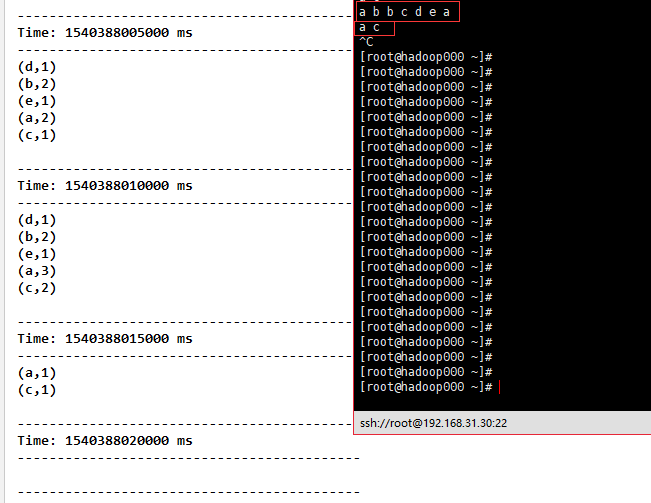
4)reduceByKeyAndWindow(func, windowLength, slideInterval, [numTasks]) 直达车,和reduceByKey类似,只不过Dstream是我们截取的。
代码
object ReduceByKeyAndWindow {
def main(args: Array[String]): Unit = {
val sparkConf = new SparkConf().setMaster("local[2]").setAppName("NetworkWordCount")
val ssc = new StreamingContext(sparkConf, Seconds(5))
ssc.checkpoint("D:\\spark\\checkpoint")
ssc.sparkContext.setLogLevel("ERROR")
val lines = ssc.socketTextStream("192.168.31.30", 9999)
val fmapLines = lines.flatMap(_.split(" "))
val tuple = fmapLines.map(word => (word, 1))
val reduceByKeyAndWindow = tuple.reduceByKeyAndWindow((a:Int,b:Int) => (a + b),Seconds(10),Seconds(5))
reduceByKeyAndWindow.print()
ssc.start()
ssc.awaitTermination()
}
} 

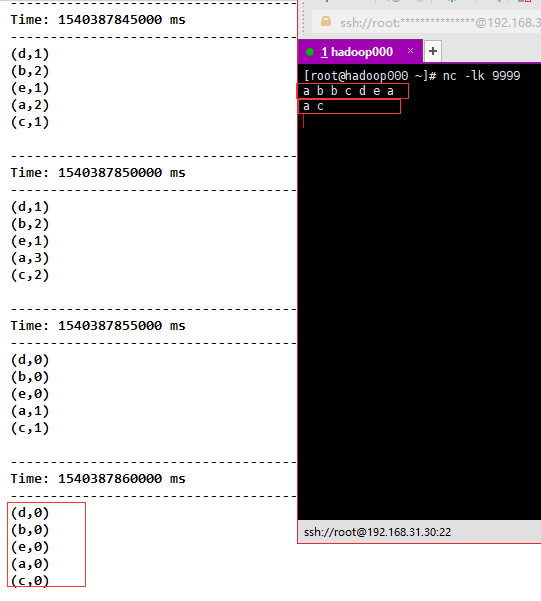
5)reduceByKeyAndWindow(func, invFunc, windowLength, slideInterval, [numTasks]),和上面相比,多传入一个函数invFunc。向车站一样,有进去的人,也有出去的人,进去的人+1,出来的人-1。
代码
object ReduceByKeyAndWindow2 {
def main(args: Array[String]): Unit = {
val sparkConf = new SparkConf().setMaster("local[2]").setAppName("NetworkWordCount")
val ssc = new StreamingContext(sparkConf, Seconds(5))
ssc.checkpoint("D:\\spark\\checkpoint")
ssc.sparkContext.setLogLevel("ERROR")
val lines = ssc.socketTextStream("192.168.31.30", 9999)
val fmapLines = lines.flatMap(_.split(" "))
val tuple = fmapLines.map(word => (word, 1))
val reduceByKeyAndWindow = tuple.reduceByKeyAndWindow((a: Int, b: Int) => (a + b), (a: Int, b: Int) => (a - b), Seconds(10), Seconds(5))
reduceByKeyAndWindow.print()
ssc.start()
ssc.awaitTermination()
}
} 

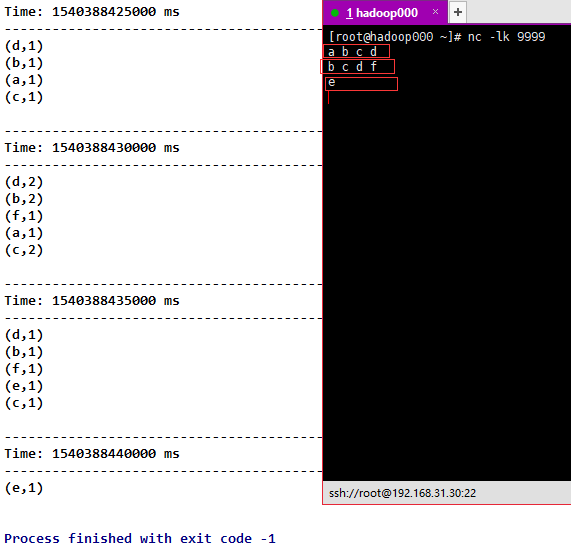
6)countByValueAndWindow(windowLength,slideInterval, [numTasks]),和countByValue类似,只不过Dstream是我们截取的。
代码
object CountByValueAndWindow {
def main(args: Array[String]): Unit = {
val sparkConf = new SparkConf().setMaster("local[2]").setAppName("NetworkWordCount")
val ssc = new StreamingContext(sparkConf, Seconds(5))
ssc.checkpoint("D:\\spark\\checkpoint")
ssc.sparkContext.setLogLevel("ERROR")
val lines = ssc.socketTextStream("192.168.31.30", 9999)
val fmapLines = lines.flatMap(_.split(" "))
val countByValueAndWindow = fmapLines.countByValueAndWindow(Seconds(10), Seconds(5))
countByValueAndWindow.print()
ssc.start()
ssc.awaitTermination()
}
} 

Join Operations 直达车
1)Stream-stream joins 直达车
调用 join,leftOuterJoin,rightOuterJoin,fullOuterJoin就ok了
2)Stream-dataset joins 直达车
val dataset: RDD[String, String] = ...
val windowedStream = stream.window(Seconds(20))...
val joinedStream = windowedStream.transform { rdd => rdd.join(dataset) }我们调用transform后就可以和dataset 连接操作了
Output Operations 直达车
| 输出操作 | 含义 |
|---|---|
| print() | 在运行流应用程序的驱动程序节点上打印DStream中每批数据的前十个元素。这对开发和调试很有用。 |
| saveAsTextFiles(prefix, [suffix]) | 将此DStream的内容保存为文本文件。每个批处理间隔的文件名基于前缀和后缀生成:“prefix-TIME_IN_MS [.suffix]”。 |
| saveAsObjectFiles(prefix, [suffix]) | 将此DStream的内容保存为SequenceFiles序列化Java对象。每个批处理间隔的文件名基于前缀和 后缀生成:“prefix-TIME_IN_MS [.suffix]”。 |
| saveAsHadoopFiles(prefix, [suffix]) | 将此DStream的内容保存为SequenceFiles序列化Java对象。每个批处理间隔的文件名基于前缀和 后缀生成:“prefix-TIME_IN_MS [.suffix]”。 Python API这在Python API中不可用。 |
| foreachRDD(func) | 最通用的输出运算符,它将函数func应用于从流生成的每个RDD。此函数应将每个RDD中的数据推送到外部系统,例如将RDD保存到文件,或通过网络将其写入数据库。请注意,函数func在运行流应用程序的驱动程序进程中执行,并且通常会在其中执行RDD操作,这将强制计算流式RDD。 |
1)foreachRDD(func),正确高效的使用 直达车
connection 为外部链接
代码
dstream.foreachRDD { rdd =>
rdd.foreachPartition { partitionOfRecords =>
val connection = createNewConnection()
partitionOfRecords.foreach(record => connection.send(record))
connection.close()
}
}更高效的
dstream.foreachRDD { rdd =>
rdd.foreachPartition { partitionOfRecords =>
// ConnectionPool is a static, lazily initialized pool of connections
val connection = ConnectionPool.getConnection()
partitionOfRecords.foreach(record => connection.send(record))
ConnectionPool.returnConnection(connection) // return to the pool for future reuse
}
}-------------------------------------------
个性签名:独学而无友,则孤陋而寡闻。做一个灵魂有趣的人!
如果觉得这篇文章对你有小小的帮助的话,记得在右下角点个“推荐”哦,在此感谢!

