
python课程设计——北上广深空气质量数据爬取
一.选题背景
随着国民经济的不断发展,社会公众越来越关注各种高影响天气事件对日常生活造成的影响。历史天气数据对于天气的预测具有重大参考意义。这些信息对于规划生活、工作、学习等活动都很有帮助。因此对历史天气数据的获取与分析能够在各个领域为天气预测提供帮助。
二.主题式网络爬虫设计方案
- 该网络爬虫为历史天气数据爬虫
- 旨在爬取历史天气的各项指标数据并进行持久化处理,通过可视化手段,总结相关规律。
- 设计方案:
使用爬虫,从天气预报网页上爬取指定北京、上海、广州、深圳四个城市的空气质量指数 AQI_PM2.5 历史数据(任意指定年份),分析网页,分析数据组织方式,将爬取的数据保存到本地,存为 excel 文件。由于2022尚未结束,该程序对2021年12个月完整数据进行分析。
包括如下:数据获取持久化处理 图表绘制
三.主题页面的结构特征分析
数据源:天气后报:www.tianqihoubao.com
该网站可以查询到各个省份、 城市的历史天气记录,其中AQI信息和PM2.5信息位于如下链接:
http://www.tianqihoubao.com/aqi/beijing-202209.html
举例数据为2022年9月份数据,可以发现其中beijing即为城市名拼音,202209为日期。即获得所需数据规律为 url = f'http://www.tianqihoubao.com/aqi/{city} -{date}.html'
至此,爬虫url规律总结完毕。
下一步对具体的url数据进行爬取即可。
通过分析具体url页面如下图发现:
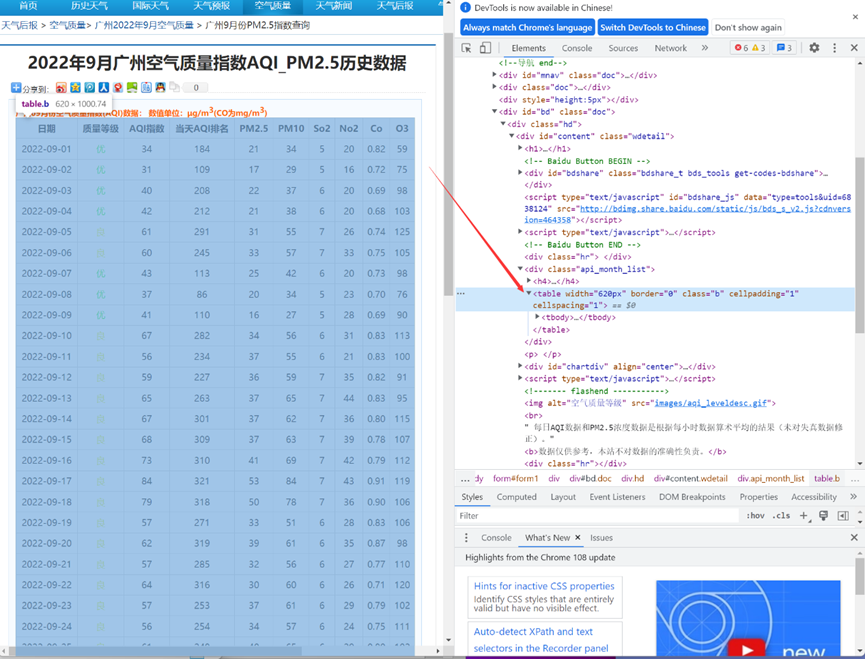
目标数据位于一个table标签中
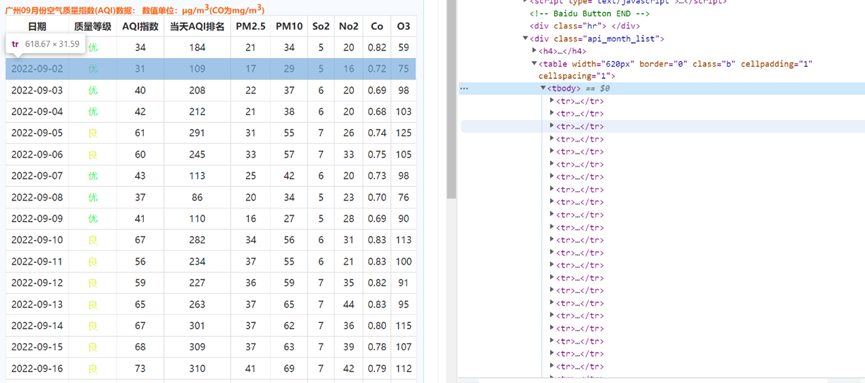
table标签中的tbody标签内即为表格的所有数据,其中每一个tr标签表示一行的数据,tr标签中的第n个td标签的数据即为第n列的数据。
四.网络爬虫程序设计
1.主页面的爬取:
由上述三中规律可以编写代码如下:

response = requests.get(url=url,headers=headers) soup = BeautifulSoup(response.text, 'html.parser') table_tag = soup.find('table') lines_lst = table_tag.find_all('tr') res_lst = [] for line in lines_lst: temp_lst = [] for col in line.find_all('td'): temp_lst.append(col.text.strip()) res_lst.append(temp_lst)
通过requests方法发起请求,使用Beautifulsoup进行数据解析,并定位标签,再使用嵌套的循环获取行列数据,最后获取到一个二维的list,使用pandas的Dataframe方法将该list转化为二维的Dataframe格式数据。
2.数据清洗
所获取的数据,可能存在重复行数据,使用drop_duplicates()方法去重。
3.数据可视化
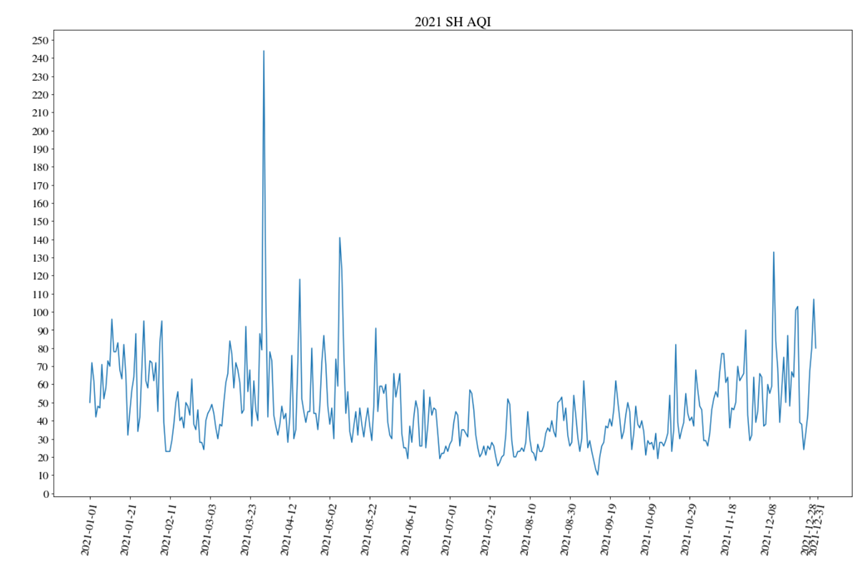
(1) 2021年上海AQI全年走势图
实现代码如下:
encoding=utf-8
sh_aqi = res_df_sh['AQI指数'].astype(float)
sh_date = res_df_sh['日期']
df = res_df_sh
totalSeed = df['日期'].tolist()
fig1, ax = plt.subplots(figsize=(20, 12))
ax.plot(totalSeed, sh_aqi)
xticks=list(range(0,len(totalSeed),20))
xlabels=[totalSeed[x] for x in xticks]
xticks.append(len(totalSeed))
xlabels.append(totalSeed[-1])
ax.set_xticks(xticks)
ax.set_xticklabels(xlabels, rotation=80)
ymajorLocator = MultipleLocator(10)
ax.yaxis.set_major_locator(ymajorLocator)
# ax.xaxis.set_major_locator(ticker.MultipleLocator(40))
plt.title("2021 SH AQI")
运行结果:
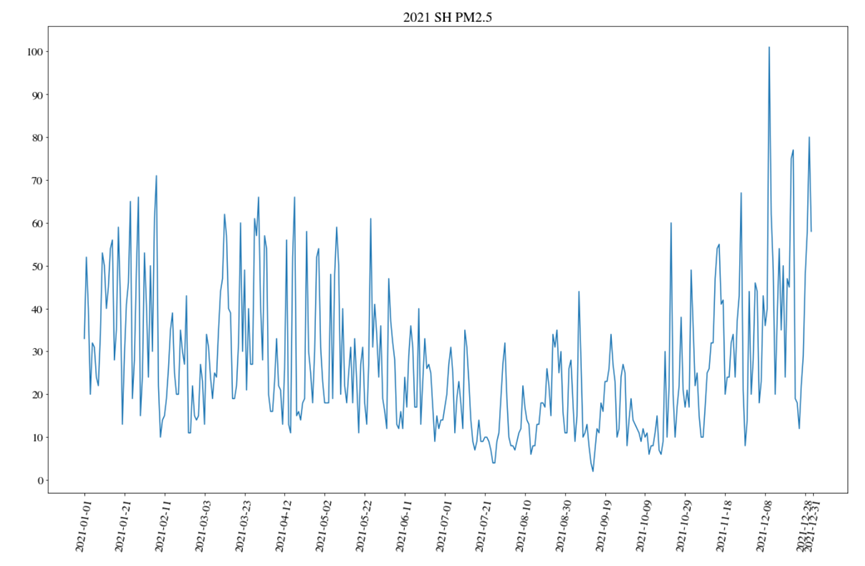
(2)绘制2021年上海PM2.5全年走势图
# encoding=utf-8 sh_aqi = res_df_sh['PM2.5'].astype(float) sh_date = res_df_sh['日期'] df = res_df_sh totalSeed = df['日期'].tolist() fig1, ax = plt.subplots(figsize=(20, 12)) ax.plot(totalSeed, sh_aqi) xticks=list(range(0,len(totalSeed),20)) xlabels=[totalSeed[x] for x in xticks] xticks.append(len(totalSeed)) xlabels.append(totalSeed[-1]) ax.set_xticks(xticks) ax.set_xticklabels(xlabels, rotation=80) ymajorLocator = MultipleLocator(10) ax.yaxis.set_major_locator(ymajorLocator) # ax.xaxis.set_major_locator(ticker.MultipleLocator(40)) plt.title("2021 SH PM2.5")
运行结果:
(3)2021年上海PM2.5指数日历图
import calmap import matplotlib import matplotlib.pyplot as plt def calendar_heatmap(df): # 定义颜色 color_list = ['#009966', '#FFDE33', '#FF9A32', '#CC0033', '#660099'] levels = [0, 50, 100, 150, 200, 300] cmap = matplotlib.colors.ListedColormap(color_list) norm = matplotlib.colors.BoundaryNorm(levels, 5) # 绘图 fig, ax = plt.subplots(figsize=(18, 9)) calmap.yearplot( df, vmin=0, vmax=300, cmap=cmap, norm=norm, how=None, year=2021, ) cbar_ax = fig.add_axes([0.94, 0.4, 0.015, 0.2]) cb = matplotlib.colorbar.ColorbarBase( cbar_ax, cmap=cmap, ticks=levels, norm=norm, orientation='vertical', extend='neither', extendrect=True, extendfrac=0.15 ) # 色标 cb.set_ticks([0, 50, 100, 150, 200, 300]) cb.ax.yaxis.set_tick_params(length=0.01) ax.set_ylabel('2021', fontdict=dict(fontsize=25, color='grey')) # 标题 ax.set_title(f'PM2.5 of SH', fontweight = 'bold', fontsize = 25) cp = res_df_sh.resample('1d').mean().round(2)['PM2.5'] calendar_heatmap(cp)
运行结果:

(4).绘制北上广深四地2021年AQI全年走势图并进行比对
# encoding=utf-8 sh_aqi = res_df_sh['AQI指数'].astype(float) sh_date = res_df_sh['日期'] df = res_df_sh totalSeed = df['日期'].tolist() fig1, ax = plt.subplots(figsize=(20, 8)) ax.plot(totalSeed, res_df_bj.loc[:,'AQI指数'].astype(float),label='BJ') ax.plot(totalSeed, res_df_sh.loc[:,'AQI指数'].astype(float),label='SH') ax.plot(totalSeed, res_df_gz.loc[:,'AQI指数'].astype(float)) ax.plot(totalSeed, res_df_sz.loc[:,'AQI指数'].astype(float)) xticks=list(range(0,len(totalSeed),20)) xlabels=[totalSeed[x] for x in xticks] xticks.append(len(totalSeed)) xlabels.append(totalSeed[-1]) ax.set_xticks(xticks) ax.set_xticklabels(xlabels, rotation=80) # fig1.legend(('北京','上海','广州','深圳'),frameon=False, loc='upper center',ncol=4,handlelength=4) # 图例 fig1.legend(('BJ','SH','GZ','SZ'),frameon=False, loc='upper center',ncol=4,handlelength=4) # 图例 ymajorLocator = MultipleLocator(10) ax.yaxis.set_major_locator(ymajorLocator) # ax.xaxis.set_major_locator(ticker.MultipleLocator(40)) plt.title("2021 AQI COMPARISON")
运行结果:
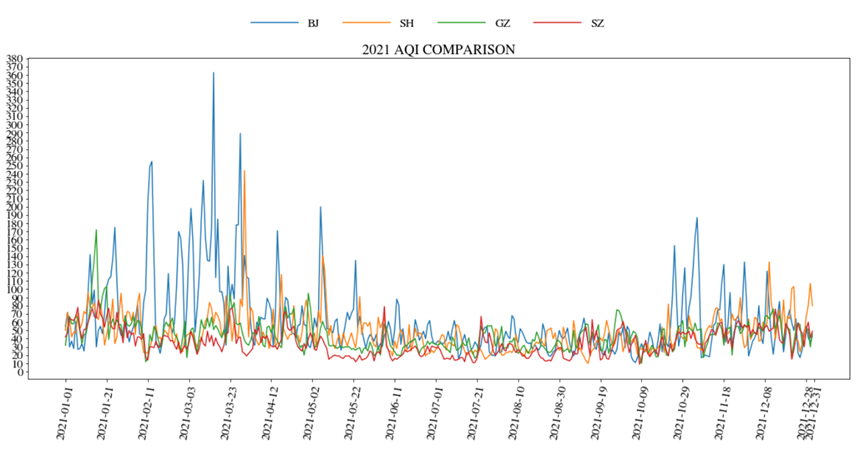
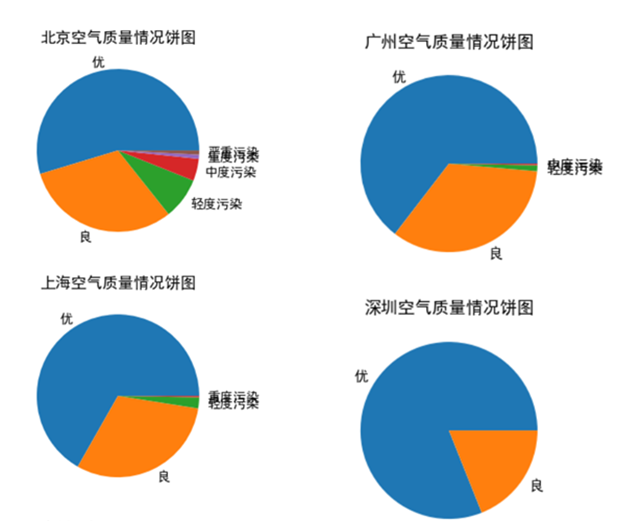
(5).绘制北上广深全年空气质量情况饼图。
plt.rcParams['font.family'] = ['sans-serif'] plt.rcParams['font.size'] = '14' plt.rcParams['font.sans-serif'] = ['SimHei'] df2 = res_df_bj labels = df2['质量等级'].value_counts().index values = df2['质量等级'].value_counts().values plt.pie(values, labels=labels, # 设置饼图标签 ) plt.title("北京空气质量情况饼图") # 设置标题 plt.show()
运行效果图:
4.数据持久化
完成上述1中操作后,使用Dataframe.to_excel()方法即可是实现数据的持久化,将数据结果保存为一个xlsx文件。
持久化结果如下图所示:
五.总结
1.对历史天气分析发现,全年四个城市中均为二三两个月份AQI指数较高,北京AQI指数远高于其他三座城市,四座城市AQI指标呈现相似的变化规律。空气质量情况上看,深圳为北上广深中最好的。
2.爬取到的数据指标众多,需要根据其他知识对指标重要性进行判断,使用不同的可视化手段进行处理,得到有用规律。
六.整体代码
# 导入所需库 import pandas as pd import matplotlib import requests import time from bs4 import BeautifulSoup # 爬虫 url1 = 'http://www.tianqihoubao.com/aqi/beijing-202209.html' url2 = 'http://www.tianqihoubao.com/aqi/beijing-202210.html' def get_url_info(url): """ 获取单个url(某城市某个月的天气信息url)的信息 return : DataFrame 为表格信息 """ headers = { 'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/avif,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.9', 'Cookie': "__51cke__=; ASP.NET_SessionId=fkkucvjbb02l3y2owpcvnl55; __tins__21287555=%7B%22sid%22%3A%201671355464098%2C%20%22vd%22%3A%2012%2C%20%22expires%22%3A%201671358170641%7D; __51laig__=12", 'Host': 'www.tianqihoubao.com', 'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/108.0.0.0 Safari/537.36' } response = requests.get(url=url, headers=headers) soup = BeautifulSoup(response.text, 'html.parser') table_tag = soup.find('table') lines_lst = table_tag.find_all('tr') res_lst = [] for line in lines_lst: temp_lst = [] for col in line.find_all('td'): temp_lst.append(col.text.strip()) res_lst.append(temp_lst) df = pd.DataFrame(res_lst) return df data1 = get_url_info(url1) data2 = get_url_info(url2) new_df = pd.concat([data1,data2],axis=0) # 北京 df_bj = pd.DataFrame() # 上海 df_sh = pd.DataFrame() # 广州 df_gz = pd.DataFrame() # 深圳 df_sz = pd.DataFrame() #北京 for date in range(202101, 202113): url_bj = f'http://www.tianqihoubao.com/aqi/beijing-{date}.html' tmp_bj = get_url_info(url_bj) df_bj = pd.concat([tmp_bj, df_bj]) print("北京", date) for date in range(202101, 202113): # 深圳 url_sz = f'http://www.tianqihoubao.com/aqi/shenzhen-{date}.html' tmp_sz = get_url_info(url_sz) df_sz = pd.concat([tmp_sz, df_sz]) print("深圳",date) for date in range(202101, 202113): # 广州 url_gz = f'http://www.tianqihoubao.com/aqi/guangzhou-{date}.html' tmp_gz = get_url_info(url_gz) df_gz = pd.concat([tmp_gz, df_gz]) print("广州",date) for date in range(202101, 202113): # 上海 url_sh = f'http://www.tianqihoubao.com/aqi/shanghai-{date}.html' tmp_sh = get_url_info(url_sh) df_sh = pd.concat([tmp_sh, df_sh]) print("上海",date) col_list = df_bj.values[:1][0] col_list = df_sz.values[:1][0] col_list = df_gz.values[:1][0] col_list = df_sh.values[:1][0] # 复制 去重 res_df_bj = df_bj.drop_duplicates() res_df_sz = df_sz.drop_duplicates() res_df_gz = df_gz.drop_duplicates() res_df_sh = df_sh.drop_duplicates() res_df_bj.columns = col_list res_df_sz.columns = col_list res_df_gz.columns = col_list res_df_sh.columns = col_list res_df_bj = res_df_bj[1:-1].sort_values(by='日期', ascending=True) res_df_sz = res_df_sz[1:-1].sort_values(by='日期', ascending=True) res_df_gz = res_df_gz[1:-1].sort_values(by='日期', ascending=True) res_df_sh = res_df_sh[1:-1].sort_values(by='日期', ascending=True) # 数据持久化 res_df_bj.to_excel('res_bj.xlsx', index=None) res_df_sz.to_excel('res_sz.xlsx', index=None) res_df_gz.to_excel('res_gz.xlsx', index=None) res_df_sh.to_excel('res_sh.xlsx', index=None) res_df_bj = pd.read_excel('res_bj.xlsx') res_df_sh = pd.read_excel('res_sh.xlsx') res_df_sz = pd.read_excel('res_sz.xlsx') res_df_gz = pd.read_excel('res_gz.xlsx') # 1.绘制2021年上海AQI全年走势图 # encoding=utf-8 import matplotlib.pyplot as plt from matplotlib.pyplot import MultipleLocator sh_aqi = res_df_sh['AQI指数'].astype(float) sh_date = res_df_sh['日期'] df = res_df_sh totalSeed = df['日期'].tolist() fig1, ax = plt.subplots(figsize=(20, 12)) ax.plot(totalSeed, sh_aqi) xticks = list(range(0, len(totalSeed), 20)) xlabels = [totalSeed[x] for x in xticks] xticks.append(len(totalSeed)) xlabels.append(totalSeed[-1]) ax.set_xticks(xticks) ax.set_xticklabels(xlabels, rotation=80) ymajorLocator = MultipleLocator(10) ax.yaxis.set_major_locator(ymajorLocator) # ax.xaxis.set_major_locator(ticker.MultipleLocator(40)) plt.title("2021 SH AQI") # 2.绘制2021年上海PM2.5全年走势图 # encoding=utf-8 sh_aqi = res_df_sh['PM2.5'].astype(float) sh_date = res_df_sh['日期'] df = res_df_sh totalSeed = df['日期'].tolist() fig1, ax = plt.subplots(figsize=(20, 12)) ax.plot(totalSeed, sh_aqi) xticks = list(range(0, len(totalSeed), 20)) xlabels = [totalSeed[x] for x in xticks] xticks.append(len(totalSeed)) xlabels.append(totalSeed[-1]) ax.set_xticks(xticks) ax.set_xticklabels(xlabels, rotation=80) ymajorLocator = MultipleLocator(10) ax.yaxis.set_major_locator(ymajorLocator) # ax.xaxis.set_major_locator(ticker.MultipleLocator(40)) plt.title("2021 SH PM2.5") sh_aqi = res_df_sh['AQI指数'] date = res_df_sh['日期'] # # 3.绘制2021年上海PM2.5指数日历图 res_df_sh.index = res_df_sh['日期'].astype('datetime64') res_df_sh.to_excel('res_sh.xlsx', index=None) res_df_sh = pd.read_excel('res_sh.xlsx') res_df_sh.index = res_df_sh['日期'].astype('datetime64') # # import calmap # import matplotlib # import matplotlib.pyplot as plt # # def calendar_heatmap(df): # # 定义颜色 # color_list = ['#009966', '#FFDE33', '#FF9A32', '#CC0033', '#660099'] # levels = [0, 50, 100, 150, 200, 300] # cmap = matplotlib.colors.ListedColormap(color_list) # norm = matplotlib.colors.BoundaryNorm(levels, 5) # # 绘图 # fig, ax = plt.subplots(figsize=(18, 9)) # calmap.yearplot( # df, # vmin=0, # vmax=300, # cmap=cmap, # norm=norm, # how=None, # year=2021, # ) # cbar_ax = fig.add_axes([0.94, 0.4, 0.015, 0.2]) # cb = matplotlib.colorbar.ColorbarBase( # cbar_ax, # cmap=cmap, # ticks=levels, # norm=norm, # orientation='vertical', # extend='neither', # extendrect=True, # extendfrac=0.15 # ) # # 色标 # cb.set_ticks([0, 50, 100, 150, 200, 300]) # cb.ax.yaxis.set_tick_params(length=0.01) # ax.set_ylabel('2021', fontdict=dict(fontsize=25, color='grey')) # # 标题 # ax.set_title(f'PM2.5 of SH', fontweight='bold', fontsize=25) # # # cp = res_df_sh.resample('1d').mean().round(2)['PM2.5'] # calendar_heatmap(cp) # 4.绘制北上广深四地2021年AQI全年走势图并进行比对 # encoding=utf-8 sh_aqi = res_df_sh['AQI指数'].astype(float) sh_date = res_df_sh['日期'] df = res_df_sh totalSeed = df['日期'].tolist() fig1, ax = plt.subplots(figsize=(20, 8)) ax.plot(totalSeed, res_df_bj.loc[:, 'AQI指数'].astype(float), label='BJ') ax.plot(totalSeed, res_df_sh.loc[:, 'AQI指数'].astype(float), label='SH') ax.plot(totalSeed, res_df_gz.loc[:, 'AQI指数'].astype(float)) ax.plot(totalSeed, res_df_sz.loc[:, 'AQI指数'].astype(float)) xticks = list(range(0, len(totalSeed), 20)) xlabels = [totalSeed[x] for x in xticks] xticks.append(len(totalSeed)) xlabels.append(totalSeed[-1]) ax.set_xticks(xticks) ax.set_xticklabels(xlabels, rotation=80) # fig1.legend(('北京','上海','广州','深圳'),frameon=False, loc='upper center',ncol=4,handlelength=4) # 图例 fig1.legend(('BJ', 'SH', 'GZ', 'SZ'), frameon=False, loc='upper center', ncol=4, handlelength=4) # 图例 ymajorLocator = MultipleLocator(10) ax.yaxis.set_major_locator(ymajorLocator) # ax.xaxis.set_major_locator(ticker.MultipleLocator(40)) plt.title("2021 AQI COMPARISON") plt.show() # 5.绘制北上广深全年空气质量情况饼图。 import matplotlib.pyplot as plt import numpy as np plt.rcParams['font.family'] = ['sans-serif'] plt.rcParams['font.size'] = '14' plt.rcParams['font.sans-serif'] = ['SimHei'] df2 = res_df_bj labels = df2['质量等级'].value_counts().index values = df2['质量等级'].value_counts().values plt.pie(values, labels=labels, # 设置饼图标签 ) plt.title("北京空气质量情况饼图") # 设置标题 plt.show() df2 = res_df_sh labels = df2['质量等级'].value_counts().index values = df2['质量等级'].value_counts().values plt.pie(values, labels=labels, # 设置饼图标签 ) plt.title("上海空气质量情况饼图") # 设置标题 plt.show() df2 = res_df_gz labels = df2['质量等级'].value_counts().index values = df2['质量等级'].value_counts().values plt.pie(values, labels=labels, # 设置饼图标签 ) plt.title("广州空气质量情况饼图") # 设置标题 plt.show() df2 = res_df_sz labels = df2['质量等级'].value_counts().index values = df2['质量等级'].value_counts().values plt.pie(values, labels=labels, # 设置饼图标签 ) plt.title("深圳空气质量情况饼图") # 设置标题 plt.show()


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· winform 绘制太阳,地球,月球 运作规律
· 震惊!C++程序真的从main开始吗?99%的程序员都答错了
· 【硬核科普】Trae如何「偷看」你的代码?零基础破解AI编程运行原理
· AI与.NET技术实操系列(五):向量存储与相似性搜索在 .NET 中的实现
· 超详细:普通电脑也行Windows部署deepseek R1训练数据并当服务器共享给他人