linux 搭建elk6.8.0集群并破解安装x-pack
一、环境信息以及安装前准备
1、组件介绍
*Filebeat是一个日志文件托运工具,在你的服务器上安装客户端后,filebeat会监控日志目录或者指定的日志文件,追踪读取这些文件(追踪文件的变化,不停的读) Kafka是一种高吞吐量的分布式发布订阅消息系统,它可以处理消费者规模的网站中的所有动作流数据(暂时不用) *Logstash是一根具备实时数据传输能力的管道,负责将数据信息从管道的输入端传输到管道的输出端;与此同时这根管道还可以让你根据自己的需求在中间加上滤网,Logstash提供里很多功能强大的滤网以满足你的各种应用场景 *ElasticSearch它提供了一个分布式多用户能力的全文搜索引擎,基于RESTful web接口 *Kibana是ElasticSearch的用户界面
在实际应用场景下,为了满足大数据实时检索的场景,利用Filebeat去监控日志文件,将Kafka作为Filebeat的输出端,Kafka实时接收到Filebeat后以Logstash作为输出端输出,到Logstash的数据也许还不是我们想要的格式化或者特定业务的数据,这时可以通过Logstash的一些过了插件对数据进行过滤最后达到想要的数据格式以ElasticSearch作为输出端输出,数据到ElasticSearch就可以进行丰富的分布式检索了
2、高级架构
Elastic的技术架构可以简单,也可以高级,它是很具有扩展性的,最简单的技术架构就是使用Beats进行数据的收集,Beats是一种抽象的称呼,具体的可以是使用FileBeat收集数据源为文件的数据或者使用TopBeat来收集系统中的监控信息,可以说类似Linux系统中的TOP命令,当然还有很多的Beats的具体实现,再使用logstash进行数据的转换和导入到Elasticsearch中,最后使用Kibana进行数据的操作以及数据的可视化等操作。
当然,在生产环境中,我们的数据可能在不同的地方,例如关系型数据库Postgre,或者MQ,再或者Redis中,我们可以统一使用Logstash进行数据的转换,同时,也可以根据数据的热度不同将ES集群架构为一种冷温热架构,利用ES的多节点,将一天以内的数据称谓热数据,读写频繁,就存放在ES的热节点中,七天以内的数据称之为温数据,就是偶尔使用的数据存放在温节点中,将极少数会用到的数据存放在冷节点中。
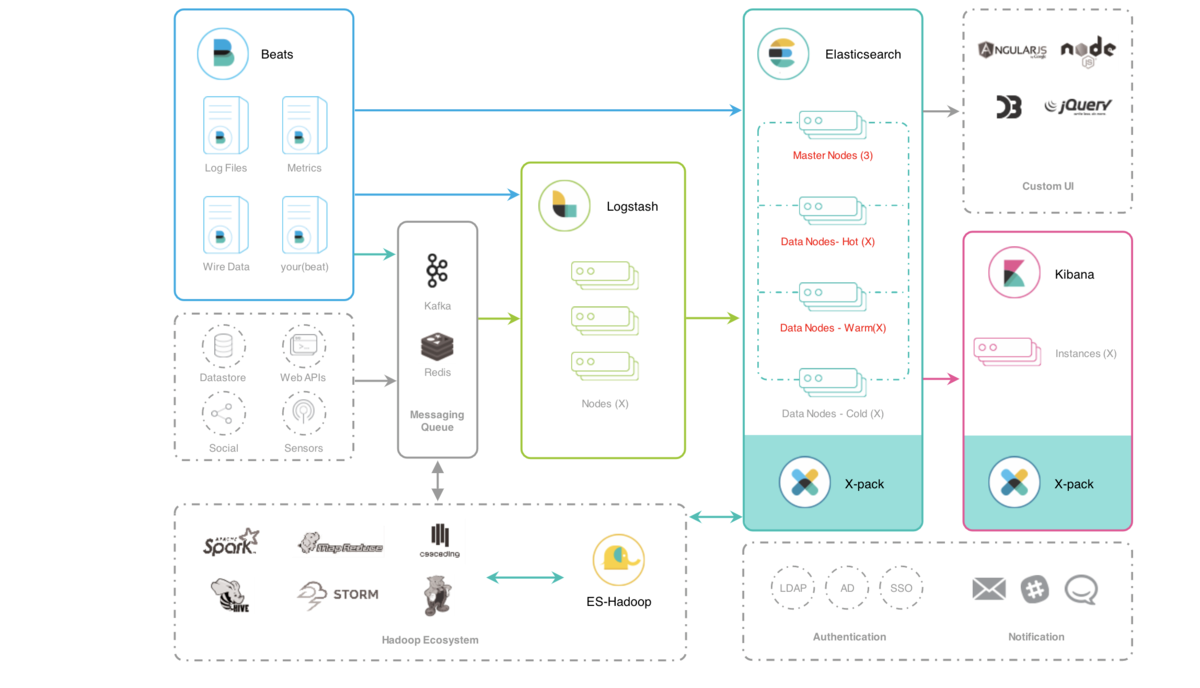
3、本次架构图

4、环境准备
主机角色,配置(内存不要低于8核16G):

5、软件版本下载
官网下载地址,个人建议最好再官网下载,之前在其他网站下载es,一直报错,一直解决不了,在官网上下载下来的就一点问题都没有:(如果下载过慢,建议使用迅雷下载,有会员就更好啦)
elastic https://artifacts.elastic.co/downloads/elasticsearch/elasticsearch-6.8.0.rpm kibana https://artifacts.elastic.co/downloads/kibana/kibana-6.8.0-x86_64.rpm logstash https://artifacts.elastic.co/downloads/logstash/logstash-6.8.0.rpm filebeat https://artifacts.elastic.co/downloads/beats/filebeat/filebeat-6.8.0-x86_64.rpm
破解的x-pack和license的包下载地址:https://pan.baidu.com/s/1f9plvnhdbeSroOdW2G1YIg 提取码:1v2g
6、安装前提:
所有插件安装之前必须安装jdk1.8,并且需要配置环境变量,这边我就不一一介绍了。
二、ES集群安装配置
2.1、安装
说明:3台机器一起安装
[root@es-node1 config]#rpm -ivh elasticsearch-6.8.0.rpm
2.2、配置elasticsearch
#配置JVM参数,最大不要超过32G,并且留一半内存给操作系统,默认是1g [root@es-node1 config]# vim jvm.options -Xms4g -Xmx4g #配置elastic信息,其他节点需要修改node.name和network.host的值 [root@es-node1 config]# cd /etc/elasticsearch [root@es-node1 config]# cp elasticsearch.yml elasticsearch.yml-bak [root@es-node1 config]# vim elasticsearch.yml [root@es-node1 config]# grep "^[a-z]" elasticsearch.yml cluster.name: my-es node.name: node-76 path.data: /data/es #日志收集的目录 path.logs: /var/log/elasticsearch #es自己的日志,如有报错可在这边查看 network.host: 172.9.201.76 http.port: 9200 discovery.zen.ping.unicast.hosts: ["172.9.201.76", "172.9.201.77","172.9.201.78"] discovery.zen.minimum_master_nodes: 2
设置打开文件描述符、进程数、内存限制
[root@es-node1 config]# vim /etc/security/limits.conf * soft nofile 65536 * hard nofile 131072 * soft nproc 2048 * hard nproc 4096 * soft memlock unlimited * hard memlock unlimited
配置内核参数
[root@es-node1 config]# vim /etc/sysctl.conf net.ipv4.tcp_max_tw_buckets = 6000 net.ipv4.ip_local_port_range = 1024 65000 net.ipv4.tcp_tw_reuse = 1 net.ipv4.tcp_tw_recycle = 1 net.ipv4.tcp_fin_timeout = 10 net.ipv4.tcp_syncookies = 1 net.core.netdev_max_backlog = 262144 net.ipv4.tcp_max_orphans = 262144 net.ipv4.tcp_max_syn_backlog = 262144 net.ipv4.tcp_timestamps = 0 net.ipv4.tcp_synack_retries = 1 net.ipv4.tcp_syn_retries = 1 net.ipv4.tcp_keepalive_time = 30 net.ipv4.tcp_mem= 786432 2097152 3145728 net.ipv4.tcp_rmem= 4096 4096 16777216 net.ipv4.tcp_wmem= 4096 4096 16777216
创建相关目录及授权
[root@es-node1 ~]# mkdir -pv /data/es/ mkdir: 已创建目录 "/data" mkdir: 已创建目录 "/data/es/" [root@es-node1 ~]# chown -R elastic:elastic /data/es/
启动elasticsearch,三台机器一起启动
[root@es-node1 ~]# systemctl start elasticsearch
检查服务是否正常:
[elastic@es-node1 elasticsearch]$ netstat -tnlp Proto Recv-Q Send-Q Local Address Foreign Address State PID/Program name tcp 0 0 172.9.201.76:9200 0.0.0.0:* LISTEN 2072/java #9200是http协议的RESTful接口 tcp 0 0 172.9.201.76:9300 0.0.0.0:* LISTEN 2072/java #9300是tcp通讯端口,集群间和TCPClient都走的它 tcp 0 0 0.0.0.0:22 0.0.0.0:* LISTEN - tcp6 0 0 :::22 :::* LISTEN -
在浏览器中访问: http://172.9.201.76:9200
name "node-76" cluster_name "my-es" cluster_uuid "FhxctUHqTz6eJZCkDuXwPQ" version number "6.8.0" build_flavor "default" build_type "rpm" build_hash "65b6179" build_date "2019-05-15T20:06:13.172855Z" build_snapshot false lucene_version "7.7.0" minimum_wire_compatibility_version "5.6.0" minimum_index_compatibility_version "5.0.0" tagline "You Know, for Search"
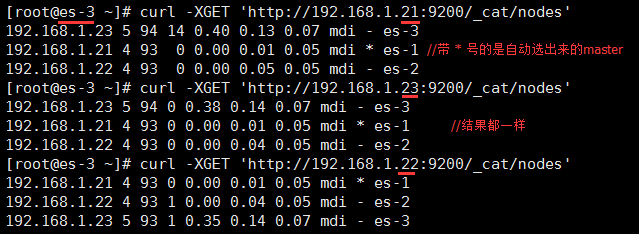
查看是否是集群:
curl -XGET 'http://172.9.201.76:9200/_cat/nodes' //随意一台es中可执行,也可更换其中的 ip(这里可22或23)
三、安装并配置Kibana
3.1、安装kibana
[root@shtw-kibana01 ~]# rpm -ivh kibana-6.8.0-x86_64.rpm
3.2、配置kibana
说明:虽然我们搭建了三台es的集群,但是我们在kibana.yml的elasticsearch.hosts只能配置一台es的主机,所以我们这边一般配置master这一台。
[root@shtw-kibana01 ~]# cd /etc/kibana [root@shtw-kibana01 ~]# cp kibana.yml kibana.yml-bak [root@shtw-kibana01 ~]# vim kibana.yml server.port: 5601 #监听的端口 server.host: "172.9.201.83" #监听的地址 elasticsearch.hosts: ["http://172.9.201.76:9200"] #elasticsearch访问的URL地址
3.3、启动kibana
[root@shtw-kibana01 ~]# systemctl start kibana
我们可以看到启动后服务监听的地址,访问这个URL:172.9.201.83:5601
kibana主页面,大致意思就是告诉我们kibana可以做哪些事
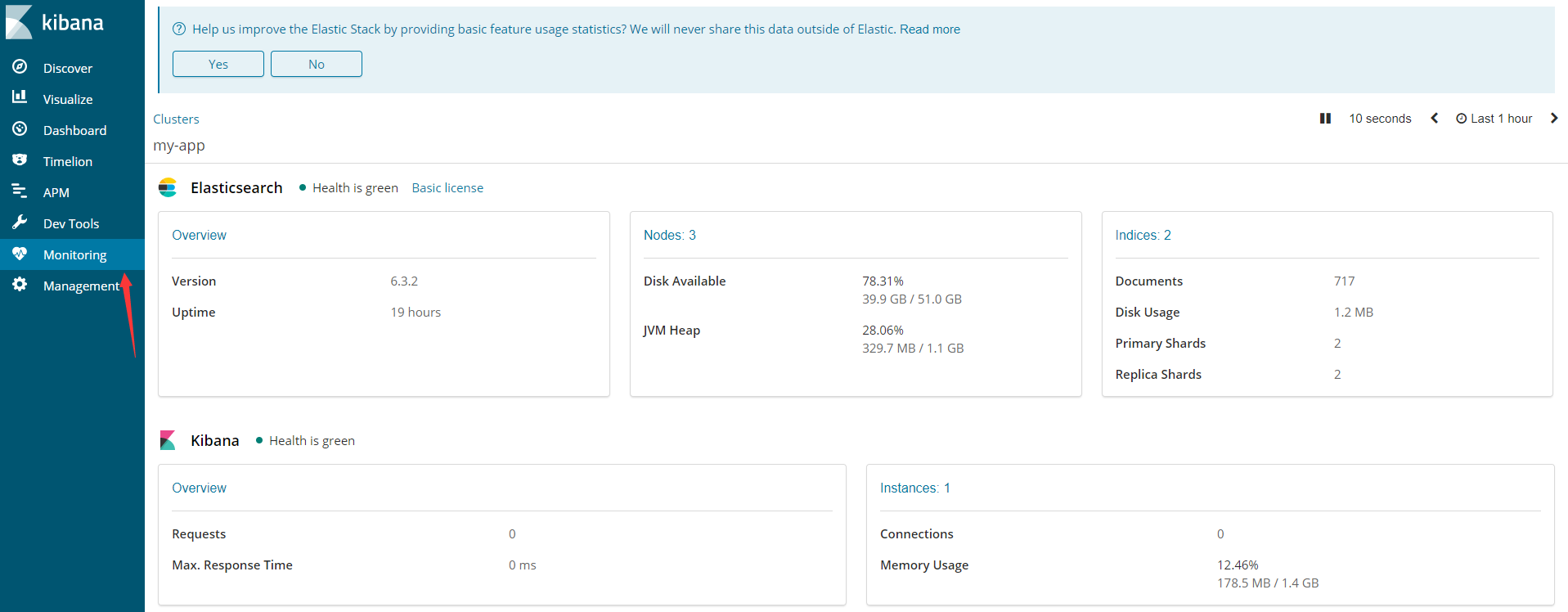
点击Monitoring标签可以开启监控设置,并且我们的license是basic版本的(即基础版)
3.4、汉化kibana
7.x版本官方自带汉化资源文件(位于kibana目录下的node_modules/x-pack/plugins/translations/translations/目录,所以我们6.8.0是自带汉化目录的,接下来我们要做的是:
[root@shtw-kibana01 translations]# cd /usr/share/kibana/node_modules/x-pack/plugins/translations [root@shtw-kibana01 translations]# cp -r translations /usr/share/kibana/src/legacy/core_plugins/kibana [root@shtw-kibana01 translations]# cd /etc/kibana/kibana.yml #修改配置文件 i18n.locale: "zh-CN" #默认是en
四、安装破解版x-pack
强烈说明:本教程只供交流学习使用,切勿运用到商业用途。如有需要请购买官方正版授权
由于在elasticsearch在6.3版本之后x-pack是默认安装好的,所以不再需要用户自己去安装
1、替换x-pack包,并重启elasticsearch服务
[root@shtw-esnode01 x-pack-core]# cd /usr/share/elasticsearch/modules/x-pack-core [root@shtw-esnode01 x-pack-core]# cp x-pack-core-6.8.0.jar x-pack-core-6.8.0.jar.20191206.bak [root@shtw-esnode01 x-pack-core]#rz -y #选择下载在windows桌面上的已经破解好的x-pack-core-6.8.0.jar
2、替换完毕之后需要新增elasticsearch.yml配置
[root@shtw-esnode01 elasticsearch]# cd /etc/elasticsearch [root@shtw-esnode01 elasticsearch]# vim elasticsearch.yml xpack.security.enabled: false #新增关闭x-pack的配置文件
重启elasticsearch服务,并把license.json上传到服务器(三台es集群机器都执行如下操作,不然无法破解)
[elastic@es-node1 elasticsearch]$ curl -XPUT -u elastic 'http://172.9.201.76:9200/_xpack/license' -H "Content-Type: application/json" -d @license.json
Enter host password for user 'elastic': #密码为:change
{"acknowledged":true,"license_status":"valid"}
在kibana上查看license
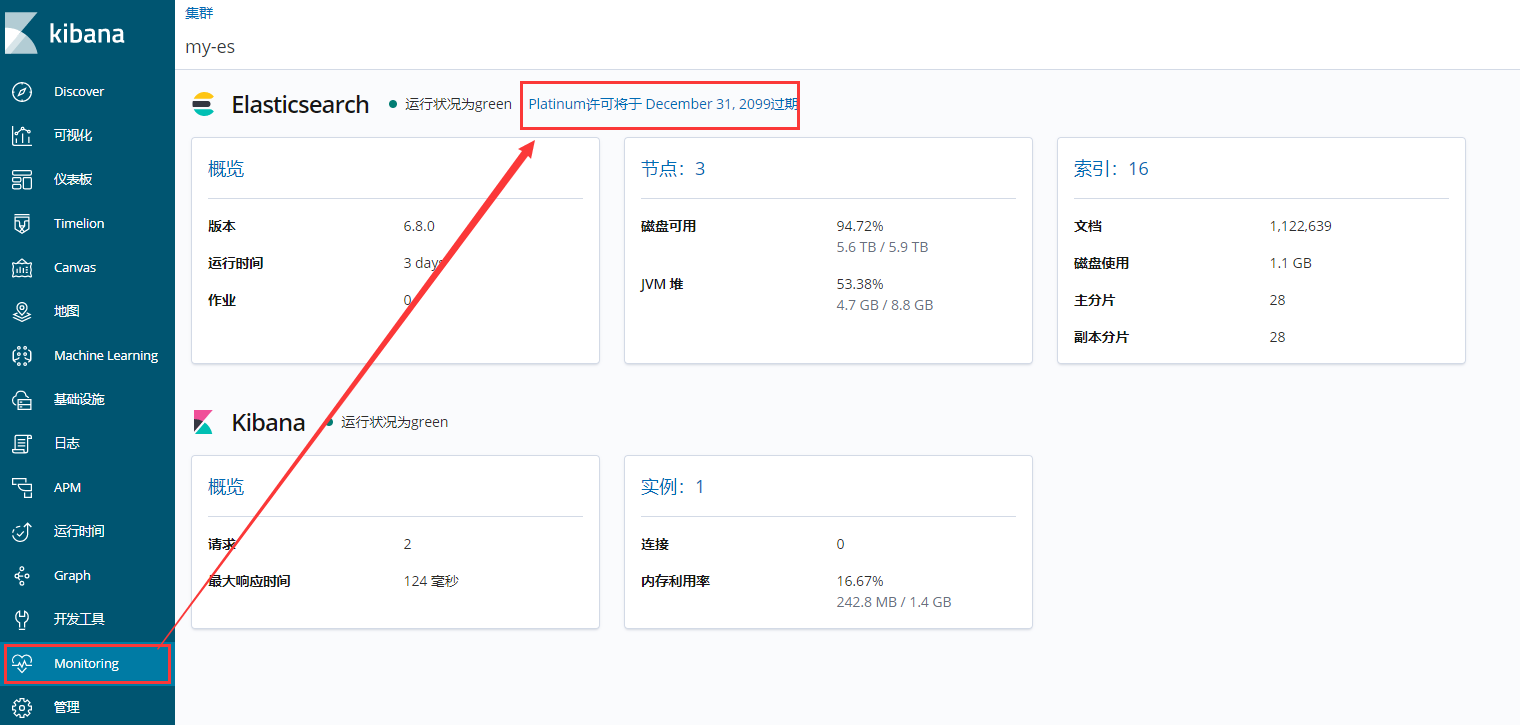
Platinum表示白金版 过期时间为2099 年12月31日,但是我们暂时还不能使用x-pack,因为白金版的x-pack需要SSL进行数据传输,所以我们需要先配置SSL
五、配置SSL并启用x-pack
配置SSL之后,只要在master的es机器上配置用户名密码之后,其他的两台es机器也具有相同的用户名密码,配置步骤如下
1、创建证书
[elastic@es-node1 elasticsearch]$ cd /usr/share/elasticsearch/bin [elastic@es-node1 bin]$ ./elasticsearch-certgen

2、解压证书
[elastic@es-node1 bin]$ mkdir /tmp/cert [elastic@es-node1 bin]$ mv cert.zip /tmp/cert/ [elastic@es-node1 bin]$ cd /tmp/cert/ [elastic@es-node1 cert]$ unzip cert.zip Archive: cert.zip creating: ca/ inflating: ca/ca.crt inflating: ca/ca.key creating: elasticsearch/ inflating: elasticsearch/elasticsearch.crt inflating: elasticsearch/elasticsearch.key [elastic@es-node1 cert]$ ll 总用量 8 drwxrwxr-x 2 elastic elastic 34 9月 20 13:47 ca -rw------- 1 elastic elastic 5157 9月 20 13:47 cert.zip drwxrwxr-x 2 elastic elastic 56 9月 20 13:47 elasticsearch [elastic@es-node1 cert]$ mv ca/* /etc/elasticsearch/ [elastic@es-node1 cert]$ mv elasticsearch/* /etc/elasticsearch/ [elastic@es-node1 cert]$ cd /etc/elasticsearch/ [elastic@es-node1 config]$ ll -rct #最后四个 总用量 48 -rw-rw---- 1 elastic elastic 0 9月 19 16:15 users_roles -rw-rw---- 1 elastic elastic 0 9月 19 16:15 users -rw-rw---- 1 elastic elastic 197 9月 19 16:15 roles.yml -rw-rw---- 1 elastic elastic 473 9月 19 16:15 role_mapping.yml -rw-rw---- 1 elastic elastic 6380 9月 19 16:15 log4j2.properties -rw-rw---- 1 elastic elastic 2942 9月 19 16:15 jvm.options -rw-r----- 1 elastic elastic 2853 9月 19 16:15 elasticsearch.yml-bak -rw-rw---- 1 elastic elastic 207 9月 19 16:20 elasticsearch.keystore -rw-rw---- 1 elastic elastic 2905 9月 20 13:27 elasticsearch.yml -rw-rw-r-- 1 elastic elastic 1671 9月 20 13:57 ca.key -rw-rw-r-- 1 elastic elastic 1200 9月 20 13:57 ca.crt -rw-rw-r-- 1 elastic elastic 1675 9月 20 13:57 elasticsearch.key -rw-rw-r-- 1 elastic elastic 1237 9月 20 13:57 elasticsearch.crt
将证书拷贝到其他节点,放入 /etc/elasticsearch 目录下
[elastic@es-node1 config]$ scp *.crt *.key 172.9.201.77:/etc/elasticsearch/ [elastic@es-node1 config]$ scp *.crt *.key 172.9.201.78:/etc/elasticsearch/
3、配置SSL,其他节点相同配置
[elastic@es-node1 config]$ vim elasticsearch.yml [elastic@es-node1 config]$ tail elasticsearch.yml # ---------------------------------- Various ----------------------------------- # # Require explicit names when deleting indices: # #action.destructive_requires_name: true xpack.security.enabled: true #之前配置为false注意删除或者修改 xpack.security.transport.ssl.enabled: true xpack.ssl.key: elasticsearch.key xpack.ssl.certificate: elasticsearch.crt xpack.ssl.certificate_authorities: ca.crt
重启elasticsearch服务,这个时候发现登录用户还是不行,不要着急,这边还需要配置kibana使用用户名密码登录
4、创建elk的集群的相关用户
注意的是:这边只需要在master的es主机上去创建,因为是master的es主机创建的ssl证书。
[elastic@es-node1 bin]$ cd /usr/share/elasticsearch/bin [elastic@es-node1 bin]$ ./elasticsearch-setup-passwords -h #查看命令帮助 Sets the passwords for reserved users Commands -------- auto - Uses randomly generated passwords #主要命令选项,表示系统将使用随机字符串设置密码 interactive - Uses passwords entered by a user #主要命令选项,表示使用用户输入的字符串作为密码 Non-option arguments: command Option Description ------ ----------- -h, --help show help -s, --silent show minimal output -v, --verbose show verbose output [elastic@es-node1 bin]$ ./elasticsearch-setup-passwords auto #为了演示效果,这里我们使用系统自动创建 Initiating the setup of passwords for reserved users elastic,kibana,logstash_system,beats_system. The passwords will be randomly generated and printed to the console. Please confirm that you would like to continue [y/N]y #选择y Changed password for user kibana #kibana角色和密码 PASSWORD kibana = 4VXPRYIVibyAbjugK6Ok Changed password for user logstash_system #logstash角色和密码 PASSWORD logstash_system = 2m4uVdSzDzpt9OEmNin5 Changed password for user beats_system #beast角色和密码 PASSWORD beats_system = O8VOzAaD3fO6bstCGDyQ Changed password for user elastic #elasticsearch角色和密码 PASSWORD elastic = 1TWVMeN8tiBy917thUxq
可以先将以上用户和密码保存下来,具体的用户介绍见最后,这边最好保存在有道云笔记中,方便记录。
配置kibana添加elasticsearch用户认证:
[root@kb-node1 ~]# vim /etc/kibana/kibana.yml [root@kb-node1 ~]# grep "^elastic" kibana.yml elasticsearch.username: "elastic" elasticsearch.password: "1TWVMeN8tiBy917thUxq" #就是上一步创建的elastic的账号和密码
重启kibana,重启后打开kibana web页面:
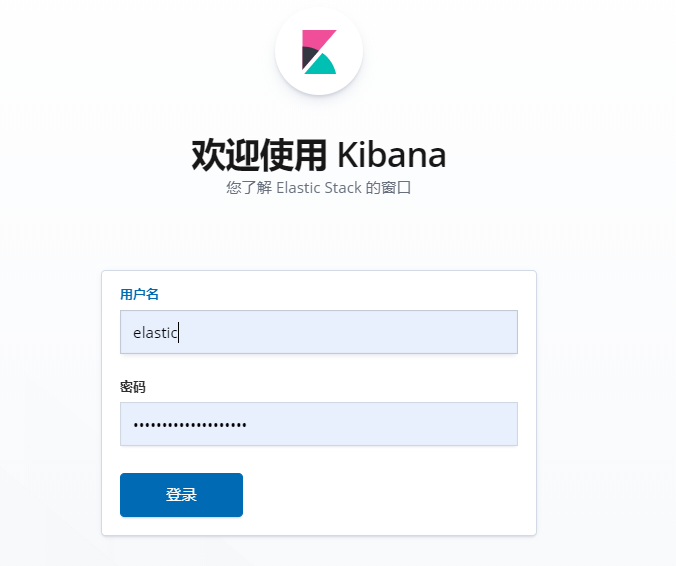
可以使用用户名和密码登录了(使用之前创建的用户名和密码登录即可),这里我们选择elastic用户登录
六、安装logstash以及配置
1、安装logstash
[root@shtw-logstash01 ~]# rpm -ivh logstash-6.8.0.rpm
2、配置logstash
[root@shtw-logstash01 logstash]# cd /etc/logstash [root@shtw-logstash01 logstash]# vim logstash.yml path.data: /data/logstash #配置数据路径 http.host: "172.9.201.82" #配置主机名 path.logs: /var/log/logstash
3、配置conf文件
说明:这边有一个大坑,如果你不在output中根据if去判断,则所有采集的日志,就会采集到各个index文件中,那样就会所有的index的内容就会是一样的,所以我们根据tags来判断。
[root@shtw-logstash01 conf.d]# cd /etc/logstash/conf.d
[root@shtw-logstash01 conf.d]# vim service_5044.conf
# Sample Logstash configuration for creating a simple
# Beats -> Logstash -> Elasticsearch pipeline.
#采集filebeat过来的日志
input {
beats {
port => 5044
}
file {
path=> [ "/usr/local/tomcat/logs/catalina.out"]
}
}
#过滤条件
filter{
if "beats_input_codec_plain_applied" in [tags]{
mutate{
remove_tag => ["beats_input_codec_plain_applied"] #删除beats_input_codec_plain_applied的tags
}
}
}
#输出到es
output {
if "workflow2" in [tags] { #tags是在filebeat客户端设置的
elasticsearch {
hosts => ["http://10.10.201.76:9200","http://10.10.201.77:9200","http://10.10.201.78:9200"] #输出的3台es集群
index => "workflow2-%{+YYYY.MM.dd}" #index名
user => "elastic" #es的用户名密码
password => "2GyYwGHHHMA7udFTozo4"
}
} else if "simpleworkflow" in [tags] {
elasticsearch {
hosts => ["http://10.10.201.76:9200","http://10.10.201.77:9200","http://10.10.201.78:9200"]
index => "simpleworkflow-%{+YYYY.MM.dd}"
user => "elastic"
password => "2GyYwGHHHMA7udFTozo4"
}
}
stdout { codec => json_lines }
}
注意的是:这边可以创建多个conf文件,每个文件的端口号必须不一致。
启动logstash:
[root@shtw-logstash01 ~]# systemctl start logstash
七、安装filebeat
在需要采集日志的地方安装filebeat
1、安装filebeta
[root@shtw-k2workflow01 ~]# rpm -ivh filebeat-6.8.0-x86_64.rpm
2、配置filebeat
[root@shtw-k2workflow01 ~]# cd /etc/filebeat
[root@shtw-k2workflow01 filebeat]# cp filebeat.yml filebeat.yml-bak
[root@shtw-k2workflow01 filebeat]# vim filebeat.yml
filebeat.inputs:
- type: log
enabled: true #默认是false,要改成true的,不然的话,采集不到日志
paths:
- /usr/local/tomcat/logs/catalina.out #日志的路径
#- /var/log/*.log
#- c:\programdata\elasticsearch\logs\*
filebeat.config.modules:
path: ${path.config}/modules.d/*.yml
reload.enabled: false
setup.template.settings:
index.number_of_shards: 3
# 用于在logstash中的output中做判断,不然采集的日志都输出到一起去了
tags: ["workflow2"]
setup.kibana:
output.logstash:
# The Logstash hosts
hosts: ["10.10.201.82:5044"] #传送到logstash的主机,并且对应端口号
processors:
- add_host_metadata: ~
- add_cloud_metadata: ~
3、启动filebeat
[root@shtw-k2workflow01 filebeat]# systemctl start filebeat
等5s中去kibana中去查看索引,如图:
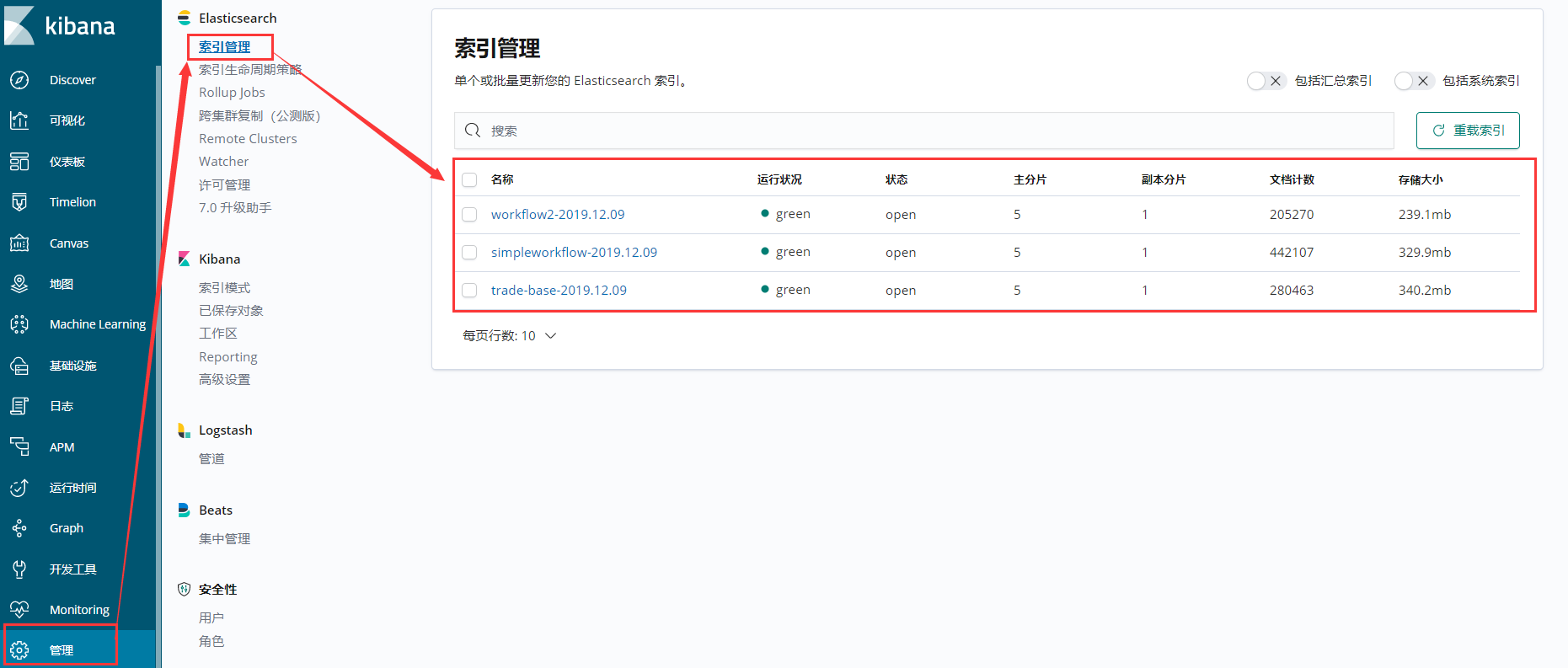
4、创建索引
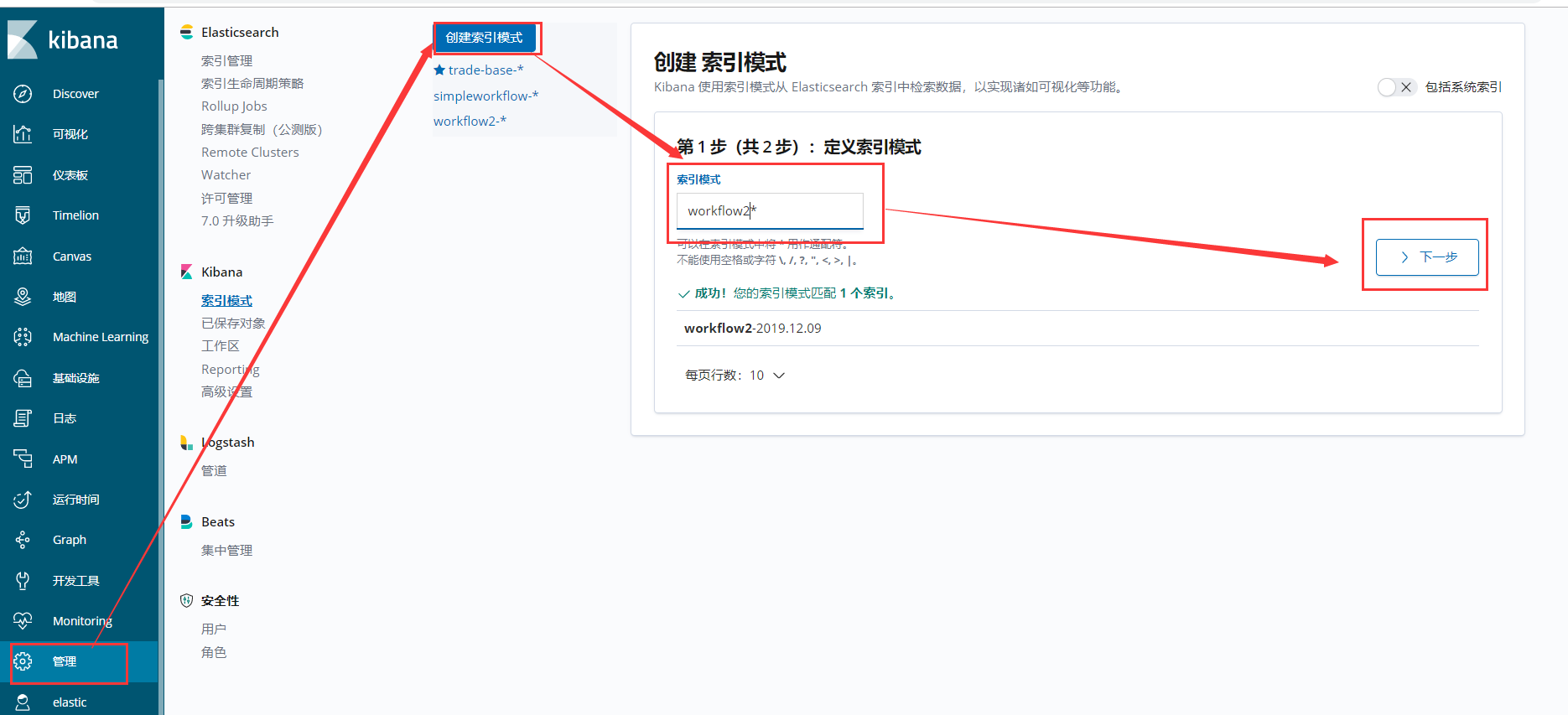
5、查看采集的日志

搭建完毕,elk的路还是很长的,才走完万里长征第一步。
