
DS博客作业04--图
0.PTA得分截图

1.本周学习总结(0-5分)
1.1 总结图内容
- 图形逻辑结构
结构特点:多对多
图:顶点集 V 和顶点间的关系:边集合E组成的数据结构。
图的逻辑结构描述:Graph = (V , E)
比如:
G=(V1,E1)
V1={A, B, C, D, E}
E1=
图分为有向图和无向图两种
-
有向图:有向图称由顶点集和弧集构成的图。“弧”是有方向的边。
比如:
![]()
-
无向图:没方向的边,也可以理解为双方向的边。
比如:
![]()
-
图的基本术语
1、 端点和邻接点
无向图:若存在一条边(i,j),则称顶点i和顶点j互为邻接点。
有向图:存在一条边<i,j>,则称此边是顶点i的一条出边,同时也是顶点j的一条入边;称顶点i 和顶点j 互为邻接点。

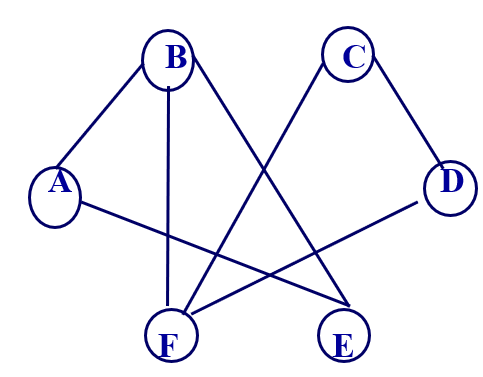
2、顶点的度、入度和出度
无向图:以顶点i为端点的边数称为该顶点的度。
比如下图:
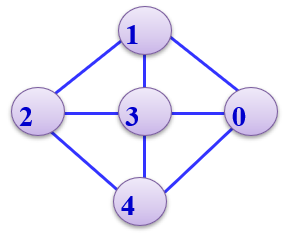
顶点0的度为3,顶点1的度为3,顶点2的度为3,顶点3的度为4,顶点4的度为3
有向图:以顶点i为终点的入边的数目,称为该顶点的入度。以顶点i为始点的出边的数目,称为该顶点的出度。一个顶点的入度与出度的和为该顶点的度。
比如下图:
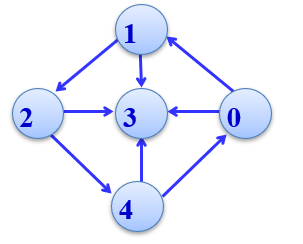
顶点0的入度为1,出度为2,顶点0的度为1+2=3。
顶点1的入度为1,出度为2,顶点0的度为1+2=3。
顶点2、顶点4同理。
而顶点3的入度为4,出度为0,顶点0的度为4+0=4。
3、完全图
无向图:每两个顶点之间都存在着一条边,称为完全无向图, 包含有n(n-1)/2条边。
有向图:每两个顶点之间都存在着方向相反的两条边,称为完全有向图,包含有n(n-1)条边。
比如:

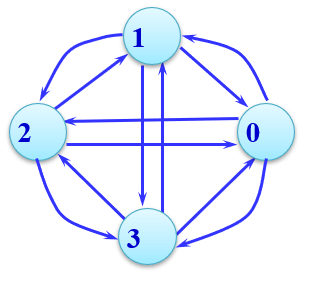
4、稠密图、稀疏图
当一个图接近完全图时,则称为稠密图。相反,当一个图含有较少的边数(即当e<<n(n-1))时,则称为稀疏图。
5、子图
子图定义:设有两个图G=(V,E)和G'=(V',E'),若V'是V的子集,即V'V,且E'是E的子集,即E'E,则称G'是G的子图。
- 路径和路径长度
从顶点i到顶点j的一条路径是一个顶点序列(i,i1,i2,…,im,j),序列中边(i,i1),(i1,i2),…,(im-1,im),(im,j)属于E(G);
路径长度是指一条路径上经过的边的数目。
简单路径:一条路径上除开始点和结束点可以相同外,其余顶点均不相同。
7、 回路或环
定义:一条路径上的开始点与结束点为同一个顶点。
简单回路或简单环:开始点与结束点相同的简单路径。
8、连通、连通图和连通分量
①无向图
若从顶点i到顶点j有路径,则称顶点i和j是连通的。
连通图:图中任意两个顶点都连通,否则称为非连通图。
连通分量:无向图G中的极大连通子图。
任何连通图的连通分量只有一个,即本身
而非连通图有多个连通分量。
②有向图
若任意两个顶点之间都存在一条有向路径,则称此有向图为强连通图。
否则,其各个强连通子图称作它的强连通分量。
9、权和网
1、图中每一条边都可以附有一个对应的数值,这种与边相关的数值称为权。
2、边上带有权的图称为带权图,也称作网。
- 图存储结构
图的两种主要存储结构:邻接矩阵、邻接表- 图的存储结构:二维数组
邻接矩阵存储表示:
1.顶点信息:记录各个顶点信息的顶点表。
2.边或弧信息:各个顶点之间关系的邻接矩阵。
设图 A = (V, E)是一个有 n 个顶点的图
A.Vex[n]:表示顶点信息集
二维数组 A.edge[n][n]表示边的关系
- 图的存储结构:二维数组

图的邻接矩阵存储类型定义如下:
#define MAXV <最大顶点个数>
typedef struct
{ int no; //顶点编号
InfoType info; //顶点其他信息
} VertexType;
typedef struct //图的定义
{ int edges[MAXV][MAXV]; //邻接矩阵
int n,e; //顶点数,边数
VertexType vexs[MAXV]; //存放顶点信息
} MatGraph;
MatGraph G;//声明邻接矩阵存储的图
无向图建立的邻接矩阵是对称,而有向图建立的邻接矩阵可能是不对称的。
邻接矩阵的主要特点:
1、一个图的邻接矩阵表示是唯一的。
2、特别适合于稠密图的存储。
(邻接矩阵的存储空间为O(n2))
- 创建图(有向图)
void CreateAdj(AdjGraph &G,int n,int e) //创建图邻接矩阵
{
int a,b,info;
int i;
cin>>G.n>>G.e;
for (i = 0; i <= G.n; i++)//图的初始化
{
for (j = 0; j <= G.n; j++)
{
if (i == j)
{
G.edges[i][j] = 0;
}
else
{
G.edges[i][j] = INF;
}
}
}
for(i=0;i<e;i++)
{
G.edges[a][b]=info;
}
}
- 图的存储结构:邻接表
邻接表存储方法:对图中每个顶点i建立一个单链表,将顶点i的所有邻接点链起来。每个单链表上添加一个表头结点(表示顶点信息)。并将所有表头结点构成一个数组,下标为i的元素表示顶点i的表头结点。
(图的邻接表存储方法是一种顺序分配与链式分配相结合的存储方法。)
图的邻接表存储类型定义如下:
typedef struct Vnode
{ Vertex data; //顶点信息
ArcNode *firstarc; //指向第一条边
} VNode;
typedef struct ANode
{ int adjvex; //该边的终点编号
struct ANode *nextarc; //指向下一条边的指针
InfoType info; //该边的权值等信息
} ArcNode;
typedef struct
{ VNode adjlist[MAXV] ; //邻接表
int n,e; //图中顶点数n和边数e
} AdjGraph;
AdjGraph *G;//声明一个邻接表存储的图G
- 创建图(有向图)
void CreateAdj(AdjGraph *&G,int n,int e) //创建图邻接表
{
int i,j,a,b;
ArcNode *p;
G=new AdjGraph;
for (i=0;i<n;i++)
G->adjlist[i].firstarc=NULL;//给邻接表中所有头结点的指针域置初值
for (i=1;i<=e;i++) //根据输入边建图
{ cin>>a>>b;
p=new ArcNode; //创建一个结点p
p->adjvex=b; //存放邻接点
p->nextarc=G->adjlist[a].firstarc; //采用头插法插入结点p
G->adjlist[a].firstarc=p;
}
G->n=n; G->e=n;
}
- 图遍历及应用。
-
图的遍历的概念:从给定图中任意指定的顶点(称为初始点)出发,按照某种搜索方法沿着图的边访问图中的所有顶点,使每个顶点仅被访问一次。
-
深度优先搜索遍历DFS
过程:
(1)从图中某个初始顶点v出发,首先访问初始顶点v。
(2)选择一个与顶点v相邻且没被访问过的顶点w为初始顶点,再从w出发进行深度优先搜索,直到图中与当前顶点v邻接的所有顶点都被访问过为止。
比如:
-
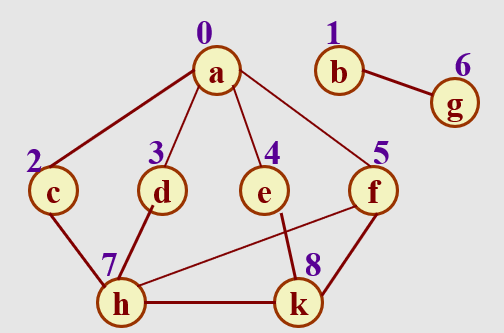
DFS遍历:a c h d k f e b g
代码描述:
void DFS(ALGraph *G,int v) //邻接表
{ ArcNode *p;
visited[v]=1; //置已访问标记
printf("%d ",v); //对结点v的某种操作,比如输出
p=G->adjlist[v].firstarc;
while (p!=NULL)
{
if (visited[p->adjvex]==0) DFS(G,p->adjvex);
p=p->nextarc;
}
}
void DFS(ALGraph* G, int v) //邻接矩阵
{
int i;
visited[v] = 1; //置已访问标记
printf("%d ", v); //对结点v的某种操作,比如输出
for (i = 0; i < G.n; i++)
{
if (!visited[i] && G.edges[v][i] == 1)
DFS(G, i);
}
}
邻接表遍历时间复杂度为O(n+e),邻接矩阵遍历时间复杂度为O(n^2)。
上述代码无法解决非连通图的遍历。
非连通图的深度优先搜索遍历:
思路:将每一个结点置为未访问,然后循环遍历图中每个顶点,如果未被访问,则以该顶点为起始点,进行深度优先搜索遍历,否则继续检查下一顶点。
代码描述:
void DFSTraverse(Graph G) {
// 对非连通图 G 作深度优先遍历。
for (v=0; v<G.vexnum; ++v)
visited[v] = 0; // 访问标志数组初始化
for (v=0; v<G.vexnum; ++v)
if (!visited[v]) DFS(G,v); // 对尚未访问的顶点调用DFS
}
- 广度优先搜索遍历(BFS)
广度优先搜索遍历的过程是:
(1)访问初始点v,接着访问v的所有未被访问过的邻接点。
(2)按照次序访问每一个顶点的所有未被访问过的邻接点。
(3)依次类推,直到图中所有顶点都被访问过为止。
(类似树的层次遍历:队列)
比如:
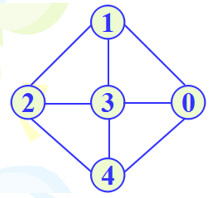
BFS:1 2 3 0 4
BFS伪代码描述:
建一个访问队列q
访问v节点,加入队列q
while(队列不空)
取队头元素w
遍历w的邻接表
取邻接点j
若j未被访问,则加入队列q,并访问j。
end while
非连通图遍历算法:
void BFS1(AdjGraph *G)
{ int i;
for (i=0;i<G->n;i++) //遍历所有未访问过的顶点
if (visited[i]==0)
BFS(G,i);
}
- 如何判断图是否连通
若是要判断是否是非连通图,则在执行DFS函数之后,遍历visited[]数组,若有visited[i]为0,即i结点没有被访问到,则说明图不连通。
判断无向图G是否连通的算法如下:
int visited[MAXV];
bool Connect(AdjGraph *G) //判断无向图G的连通性
{ int i;
bool flag=true;
for (i=0;i<G->n;i++) //visited数组置初值
visited[i]=0;
DFS(G,0); //调用前面的中DSF算法,从顶点0开始深度优先遍历
for (i=0;i<G->n;i++)
if (visited[i]==0)
{ flag=false;
break;
}
return flag;
}
- 判断顶点u,v是否有简单路径
假设图G采用邻接表存储,设计一个算法,判断顶点u,v是否有简单路径。
void ExistPath(AGraph *G,int u,int v,bool &has)
{ //has表示u到v是否有路径,初值为false
int w; ArcNode *p;
visited[u]=1; //置已访问标记
if (u==v) //找到了一条路径
{
has=true; //置has为true并结束算法
return;
}
p=G->adjlist[u].firstarc; //p指向顶点u的第一个相邻点
while (p!=NULL)
{ w=p->adjvex; //w为顶点u的相邻顶点
if (visited[w]==0) //若w顶点未访问,递归访问它
ExistPath(G,w,v,has);
p=p->nextarc; //p指向顶点u的下一个相邻点
}
}
- 如何查找图路径
假设图G采用邻接表存储,设计一个算法输出图G中从顶点u v的一条简单路径(假设图G中从顶点u v至少有一条简单路径)。
求解思路
1、采用深度优先遍历的方法。
2、增加path[i],存放路径。
3、递归函数添加形参d,表示目前递归深度。path[d]=图结点
4、当从顶点u遍历到顶点v后,输出path并返回。
void FindaPath(AGraph *G,int u,int v,int path[],int d)
{ //d表示path中的路径长度,初始为-1
int w,i; ArcNode *p;
visited[u]=1;
d++; path[d]=u; //路径长度d增1,顶点u加入到路径中
if (u==v) //找到一条路径后输出并返回
{ printf("一条简单路径为:");
for (i=0;i<=d;i++) printf("%d ",path[i]);
printf("\n");
return; //找到一条路径后返回
}
p=G->adjlist[u].firstarc; //p指向顶点u的第一个相邻点
while (p!=NULL)
{ w=p->adjvex; //相邻点的编号为w
if (visited[w]==0)
FindaPath(G,w,v,path,d);
p=p->nextarc; //p指向顶点u的下一个相邻点
}
}
- 最小生成树相关算法及应用
生成最小生成树有两种算法:普里姆算法和克鲁斯卡尔算法。- 生成树的概念:一个连通图的生成树是一个极小连通子图,它含有图中全部n个顶点和构成一棵树的(n-1)条边。不能回路。
比如:
- 生成树的概念:一个连通图的生成树是一个极小连通子图,它含有图中全部n个顶点和构成一棵树的(n-1)条边。不能回路。

-
最小生成树的概念
对于带权连通图G ,n个顶点,n-1条边
根据深度遍历或广度遍历生成生成树,树不唯一
其中权值之和最小的生成树称为图的最小生成树。 -
普里姆算法
过程:
(1)初始化U={v}。v到其他顶点的所有边为候选边;
(2)重复以下步骤n-1次,使得其他n-1个顶点被加入到U中:
① 从候选边中挑选权值最小的边输出,设该边在V-U中的顶点是k,将k加入U中;
②考察当前V-U中的所有顶点j,修改候选边:若(j,k)的权值小于原来和顶点k关联的候选边,则用(k,j)取代后者作为候选边。
设置2个辅助数组。
1.closest[i]:最小生成树的边依附在U中顶点编号。
2.lowcost[i]表示顶点i(i ∈ V-U)到U中顶点的边权重,取最小权重的顶点k加入U。并规定lowcost[k]=0表示这个顶点在U中
3.(closest[k],k)构造最小生成树一条边。
伪代码描述:
初始化lowcost,closest数组
for(v=1;v<=n;v++)
遍历lowcost数组 //选最小边
若lowcost[i]!=0,找最小边
找最小边对应邻接点k
最小边lowcost[k]=0;
输出边(closest[k],k);
遍历lowcost数组 //修正lowcost
若lowcost[i]!=0 && edges[i][k]<lowcost[k]
修正lowcost[k]=edges[i][k]
修正closest[j]=k;
end
具体代码:
#define INF 32767 //INF表示∞
void Prim(MGraph g, int v)
{
int lowcost[MAXV], min, closest[MAXV], i, j, k;
for (i = 0; i < g.n; i++) //给lowcost[]和closest[]置初值
{
lowcost[i] = g.edges[v][i]; closest[i] = v;
}
for (i = 1; i < g.n; i++) //找出(n-1)个顶点
{
min = INF;
for (j = 0; j < g.n; j++) // 在(V-U)中找出离U最近的顶点k
if (lowcost[j] != 0 && lowcost[j] < min)
{
min = lowcost[j]; k = j; / k记录最近顶点的编号
}
printf(" 边(%d,%d)权为:%d\n", closest[k], k, min);
lowcost[k] = 0; //标记k已经加入U
for (j = 0; j < g.n; j++) //修改数组lowcost和closest
if (lowcost[j] != 0 && g.edges[k][j] < lowcost[j])
{
lowcost[j] = g.edges[k][j];
closest[j] = k;
}
}
}
时间复杂度为O(n^2)。
- 克鲁斯卡尔算法
是一种按权值的递增次序选择合适的边来构造最小生成树的方法。
算法过程:
(1)置U的初值等于V(即包含有G中的全部顶点),TE的初值为空集(即图T中每一个顶点都构成一个连通分量)。
(2)将图G中的边按权值从小到大的顺序依次选取:
① 若选取的边未使生成树T形成回路,则加入TE;
②否则舍弃,直到TE中包含(n-1)条边为止。
代码描述:
void Kruskal(AdjGraph* g)
{
int i,j,u1,v1,sn1,sn2,k;
int vset[MAXV]; //集合辅助数组
Edge E[MaxSize]; //存放所有边
k = 0; //E数组的下标从0开始计
for (i = 0; i < g.n; i++) //由g产生的边集E,邻接表
{
p = g->adjlist[i].firstarc;
while (p != NULL)
{
E[k].u = i; E[k].v = p->adjvex;
E[k].w = p->weight;
k++; p = p->nextarc;
}
}
Sort(E,g.e); //用快排对E数组按权值递增排序
for (i = 0; i < g.n; i++) //初始化集合
vset[i] = i;
k = 1; //k表示当前构造生成树的第几条边,初值为1
j = 0; //E中边的下标,初值为0
while (k < g.n) //生成的顶点数小于n时循环
{
u1 = E[j].u; v1 = E[j].v; //取一条边的头尾顶点
sn1 = vset[u1];
sn2 = vset[v1]; //分别得到两个顶点所属的集合编号
if (sn1 != sn2) //两顶点属于不同的集合
{
printf(" (%d,%d):%d\n",u1,v1,E[j].w);
k++; //生成边数增1
for (i = 0; i < g.n; i++) //两个集合统一编号
if (vset[i] == sn2) //集合编号为sn2的改为sn1
vset[i] = sn1;
}
j++; //扫描下一条边
}
}
-
最短路径相关算法及应用。
两种常见的最短路径问题:
一、 单源最短路径—用Dijkstra(迪杰斯特拉)算法(一顶点到其余各顶点)
二、所有顶点间的最短路径—用Floyd(弗洛伊德)算法(任意两顶点之间)- Dijkstra算法
过程:
0.初始化
S={入选顶点集合,初值V0},T={未选顶点集合}。
若存在<V0,Vi>,距离值为<V0,Vi>弧上的权值
若不存在<V0,Vi>,距离值为∞
从T中选取一个其距离值为最小的顶点W, 加入S
1.从T中选取一个其距离值为最小的顶点W, 加入S
2.S中加入顶点w后,对T中顶点的距离值进行修改:
若加进W作中间顶点,从V0到Vj的距离值比不加W的路径要短,则修改此距离值;
3.重复上述步骤1,直到S中包含所有顶点,即S=V为止。
(采用一维数组path来保存最短路径)
- Dijkstra算法
伪代码描述:
遍历图中所有节点
{
for(i=0;i<g.n;i++) //找最短dist
{
若s[i]!=0,则dist数组找最短路径,顶点为u
}
s[u]=1 //加入集合S,顶点已选
for(i=0;i<g.n;i++) //修正dist
{
若s[i]!=0 && dist[i]>dist[u]+g.edges[u][i]
则修正dist[i]= dist[i]>dist[u]+g.edges[u][i]
path[i]=u;
}
}
具体代码:
void Dijkstra(MatGraph g,int v)
{
int dist[MAXV],path[MAXV];
int s[MAXV];
int mindis, i, j, u;
for (i = 0; i < g.n; i++)
{
dist[i] = g.edges[v][i]; //距离初始化
s[i] = 0; //s[]置空
if (g.edges[v][i] < INF) //路径初始化
path[i] = v; //顶点v到i有边时
else
path[i] = -1; //顶点v到i没边时
}
s[v] = 1; //源点v放入S中
for (i = 0; i < g.n; i++) //循环n-1次
{
mindis = INF;
for (j = 0; j < g.n; j++)
if (s[j] == 0 && dist[j] < mindis)
{
u = j;
mindis = dist[j];
}
s[u] = 1; //顶点u加入S中
for (j = 0; j < g.n; j++) //修改不在s中的顶点的距离
if (s[j] == 0)
if (g.edges[u][j] < INF && dist[u] + g.edges[u][j] < dist[j])
{
dist[j] = dist[u] + g.edges[u][j];
path[j] = u;
}
}
Dispath(dist, path, s, g.n, v); //输出最短路径
}
Dijkstra算法特点
1、不适用带负权值的带权图求单源最短路径。
2、不适用求最长路径长度。
图存储结构:邻接矩阵存储
数组dist[]:源点V0到每个终点的最短路径长度。
- Floyd算法
思路:
有向图G=(V,E)采用邻接矩阵存储
二维数组A用于存放当前顶点之间的最短路径长度,分量A[i][j]表示当前顶点i到顶点j的最短路径长度。
递推产生一个矩阵序列A0,A1,…,Ak,…,An-1,Ak+1[i][j]表示从顶点i到顶点j的路径上所经过的顶点编号k+1的最短路径长度。
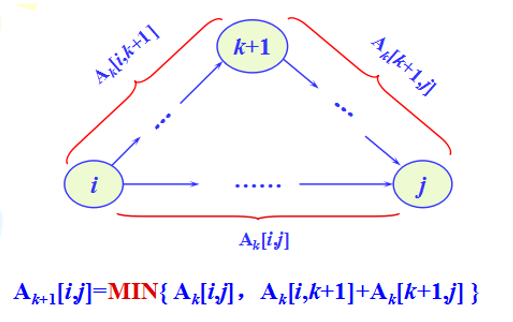
Ak[i,j]=MIN{ Ak-1[i,j],Ak-1[i,k]+Ak-1[k,j] }
上代码:
void Floyd(MatGraph g) //求每对顶点之间的最短路径
{ int A[MAXVEX][MAXVEX]; //建立A数组
int path[MAXVEX][MAXVEX]; //建立path数组
int i, j, k;
for (i=0;i<g.n;i++)
for (j=0;j<g.n;j++)
{ A[i][j]=g.edges[i][j];
if (i!=j && g.edges[i][j]<INF)
path[i][j]=i; //i和j顶点之间有一条边时
else //i和j顶点之间没有一条边时
path[i][j]=-1;
}
for (k=0;k<g.n;k++) //求Ak[i][j]
{ for (i=0;i<g.n;i++)
for (j=0;j<g.n;j++)
if (A[i][j]>A[i][k]+A[k][j]) //找到更短路径
{ A[i][j]=A[i][k]+A[k][j]; //修改路径长度
path[i][j]=k; //修改经过顶点k
}
}
}
求任意两顶点之间的最短路径:
1、调用n次Dijkstra(迪杰斯特拉)算法
2、Floyd(弗洛伊德)算法
时间复杂度均为O(n^3)。
- 拓扑排序、关键路径
- 拓扑排序
在一个有向图中找一个拓扑序列的过程称为拓扑排序。
序列必须满足条件:
1、每个顶点出现且只出现一次。
2、若存在一条从顶点 A 到顶点 B 的路径,那么在序列中顶点 A 出现在顶点 B 的前面。
- 拓扑排序
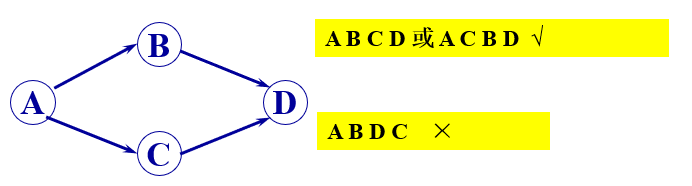
例子:
如图:
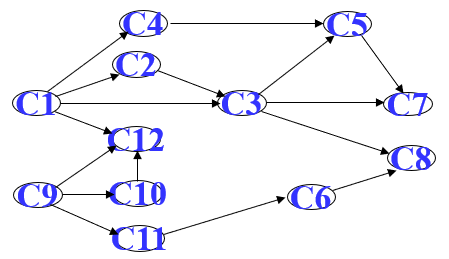
拓扑序列:C1--C2--C3--C4--C5--C7--C9--C10--C11--C6--C12--C8
或C9--C10--C11--C6--C1--C12--C4--C2--C3--C5--C7--C8
特点:
图中有回路,无法拓扑排序
拓扑排序可以用来检测图中是否有回路
那么如何进行拓扑排序呢?
1.从有向图中选取一个没有前驱的顶点,并输出之;
2.从有向图中删去此顶点以及所有以它为尾的弧;
3.重复上述两步,直至图空,或者图不空但找不到无前驱的顶点为止。
ps:一个AOV-网的拓扑序列不是唯一的
头结点结构体(多了一个count):
typedef struct //表头节点类型
{ vertex data; //顶点信息
int count; //存放顶点入度
ArcNode *firstarc; //指向第一条弧
} VNode;
伪代码描述:
遍历邻接表
计算每个顶点的入度,存入头结点count成员
遍历图顶点
若发现入度为0顶点,入栈st
while(栈不空)
{
出栈节点v,访问。
遍历v的所有邻接点
{ 所有邻接点的入度-1
若有邻接点入度为0,则入栈st
}
}
具体代码:
void TopSort(AdjGraph *G) //拓扑排序算法
{ int i,j;
int St[MAXV],top=-1; //栈St的指针为top
ArcNode *p;
for (i=0;i<G->n;i++) //入度置初值0
G->adjlist[i].count=0;
for (i=0;i<G->n;i++) //求所有顶点的入度
{ p=G->adjlist[i].firstarc;
while (p!=NULL)
{ G->adjlist[p->adjvex].count++;
p=p->nextarc;
}
}
for (i=0;i<G->n;i++) //将入度为0的顶点进栈
if (G->adjlist[i].count==0)
{ top++;
St[top]=i;
}
while (top>-1) //栈不空循环
{ i=St[top];top--; //出栈一个顶点i
printf("%d ",i); //输出该顶点
p=G->adjlist[i].firstarc; //找第一个邻接点
while (p!=NULL) //将顶点i的出边邻接点的入度减1
{ j=p->adjvex;
G->adjlist[j].count--;
if (G->adjlist[j].count==0) //将入度为0的邻接点进栈
{ top++;
St[top]=j;
}
p=p->nextarc; //找下一个邻接点
}
}
}
- 关键路径
整个工程完成的时间为:从有向图的源点到汇点的最长路径。又叫关键路径。
关键路径为源点到汇点的最长路径,这样转变为查找图中最长路径问题。
求关键路径的过程
1.事件的最早开始和最迟开始时间
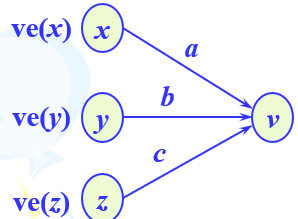
事件v最早开始时间ve(v):v作为源点事件最早开始时间为0。
ve(v)=0 当v为初始源点时
ve(v)=MAX{ve(x)+a,ve(y)+b,ve(z)+c} 否则
(v为源点事件最早开始时间一定是前驱事件x,y,z已完成)
如图:
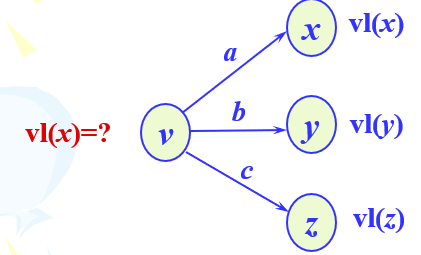
2、事件v的最迟开始时间vl(v):定义在不影响整个工程进度的前提下,事件v必须发生的时间称为v的最迟开始时间。
vl(v)=ve(v) 当v为终点时
vl(v)=MIN{vl(x)-a,vl(y)-b,vl(z)-c} 否则
(最迟时间要保证后继事件能完成,取最小)
如图:
- 求关键路径步骤
1.对有向图拓扑排序
2.根据拓扑序列计算事件(顶点)的ve,vl数组
ve(j) = Max{ve(i) + dut(<i,j>)}
vl(i) = Min{vl(j) - dut(<i,j>)}
3.计算关键活动的e[],l[]。即边的最早、最迟时间
e(i) = ve(j)
l(i) = vl(k) - dut(<j, k>
4.找e=l边即为关键活动
5.关键活动连接起来就是关键路径
1.2.谈谈你对图的认识及学习体会。
2.阅读代码(0--5分)
2.1 题目及解题代码
- 题目:

- 解题代码:
class Solution {
public:
vector<int> findRedundantConnection(vector<vector<int>>& edges) {
vector<int> rp(1001);
int sz = edges.size();
// 初始化各元素为单独的集合,代表节点就是其本身
for(int i=0;i<sz;i++)
rp[i] = i;
for(int j=0;j<sz;j++){
// 找到边上两个节点所在集合的代表节点
int set1 = find(edges[j][0], rp);
int set2 = find(edges[j][1], rp);
if(set1 == set2) // 两个集合代表节点相同,说明出现环,返回答案
return edges[j];
else // 两个集合独立,合并集合。将前一个集合代表节点戳到后一个集合代表节点上
rp[set1] = set2;
}
return {0, 0};
}
// 查找路径并返回代表节点,实际上就是给定当前节点,返回该节点所在集合的代表节点
// 之前这里写的压缩路径,引起歧义,因为结果没更新到vector里,所以这里改成路径查找比较合适
// 感谢各位老哥的提议
int find(int n, vector<int> &rp){
int num = n;
while(rp[num] != num)
num = rp[num];
return num;
}
};
/*
作者:Zhcode
链接:https://leetcode-cn.com/problems/redundant-connection/solution/tong-su-jiang-jie-bing-cha-ji-bang-zhu-xiao-bai-ku/
来源:力扣(LeetCode)
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
*/
2.1.1 该题的设计思路
采用并查集解法
我们以这个边集合为例子[[1,2], [3,4], [3,2], [1,4], [1,5]]讲解
一、首先,对于边集合edges的每个元素,我们将其看作两个节点集合
比如边[2, 3],我们将其看作节点集合2,和节点集合3
二、在没有添加边的时候,各个节点集合独立,我们需要初始化各个节点集合的代表节点为其自身
所以,我们先初始化一个容器vector,使得vector[i]=i
这里两个i意思不同,作为索引的i是指当前节点,作为值的i是指当前节点所在集合的代表节点
比如vector[2] = 2,意味着2这个节点所在集合的代表节点就是2,没有添加边的情况下,所有节点单独成集合,自身就是代表节点
初始化后,集合图如下图所示:

三、然后我们开始遍历边集合,将边转化为集合的关系
这里有一点很重要:边[a,b]意味着a所在集合可以和b所在集合合并。
合并方法很多,这里我们简单地将a集合的代表节点戳到b集合的代表节点上
这意味着,将b集合代表节点作为合并后大集合的代表节点
对于一个集合的代表节点s,一定有s->s,意思是s如果是代表节点,那么它本身不存在代表节点
假设我们的读取顺序为[[1,2], [3,4], [3,2], [1,4], [1,5]]
初始化vector[0, 1, 2, 3, 4, 5]
对应的index [0, 1, 2, 3, 4, 5]
1.读取[1,2]:
读取顺序为[[1,2], [3,4], [3,2], [1,4], [1,5]]
当前vector[0, 1, 2, 3, 4, 5]
当前index [0, 1, 2, 3, 4, 5]
原本1->1,2->2,
由1节点出发,vector[1]=1, 找到1所在集合的代表节点1
由2节点出发,vector[2]=2, 找到2所在集合的代表节点2
于是,将1的代表置为2,vector[1]=2, vector[2]=2
对应的vector[0, 2, 2, 3, 4, 5]
对应的index [0, 1, 2, 3, 4, 5]
原集合变为下图:

2.读取[3, 4]
读取顺序为[[1,2], [3,4], [3,2], [1,4], [1,5]]
当前vector[0, 2, 2, 3, 4, 5]
当前index [0, 1, 2, 3, 4, 5]
同理,将3所在集合的的代表节点3的代表节点置为4
对应的vector[0, 2, 2, 4, 4, 5]
对应的index [0, 1, 2, 3, 4, 5]
集合变化如下图:

3.读取[3, 2]
读取顺序为[[1,2], [3,4], [3,2], [1,4], [1,5]]
当前vector[0, 1, 2, 4, 4, 5]
当前index [0, 1, 2, 3, 4, 5]
从节点3出发,vector[3]=4, vector[4]=4,于是找到节点3所在集合的代表节点为4
从节点2出发,vector[2]=2, 找到节点2所在集合的代表节点为2
于是,将4的代表置为2,vector[4]=2, vector[2]=2
对应的vector[0, 2, 2, 4, 2, 5]
对应的index [0, 1, 2, 3, 4, 5]
集合变化如下图:
4.读取[1, 4]
读取顺序为[[1,2], [3,4], [3,2], [1,4], [1,5]]
当前vector[0, 2, 2, 4, 2, 5]
当前index [0, 1, 2, 3, 4, 5]
从节点1出发,vector[1]=2, vector[2]=2, 找到节点1所在集合代表节点为2
从节点4出发,vector[4]=2, vector[2]=2, 找到节点4所在集合代表节点为2
由于1和4的代表节点相同,说明这两个节点本身就在同一个集合中
由于原图是无向图,路径是双向可达的,1能够到达2,而且2能够到达4,再加上1能够到达4
说明1能通过两条路径到达4,,这也意味着这条边出现的时候,原图中一定出现了环
至于题中要求的,返回最后一条边,其实这就是返回添加过后会构成环的那一条边
直白解释就是,在这条边出现之前,图中没有环
这条边出现,图中也出现环。包括这条边在内,构成环的边都是满足破圈条件的边
然而谁是最后一条出现在边集合里的?当然,就是这条构成环的最后一条边
时间复杂度:O(n2);
空间复杂度:O(n);
2.1.2 该题的伪代码
初始化各元素为单独的集合,代表节点就是其本身
for(int i=0;i<sz;i++)rp[i] = i;
for (j=0->sz)
用find函数找到边上两个节点所在集合的代表节点set1和set2
if(set1和set2相等),即两个集合代表节点相同,说明出现环
return答案
else 两个集合独立,合并集合。将前一个集合代表节点戳到后一个集合代表节点上
rp[set1] = set2;
end for
int find函数://找n的代表结点
{
int num = n;
while(num的代表结点不是它本身)
num = num的父节点;
end while
return num;
}
2.1.3 运行结果


2.1.4分析该题目解题优势及难点。
优势:巧妙运用并查集,筛选出会形成“环”的那一条边。
难点:如果对并查集运用不熟练,会卡壳。这道题要求我们深入理解并查集。
2.2 题目及解题代码
题目:

解题代码:
class Solution {
public:
vector<int> eventualSafeNodes(vector<vector<int>>& graph) {
int n = graph.size();
vector<int> outDegree(n, 0); // 维护出度
vector<vector<int>> revGraph(n, vector<int>{});
vector<int> ans;
for (int i =0; i < n; i++){
outDegree[i] = graph[i].size();
for (auto &end : graph[i]){
revGraph[end].push_back(i);
}
}
queue<int> q;
for (int i =0; i< n ; i++){
if (outDegree[i] == 0) q.push(i);
}
while (!q.empty()){
int f = q.front();
ans.push_back(f);
q.pop();
for (auto start: revGraph[f]){
outDegree[start]--;
if (outDegree[start] == 0) q.push(start);
}
}
sort(ans.begin(), ans.end());
return ans;
}
};
2.2.1 该题的设计思路
tips:题目有说:“存在一个自然数 K, 无论选择从哪里开始行走, 我们走了不到 K 步后必能停止在一个终点。”,实际上这道题并没有给出k的值,也不对k作出要求,所以这句话可忽略掉。
解题思路
定义安全的点:路径终点,也就是出度为0的点
定义最终安全的点:从起始节点开始,可以沿某个路径到达终点,那么起始节点就是最终安全的点。
1、找到出度为0的顶点,这些点是安全的点
2、逆向删除以出度为0的顶点为弧头的边,弧尾的出度减一
3、重复上面两步,直到不存在出度为0的顶点
时间复杂度:O(n2);
空间复杂度:O(n);

 浙公网安备 33010602011771号
浙公网安备 33010602011771号