初识Elasticsearch

许多年前,一个刚结婚的名叫 Shay Banon 的失业开发者,跟着他的妻子去了伦敦,他的妻子在那里学习厨师。 在寻找一个赚钱的工作的时候,为了给他的妻子做一个食谱搜索引擎,他开始使用 Lucene 的一个早期版本。
直接使用 Lucene 是很难的,因此 Shay 开始做一个抽象层,Java 开发者使用它可以很简单的给他们的程序添加搜索功能。 他发布了他的第一个开源项目 Compass。
后来 Shay 获得了一份工作,主要是高性能,分布式环境下的内存数据网格。这个对于高性能,实时,分布式搜索引擎的需求尤为突出, 他决定重写 Compass,把它变为一个独立的服务并取名 Elasticsearch。
第一个公开版本在2010年2月发布,从此以后,Elasticsearch 已经成为了 Github 上最活跃的项目之一,他拥有超过300名 contributors(目前736名 contributors )。 一家公司已经开始围绕 Elasticsearch 提供商业服务,并开发新的特性,但是,Elasticsearch 将永远开源并对所有人可用。
据说,Shay 的妻子还在等着她的食谱搜索引擎…
Elasticsearch是Java开发的基于Lucene的搜索服务器。它提供了一个分布式多用户能力的全文搜索引擎,基于RESTful web接口。
Elasticsearch的作用:1.存放海量数据。 2.实现快速查询。 3.实现高亮查询。 4.支持模糊、精确查询。 Elasticsearch的使用场景:1.elk的日志场景。 2.业务(海量)数据的搜索。
说到Elasticsearch必须提到ELK
E:Elasticsearch 存放数据的仓库
L:LogStach 帮助我们收集各种情况下的日志(文本日志、数据库日志) 把数据写入我们的es数据库
K:Kinbana 可视化工具,可以查看报表以及通过搜索查看我们数据库所有的数据
下载地址:
Elasticsearch: https://www.elastic.co/cn/downloads/elasticsearch
Kibana: https://www.elastic.co/cn/downloads/kibana
下载完成之后双击各自bin目录下的bat文件

基本操作:
1.需要指定id PUT dbindex/userinfo/1 2.自动生成id POST dbindex/userinfo 3.代表文档的id GET dbindex/userinfo/1 4.查看所有数据 GET dbindex/userinfo/_search
5.删除索引(数据库)
DELETE dbndex

创建索引,指定数据的数据类型.如果给字段的类型是keyword类型,则相当于服务没有帮助我们去分词,相当于自己创建了一个字典。如果是text类型则会帮助我们分词。
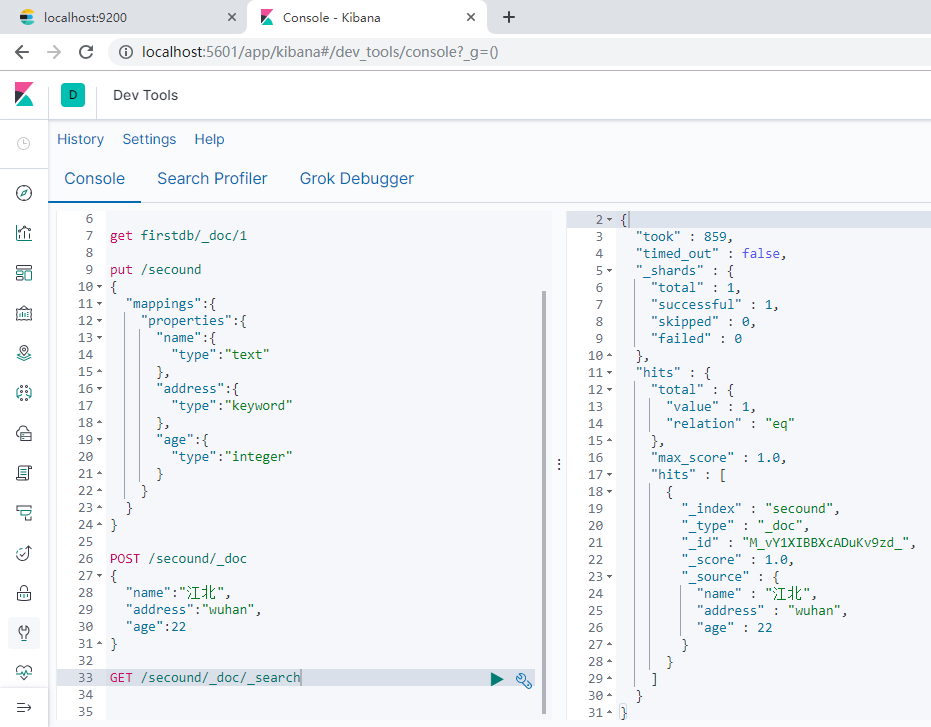
通过关键字查询数据:

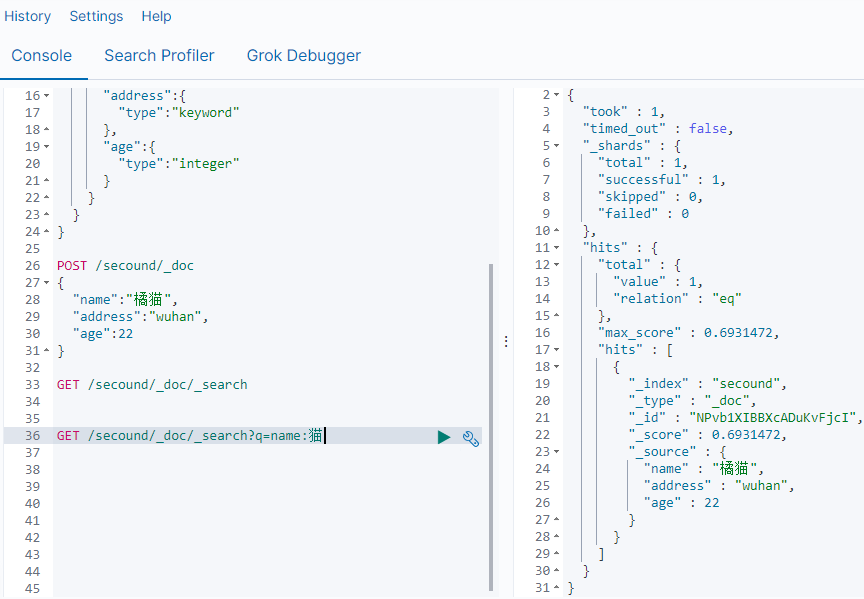
GET /secound/_doc/_search?q=name:猫
ik分词器
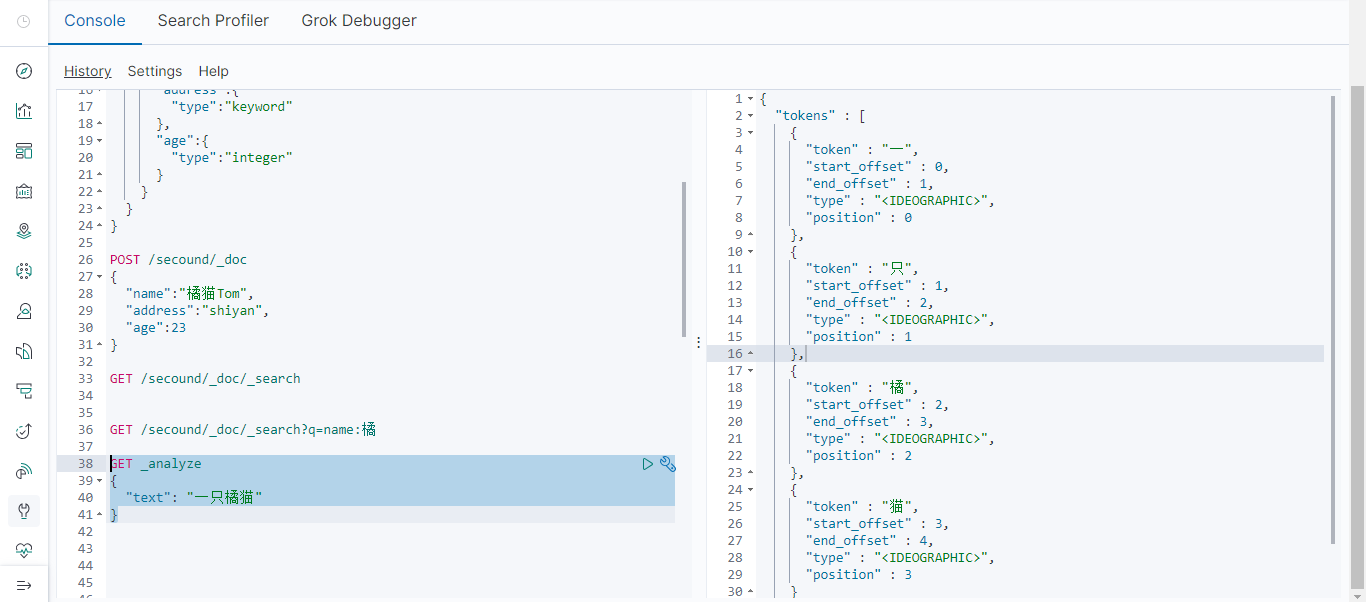
如上,elasticsearch的默认分词器无法识别中文中"一只"这样的词汇,而是简单的将每个字拆完分为一个词。我们可以使用第三方分词器达到我们想要的效果。
下载ik分词器包
解压文件,将elasticsearch-analysis-ik文件中的文件拷贝到elasticsearch文件下的plugins文件中(一定要在plugins中新建一个ik命名的文件,ik分词器的版本和elasticsearch的版本一定要一样)
建一个自定义分词的字典文件,并做好配置,然后重启elasticsearch.
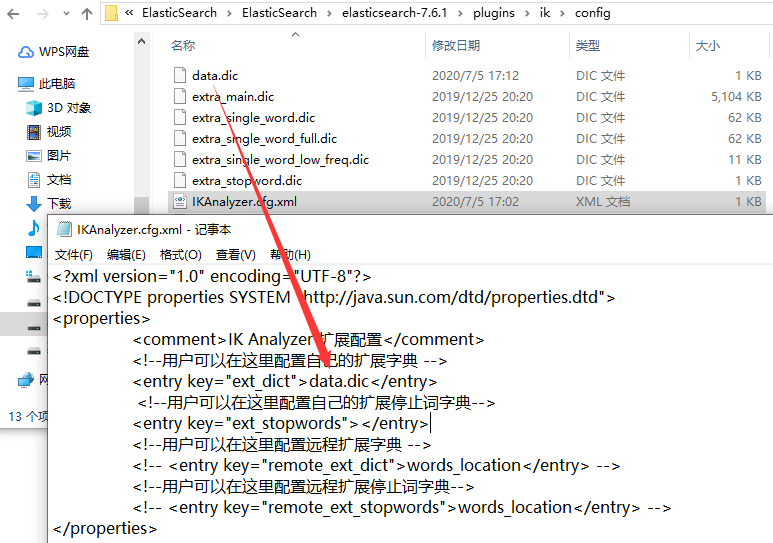
我在我的字典文件(data.dic)中写了:一只橘猫
查询:

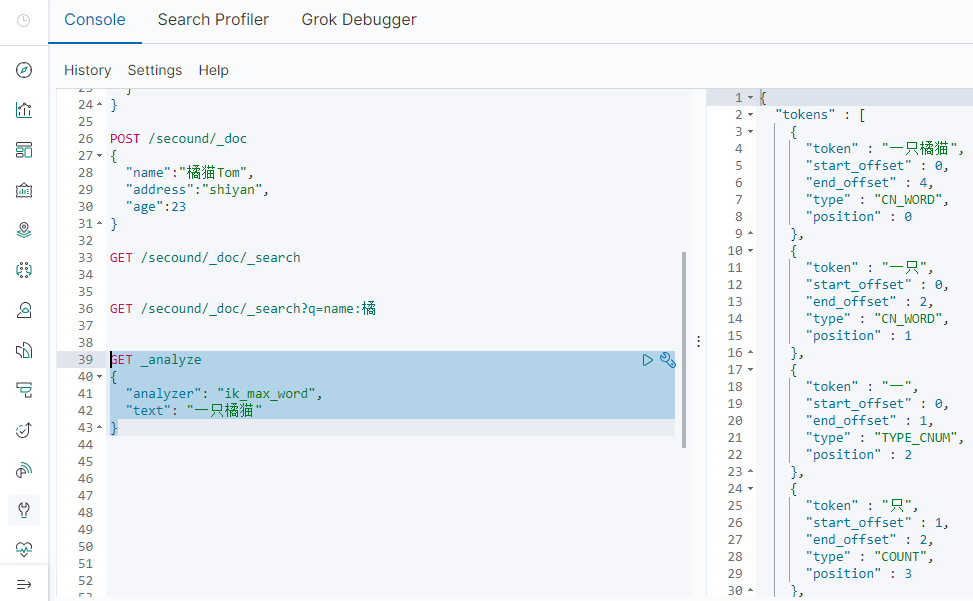
k_max_word:会将文本做最细粒度的拆分,例如「一只橘猫」会被拆分为「一只橘猫、一只、一、只、橘、猫」,会穷尽各种可能的组合
ik_smart:会将文本做最粗粒度的拆分,例如「一只橘猫」会被拆分为「一只橘猫」
有一首歌叫南方姑娘很好听,我们可以先用elasticsearch的默认分词器查查看。
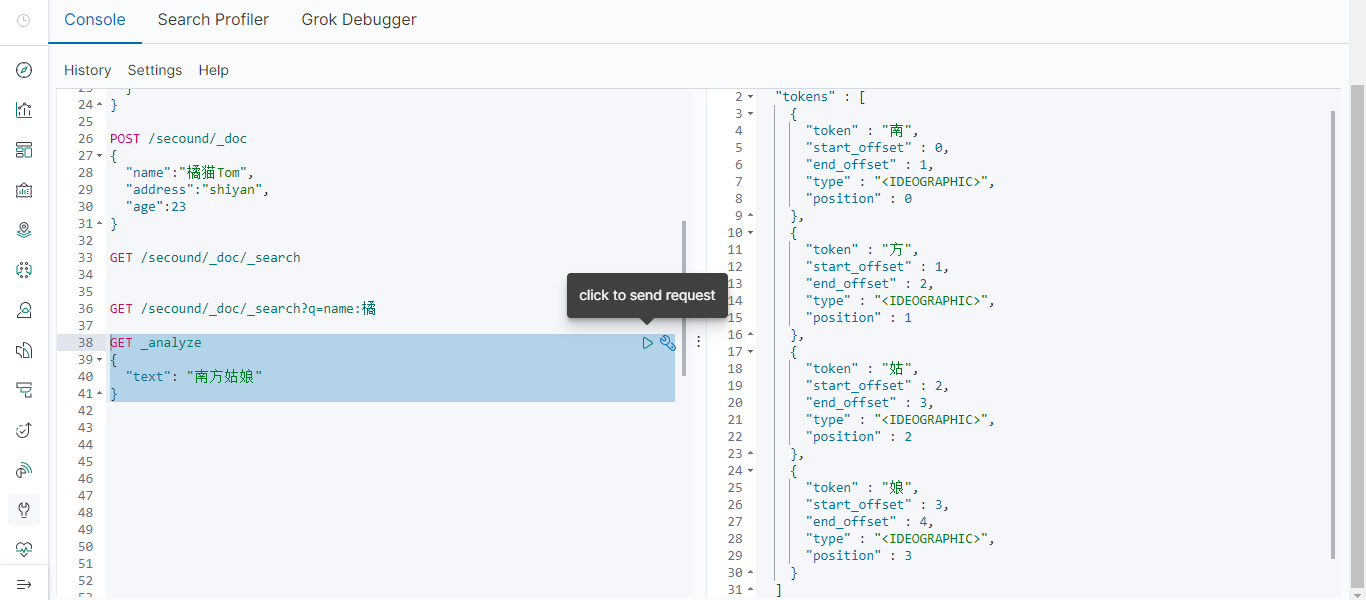
将南方姑娘加入我们自定义的分词字典文件中,再来查询:
.

elasticsearch的倒排索引
有一张表还有如下数据

首先说一下正排索引:正排索引就是我们可以根据id查询指定的数据,也可理解为通过人名(在不重复的情况下)找到指定的人。
倒排索引:如下.不同的条件查询的数据不同。
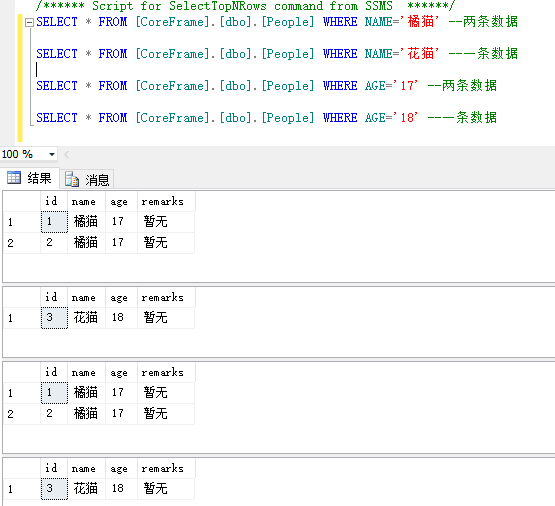
在elasticsearch中也一样,elasticsearch会建倒排索引。将每一行数据看成为一个document。每个document都有一个docid。那么给这些document建立的倒排索引就是:
姓名 [key] [value] 橘猫 [1,2] 花猫 [3] 年龄 [key] [value] 17 [1,2] 18 [3]

作者:江北
出处:https://www.cnblogs.com/zhangnever/p/13172512.html
版权:本作品采用「署名-非商业性使用-相同方式共享 4.0 国际」许可协议进行许可。
微信:CodeDoraemon




· go语言实现终端里的倒计时
· 如何编写易于单元测试的代码
· 10年+ .NET Coder 心语,封装的思维:从隐藏、稳定开始理解其本质意义
· .NET Core 中如何实现缓存的预热?
· 从 HTTP 原因短语缺失研究 HTTP/2 和 HTTP/3 的设计差异
· 分享一个免费、快速、无限量使用的满血 DeepSeek R1 模型,支持深度思考和联网搜索!
· 使用C#创建一个MCP客户端
· ollama系列1:轻松3步本地部署deepseek,普通电脑可用
· 基于 Docker 搭建 FRP 内网穿透开源项目(很简单哒)
· 按钮权限的设计及实现