多线程续集
多进程vs多线程
#分析:
我们有四个任务需要处理,处理方式肯定是要玩出并发的效果,解决方案可以是:
方案一:开启四个进程
方案二:一个进程下,开启四个线程
#多核情况下,分析结果:
如果四个任务是计算密集型,多核意味着并行计算,在python中一个进程中同一时刻只有一个线程执行用不上多核,方案一胜。
如果四个任务是I/O密集型,再多的核也解决不了I/O问题,方案二胜
#结论:现在的计算机基本上都是多核,python对于计算密集型的任务开多线程的效率并不能带来多大性能上的提升,甚至不如串行(没有大量切换),但是,对于IO密集型的任务效率还是有显著提升的。
#计算密集型 -----》推荐多进程
-多线程
四个线程每个都要做计算的时间一点也没少。
-多进程
四个进程可以实现并行的去计算,只花了一个进程计算的时间。
#io密集型 99%都在做io ----》推荐多线程
假设io要10s
-多进程
四个进程每个io 10s,开四个进程并行的拿到cpu,启动4个进程的时间(这个时间比较长)+10s+1点计算时间(忽略不计)+进程的切换(时间较久)。
启动进程时间耗的比较久,进程的切换耗时也比较久。
-多线程
四个线程每个io 10s 遇到io了切遇到io了切,启动4个线程的时间+10s+4点计算的时间(忽略不计)+线程的切换。
计算密集型测试(推荐使用多进程)
# 计算密集型
from multiprocessing import Process
from threading import Thread
import os,time
def work1():
res=0
for i in range(100000000): #1+8个0
res*=i
def work2():
res=0
for i in range(100000000):
res*=i
def work3():
res=0
for i in range(100000000):
res*=i
def work4():
res=0
for i in range(100000000):
res*=i
if __name__ == '__main__':
l=[]
# print(os.cpu_count()) #本机为4核
start=time.time()
# p1=Process(target=work1) #
# p2=Process(target=work2)
# p3=Process(target=work3)
# p4=Process(target=work4)
p1=Thread(target=work1) #
p2=Thread(target=work2)
p3=Thread(target=work3)
p4=Thread(target=work4)
p1.start()
p2.start()
p3.start()
p4.start()
p1.join()
p2.join()
p3.join()
p4.join()
stop=time.time()
print('run time is %s' %(stop-start))
#多进程 6.484470367431641
#多线程 17.391708850860596
io密集型测试(推荐使用多线程)
# IO密集型
from multiprocessing import Process
from threading import Thread
import os,time
def work1():
time.sleep(5)
def work2():
time.sleep(5)
def work3():
time.sleep(5)
def work4():
time.sleep(5)
if __name__ == '__main__':
l=[]
# print(os.cpu_count()) #本机为4核
start=time.time()
# p1=Process(target=work1) #
# p2=Process(target=work2)
# p3=Process(target=work3)
# p4=Process(target=work4)
p1=Thread(target=work1) #
p2=Thread(target=work2)
p3=Thread(target=work3)
p4=Thread(target=work4)
p1.start()
p2.start()
p3.start()
p4.start()
p1.join()
p2.join()
p3.join()
p4.join()
stop=time.time()
print('run time is %s' %(stop-start))
#多进程 5.162574291229248
#多线程 5.002141714096069
线程定时器
from threading import Timer,current_thread
def task(x):
print('%s run....' %x)
print(current_thread().name)
if __name__ == '__main__':
t=Timer(3,task,args=(10,)) # 3s后执行该线程
t.start()
print('主')
线程queue
queue队列 :使用import queue,用法与进程Queue一样
queue is especially useful in threaded programming when information must be exchanged safely between multiple threads.
- class queue.Queue(maxsize=0) #先进先出
import queue
q=queue.Queue()
q.put('first')
q.put('second')
q.put('third')
print(q.get())
print(q.get())
print(q.get())
'''
结果(先进先出):
first
second
third
'''
class queue.LifoQueue(maxsize=0) #实现堆栈的效果 先进后出
import queue
q=queue.LifoQueue()
q.put('first')
q.put('second')
q.put('third')
print(q.get())
print(q.get())
print(q.get())
'''
结果(后进先出):
third
second
first
'''
class queue.PriorityQueue(maxsize=0) #存储数据时可设置优先级的队列
import queue
q=queue.PriorityQueue()
#put进入一个元组,元组的第一个元素是优先级(通常是数字,也可以是非数字之间的比较),数字越小优先级越高
q.put((20,'a'))
q.put((10,'b'))
q.put((30,'c'))
print(q.get())
print(q.get())
print(q.get())
'''
结果(数字越小优先级越高,优先级高的优先出队):
(10, 'b')
(20, 'a')
(30, 'c')
'''
基本socket代码模板
# 服务端
import socket
server=socket.socket(socket.AF_INET,socket.SOCK_STREAM)
server.bind(('127.0.0.1',8081))
server.listen(5)
while True:
conn,addr=server.accept()
while True:
try:
msg=conn.recv(1024)
if len(msg) == 0:break
conn.send(msg.upper())
except ConnectionResetError:
print('客户端关闭了一个链接')
break
conn.close()
# 客户端
import socket
client=socket.socket(socket.AF_INET,socket.SOCK_STREAM)
client.connect(('127.0.0.1',8081))
while True:
msg=input('>>: ').strip()
if len(msg) == 0:continue
client.send(msg.encode('utf-8'))
feedback=client.recv(1024)
print(feedback.decode('utf-8'))
client.close()
思考socket服务端是io密集型程序,io密集型程序更适合使用多线程处理。
# 多线程改写socket服务端
多线程实现服务端并发
# 多线程服务端
from threading import Thread
import socket
def talk(conn):
while True:
try:
msg = conn.recv(1024)
if len(msg) == 0: break
conn.send(msg.upper())
except ConnectionResetError:
print('客户端关闭了一个链接')
break
conn.close()
def socket_server_demo():
server=socket.socket(socket.AF_INET,socket.SOCK_STREAM)
server.bind(('127.0.0.1',8081))
server.listen(5)
while True:
conn,addr=server.accept()
t= Thread(target=talk,args=(conn,))
t.start()
if __name__ == '__main__':
socket_server_demo()
# 多线程客户端
import socket
from threading import currentThread,Thread
def task():
client = socket.socket(socket.AF_INET, socket.SOCK_STREAM)
client.connect(('127.0.0.1', 8081))
while True:
msg = f'{currentThread().name}'
client.send(msg.encode('utf-8'))
feedback = client.recv(1024)
print(feedback.decode('utf-8'))
client.close()
if __name__ == '__main__':
for i in range(5):
t = Thread(target=task)
t.start()
同步异步
#所谓同步,就是在发出一个功能调用时,在没有得到结果之前,该调用就不会返回。按照这个定义,其实绝大多数函数都是同步调用。但是一般而言,我们在说同步、异步的时候,特指那些需要其他部件协作或者需要一定时间完成的任务。
#异步的概念和同步相对。当一个异步功能调用发出后,调用者不能立刻得到结果。当该异步功能完成后,通过状态、通知或回调来通知调用者。如果异步功能用状态来通知,那么调用者就需要每隔一定时间检查一次,效率就很低(有些初学多线程编程的人,总喜欢用一个循环去检查某个变量的值,这其实是一 种很严重的错误)。如果是使用通知的方式,效率则很高,因为异步功能几乎不需要做额外的操作。至于回调函数,其实和通知没太多区别。
ps:
”同步“就好比:你去外地上学(人生地不熟),突然生活费不够了;此时你决定打电话回家,通知家里转生活费过来,可是当你拨出电话时,对方一直处于待接听状态(即:打不通,联系不上),为了拿到生活费,你就不停的oncall、等待,最终可能不能及时要到生活费,导致你今天要做的事都没有完成,而白白花掉了时间。
“异步”就是:在你打完电话发现没人接听时,猜想:对方可能在忙,暂时无法接听电话,所以你发了一条短信(或者语音留言,亦或是其他的方式)通知对方后便忙其他要紧的事了;这时你就不需要持续不断的拨打电话,还可以做其他事情;待一定时间后,对方看到你的留言便回复响应你,当然对方可能转钱也可能不转钱。但是整个一天下来,你还做了很多事情。 或者说你找室友临时借了一笔钱,又开始happy的上学时光了。
进程池&线程池
前言:
'''重点掌握概念
1、什么时候用池:
池的功能是限制启动的进程数或线程数,
什么时候应该限制???
当并发的任务数远远超过了计算机的承受能力时,即无法一次性开启过多的进程数或线程数时
就应该用池的概念将开启的进程数或线程数限制在计算机可承受的范围内。
2、同步vs异步
同步、异步指的是提交任务的两种方式
同步:提交完任务后就在原地等待,直到任务运行完毕后拿到任务的返回值,再继续运行下一行代码
异步:提交完任务(可以绑定一个回调函数来实现)后根本就不在原地等待,直接运行下一行代码,等到任务有返回值后会自动触发回调函数
回调机制:任务执行中处于某种机制的情况自动触发回调函数。
'''
'''
'''
Python标准模块--concurrent.futures
https://docs.python.org/dev/library/concurrent.futures.html
#1 介绍
concurrent.futures模块提供了高度封装的异步调用接口
ThreadPoolExecutor:线程池,提供异步调用
ProcessPoolExecutor: 进程池,提供异步调用
Both implement the same interface, which is defined by the abstract Executor class.
#2 基本方法
#submit(fn, *args, **kwargs)
异步提交任务
#map(func, *iterables, timeout=None, chunksize=1)
取代for循环submit的操作
#shutdown(wait=True)
相当于进程池的pool.close()+pool.join()操作
wait=True,等待池内所有任务执行完毕回收完资源后才继续
wait=False,立即返回,并不会等待池内的任务执行完毕
但不管wait参数为何值,整个程序都会等到所有任务执行完毕
submit和map必须在shutdown之前
#result(timeout=None)
取得结果
#add_done_callback(fn)
回调函数
进程池/线程池的基本用法
from concurrent.futures import ThreadPoolExecutor,ProcessPoolExecutor
from threading import currentThread
from multiprocessing import current_process
import time,os
def task(i):
# print(f'{currentThread().name} 在运行 任务{i}')
print(f'{current_process().name} 在运行 任务{i}')
time.sleep(0.2)
return i**2
if __name__ == '__main__':
pool = ProcessPoolExecutor(4)
fu_list = []
for i in range(20):
future = pool.submit(task,i)
# print(future.result()) # 拿不到值会阻塞在这里。
fu_list.append(future)
pool.shutdown(wait=True) # 等待池内所有任务执行完毕
for i in fu_list:
print(i.result())# 拿不到值会阻塞在这里。
回调函数
from concurrent.futures import ThreadPoolExecutor,ProcessPoolExecutor
from threading import currentThread
from multiprocessing import current_process
import time,os
def task(i):
# print(f'{currentThread().name} 在运行 任务{i}')
print(f'{current_process().name} 在运行 任务{i}')
time.sleep(0.2)
return i**2
def parse(future):
# print(future.result())
# print(currentThread().name,'拿到了结果',future.result()) # 如果是线程池 执行完当前任务 负责执行回调函数的是执行任务的线程。
print(current_process().name,'拿到了结果',future.result()) # 如果是进程池 执行完当前任务 负责执行回调函数的是执行任务的是主进程
if __name__ == '__main__':
pool = ProcessPoolExecutor(4)
# pool = ThreadPoolExecutor(4)
fu_list = []
for i in range(20):
future = pool.submit(task,i)
future.add_done_callback(parse) # 绑定回调函数
# 当任务执行结束拿到返回值的时候自动触发回调函数。并且把future当做参数直接传给回调函数parse
rocky手撸系列(了解)
我们每一个请求进来的时候都开一个进程肯定不合理,那么如果每一个请求进来都是串行的,那么根本实现不了并发,所以我们假定每一个请求进来使用的是线程。
那么线程中数据互相不隔离,存在修改数据的时候数据不安全的问题 。
假定我们的需求是,每个线程都要设置值,并且该线程打印该线程修改的值。
from threading import Thread,current_thread
import time
class Foo(object):
def __init__(self):
self.name = 0
locals_values = Foo()
def func(num):
locals_values.name = num
time.sleep(2) # 取出该线程的名字
print(locals_values.name, current_thread().name)
for i in range(10):
# 设置该线程的名字
t = Thread(target=func,args=(i,),name='线程%s'%i)
t.start()
很明显阻塞了2秒的时间所有的线程都完成了修改值,而2秒后所有的线程打印出来的时候都是9了。

那我们的需求是想看到自己设置的值。
所以我们要解决这种线程不安全的问题,有如下两种解决方案。
- 方案一:是加锁
- 方案二:使用`threading.local`对象把要修改的数据复制一份,使得每个数据互不影响。
我们要实现的并发是多个请求实现并发,而不是纯粹的只是修改一个数据,所以第二种思路更适合做我们每个请求的并发,把每个请求对象的内容都复制一份让其互相不影响。
*详解:为什么不用加锁的思路?加锁的思路是多个线程要真正实现共用一个数据,并且该线程修改了数据之后会影响到其他线程,更适合类似于12306抢票的应用场景,而我们是要做请求对象的并发,想要实现的是该线程对于请求对象这部分内容有任何修改并不影响其他线程。所以使用方案二*
threading.local 模块
多个线程修改同一个数据,复制多份数据给每个线程用,为每个线程开辟一块空间进行数据存储
实例:
from threading import Thread,current_thread,local
import time
locals_values = local()
# 可以简单理解为,识别到新的线程的时候,都会开辟一片新的内存空间,相当于每个线程对该值进行了拷贝。
def func(num):
locals_values.name = num
time.sleep(2)
print(locals_values.name, current_thread().name)
for i in range(10):
t = Thread(target=func,args=(i,),name='线程%s'%i)
t.start()
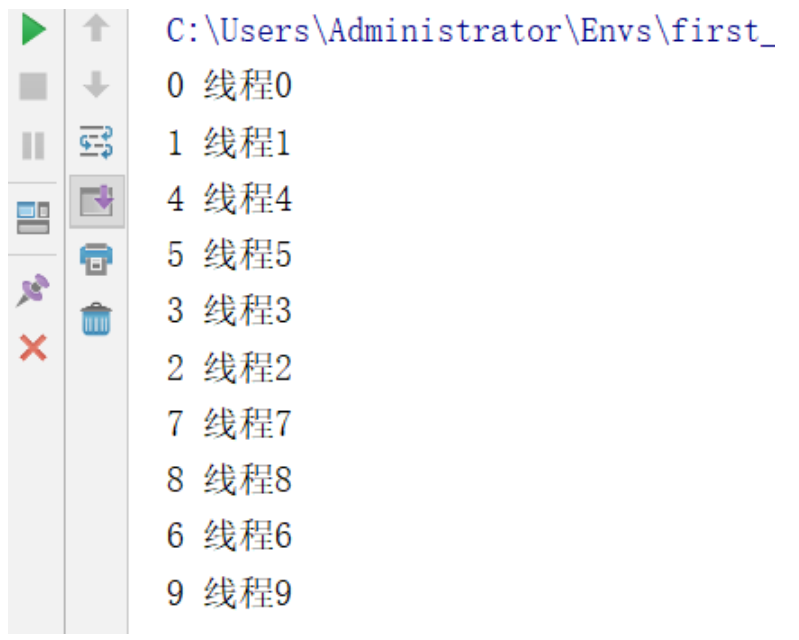
如上通过threading.local实例化的对象,实现了多线程修改同一个数据,每个线程都复制了一份数据,并且修改的也都是自己的数据。达到了我们想要的效果。
手动撸一个threading.local
实例:
from threading import get_ident,Thread,current_thread
# get_ident()可以获取每个线程的唯一标记,
import time
class Local(object):
storage = {}# 初始化一个字典
get_ident = get_ident # 拿到get_ident的地址
def set(self,k,v):
ident =self.get_ident()# 获取当前线程的唯一标记
origin = self.storage.get(ident)
if not origin:
origin={}
origin[k] = v
self.storage[ident] = origin
def get(self,k):
ident = self.get_ident() # 获取当前线程的唯一标记
v= self.storage[ident].get(k)
return v
locals_values = Local()
def func(num):
# get_ident() 获取当前线程的唯一标记
locals_values.set('KEY',num)
time.sleep(2)
print(locals_values.get('KEY'),current_thread().name)
for i in range(10):
t = Thread(target=func,args=(i,),name='线程%s'%i)
t.start()
讲解:
利用get_ident()获取每个线程的唯一标记作为键,然后组织一个字典storage。
如:{线程1的唯一标记:{k:v},线程2的唯一标记:{k:v}.......}
{
15088: {'KEY': 0},
8856: {'KEY': 1},
17052: {'KEY': 2},
8836: {'KEY': 3},
13832: {'KEY': 4},
15504: {'KEY': 5},
16588: {'KEY': 6},
5164: {'KEY': 7},
560: {'KEY': 8},
1812: {'KEY': 9}
}
运行效果:

进阶版(setattr getattr)
from threading import get_ident,Thread,current_thread
# get_ident()可以获取每个线程的唯一标记,
import time
class Local(object):
storage = {}# 初始化一个字典
get_ident = get_ident # 拿到get_ident的地址
def __setattr__(self, k, v):
ident =self.get_ident()# 获取当前线程的唯一标记
origin = self.storage.get(ident)
if not origin:
origin={}
origin[k] = v
self.storage[ident] = origin
def __getattr__(self, k):
ident = self.get_ident() # 获取当前线程的唯一标记
v= self.storage[ident].get(k)
return v
locals_values = Local()
def func(num):
# get_ident() 获取当前线程的唯一标记
locals_values.KEY=num
time.sleep(2)
print(locals_values.KEY,current_thread().name)
for i in range(10):
t = Thread(target=func,args=(i,),name='线程%s'%i)
t.start()
进阶版2 每个对象有自己的存储空间(字典)
我们可以自定义实现了threading.local的功能,但是现在存在一个问题,如果我们想生成多个Local对象,但是会导致多个Local对象所管理的线程设置的内容都放到了类属性storage = {}里面,所以我们如果想实现每一个Local对象所对应的线程设置的内容都放到自己的storage里面,就需要重新设计代码。
实例:
from threading import get_ident,Thread,current_thread
# get_ident()可以获取每个线程的唯一标记,
import time
class Local(object):
def __init__(self):
# 千万不要按照注释里这么写,否则会造成递归死循环,死循环在__getattr__中,不理解的话可以全程使用debug测试。
# self.storage = {}
# self.get_ident =get_ident
object.__setattr__(self,"storage",{})
object.__setattr__(self,"get_ident",get_ident) #借用父类设置对象的属性,避免递归死循环。
def __setattr__(self, k, v):
ident =self.get_ident()# 获取当前线程的唯一标记
origin = self.storage.get(ident)
if not origin:
origin={}
origin[k] = v
self.storage[ident] = origin
def __getattr__(self, k):
ident = self.get_ident() # 获取当前线程的唯一标记
v= self.storage[ident].get(k)
return v
locals_values = Local()
locals_values2 = Local()
def func(num):
# get_ident() 获取当前线程的唯一标记
# locals_values.set('KEY',num)
locals_values.KEY=num
time.sleep(2)
print(locals_values.KEY,current_thread().name)
# print('locals_values2.storage:',locals_values2.storage) #查看locals_values2.storage的私有的storage
for i in range(10):
t = Thread(target=func,args=(i,),name='线程%s'%i)
t.start()
显示效果我们就不做演示了,和前几个案例演示效果一样。
flask浅析flask框架原理
-
情况一:单进程单线程,基于全局变量就可以做
-
情况二:单进程多线程,基于threading.local对象做
-
情况三:单进程多线程多协程,如何做?
提示:协程属于应用级别的,协程会替代操作系统自动切换遇到
IO的任务或者运行级别低的任务,而应用级别的切换速度远高于操作系统的切换当然如果是自己来设计框架,为了提升程序的并发性能,一定是上诉的情况三,不光考虑多线程并且要多协程,那么该如何设计呢?
在我们的flask中为了这种并发需求,依赖于底层的
werkzeug外部包,werkzeug实现了保证多线程和多携程的安全,werkzeug基本的设计理念和上一个案例一致,唯一的区别就是在导入的时候做了一步处理,且看werkzeug源码。werkzeug.local.py部分源码... try: from greenlet import getcurrent as get_ident # 拿到携程的唯一标识 except ImportError: try: from thread import get_ident #线程的唯一标识 except ImportError: from _thread import get_ident class Local(object): ... def __init__(self): object.__setattr__(self, '__storage__', {}) object.__setattr__(self, '__ident_func__', get_ident) ... def __getattr__(self, name): try: return self.__storage__[self.__ident_func__()][name] except KeyError: raise AttributeError(name) def __setattr__(self, name, value): ident = self.__ident_func__() storage = self.__storage__ try: storage[ident][name] = value except KeyError: storage[ident] = {name: value}讲解:
原理就是在最开始导入线程和协程的唯一标识的时候统一命名为
get_ident,并且先导入协程模块的时候如果报错说明不支持协程,就会去导入线程的get_ident,这样无论是只有线程运行还是协程运行都可以获取唯一标识,并且把这个标识的线程或协程需要设置的内容都分类存放于__storage__字典中。
协程
'''
1、协程:
单线程实现并发
在应用程序里控制多个任务的切换+保存状态
优点:
应用程序切换的速度要远远高于操作系统的切换的速度。
缺点(对比多线程,多进程):
多个任务一旦有一个阻塞没有切,整个线程都阻塞在原地
该线程内的其他的任务都不能执行了
一旦引入协程,就需要检测单线程下所有的IO行为,
2、协程序的目的:
想要在单线程下实现并发
并发指的是多个任务看起来是同时运行的
并发=切换+保存状态
3、思考什么样的协程有意义?
盲目切换反而会导致效率低下,遇到io切换的协程才会提升单个线程下的执行效率(降低io时间)
'''
通过yield实现协程
import time
def func1():
while True:
1000000+1
yield
def func2():
g = func1()
for i in range(100000000):
i+1
next(g)
start = time.time()
func2()
stop = time.time()
print(stop - start) # 28.522686004638672
### 对比通过yeild切换运行的时间反而比串行更消耗时间,这样实现的携程是没有意义的。
import time
def func1():
for i in range(100000000):
i+1
def func2():
for i in range(100000000):
i+1
start = time.time()
func1()
func2()
stop = time.time()
print(stop - start) # 17.141255140304565
Gevent介绍
#安装
pip3 install gevent
Gevent 是一个第三方库,可以轻松通过gevent实现并发同步或异步编程,在gevent中用到的主要模式是Greenlet, 它是以C扩展模块形式接入Python的轻量级协程。 Greenlet全部运行在主程序操作系统进程的内部,但它们被协作式地调度。
#用法
g1=gevent.spawn(func,1,,2,3,x=4,y=5)创建一个协程对象g1,spawn括号内第一个参数是函数名,如eat,后面可以有多个参数,可以是位置实参或关键字实参,都是传给函数eat的
g2=gevent.spawn(func2)
g1.join() #等待g1结束
g2.join() #等待g2结束
#或者上述两步合作一步:gevent.joinall([g1,g2])
g1.value#拿到func1的返回值
import gevent
def eat(name):
print('%s eat 1' %name)
gevent.sleep(2)
print('%s eat 2' %name)
def play(name):
print('%s play 1' %name)
gevent.sleep(1)
print('%s play 2' %name)
g1=gevent.spawn(eat,'egon')
g2=gevent.spawn(play,name='egon')
g1.join()
g2.join()
#或者gevent.joinall([g1,g2])
print('主')
上例gevent.sleep(2)模拟的是gevent可以识别的io阻塞,
而time.sleep(2)或其他的阻塞,gevent是不能直接识别的需要用下面一行代码,打补丁,就可以识别了
from gevent import monkey;monkey.patch_all()必须放到被打补丁者的前面,如time,socket模块之前
或者我们干脆记忆成:要用gevent,需要将from gevent import monkey;monkey.patch_all()放到文件的开头
from gevent import monkey
monkey.patch_all()
import gevent
import time
def eat():
print('eat food 1')
time.sleep(2)
print('eat food 2')
def play():
print('play 1')
time.sleep(1)
print('play 2')
start = time.time()
g1 = gevent.spawn(eat)
g2 = gevent.spawn(play)
g1.join()
g2.join()
# gevent.joinall([g1,g2])
end = time.time() # 3.0165441036224365
# 如果打好了补丁 就可以识别非gevent.sleep阻塞进行切换
print(end-start)
socket服务端单线程并发。
通过gevent实现单线程下的socket并发(from gevent import monkey;monkey.patch_all()一定要放到导入socket模块之前,否则gevent无法识别socket的阻塞)
from threading import Thread
import socket
from gevent import monkey;monkey.patch_all()
import gevent
def talk(conn):
while True:
try:
msg = conn.recv(1024)
if len(msg) == 0: break
conn.send(msg.upper())
except ConnectionResetError:
print('客户端关闭了一个链接')
break
conn.close()
def socket_server_demo():
server=socket.socket(socket.AF_INET,socket.SOCK_STREAM)
server.bind(('127.0.0.1',8081))
server.listen(5)
while True:
conn,addr=server.accept()
gevent.spawn(talk,conn)
if __name__ == '__main__':
g = gevent.spawn(socket_server_demo)
g.join()

 浙公网安备 33010602011771号
浙公网安备 33010602011771号