Centos安装ELK5.3.2
一、注意情况
1、elk的版本要一致。
2、ElasticSearch是基于lucence开发的,也就是运行需要java支持。所以要先安装JAVA环境。由于es5.x依赖于JDK1.8,所以需要安装JDK1.8或者更高版本。
3、官方文档上说Elasticsearch不适合在root管理员帐号下运行,所以要先建立一个账号专门运行Elasticsearch.
4、安装完Kibana后,打开UI界面,需要创建index,否则界面上一致会有警告。
5、开放防火墙端口及关闭selinux,我开放的端口:
Elasticsearch.transport.tcp.port: 9300 设置节点之间交互的tcp端口,默认是9300。
Elasticsearch.http.port: 9200 设置对外服务的http端口,默认为9200。
Elasticsearch.默认情况下,ElasticSearch使用0.0.0.0地址,并为http传输开启9200-9300端口,为节点到节点的通信开启9300-9400端口
Logstash:9600-9700 9100
kibana访问5601端口,如localhost:5601,打开kibana
二、Elasticsearch引擎安装
1、创建帐号和分配权限
官方文档上说Elasticsearch不适合在root管理员帐号下运行,所以要先建立一个账号专门运行Elasticsearch.
创建一个elsearch账户
$ adduser elsearch设置密码
$ passwd elsearch按照提示输入密码和确认密码就成功创建elsearch账户了。
2、引擎下载
退出root账户,使用刚刚创建的elsearch账户登录服务器想,下载Elasticsearch安装包。
$ wget -c https://artifacts.elastic.co/downloads/elasticsearch/elasticsearch-5.3.2.zip文件校验
$ sha1sum elasticsearch-5.3.2.zip 解压
$ unzip elasticsearch-5.3.2.zip解压完将有两个文件,zip可以删掉。
$ ls
elasticsearch-5.3.2 elasticsearch-5.3.2.zip3、引擎启动
进到elasticsearch-5.3.2目录下
# cd elasticsearch-5.3.2/ 启动引擎(-d表示为后台启动)
$ ./bin/elasticsearch -d查看elasticsearch进程情况
$ ps -ef |grep elasticsearch如果看到如下一串东西则表示启动成功
elsearch 22042 1 20 00:36 pts/2 00:00:09 /bin/java -Xms2g -Xmx2g -XX:+UseConcMarkSweepGC -XX:CMSInitiatingOccupancyFraction=75 -XX:+UseCMSInitiatingOccupancyOnly -XX:+DisableExplicitGC -XX:+AlwaysPreTouch -server -Xss1m -Djava.awt.headless=true -Dfile.encoding=UTF-8 -Djna.nosys=true -Djdk.io.permissionsUseCanonicalPath=true -Dio.netty.noUnsafe=true -Dio.netty.noKeySetOptimization=true -Dio.netty.recycler.maxCapacityPerThread=0 -Dlog4j.shutdownHookEnabled=false -Dlog4j2.disable.jmx=true -Dlog4j.skipJansi=true -XX:+HeapDumpOnOutOfMemoryError -Des.path.home=/home/elsearch/elasticsearch-5.3.2 -cp /home/elsearch/elasticsearch-5.3.2/lib/elasticsearch-5.3.2.jar:/home/elsearch/elasticsearch-5.3.2/lib/* org.elasticsearch.bootstrap.Elasticsearch -d或者使用 curl测试,es端口默认情况下是9200
$ curl "localhost:9200"返回如下信息则说明启动成功
{
"name" : "nHlYWW8",
"cluster_name" : "elasticsearch",
"cluster_uuid" : "SNUvV-1fQLKaGnfXrA4UXg",
"version" : {
"number" : "5.3.2",
"build_hash" : "3068195",
"build_date" : "2017-04-24T16:15:59.481Z",
"build_snapshot" : false,
"lucene_version" : "6.4.2"
},
"tagline" : "You Know, for Search"
}4、引擎健康情况
$ curl "localhost:9200/_cat/health?v"
epoch timestamp cluster status node.total node.data shards pri relo init unassign pending_tasks max_task_wait_time active_shards_percent
1493916286 00:44:46 elasticsearch green 1 1 0 0 0 0 0 0 - 100.0%如果出现这条信息,说明你的elastic search已经正常运行了,恭喜你
| 标题 | 含义 |
|---|---|
| epoch | unix 的时间 |
| timestamp | 时间戳 |
| cluster | 集群 |
| status | 健康状态:红为异常, 绿黄为健康 |
| node.total | 节点的总数 |
| node.data | 节点的数据 |
| shards | 分片 |
| pri | active_primary_shards 已激活的主要分片 |
| relo | 回收的切片 |
| init | 已经初始的切片数量 |
| unassign | 未分配切片数量 |
| pending_tasks | 被搁置的任务数量 |
| max_task_wait_time | 任务等待的最大时间 |
| active_shards_percents | 激活分片的百分比 |
注意 status黄色和绿色的区别:
- 红色:所有的分片没有全部激活
- 黄色:主要分片全部启动,但是备份的分片没有启动
- 绿色:主要分片和其备份都已经启动
官方详情请参阅https://www.elastic.co/guide/en/elasticsearch/reference/current/install-elasticsearch.html
5、安装中文分词插件 smartcn
仍然使用elsearch登录,然后切换目录到elsearchsearch 所在的文件夹
$ cd elasticsearch-5.3.2执行安装命令
$ sudo ./bin/elasticsearch-plugin install analysis-smartcn卸载命名
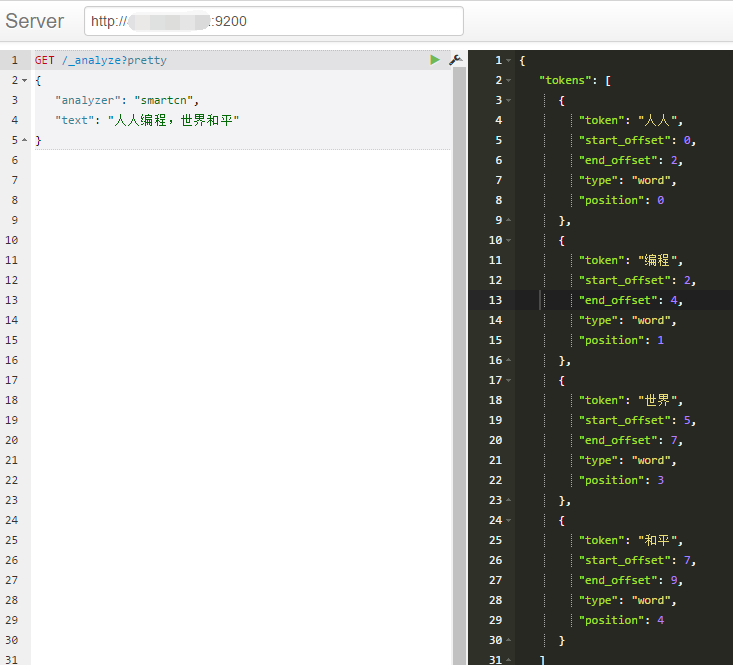
$ sudo ./bin/elasticsearch-plugin remove analysis-smartcn测试分词,使用"人人编程,世界和平"为例子,进行测试,使用站长工具 将例子中的字断转换成unicode编码的字断 在的终端中,调用下面方法,验证smartcn分词插件是否已经成功运行
$ curl -XGET 'localhost:9200/_analyze?pretty' -d '{"analyzer":"smartcn", "text": "\u4eba\u4eba\u7f16\u7a0b\uff0c\u4e16\u754c\u548c\u5e73"}'出现如下结果证明分词成功。若没有添加"analyzer":"smartcn"指定分词,将使用默认分词。对于中文来讲,将会把所有的字单独分出来。
{
"tokens" : [
{
"token" : "人人",
"start_offset" : 0,
"end_offset" : 2,
"type" : "word",
"position" : 0
},
{
"token" : "编程",
"start_offset" : 2,
"end_offset" : 4,
"type" : "word",
"position" : 1
},
{
"token" : "世界",
"start_offset" : 5,
"end_offset" : 7,
"type" : "word",
"position" : 3
},
{
"token" : "和平",
"start_offset" : 7,
"end_offset" : 9,
"type" : "word",
"position" : 4
}
]
}
6、配置elasticsearch.yml
$ cd elasticsearch-5.3.2
$ vim ./config/elasticsearch.yml根据需求修改一下节点:
cluster.name: es-5.3-test #换个集群的名字,免得跟别人的集群混在一起
node.name: node-es-101 #换个节点名字
network.host: 0.0.0.0 #修改一下ES的监听地址,这样别的机器也可以访问
http.port: 9200 #端口号,默认就好
# 增加新的参数,这样head插件可以访问es
http.cors.enabled: true
http.cors.allow-origin: "*"
#增加新的参数,这样ES可以通过外网进行访问,只设置network.host: 0.0.0.0 公网仍旧无法访问
transport.host: localhost
transport.tcp.port: 9300
@注意,设置参数的时候:后面要有空格!7、Sense安装使用
对于不熟悉Linux的人来讲,使用curl是个硬伤,所以 Chrome有个插件Sense可以帮我们很方便的操作Elasticsearch。国内需要FQ。
先来测试下分词
head插件:
docker pull jeanberu/elasticsearch-head //去镜像仓库找
docker run -d -p 9200:9200 -p 9300:9300 --name elasticsearch jeanberu/elasticsearch-head
ip:9200/_plugin/head
三、安装 Kibaba
Kibana是一个开源为elasticsearch 引擎提供数据和数据分析
1、下载安装
切换到root账户,按顺序依次执行以下命令
$ wget -c https://artifacts.elastic.co/downloads/kibana/kibana-5.3.2-x86_64.rpm
$ sha1sum kibana-5.3.2-x86_64.rpm
$ sudo rpm --install kibana-5.3.2-x86_64.rpm2、配置Kibana的host
$ whereis kibana
kibana: /etc/kibana /usr/share/kibana如果显示以上结果表明kibana已经正确安装完成,两个目录
/etc/kibana 为kibana config文件所在的目录
/usr/share/kibana 为程序所在的目录
修改Kibana的配置文件,允许公网访问
$ vim /etc/kibana/kibana.yml将server.host修改为
server.host: "0.0.0.0"3、启动Kibana
配置kibana能够自动启动
$ sudo chkconfig --add kibana启动和停止
$ sudo -i service kibana start
$ sudo -i service kibana stop接下来即可使用公网访问http://IP:5601打开Kibana了。
官方详情请参阅https://www.elastic.co/guide/en/kibana/5.3/targz.html
四、安装 Logstash
下载:wget -c https://artifacts.elastic.co/downloads/logstash/logstash-5.3.2.zip
修改配置文件:logstash-5.3.2/config/logstash.yml
测试:/opt/logstash-5.3.2/bin/logstash -f 配置文件
input {
file { path =>"/var/log/messages" type =>"syslog"}
}
output{
stdout { codec => rubydebug }
elasticsearch {
hosts => ["10.75.241.238:9200"]
index => "logstash-apacheaccesslog-%{+YYYY.MM.dd}"
}
}
上面的配置文件为监听/var/log/messages文件,然后将监听内容存到es里面。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号