详解Kubernetes Pod优雅退出
1、概述
Pod优雅关闭是指在Kubernetes中,当Pod因为某种原因(如版本更新、资源不足、故障等)需要被终止时,Kubernetes不会立即强制关闭Pod,而是首先尝试以一种“优雅”的方式关闭Pod。这个过程允许Pod中的容器有足够的时间来响应终止信号(默认为SIGTERM),并在终止前完成必要的清理工作,如保存数据、关闭连接等。
注意 :在《Docker容器优雅退出》这篇博文中,我们详细讲解了Docker优雅退出机制,在本文我们将详细详解Kubernetes Pod优雅退出机制。
1.1 Pod优雅退出流程
具体来说,Pod优雅关闭的流程如下:
(1)PreStop Hook:
-
- 在Pod的定义中,可以配置一个PreStop Hook。这是一个在容器接收到SIGTERM信号之前执行的命令或HTTP请求。
- PreStop Hook允许容器在接收到SIGTERM信号前,有一段缓冲时间来执行清理工作,如关闭数据库连接、保存文件、通知其他系统等。
(2)SIGTERM信号:
-
- 在PreStop Hook执行完毕后或未定义PreStop Hook的情况下,kubelet 会遍历 Pod 中 container, 然后调用 cri 接口中 StopContainer 方法对 Pod 中的所有 container 进行优雅关停,向 dockerd 发送 stop -t 指令,用 SIGTERM 信号以通知容器内应用进程开始优雅停止。
-
- 等待容器内应用进程完全停止,如果容器在 gracePeriod 执行时间内还未完全停止,就发送 SIGKILL 信号强制杀死应用进程(容器运行时处理)。
(3)SIGKILL信号与资源清理:如果容器在宽限期后仍在运行,容器运行时会发送 SIGKILL 信号强制终止容器,并随后清理 Pod 的资源(容器运行时处理)。
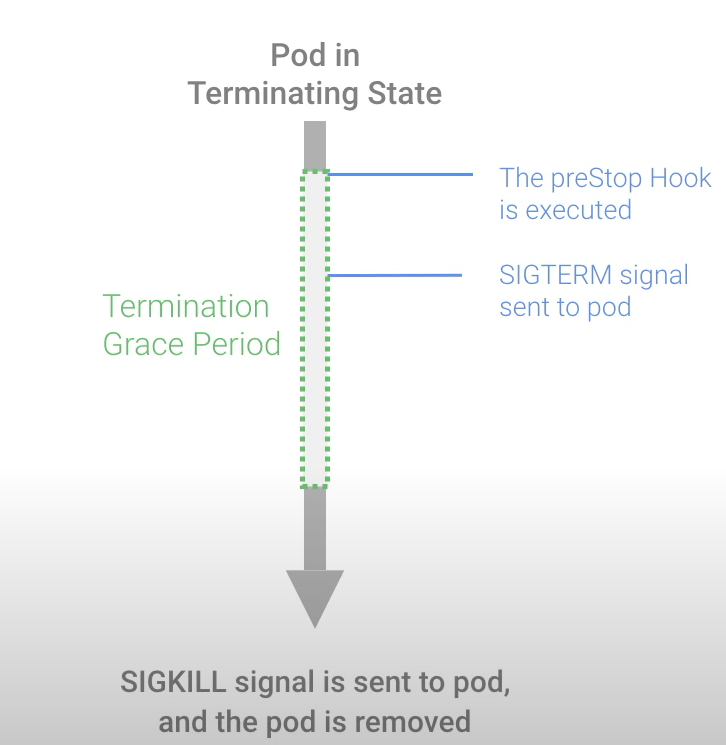
注意:Kubelet 调用 cri 接口中 StopContainer 方法时,向 dockerd 发送 stop -t 指令时会带着优雅关停容器的宽限时间 gracePeriod,gracePeriod 取值分多个情况,默认是 terminationGracePeriodSeconds[30秒] - 容器执行 preStop 时间,具体详情见下文源码分析部分。
1.2 为什么要进行Pod优雅关闭
进行Pod优雅关闭的重要性主要体现在以下几个方面:
-
避免服务中断:通过优雅关闭,Pod可以在终止前完成当前正在处理的请求,确保服务不会因为Pod的突然终止而中断。
-
确保数据一致性:优雅关闭允许Pod在终止前通过PreStop Hook完成必要的数据持久化或事务处理,从而确保数据的一致性。
-
最小化用户体验影响:通过优雅关闭,可以避免将流量路由到已经被删除的Pod,减少用户请求处理失败的可能性。在滚动更新或扩展Pod时,优雅关闭能够确保服务的平滑过渡,对用户来说几乎是无感知的。
-
合理利用资源:优雅关闭允许Pod在终止前释放占用的资源,避免资源浪费和泄露,提高资源的利用率。
总的来说,Pod优雅关闭是Kubernetes中一个重要的功能,它结合了PreStop Hook和宽限期等机制,确保Pod在终止前能够优雅地完成必要的清理工作,从而保持服务的稳定性和可用性、确保数据一致性、提升用户体验和合理利用资源。在进行Pod管理时,应该充分了解和利用Pod优雅关闭的功能。
2、Kubernetes Pod删除原理
Kubernetes (k8s) 中的 Pod 可能因多种原因被删除。以下是一些常见原因:
-
手动删除:用户使用 kubectl delete pod 命令手动删除 Pod。
-
控制器策略:Deployment、ReplicaSet 或 DaemonSet 等控制器根据其策略调整副本数,例如缩减副本数时会删除多余的 Pod;Job 和 CronJob 完成后删除其创建的 Pod。
-
节点故障:如果节点失效,节点上的 Pod 会被 Kubernetes 控制平面标记为失效并在其他节点上重新调度。
-
资源限制:当节点资源不足时,Kubernetes 可能会根据优先级和资源限制(如资源配额和调度策略)来删除一些 Pod。
-
健康检查失败:Pod 的 liveness 或 readiness 探针连续失败,Kubernetes 会认为 Pod 不健康并删除或重启它。
-
优先级抢占:如果有更高优先级的 Pod 需要资源,Kubernetes 可能会删除较低优先级的 Pod 以释放资源。
-
调度器策略:Kubernetes 调度器可能会根据调度策略(如 NodeAffinity、PodAffinity 等)重新分配 Pod,从而删除旧的 Pod。
-
更新策略:Deployment 或 StatefulSet 进行滚动更新时,旧的 Pod 会被删除并替换为新的 Pod。
-
节点自动缩放:当使用集群自动缩放器时,如果集群缩小(移除节点),部分 Pod 会被删除。
但是不管是何种原因删除Pod(用户手动删除或控制器自动删除),在Pod的删除过程中,都会同时会存在两条并行的时间线,如下图所示:
- 一条时间线是网络规则的更新过程。
- 另一条时间线是 Pod 的删除过程。
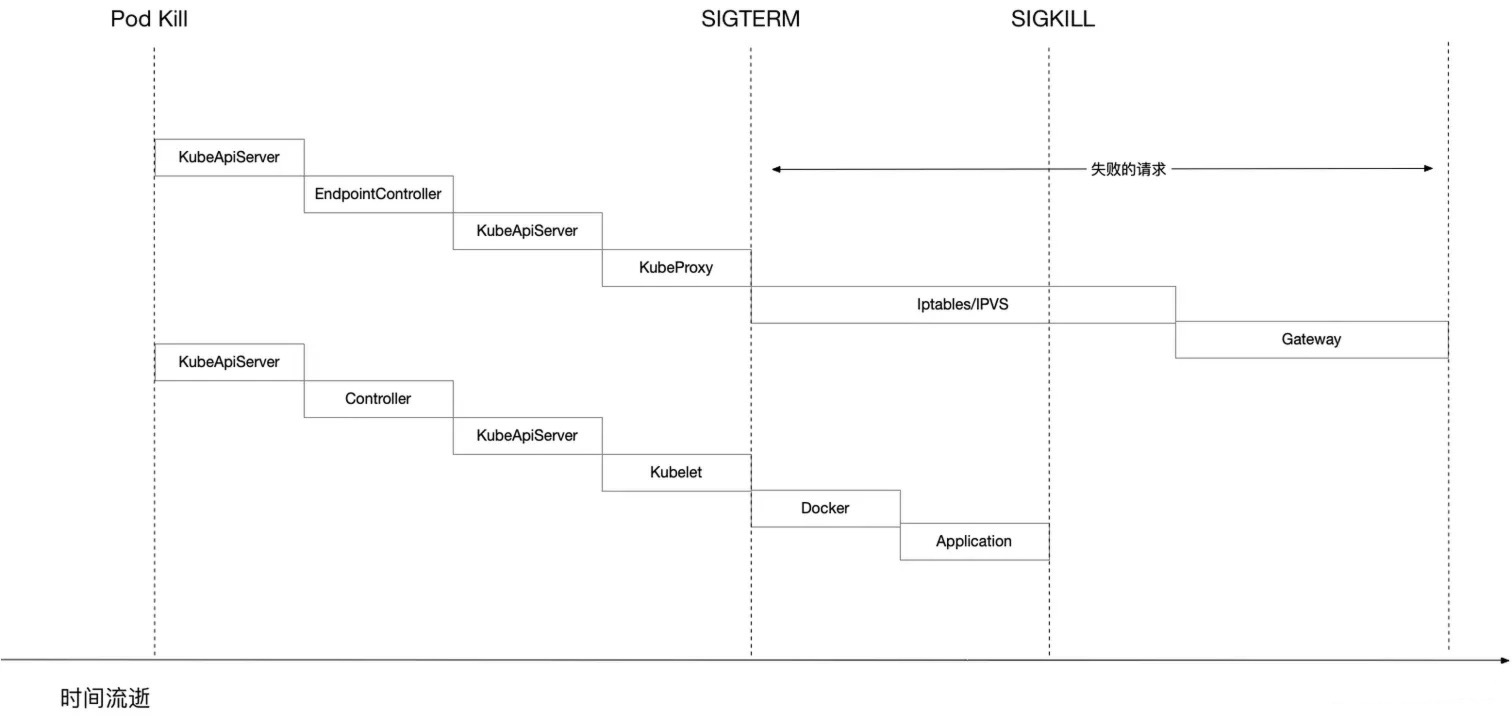
由上面流程图可知,在 Pod 删除过程中,存在两条并行的时间线,这两条时间线谁先执行完毕是不确定的。如果 Pod 内的容器已经删除,但网络层面的 Endpoint 资源仍包含该 Pod 的 IP,客户端请求可能会被路由到已删除的 Pod,导致请求处理失败;或者请求未处理完时,Pod 内的容器已经被删除,这样也会导致请求处理失败。以下是一个工作负载滚动升级的示例,说明如果不为 Pod 配置合理的优雅退出机制,会出现什么问题。
工作负载滚动升级问题示例
-
请求路由错误:旧 Pod 删除但仍在 Endpoint 资源中,导致请求被路由到已删除的 Pod,返回以下错误:
- 502 Bad Gateway:负载均衡器或反向代理无法正确路由请求。
-
数据丢失或不一致:旧 Pod 未将正在处理的请求处理完成的情况下被删除,如果该请求不是幂等性的,则可能导致以下错误:
- 500 Internal Server Error:服务器内部错误,无法完成请求。
- 404 Not Found:如果数据未正确保存或更新,可能找不到预期的资源。
注意 1:本文假设删除Pod都有关联的svc资源,客户端都是通过svc访问Pod。
注意 2:HTTP 404错误通常表示服务器无法找到请求的资源。这可能是因为资源已被删除、移动或从未存在过。在数据丢失或不一致的场景中,404错误可能是一个间接的结果。例如,如果Pod在删除之前正在处理一个应该创建新资源的请求(如数据库记录或文件),但由于Pod的删除,该资源可能没有被正确创建。稍后的请求试图访问该资源时,可能会收到404错误,因为资源不存在。
2.1 原理分析
一切都从 TerminationGracePeriodSeconds 开始说起,我们回顾下 k8s 关闭 Pod 的流程过程。
网络层面:
- Pod 被删除,状态置为 Terminating。
- Endpoint Controller 将该 Pod 的 ip 从 Endpoint 对象中删除。
- Kube-proxy 根据 Endpoint 对象的改变更新 iptables/ipvs 规则,不再将流量路由到被删除的 Pod。
- 如果还有其他 Gateway 依赖 Endpoint 资源变化的,也会改变自己的配置(比如 Nginx Ingress Controller)。
注意 1: 默认 Ingres nginx.ingress.kubernetes.io/service-upstream 注解值为false,Nginx Ingress Controller 代理服务时,借助Endpoint代理代理上游服务到 PodIp。
注意 2:谁监听Endpoint的更改?kube-proxy、Ingress控制器、CoreDNS等都会收到更改的通知。
Pod 层面:
- Pod 被删除,状态置为 Terminating。
- Kubelet 捕获到 ApiServer 中 Pod 状态变化,执行 syncPod 动作。
- 如果 Pod 配置了 preStop Hook ,将会执行。
- kubelet 对 Pod 中各个 container 发送调用 cri 接口中 StopContainer 方法,向 dockerd 发送 stop -t 指令,用 SIGTERM 信号以通知容器内应用进程开始优雅停止。
- 等待容器内应用进程完全停止,如果容器在 gracePeriod 执行时间内还未完全停止,就发送 SIGKILL 信号强制杀死应用进程(容器运行时处理)。
- 所有容器进程终止,清理 Pod 资源。
注意: 默认 Ingres nginx.ingress.kubernetes.io/service-upstream 注解值为false,Nginx Ingress Controller 代理服务时,借助Endpoint代理代理上游服务到 PodIp。
我们重点关注下几个信号:K8S_EVENT, SIGTERM, SIGKILL
- K8S_EVENT: SyncPodKill,kubelet 监听到了 apiServer 关闭 Pod 事件,经过一些处理动作后,向内部发出了一个 syncPod 动作,完成当前真实 Pod 状态的改变。
- SIGTERM: 用于终止程序,也称为软终止,因为接收 SIGTERM 信号的进程可以选择忽略它(容器运行时处理)。
- SIGKILL: 用于立即终止,也称为硬终止,这个信号不能被忽略或阻止。这是杀死进程的野蛮方式,只能作为最后的手段(容器运行时处理)。
注意:信号详解可以参加《Docker容器优雅退出》这篇博文。
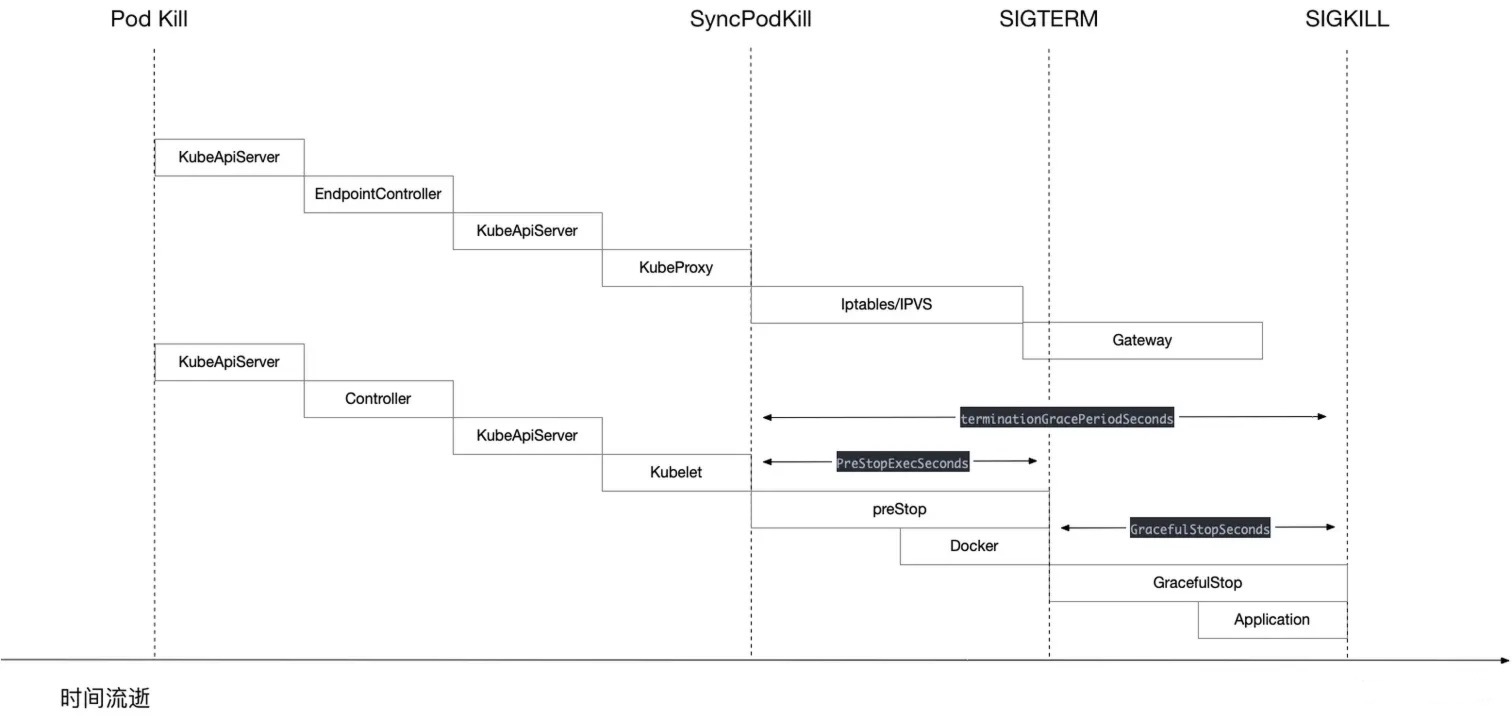
了解信号的解释以后,再通过代码讲解下 Kubelet 关闭 Pod 流程(包含 preStop 和 GracefulStop):
Kubernetes 源码(1.21.5版本):
pkg/kubelet/types/pod_update.go:
// SyncPodType classifies pod updates, eg: create, update. type SyncPodType int const ( // SyncPodSync is when the pod is synced to ensure desired state SyncPodSync SyncPodType = iota // SyncPodUpdate is when the pod is updated from source SyncPodUpdate // SyncPodCreate is when the pod is created from source SyncPodCreate // SyncPodKill is when the pod is killed based on a trigger internal to the kubelet for eviction. // If a SyncPodKill request is made to pod workers, the request is never dropped, and will always be processed. SyncPodKill )
pkg/kubelet/kubelet.go:
如果是删除Pod事件(SyncPodKill)将执行删除Pod逻辑(killPod)。注意看Kubelet调用删除Pod逻辑方法传了一个参数PodTerminationGracePeriodSecondsOverride,它是 Kubelet 的一个配置参数,用于覆盖所有 Pod 的终止宽限时间(grace period)。具体来说,这个参数会设置一个全局的宽限时间值,该值会覆盖所有 Pod 自定义的 terminationGracePeriodSeconds 值。
- 默认情况下,PodTerminationGracePeriodSecondsOverride 是未设置的(即值为 nil 或未定义)。在这种情况下,Kubelet 会使用每个 Pod 自己定义的 terminationGracePeriodSeconds 值,默认值为 30 秒。
- 如果设置了这个参数,Kubelet 会使用此值作为所有 Pod 的终止宽限时间,而不再使用各个 Pod 自定义的 terminationGracePeriodSeconds。这意味着所有 Pod 都会在这个指定的时间内尝试完成终止操作,在时间结束后,Kubelet 会强制终止 Pod。
func (kl *Kubelet) syncPod(o syncPodOptions) error {
......
// if we want to kill a pod, do it now!
if updateType == kubetypes.SyncPodKill {
killPodOptions := o.killPodOptions
if killPodOptions == nil || killPodOptions.PodStatusFunc == nil {
return fmt.Errorf("kill pod options are required if update type is kill")
}
apiPodStatus := killPodOptions.PodStatusFunc(pod, podStatus)
// 修改 Pod 的状态
kl.statusManager.SetPodStatus(pod, apiPodStatus)
// 这里事件类型是关闭 Pod,这里开始执行 Pod 的关闭过程,至此 SyncPodKill 信号的作用结束
if err := kl.killPod(pod, nil, podStatus, killPodOptions.PodTerminationGracePeriodSecondsOverride); err != nil {
kl.recorder.Eventf(pod, v1.EventTypeWarning, events.FailedToKillPod, "error killing pod: %v", err)
// there was an error killing the pod, so we return that error directly
utilruntime.HandleError(err)
return err
}
return nil
}
........
}
pkg/kubelet/kubelet_pods.go:
// One of the following arguments must be non-nil: runningPod, status.
func (kl *Kubelet) killPod(pod *v1.Pod, runningPod *kubecontainer.Pod, status *kubecontainer.PodStatus, gracePeriodOverride *int64) error {
......
// Call the container runtime KillPod method which stops all running containers of the pod
if err := kl.containerRuntime.KillPod(pod, p, gracePeriodOverride); err != nil {
return err
}
.......
}
pkg/kubelet/kuberuntime/kuberuntime_manager.go:
func (m *kubeGenericRuntimeManager) KillPod(pod *v1.Pod, runningPod kubecontainer.Pod, gracePeriodOverride *int64) error {
err := m.killPodWithSyncResult(pod, runningPod, gracePeriodOverride)
return err.Error()
}
func (m *kubeGenericRuntimeManager) killPodWithSyncResult(pod *v1.Pod, runningPod kubecontainer.Pod, gracePeriodOverride *int64) (result kubecontainer.PodSyncResult) {
killContainerResults := m.killContainersWithSyncResult(pod, runningPod, gracePeriodOverride)
for _, containerResult := range killContainerResults {
result.AddSyncResult(containerResult)
}
......
}
pkg/kubelet/kuberuntime/kuberuntime_container.go:
使用协程清理Pod里面所有的容器。
// killContainersWithSyncResult kills all pod's containers with sync results.
func (m *kubeGenericRuntimeManager) killContainersWithSyncResult(pod *v1.Pod, runningPod kubecontainer.Pod, gracePeriodOverride *int64) (syncResults []*kubecontainer.SyncResult) {
containerResults := make(chan *kubecontainer.SyncResult, len(runningPod.Containers))
wg := sync.WaitGroup{}
wg.Add(len(runningPod.Containers))
for _, container := range runningPod.Containers {
go func(container *kubecontainer.Container) {
......
if err := m.killContainer(pod, container.ID, container.Name, "", reasonUnknown, gracePeriodOverride);
......
}
wg.Wait()
close(containerResults)
for containerResult := range containerResults {
syncResults = append(syncResults, containerResult)
}
return
}
pkg/kubelet/kuberuntime/kuberuntime_container.go:
Kubelet 进行 Pod 中容器的关停,这个方法比较关键,这里重点讲解下:
(1)计算容器优雅关闭宽限时间
- 默认设置容器最小优雅关停宽限时间等于2秒。
- 如果 podDeletionGracePeriodSeconds 不是 nil,即 Pod 是被 Apiserver 删除的,那么 gracePeriod 直接取值,优先使用调用 Apiserver 删除Pod时指定的值作为优雅关闭Pod宽限时间,比如kubectl delete pod my-pod --grace-period=60。
- 如果 pod Spec.TerminationGracePeriodSeconds 不是 nil,gracePeriod 取值分为以下三种情况:
- 使用Pod规格配置文件中的定义的terminationGracePeriodSeconds的值,gracePeriod 默认值30秒;
- 如果删除的原因是执行失败 startupProbe,gracePeriod 取启动探针TerminationGracePeriodSeconds值(启用探针宽限时间特性);
- 如果删除的原因是执行失败 livenessProbe,gracePeriod 取存活探针TerminationGracePeriodSeconds值(启用探针宽限时间特性);
(2)如果容器配置了 lifecycle preStop ,执行 container 中 lifecycle preStop 设置的动作或命令,并计算容器执行 lifecycle preStop 的时间。
(3)容器宽限时间 gracePeriod = gracePeriod - 容器执行 lifecycle preStop 的时间。
(4)如果容器执行完 lifecycle preStop 后的宽限时间 < minimumGracePeriodInSeconds(2秒)的话,gracePeriod = minimumGracePeriodInSeconds。
(5)如果kubelet全局配置不为空,所有容器退出宽限时间使用kubelet PodTerminationGracePeriodSecondsOverride配置参数值。
(6)调用 CRI 接口,调用容器云运行时 /container/{containerID}/stop 接口用于关停容器,容器优雅停止的 gracePeriod 值,为上面计算的 gracePeriod。
// killContainer kills a container through the following steps:
// * Run the pre-stop lifecycle hooks (if applicable).
// * Stop the container.
func (m *kubeGenericRuntimeManager) killContainer(pod *v1.Pod, containerID kubecontainer.ContainerID, containerName string, message string, reason containerKillReason, gracePeriodOverride *int64) error {
var containerSpec *v1.Container
if pod != nil {
if containerSpec = kubecontainer.GetContainerSpec(pod, containerName); containerSpec == nil {
return fmt.Errorf("failed to get containerSpec %q (id=%q) in pod %q when killing container for reason %q",
containerName, containerID.String(), format.Pod(pod), message)
}
} else {
// Restore necessary information if one of the specs is nil.
restoredPod, restoredContainer, err := m.restoreSpecsFromContainerLabels(containerID)
if err != nil {
return err
}
pod, containerSpec = restoredPod, restoredContainer
}
// 最小优雅关闭Pod周期是2秒
gracePeriod := int64(minimumGracePeriodInSeconds)
switch {
case pod.DeletionGracePeriodSeconds != nil:
// 优先使用删除Pod时指定的值作为优雅关闭Pod宽限时间,比如kubectl delete pod my-pod --grace-period=60
gracePeriod = *pod.DeletionGracePeriodSeconds
case pod.Spec.TerminationGracePeriodSeconds != nil:
// 使用Pod规格配置文件中的定义的terminationGracePeriodSeconds的值,默认30秒
gracePeriod = *pod.Spec.TerminationGracePeriodSeconds
// 如果启用探针宽限时间特性的话,宽限时间使用探针宽限时间
if utilfeature.DefaultFeatureGate.Enabled(features.ProbeTerminationGracePeriod) {
switch reason {
case reasonStartupProbe:
if containerSpec.StartupProbe != nil && containerSpec.StartupProbe.TerminationGracePeriodSeconds != nil {
gracePeriod = *containerSpec.StartupProbe.TerminationGracePeriodSeconds
}
case reasonLivenessProbe:
if containerSpec.LivenessProbe != nil && containerSpec.LivenessProbe.TerminationGracePeriodSeconds != nil {
gracePeriod = *containerSpec.LivenessProbe.TerminationGracePeriodSeconds
}
}
}
}
if len(message) == 0 {
message = fmt.Sprintf("Stopping container %s", containerSpec.Name)
}
m.recordContainerEvent(pod, containerSpec, containerID.ID, v1.EventTypeNormal, events.KillingContainer, message)
// 空壳函数,没有实际作用,估计是为了以后的扩展用的
// Run internal pre-stop lifecycle hook
if err := m.internalLifecycle.PreStopContainer(containerID.ID); err != nil {
return err
}
// 这里真正执行 container 中 lifecycle preStop 设置的动作或命令
// Run the pre-stop lifecycle hooks if applicable and if there is enough time to run it
if containerSpec.Lifecycle != nil && containerSpec.Lifecycle.PreStop != nil && gracePeriod > 0 {
gracePeriod = gracePeriod - m.executePreStopHook(pod, containerID, containerSpec, gracePeriod)
}
// 宽限时间不够的话再多给2秒
// always give containers a minimal shutdown window to avoid unnecessary SIGKILLs
if gracePeriod < minimumGracePeriodInSeconds {
gracePeriod = minimumGracePeriodInSeconds
}
// 如果kubelet全局配置不为空,所有容器退出宽限时间使用kubelet PodTerminationGracePeriodSecondsOverride配置参数值
if gracePeriodOverride != nil {
gracePeriod = *gracePeriodOverride
klog.V(3).InfoS("Killing container with a grace period override", "pod", klog.KObj(pod), "podUID", pod.UID,
"containerName", containerName, "containerID", containerID.String(), "gracePeriod", gracePeriod)
}
klog.V(2).InfoS("Killing container with a grace period override", "pod", klog.KObj(pod), "podUID", pod.UID,
"containerName", containerName, "containerID", containerID.String(), "gracePeriod", gracePeriod)
// 调用 CRI 接口,调用容器云运行时 /container/{containerID}/stop 接口用于关停容器,容器优雅停止的 gracePeriod 值,为上面计算的 gracePeriod
err := m.runtimeService.StopContainer(containerID.ID, gracePeriod)
if err != nil {
klog.ErrorS(err, "Container termination failed with gracePeriod", "pod", klog.KObj(pod), "podUID", pod.UID,
"containerName", containerName, "containerID", containerID.String(), "gracePeriod", gracePeriod)
} else {
klog.V(3).InfoS("Container exited normally", "pod", klog.KObj(pod), "podUID", pod.UID,
"containerName", containerName, "containerID", containerID.String())
}
return err
}
// 计算容器执行preStopHook时间
// executePreStopHook runs the pre-stop lifecycle hooks if applicable and returns the duration it takes.
func (m *kubeGenericRuntimeManager) executePreStopHook(pod *v1.Pod, containerID kubecontainer.ContainerID, containerSpec *v1.Container, gracePeriod int64) int64 {
klog.V(3).InfoS("Running preStop hook", "pod", klog.KObj(pod), "podUID", pod.UID, "containerName", containerSpec.Name, "containerID", containerID.String())
start := metav1.Now()
done := make(chan struct{})
go func() {
defer close(done)
defer utilruntime.HandleCrash()
if msg, err := m.runner.Run(containerID, pod, containerSpec, containerSpec.Lifecycle.PreStop); err != nil {
klog.ErrorS(err, "PreStop hook failed", "pod", klog.KObj(pod), "podUID", pod.UID,
"containerName", containerSpec.Name, "containerID", containerID.String())
m.recordContainerEvent(pod, containerSpec, containerID.ID, v1.EventTypeWarning, events.FailedPreStopHook, msg)
}
}()
select {
case <-time.After(time.Duration(gracePeriod) * time.Second):
klog.V(2).InfoS("PreStop hook not completed in grace period", "pod", klog.KObj(pod), "podUID", pod.UID,
"containerName", containerSpec.Name, "containerID", containerID.String(), "gracePeriod", gracePeriod)
case <-done:
klog.V(3).InfoS("PreStop hook completed", "pod", klog.KObj(pod), "podUID", pod.UID,
"containerName", containerSpec.Name, "containerID", containerID.String())
}
return int64(metav1.Now().Sub(start.Time).Seconds())
}
注意:这里只粘贴和Pod优雅退出相关代码,其他代码直接忽视了。
容器运行时Docker源码:
moby/daemon/stop.go:
// containerStop sends a stop signal, waits, sends a kill signal.
func (daemon *Daemon) containerStop(ctx context.Context, ctr *container.Container, options containertypes.StopOptions) (retErr error) {
...
var (
// 获得配置的 StopSignal 值,一般我们不会做配置,所以这里默认就是 SIGTERM
stopSignal = ctr.StopSignal()
...
)
...
// 1. 发送关闭信号 SIGTERM
err := daemon.killPossiblyDeadProcess(ctr, stopSignal)
if err != nil {
wait = 2 * time.Second
}
...
// 2. 启动一个超时等待器,等待容器关停优雅宽限时间结束(kubelet调用传过来的gracePeriod,一般是terminationGracePeriodSeconds[30秒] - 容器执行 preStop 时间)
if status := <-ctr.Wait(subCtx, container.WaitConditionNotRunning); status.Err() == nil {
// container did exit, so ignore any previous errors and return
return nil
}
...
// 3. 如果在容器优雅退出时间内(如果是kubelet调用CRI接口的话,容器优雅退出时间默认情况下等于terminationGracePeriodSeconds - preStop 执行时间)还未完全停止,就发送 SIGKILL 信号强制杀死应用进程
if err := daemon.Kill(ctr); err != nil {
// got a kill error, but give container 2 more seconds to exit just in case
subCtx, cancel := context.WithTimeout(ctx, 2*time.Second)
defer cancel()
status := <-ctr.Wait(subCtx, container.WaitConditionNotRunning)
if status.Err() != nil {
logrus.WithError(err).WithField("container", ctr.ID).Errorf("error killing container: %v", status.Err())
return err
}
// container did exit, so ignore previous errors and continue
}
return nil
}
通过上面的代码,验证了之前架构图中流程。我们这边可以简单的终结下一些内容:
- kubelet 作为观察者监控着 ApiServer 中Pod的变化,调用 syncPod 方法去完成当前 node 内的 Pod 状态更新。(删除 Pod 也算是一种 Pod 的状态更新)
- kubelet 不对 Pod 内的 container 应用程序发送任何信号,这个是由 CRI 接口实现体来操作,但是容器的优雅关停的宽限时间是kubelet计算传输的。
2.2 隐形的时间轴
原则公式:T1 = T2 + T3
- TerminationGracePeriodSeconds(T1): 总体容器关闭容忍时间。这个值并不是一个固定参考值,每一个应用对着值的要求也不一样,所以这个值有明确的业务属性。这个值来源优先级如下:
- 如果kubelet全局配置不为空,所有容器退出宽限时间使用 kubelet PodTerminationGracePeriodSecondsOverride 配置参数值;
- 如果 podDeletionGracePeriodSeconds 不是 nil,即 Pod 是被 Apiserver 删除的,那么容器关闭容忍时间等于 podDeletionGracePeriodSeconds 值;
- 如果 K8s 集群开启了探针宽限时间特性的话,那么容器关闭容忍时间优先等于启动探针TerminationGracePeriodSeconds值,其次等于存活探针 TerminationGracePeriodSeconds值;
- 使用Pod规格配置文件中的定义的terminationGracePeriodSeconds的值,gracePeriod 默认值30秒。
- Lifecycle PreStop Hook 执行时间(T2): 等待应用进程关闭前需要执行动作的执行时间,这个主要是影响 “新建请求” 到业务 Pod,因为在执行 preStop 的时候 k8s 网络层的变更也在执行。
- Container Graceful Stop 执行时间(T3): 等待应用自主关闭已有请求的连接,同时结束到数据库之类后端数据写入工作,保证数据都落库或者落盘。这个值来源优先级如下:
- 如果kubelet全局配置不为空,所有容器退出宽限时间使用 kubelet PodTerminationGracePeriodSecondsOverride 配置参数值(T2时间不算入到容器优雅关停时间里面);
- T1 - T2(T3 = T1 - T2 );
- 如果 T1 - T2时间 < minimumGracePeriodInSeconds(2秒)的话,T3 = minimumGracePeriodInSeconds。
- Kubernetes 网络层变更时间(T4)
复杂的逻辑:
- T4 <= T2,正常,响应码200;
- T2 < T4 <= T1,如果服务代码里面正确编写了优雅关停逻辑的话,那么正常,响应码200;如果未优雅关停,可能存在未将正在处理的请求处理完成的情况下被删除,响应码可能是404、500;
- T1 < T4,Bad Gateway,Pod 已经删除了,但是网络层还没有完成变更,导致流量还在往不存在的Pod转发,响应码 502。
2.3 处理方法
心思新密的小伙伴可能逐渐发现,要解决问题,实际就是做一个巧妙的动作调整时间差,满足业务 pod 能够真正的正确的关闭。
知道了原因,知道了逻辑,那顺理成章的就有了解决方案:
- 容器应用进程中要有优雅退出代码,能够执行优雅退出;
- 增加 preStopHook,能够执行一定时间的 sleep;
- 修改 TerminationGracePeriodSeconds,每一个业务根据实际需要修改;
3、示例(通过Lifecycle PreStop Hook来优雅的停掉服务)
有时候我们也想在服务停止前,通过执行一条命令或者发送一个HTTP请求来优雅的停掉服务。
举例:
- 比如对于Spring boot应用,Spring Boot Actuator提供了服务优雅停止办法,当要停止服务时,可以向服务发送一个post方法的shutdown HTTP请求。
- 比如对于Nginx服务,当要停止服务时,可以执行命令kill -QUIT Nginx主进程号来停止服务。
下面我们将以Nginx服务来讲解如何使用一条命令来停止服务:
先回顾一下有关Nginx的基础知识:
Nginx是一个多进程服务,master进程和一堆worker进程,master进程只负责校验配置文件语法,创建worker进程,真正的执行、接收客户请求、处理配置文件中指令都是由worker进程来完成的。master进程与worker进程之间主要是通过Linux Signal来实现交互。Nginx提供了大量的命令和处理信号来实现对配置文件的语法检查,服务优雅停止,进程平滑重启、升级等功能,我们这里仅简单介绍与nginx优雅停止相关命令触发的Linux Signal执行过程和执行原理。
nginx 的停止方法有很多,一般通过发送系统信号给 nginx 的master进程的方式来停止 nginx。
3.1 优雅停止 nginx
[root@localhost ~]# nginx -s quit [root@localhost ~]# kill -QUIT 【Nginx主进程号】 [root@localhost ~]# kill -QUIT /usr/local/nginx/logs/nginx.pid
master进程接到SIGQUIT信号时,将此信号转发给所有工作进程。工作进程随后关闭监听端口以便不再接收新的连接请求,并闭空闲连接,等待活跃连接全部正常结速后,调用 ngx_worker_process_exit 退出。而 master 进程在所有工作进程都退出后,调用 ngx_master_process_exit 函数退出。
注意:以上三个命令中,任选一个执行就可以达到停止 Nginx 服务的目的。推荐使用 nginx -s quit 或 kill -QUIT /usr/local/nginx/logs/nginx.pid,因为它们不需要你手动查找 Nginx 主进程号。
3.2 快速停止 nginx
[root@localhost ~]# nginx -s stop [root@localhost ~]# kill -TERM 【Nginx主进程号】 [root@localhost ~]# kill -INT 【Nginx主进程号】
TERM信号在Linux系统可以称为优雅的退出信号,INT信号是系统SIGINT信号,Nginx对这两个信号的处理方式有所不同。Nginx用SIGQUIT(3)信号来优雅停止服务。
master进程接收到SIGTERM或者SIGINT信号时,将信号转发给工作进程,工作进程直接调用ngx_worker_process_exit 函数退出。master进程在所有工作进程都退出后,调用 ngx_master_process_exit 函数退出。另外,如果工作进程未能正常退出,master进程会等待1秒后,发送SIGKILL信号强制终止工作进程。
3.3 强制停止所有 nginx 进程
[root@localhost ~]# nginx -s stop [root@localhost ~]# pkill -9 nginx
直接给所有的nginx进程发送SIGKILL信号。
3.4 使用Lifecycle PreStop Hook来优雅关停 nginx
1) 运行Docker hub官方提供的Nginx镜像。
官方提供的Nginx Dockerfile中提供的默认的启动Nginx命令如下
Dockerfile
... CMD ["nginx", "-g", "daemon off;"]
上面CMD指定直接在前端启动nginx。
2) Nginx优雅关停Deployment Yaml配置。
apiVersion: apps/v1
kind: Deployment
metadata:
name: nginx-deployment
spec:
replicas: 3
selector:
matchLabels:
app: nginx
template:
metadata:
labels:
app: nginx
spec:
containers:
- name: nginx
image: nginx:latest
ports:
- containerPort: 80
lifecycle:
preStop:
exec:
command: ["/usr/sbin/nginx", "-s", "quit"]
terminationGracePeriodSeconds: 120 # 设置优雅终止的超时时间为 120 秒(2 分钟)
4、总结
preStop 钩子。只有在集群中的所有端点都被传播并从 kube-proxy、Ingress 控制器、CoreDNS 等中删除后,才应该删除 Pod。通过合理的优雅退出配置 T4 <= T2,即在确保网络层面已经删除了Pod IP的前提下,容器再进行优雅退出,在优雅退出过程中继续处理尚未完成的请求,并完成必要的清理工作,如数据保存、连接关闭等。确保Pod在退出时对用户客户端请求是无感知的,同时保证服务的一致性和可靠性。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号