
Linux iowait详解
1、概述
Linux中,%iowait 过高可能是个问题,严重的时候,它能使服务停止, 但问题是,多高才算高? 什么时候应该担心呢?
本文将讨论 iowait 的含义、相关的统计数据、原理以及 iowait 的瓶颈问题。
2、什么是 iowait
Linux 中的解释:
Show the percentage of time that the CPU or CPUs were idle during which the system had an outstanding disk I/O request.
iowait 指在一个采样周期内有百分之几的时间是属于以下情况:CPU处于空闲状态并且至少有一个未完成的磁盘IO请求。
每个CPU 可以处于以下状态之一: user, sys, idle, iowait , 我们通过 iostat工具可以看到这几个状态的值,它们都是以百分比的形式显示的,CPU 是在这几个状态之间切换,所以这几个值总和是 100%。
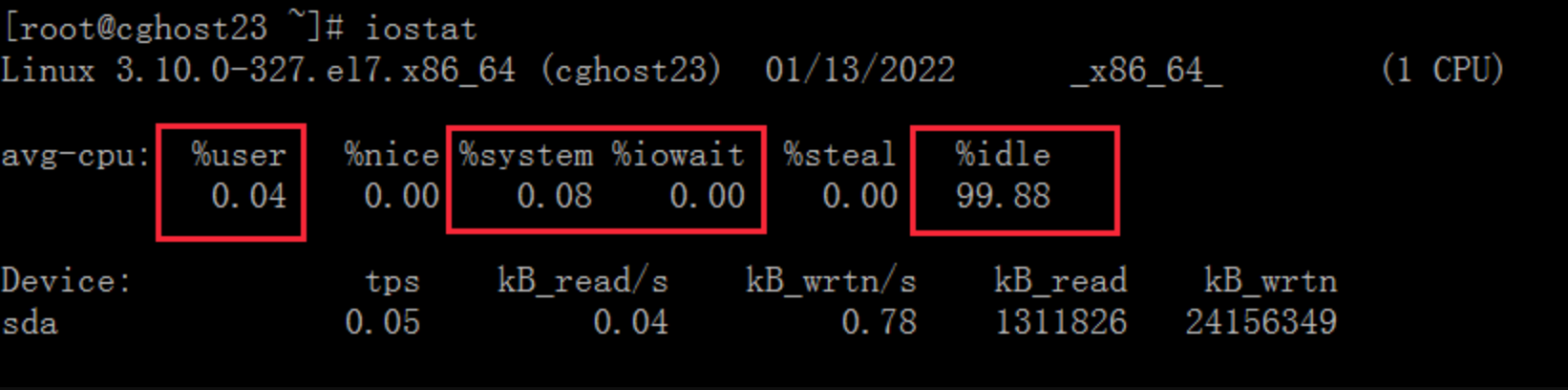
需要说明一点,上图中的 %sys, %user, %idle, %iowait 的百分比值都是针对所有的 CPU 来说的,统计的是全局的信息,并不是指单个进程的数据。
根据 iowait 的定义可知, iowait是属于 idle的一个子类,为了便于理解,可以把 iowait 当成一种等待 IO 造成的 idle 状态。
3、原理
在内核中,user, sys, idle, iowait 四种状态,每个状态都有一个计数器,一个采样周期内统计每个状态的计数器,最后计算每个计数器占总计数的百分比,结果就是每个状态所占的百分比。
当发生时钟中断的时候,内核会检查 CPU 当前的状态,如果 CPU 正在执行内核空间的指令,则 sys 的计数器加 1 ,如果是用户空间的指令,则 user 的计数器加 1。
如果 CPU 此时处于 idle 状态,内核会做以下检查:
1、是否存在从该 CPU 发起的一个未完成的本地磁盘IO请求; 2、是否存在从该 CPU 发起的网络磁盘挂载的操作。
如果存在以上任一情况,则 iowait 的计数器加 1,如果都没有,则 idle 的计数器加 1。
当使用 iostat 工具时,它会读取上述四种计数器的值,间隔玩家指定的秒数后,再次读取计数器的值,取两次的差值就得到了采样周期内计的增量值,我们知道,Linux下每一个时钟 tick 是 10ms,根据间隔的秒数,就可以得到间隔了多少个时钟,而计数器是在每次时钟中断时进行计数,所以用每种状态的计数器的增量值除以总间隔时钟数,就能得到每种状态所占时间的百分比。
假如间隔时间是 1s,则共有 100 个时钟,假如 sys 计数为 2, user 计数为 3,iowait 计数为 0 , idle 计数为 95,则 它们的百分比依次为:2%、 3%、 0%、 95%。
4、iowait 常见的误解
有些同学可能对 iowait 的理解有偏差,常见的误解大概有以下几点:
- iowait 表示等待IO完成,在此期间 CPU 不能接受其他任务
从上面 iowait 的定义可以知道,iowait 表示 CPU 处于空闲状态并且有未完成的磁盘 IO 请求,也就是说,iowait 的首要条件就是 CPU 空闲,既然空闲就能接受任务,只是当前没有可运行的任务,才会处于空闲状态的,为什么没有可运行的任务呢? 有可能是正在等待一些事件,比如:磁盘IO、键盘输入或者等待网络的数据等。
- iowait 高表示 IO 存在瓶颈
由于 Linux 文档对 iowait 的说明不多,这点很容易产生误解,iowait 第一个条件是 CPU 空闲,也即所有的进程都在休眠,第二个条件是 有未完成的 IO 请求。
这两个条件放到一起很容易产生下面的理解:进程休眠的原因是为了等待 IO 请求完成,而 %iowait 变高说明进程因等待IO 而休眠的时间变长了,或者因等待IO而休眠的进程数量变多了 初一听,似乎很有道理,但实际是不对的。
iowait 升高并不一定会导致等待IO进程的数量变多,也不一定会导致等待IO的时间变长,我们借助下面的图来理解:
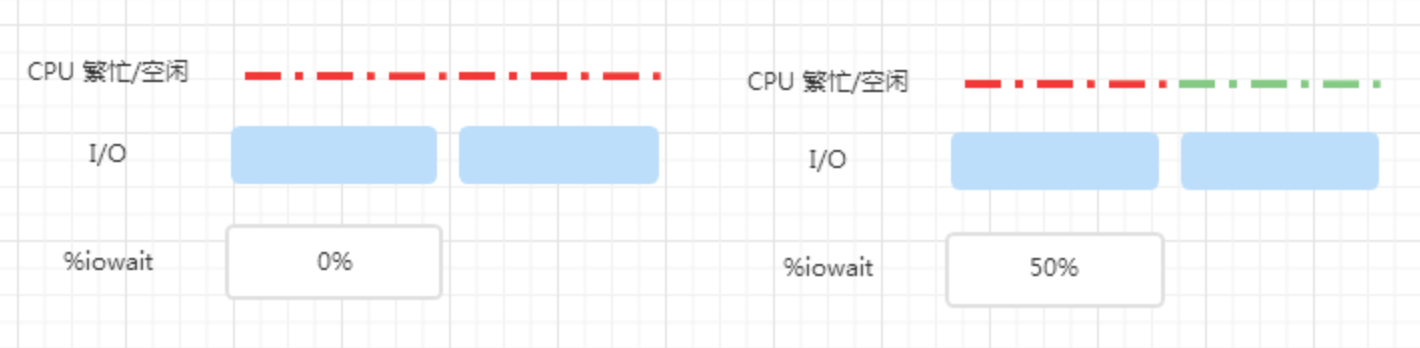
上图中,红色表示 CPU繁忙,绿色表示 CPU 空闲。
一个周期内,两个 IO 依次提交,左图的 CPU 一直处于繁忙状态,所以 %iowait 为 0%,右边的 CPU 繁忙时间只有左边的一半儿,另一半时间是空闲时间,因此 %iowait 为 50%,可以看到,IO 并没有变化,%iowait 确升高了,其实是因为 CPU 空闲时间增加了而已。
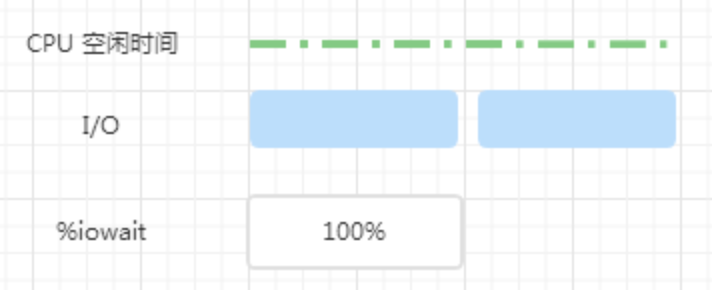
上图中,一个周期内,CPU 一直处于空闲状态,两个 IO 依次提交,整个周期内始终有 IO 再进行,所以 %iowait 为 100%。
假如系统有能力同时处理多个 IO,现在两个 IO 同时提交。
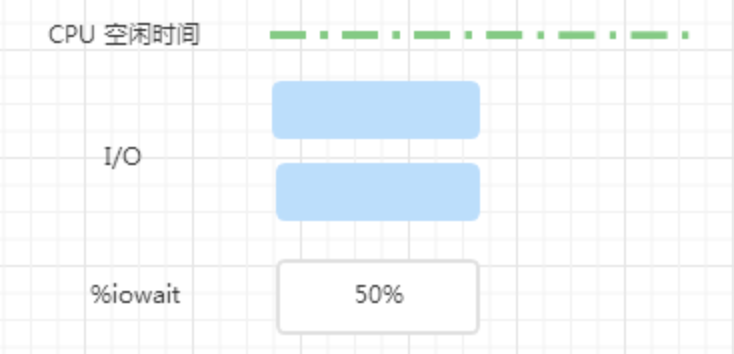
可以看到,系统处理两个并发 IO 只需要一半儿的时间,此时, %iowait 变成了 50%,其实,如果系统能同时处理 3 个并发 IO 的话,%iowait 依然为 50%。
所以,%iowait 的高低与 IO 的多少没有必然的关系,而是与 IO 的并发度相关,仅根据 %iowait 的上升是不能确定 IO 负载增加的结论。
5、如何确定磁盘IO的瓶颈
通过前面的讲述,可以发现 %iowait 包含的信息量还不足以判断出 磁盘IO 是否存在瓶颈。(比如,高速cpu可能会造成很高的iowait值)。唯一能说明磁盘是系统瓶颈的方法,就是很高的read/write时间(svctm),一般来说超过20ms,就代表了不太正常的磁盘性能。为什么是20ms呢?一般来说,一次io就是一次寻道+旋转延迟+数据传输的时间。由于,现代硬盘数据传输就是几微秒或者几十微秒的事情,远远小于寻道时间2~20ms和旋转延迟4~8ms,所以只计算这两个时间就差不多了,也就是15~20ms。只要大于20ms,就必须考虑是否交给磁盘读写的次数太多,导致磁盘性能降低了。
当 %iowait 升高,可以通过iostat来对linux硬盘IO性能进行分析,iostat 是最常用的磁盘 I/O 性能观测工具,它提供了每个磁盘的使用率、IOPS、吞吐量等各种常见的性能指标,当然,这些指标实际上来自 /proc/diskstats。iostat 的输出界面如下。
# -d -x表示显示所有磁盘I/O的指标 [root@node106 ~]# iostat -d -x 1 Linux 3.10.0-1160.59.1.el7.x86_64 (node106) 2024年04月17日 _x86_64_ (8 CPU) Device: rrqm/s wrqm/s r/s w/s rkB/s wkB/s avgrq-sz avgqu-sz await r_await w_await svctm %util sdc 0.00 0.00 0.00 0.00 0.30 0.01 207.67 0.00 3.64 4.85 1.54 2.35 0.00 sdd 0.00 0.00 0.00 0.04 0.48 0.20 31.11 0.00 1.13 9.57 0.67 0.96 0.00 sdb 0.00 0.00 0.00 0.01 0.24 0.07 39.05 0.00 1.07 5.93 0.60 0.89 0.00 sda 0.00 0.24 0.04 51.55 2.50 443.38 17.29 0.09 1.69 8.34 1.68 0.62 3.21 dm-0 0.00 0.00 0.04 51.79 2.49 443.38 17.20 0.09 1.72 8.26 1.71 0.62 3.22 dm-1 0.00 0.00 0.00 0.00 0.00 0.00 48.00 0.00 6.00 6.00 0.00 5.17 0.00
注意:iostat的包名叫sysstat,如果当前Linux服务器没有iostat命令的话,可以通过安装sysstat包解决。
从这里你可以看到,iostat 提供了非常丰富的性能指标。第一列的 Device 表示磁盘设备的名字,其他各列指标,虽然数量较多,但是每个指标的含义都很重要。为了方便你理解,我把它们总结成了一个表格。
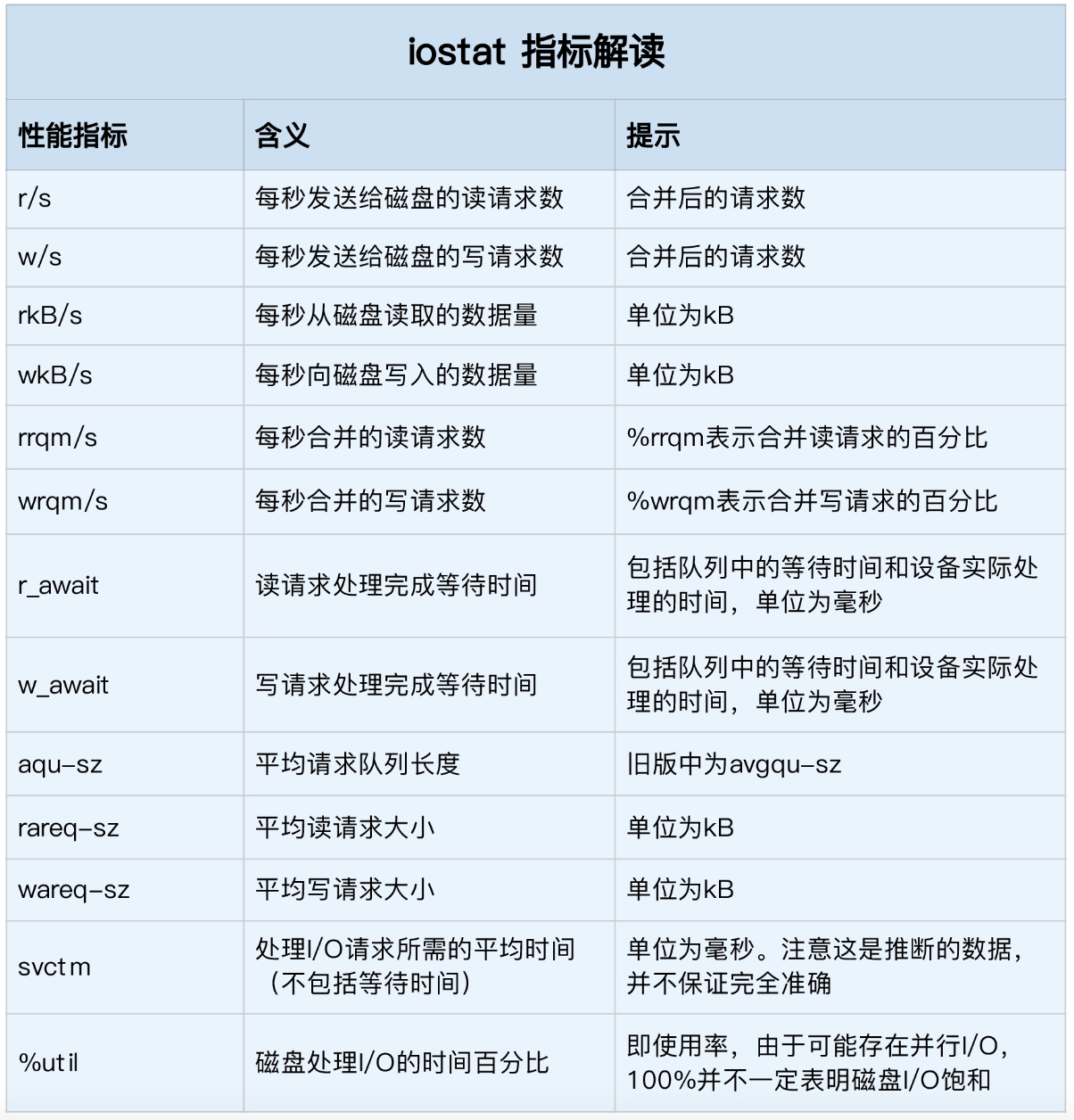
当 %iowait 升高,需要重点关注以下指标:
avgrq-sz: 向设备发出请求的平均大小(单位:扇区)
avgqu-sz: 向设备发出请求的队列平均长度
也是个做 IO 调优时需要注意的地方,这个就是直接每次操作的数据的大小,如果次数多,但数据拿的小的话,其实 IO 也会很小.如果数据拿的大,才IO 的数据会高
r_await: 向服务设备发出读取请求的平均时间(单位:毫秒)
包括请求入队的时间以及设备处理请求的时间
w_await: 向服务设备发出写请求的平均时间(单位:毫秒)
包括请求入队的时间以及设备处理请求的时间
%util: 一秒中有百分之多少的时间用于 I/O 操作,或者说一秒中有多少时间 I/O 队列是非空的
如果 %util 接近 100%,说明产生的I/O请求太多,I/O系统已经满负荷,该磁盘可能存在瓶颈
%svctm: 平均每次设备I/O操作的服务时间 (毫秒)
一般要小于 await (因为同时等待的请求的等待时间被重复计算了),svctm 的大小一般和磁盘性能有关,CPU/内存的负荷也会对其有影响,请求过多也会间接导致 svctm 的增加。await 的大小一般取决于服务时间(svctm) 以及 I/O 队列的长度和 I/O 请求的发出模式。如果 svctm 比较接近 await,说明 I/O 几乎没有等待时间;如果 await 远大于 svctm,说明 I/O 队列太长,应用得到的响应时间变慢,如果响应时间超过了用户可以容许的范围,这时可以考虑更换更快的磁盘,调整内核 elevator 算法,优化应用,或者升级 CPU
其他博主举得一个很不错的例子(I/O 系统 vs. 超市排队):
我们在超市排队结账时,怎么决定该去哪个交款台呢? 首当是看排的队人数,5个人总比20人要快吧? 除了数人头,我们也常常看看前面人购买的东西多少,如果前面有个采购了一星期食品的大妈,那么可以考虑换个队排了。还有就是收银员的速度了,如果碰上了连 钱都点不清楚的新手,那就有的等了。另外,时机也很重要,可能 5 分钟前还人满为患的收款台,现在已是人去楼空,这时候交款可是很爽啊,当然,前提是那过去的 5 分钟里所做的事情比排队要有意义 (不过我还没发现什么事情比排队还无聊的)。
- r/s+w/s 类似于交款人的总数
- 平均队列长度(avgqu-sz)类似于单位时间里平均排队人的个数
- 平均服务时间(svctm)类似于收银员的收款速度
- 平均等待时间(await)类似于平均每人的等待时间
- 平均I/O数据(avgrq-sz)类似于平均每人所买的东西多少
- I/O 操作率 (%util)类似于收款台前有人排队的时间比例。
下面是其他博主写的这个参数输出的分析:
iostat -x 1 avg-cpu: %user %nice %sys %idle 16.24 0.00 4.31 79.44 Device: rrqm/s wrqm/s r/s w/s rsec/s wsec/s rkB/s wkB/s avgrq-sz avgqu-sz await svctm %util /dev/cciss/c0d0 0.00 44.90 1.02 27.55 8.16 579.59 4.08 289.80 20.57 22.35 78.21 5.00 14.29上面的 iostat 输出表明秒有 28.57 次设备 I/O 操作: 总IO(io)/s = r/s(读) +w/s(写) = 1.02+27.55 = 28.57 (次/秒) 其中写操作占了主体 (w:r = 27:1)。
- 平均每次设备 I/O 操作只需要 5ms 就可以完成,但每个 I/O 请求却需要等上 78ms,为什么? 因为发出的 I/O 请求太多 (每秒钟约 29 个),假设这些请求是同时发出的,那么平均等待时间可以这样计算:
- 平均等待时间 = 单个 I/O 服务时间 * ( 1 + 2 + … + 请求总数-1) / 请求总数
- 应用到上面的例子: 平均等待时间 = 5ms * (1+2+…+28)/29 = 70ms,和 iostat 给出的78ms 的平均等待时间很接近。这反过来表明 I/O 是同时发起的
- 一秒中有 14.29% 的时间 I/O 队列中是有请求的,也就是说,85.71% 的时间里 I/O 系统无事可做,所有 29 个 I/O 请求都在142毫秒之内处理掉了
- 每秒发出的 I/O 请求很多 (约 29 个),平均队列却不长 (只有 2 个 左右),这表明这 29 个请求的到来并不均匀,大部分时间 I/O 是空闲的。delta(ruse+wuse)/delta(io) = await = 78.21 => delta(ruse+wuse)/s =78.21 * delta(io)/s = 78.21*28.57 = 2232.8,表明每秒内的I/O请求总共需要等待2232.8ms。所以平均队列长度应为 2232.8ms/1000ms = 2.23,而 iostat 给出的平均队列长度 (avgqu-sz) 却为 22.35,为什么?! 因为 iostat 中有 bug,avgqu-sz 值应为 2.23,而不是 22.35
6、小结
把 %iowait的值作为判断 IO 性能的指标,可能有用,也可能没用,但是它的能告诉我们系统是否还能处理更多的计算任务,例如: 当 iowait 很高时,说明空闲的 CPU 资源较多,还能处理一些计算相关的工作,也就是说,iowait 是 CPU 空闲时间的一种表现形式,唯一能说明磁盘是系统瓶颈的方法,就是很高的read/write时间(svctm,不包括队列等待时间),一般来说超过20ms,就代表了不太正常的磁盘性能。
参考:全面内容主要参考《 如何理解iowait 》,如有侵权麻烦私聊删除。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号