
Kubernetes日志采集——Fluent Bit插件详细配置(二)
1、全局配置——SERVICE
1.1 常用配置参数:
- Flush 设置flush时间(默认5秒),每到刷新时间,fluent-bit都会把数据刷新到输出插件
- Grace 设置超时时间(默认5秒)
- Daemon 用于设置fluent-bit为守护进程(yes、no)
- Log_File 可选日志文件的绝对路径
- Log_Level 日志级别:error, warning, info, debug 和 trace. 注意只有WITH_TRACE启用的情况下trace模式才可用
- Parsers_File Parsers配置路径,可使用多个路径
- Plugins_File 插件配置路径,可以配置外部插件
- Streams_File 流处理器配置文件路径
- HTTP_Server 启用内容Http服务器
- HTTP_Listen 启动Http监听端口
- HTTP_Port tcp 端口(默认2020)
- Coro_Stack_Size 设置协程堆栈大小(以字节为单位)。该值应该大于允许系统页面大小,不要设置太小,否则协程可能会超出堆栈缓冲区(默认 24576)
- scheduler.cap 最大重试时间,默认2000
示例:
1 2 3 4 5 | [SERVICE] Flush 5 Daemon off Log_Level debug Parsers_File parsers.conf |
2、输入——Input
用于从数据源抽取数据,一个数据管道中可以包含多个 Input。
2.1 常用配置参数:
- Buffer_Chunk_Size 设置初始缓冲区大小以读取文件数据(默认32k)
- Buffer_Max_Size 设置每个受监控文件的缓冲大小的限制
- Path 通过使用通用统配符指定一个或者多个特定日志文件的模式
- Path_key 将附加受监视文件的名称作为记录的一部分
- Exclude_Path 设置一个或者多个逗号分隔的shell模式,排除符合特定条件的文件
- Refresh_Interval 刷新监视文件列表的时间间隔(单位秒默认60s)
- Rotate_Wait 在刷新某些挂起的数据时,以秒为单位监视文件一次轮转所需的额外时间
- lgnore_Older 忽略比该时间旧的记录
- Skip_Long_Lines 当受监视的文件由于行很长而达到缓冲区容量时,默认停止监视该文件
- DB 指定数据库文件以跟踪受监视的文件和偏移量
- DB.Sync 设置默认的同步方法(extra、Full、Normal、off)
- full 数据库引擎在紧急时刻会暂停以确定数据已经写入磁盘每次写操作之后就会同步
- Normal SQLite数据库引擎在大部分紧急时刻会暂停,但不像FULL模式下那么频繁
- Mem_Buf_Limit 置将数据附加到引擎时,Tail插件可以使用的内存限制如果达到了极限,就会暂停;当刷新数据时,它将恢复。
- Parser 指定解析器名称
- Key 当消息是非结构化消息(未应用解析器),它将作为字符串附加在键名log下
- Tag 设置一个标签,该标签将放置在读取的行上
- Tag_Regex 设置正则表达式以从文件中提取字段
2.2 常用输入插件:
- systemd 从 systemd / journaled 读取日志
- tail 从文件末尾读取数据
- collected 侦听来自collected的UDP数据包
- cpu 测量CPU的总使用率
- disk 测量磁盘IO
- Docker Metrics 收集docker容器指标
- dummy 生产模拟事件
- exec 执行外部程序并收集事件日志
- forward fluentd 转发协议
- head 读取文件的前几行
- health 检查TCP服务的健康状况
- kmsg 读取Linux内核日志缓冲区消息
- mem 测量系统上使用的内存总量
- mqtt 启动mqtt服务器并接受发布消息
- netif 测量网络流量
- proc 检查进程的运行状况
- random 生产随机样本
- serial 从串行接口读取数据信息
- stdin 从标准输入读取数据
- syslog 从unix套接字读取syslog消息
- tcp 监听tcp json数据
- thermal 测量系统温度
下面以tail插件为示例:
- tail输入插件允许监视一个或多个文本文件。它具有类似于tail -f 这个shell命令的行为。
- tail 插件读取Path配置的每个匹配文件,每发现一行就会生产一个记录,可以选择使用数据库文件,来记录文件的历史和偏移量状态,如果服务重启,就可以恢复之前的状态。
1 2 3 4 | [Input] Name tail //Name是必填的,它的作用是让fluent-bit知道应该加载哪个输入插件 Path /var/log/containers/*.log // 采集的日志路径 Tag kube.* //产生记录的标签名 |
3、转换——PARSER
负责将 Input 抽取的非结构化数据转化为标准的结构化数据,每个 Input 均可以定义自己的 Parser。(可选,在input中定义Parser)
解析器汇总:
- json 把json字符串转换为fluent-bit内部处理格式
- regex 使用正则表达式
- ltsv 解析ltsv格式的文本
下面以json解析器为示例:
1 2 3 4 5 6 | [PARSER] Name docker Format json Time_Key time Time_Format %Y-%m-%dT%H:%M:%S.%L Time_Keep On |
4、过滤——Filter
负责对格式化数据进行过滤和修改。一个数据管道中可以包含多个 Filter,Filter 会顺序执行,其执行顺序与配置文件中的顺序一致。
4.1 常用配置参数:
- Name: 过滤器名称(必填,fluent-bit 通过name知道应该加载哪个插件)
- Match:传入记录标签匹配,* 作为统配符
- Match_Regex:通过正则表达式语法进行配(和Match同时定义,Match_Regex优先)
4.2 常用过滤器:
4.2.1 kubernetes插件
4.2.1.1 简介
kubernetes 过滤器插件允许使用kubernetes元数据丰富日志文件。
4.2.1.2 kubernetes插件所做操作
Fluent Bit一般作为DaemonSet部署在kubernetes中,配置kubernetes插件过滤容器日志时,该过滤器执行以下操作:
> 分析Tag并提取以下元数据(通过kubelet生成的软链接文件名获取):
pod name、namespace、container name、container id
> 查询kubernetes API服务器以获取pod额外元数据
Pod ID、Lables 、Annotations、host、container image等
4.2.1.3 kubernetes插件配置参数
> Buffer_Size 从k8s服务器读取响应时,设置HTTP客户端的缓冲区大小(默认32K)
> Kube_URL API 服务器地址(默认:https://kubernetes.default.svc:443)
> Kube_CA_File CA证书文件(默认:/var/run/secrets/kubernetes.io/serviceaccount/ca.crt)
> Kube_Token_File Token文件
> Kube_Tag_Prefix 当源记录来自 Tail 输入插件时,这个选项允许指定 Tail 配置中使用的前缀
> Merge_Log 当启用时检查 log 字段内容是否是一个 JSON 字符串如果是,追加 map 字段,默认off
> Merge_Log_Key 从原始log内容中获取所有新的结构化字段赋值给指定字符串
> merge_Log_Trim 当启用 Merge_Log 时,修剪(删除可能的 \n 或 \r)字段值
> Merge_Parser 可选解析器名称,用于指定如何解析 log 键中包含的数据
> Keep_Log 当禁用 Keep_Log 时,一旦成功合并传入消息,log 字段将从传入消息中删除(Merge_Log 也必须启用
> tls.debug 调试级别介于 0(无)和 4(每个细节)之间(默认:-1)
> tls.verify 当启用时,将在连接到 Kubernetes API 服务器时启用证书验证(默认:On)
> Use_Journal 当启用时,过滤器读取以 Journald 格式传入的日志(默认:Off)
> Cache_Use_Docker_Id 启用时,当 docker_id 被更改时,元数据将从 k8s 中获取(默认:Off)
> Regex_Parser 设置一个替代的解析器来处理记录标记并提取 pod_name, namespace_name,container_name 和 docker_id。解析器必须在解析器文件中注册
> K8S-Logging.Parser 允许 Kubernetes Pods 建议一个预定义的解析器(在 Kubernetes
> K8S-Logging.Exclude 允许 Kubernetes Pods 从日志处理器中排除它们的日志
> Labels 在额外的元数据中包含 Kubernetes 资源标签(默认:On)
> Annotations 在额外的元数据中包含 Kubernetes 资源注释(默认:On)
> Kube_meta_preload_cache_dir 如果设置了,Kubernetes 元数据可以从该目录中的 JSON 格式文件中缓存 / 预加载,该目录命名为 namespace-pod.meta。
> Dummy_Meta 如果设置了,则使用虚拟元数据(用于 test/dev 目的)
> DNS_Retries DNS 查找重试 N 次,直到网络开始工作(默认:6)
> DNS_Wait_Time 网络状态检查之间的 DNS 查找时间间隔(30)
> Use_Kubelet 这是一个可选的特性标志,用于从 kubelet 获取元数据信息,而不是调用Kube Server API 来增强日志。这可以缓解大型集群的 Kube API 繁忙的流量问题(默认off)
> Kubelet_Port kubelet 端口用于 HTTP 请求,只有当 Use_Kubelet 设置为 On 时才有效(10250)
> Kube_Token_Command 命令获取 Kubernetes 授权令牌。默认情况下,它是 NULL,我们将使用令牌文件来获取令牌。如果你想手动选择一个命令来获取它,你可以在这里设置命令
4.2.2 Parser 插件
4.2.2.1 parser 配置参数
> Key_Name 要解析的记录中的字段名
> Parser 指定解释改字段的解析器名称,允许多个parser条目
> Preserve_Key 在解析的结果中保留原始的 Key_Name 字段。如果为 false,该字段将被删除。
> Reserve_Data 在解析的结果中保留所有其他原始字段(除了 Key_Name 指定的那个字段之外的其他字段)。如果为 false,将删除所有其他原始字段。
> Unescape_Key 如果键是一个被转义的字符串(例如 stringify JSON),在应用解析器之前对字符串进行反转义。
4.2.3 nest 插件
对嵌套数据进行操作。
4.2.3.1 nest插件操作模式
> nest 从记录中指定一组key value合并,并放到一个map里
> lift 从记录的将指定map中的key value都提取出来放到上一层
4.2.3.2 nest插件配置参数
> Operation 指定操作模式(nest or lift)
> Wildcard 字段通配符(nest模式)
> Nest_under 指定map名(nest模式)
> Nested_under 指定map名(lift模式)
> Add_prefix 添加前缀
> Remove_prefix 删除前缀
示例:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 | // nest 操作模式配置文件:[Filter] Name nest Operation nest Wildcard key* Nest_under NestKey输入:{"Key1" : "Value1","Key2" : "Value2","OtherKey" : "Value3"}输出:{"OtherKey" : "Value3""NestKey" : {"Key1" : "Value1","Key2" : "Value2",}}// lift 操作模式 把json对应的层级扯平[Filter] Name nest Operation lift Nested_under NestKey输入:{"OtherKey" : "Value3""NestKey" : {"Key1" : "Value1","Key2" : "Value2"}}输出:{"Key1" : "Value1","Key2" : "Value2","OtherKey" : "Value3"} |
4.2.4 modify 插件
可以通过modify调整相关记录(增、删、改、过滤日志字段)。
4.2.4.1 rules(规则) 规则区分大小写,参数不区分,安装顺序安装
set 修改key:values
add 添加key:values
remove 删除某个key
remove_wildcard 使用通配符
remove_ragex 使用正则匹配
rename 改名
hard_rename 重命名,如果重命名的key存在则覆盖
copy 将键值对赋值到 指定key
hard_copy 硬copy,如果指定key存在则覆盖
4.2.4.2 conditions(判断条件,相当于where语句,不满足条件的记录不会经此modify过滤器处理)
key_exists 判断key是否存在
key_does_not_exist 判断key是否不存在
a_key_matches 正则匹配key是否存在
no_key_matches 正则匹配key是否不存在
key_value_equals 判断key的值是否为指定字符串
key_value_does_not_equal 判断key的值不是指定字符串
key_value_matches 正则匹配key的值(存在)
key_value_does_not_match 正则匹配key的值(不存在)
matching_keys_have_matching_values
matching_keys_do_not_have_matching_values
示例:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 | // 将key2 修改为 test2、添加key3 值为value3[FILTER]Name modifyMatch *SET Key2 test2Add key3 value3输入:{ "Key1" : "Value1", "Key2" : "Value2"}输出:{ "Key1" : "Value1", "Key2" : "test2", "key3" : "Value3"} |
5、缓冲——Buffer
fluent-bit处理数据时,它使用系统内存作为主要和临时位置来存储记录日志,直到路由传递到output之前,在这个私有内存区域上处理记录(也就是说,input、filter、parser都是在是在内存中处理)。
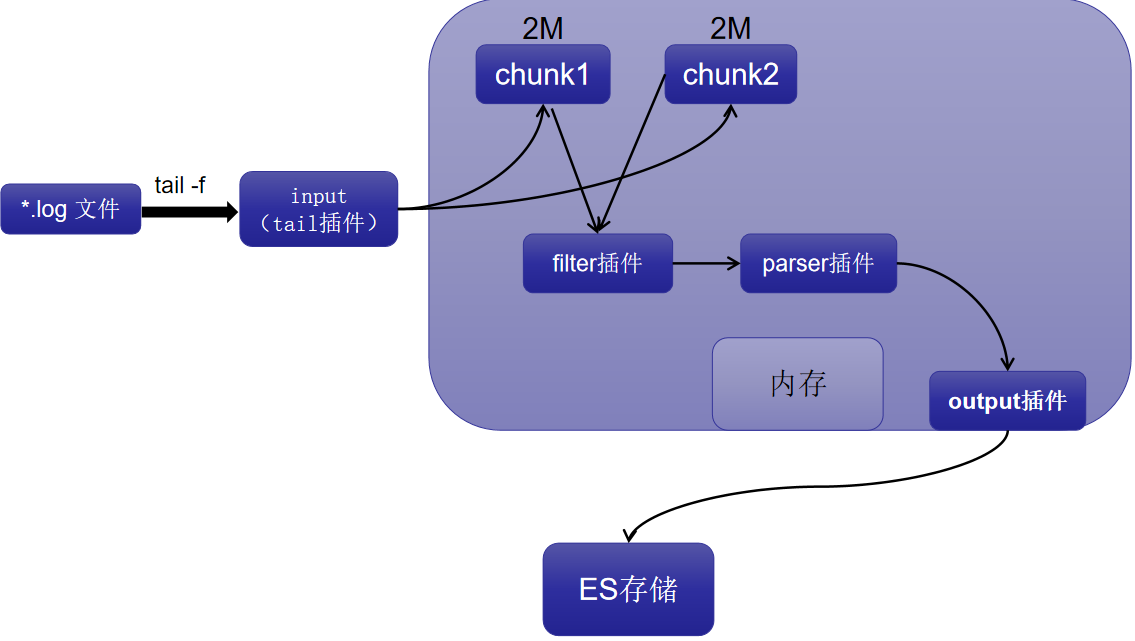
内存缓存风险及解决:
- -缓存风险:默认所有的chunk都会存在内存中,如果output传输的时候有延迟,传输速度很慢,会导致数据堆积,等待output传输,内存使用量会越来越大,高内存使用有可能会被内核杀死。
- - 风险解决方案:解决方法是通过限制input插件可以使用内存量,通过mem_buf_limit参数解决,如果摄取的量超过mem_buf_limit参数指定的大小,input将无法获取更多数据,直到数据output或者刷新。
配置参数:
- storage.path 在文件系统中配置一个可选位置用于存储数据流和数据块,如果未设置此参数,那么只能使用内存作为缓存。
- storage.sync 开启数据同步到文件存储系统,可以配置normal和full两种(默认normal)
- storage.checksum 从文件系统中读取或写入数据时启用完整性检查,存储层使用CRC32算法(默认是关闭的)
- storage.backlog.mem_limit 如果配置storage.path,fluent-bit 会查找尚未分发出去的数据块,这些数据块称之为积压数据,此配置用来控制处理这些积压数据时占用系统内存大小。
- - storage.type (input插件) 指定缓存机制(内存或者文件系统)
配置样例:
1 2 3 4 5 6 7 8 9 10 | [Input] Name tail Path /var/log/containers/nginx*.log Refresh_Interval 10 Skip_Long_Lines true DB /fluent-bit/bin/pos.db DB.Sync Normal Mem_Buf_Limit 5MB Parser docker Tag kube.* |
6、路由——Routing
将 Buffer 中缓存的数据路由到不同的 Output,详细步骤参见:Kubernetes日志采集——Fluent Bit详细介绍(一) 5.5章节。
7、输出——Output
负责将数据发送到不同的目的地,一个数据管道中可以包含多个 Output。
7.1 常用外部输出插件:
- azure 将记录吸收到 azure log analytics 中
- bigquery 将记录提取到Google Big query
- counter 简单记录计数器
- datadog 提取日志到datadog
- es 将记录刷新到ES服务器
- file 将记录刷新到文件
- flowcounter 计数记录
- forward 转发协议
- http 将记录刷新到http端点
- influxdb 将记录刷新到influxDB时间序列数据库
- kafaka 将记录刷新到Apache Kafka
- kafaka-rest 将记录刷新到Kafka rest代理服务器
- stackdriver 将记录刷新到Google Stackdriver Logging服务
- stdout 将记录刷新到标准输出
- splunk 将记录刷新到Splunk Enterprise服务
- tcp 将记录刷新到TCP服务器
- td 将记录刷新到云服务以进行分析
- nats 将记录刷新到NATS服务器
- null 不进行事件处理
下面以es输出插件为例,详细介绍下es输出插件的参数项:
|
参数名
|
默认值
|
注释
|
|
Hosts
|
127.0.0.1
|
es实例的地址
|
|
Port
|
9200
|
es端口
|
|
Path
|
Empty string
|
Elasticsearch 接受 HTTP 查询路径“/_bulk”上的新数据。但是也可以在子路径上的反向代理后面为 Elasticsearch 提供服务
|
|
Buffer_Size
|
4KB
|
指定用于从 Elasticsearch HTTP 服务读取响应的缓冲区大小
|
|
Pipeline
|
较新版本的 Elasticsearch 允许设置称为管道的过滤器。此选项允许定义数据库应使用的管道。出于性能原因,强烈建议在 Fluent Bit 端进行解析和过滤,避免使用管道
|
|
|
AWS_Auth
|
Off
|
为 Amazon OpenSearch Service 启用 AWS Sigv4 身份验证
|
|
AWS_Region
|
为 Amazon OpenSearch Service 指定 AWS 区域
|
|
|
AWX_STS_Endpoint
|
指定要与 STS API for Amazon OpenSearch Service 一起使用的自定义 sts 终端节点
|
|
|
AWX_Role_ARN
|
要承担将记录放入 Amazon 集群的 AWS IAM 角色
|
|
|
AWX_External_ID
|
指定的 AWS IAM 角色的外部 ID aws_role_arn
|
|
|
Cloud_ID
|
如果您使用的是 Elastic 的 Elasticsearch 服务,您可以指定正在运行的集群的 cloud_id
|
|
|
Cloud_Auth
|
指定用于连接到在 Elastic Cloud 上运行的 Elastic 的 Elasticsearch 服务的凭据
|
|
|
HTTP_User
|
用于 Elastic X-Pack 访问的可选用户名凭据
|
|
|
HTTP_Passwd
|
HTTP_User 中定义的用户密码
|
|
|
Index
|
fluent-bit
|
索引名称
|
|
Type
|
_doc
|
类型名称
|
|
Logstash_Format
|
Off
|
启用 Logstash 格式兼容性。
|
|
Logstash_Prefix
|
logstash
|
用 Logstash_Format 时,索引名称由前缀和日期组成,例如:如果 Logstash_Prefix 等于 'mydata',您的索引将变为 'mydata-YYYY.MM.DD'
|
|
Logstash_DateFormat
|
%Y.%m.%d
|
指定日期格式
|
|
Time_Key
|
@timestamp
|
启用 Logstash_Format 后,每条记录都会获得一个新的时间戳字段
|
|
Time_Key_Format
|
%Y-%m-%dT%H:%M:%S
|
定义时间戳格式
|
|
Time_Key_Nanos
|
Off
|
启用此属性会发送纳秒精度时间戳
|
|
Include_Tag_Key
|
Off
|
启用后,它会将标签名称附加到记录中
|
|
Tag_Key
|
_flb-key
|
启用 Include_Tag_Key 时,此属性定义标记的键名称
|
|
Generate_ID
|
Off
|
生成_id传出记录。这可以防止重试 ES 时出现重复记录
|
|
Id_Key
|
如果设置,_id将是来自传入记录的键的值,Generate_ID选项将被忽略。
|
|
|
Replace_Dots
|
Off
|
启用后,将字段名称点替换为下划线,这是 Elasticsearch 2.0-2.3 所要求的
|
|
Trace_Output
|
Off
|
启用后将 elasticsearch API 调用打印到 stdout(仅用于 diag)
|
|
Trace_Error
|
Off
|
启用后,当elasticsearch 返回错误时,将elasticsearch API 调用打印到stdout(仅适用于diag)
|
|
Current_Time_Index
|
Off
|
使用当前时间生成索引而不是消息记录
|
|
Logstash_Prefix_Key
|
包含时:将查找记录中属于该键的值并覆盖 Logstash_Prefix 以生成索引。如果在记录中找不到键/值,则 Logstash_Prefix 选项将作为后备。不支持嵌套键(如果需要,您可以使用嵌套过滤器插件删除嵌套)
|
|
|
Suppress_Type_Name
|
Off
|
启用后,将删除映射类型并Type忽略选项。在v7.0中的 API 中不推荐使用类型。此选项适用于 v7.0 或更高版
|
1 2 3 4 5 6 7 8 | [Output] Name es Match kube.* Host 192.168.30.40 Port 9200 Logstash_Format true Logstash_Prefix cb-logstash-log Time_Key @timestamp |
分类:
日志
, Mesos&Kubernetes


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· TypeScript + Deepseek 打造卜卦网站:技术与玄学的结合
· 阿里巴巴 QwQ-32B真的超越了 DeepSeek R-1吗?
· 【译】Visual Studio 中新的强大生产力特性
· 张高兴的大模型开发实战:(一)使用 Selenium 进行网页爬虫
· 【设计模式】告别冗长if-else语句:使用策略模式优化代码结构
2021-07-08 优化Kubernetes集群DNS性能
2021-07-08 (转)Kubernetes内部域名解析原理、弊端及优化方式