
Kubernetes集群证书过期后,使用kubeadm重新颁发证书
背景:
默认情况下部署kubernetes集群的证书一年内便过期,如果不及时升级证书导致证书过期,Kubernetes控制节点便会不可用,所以需要升级Kubernetes集群版本或者及时更新Kubernetes证书(kubeadm升级Kubernetes证书(证书未过期))避免因证书过期导致集群不可用问题,本文主要讲解因未及时更新Kubernetes证书导致的证书过期后,使用kubeadm重新颁发Kubernetes证书的步骤,本文kubernetes版本为1.18.6。

注意:生产环境一般不会升级Kubernetes版本,所以还可以修改kubeadm源码,修改证书过期时间,重新编译kubeadm使其颁发的Kubernetes证书时间为我们想要的年限(Kubeadm颁发证书延迟到10年 )。
步骤:
1、查看证书过期时间
kubeadm alpha certs check-expiration
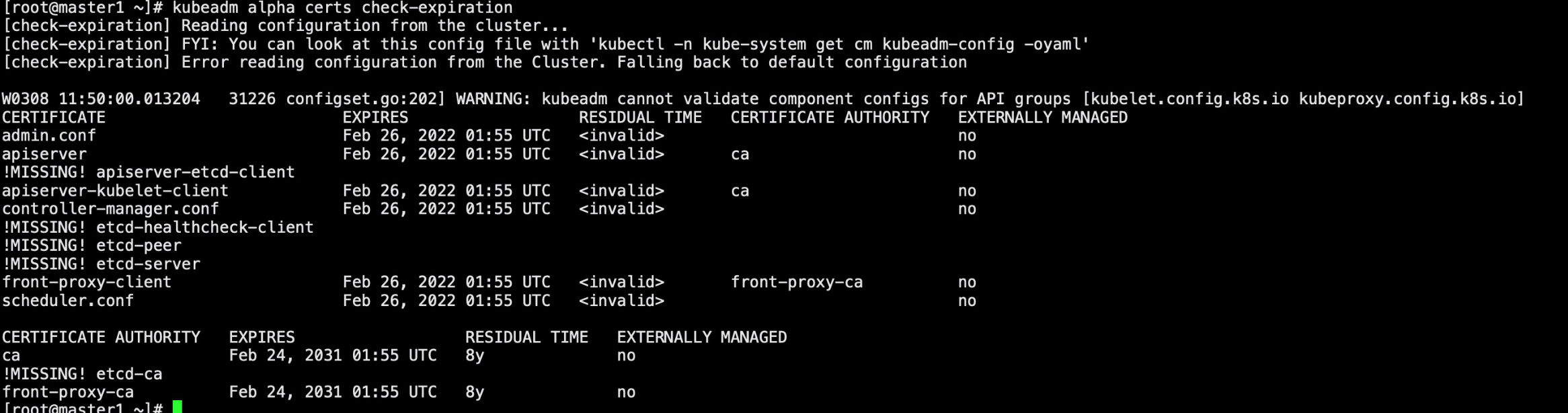
该命令仅在kubernetes1.15 之后的版本可用,版本过低无法使用 kubeadm 命令时,还可以通过 openssl 查看对应证书是否过期。
openssl x509 -in /etc/kubernetes/pki/apiserver.crt -noout -text |grep ' Not '
2、备份证书
备份原有证书
cp -r /etc/kubernetes/ /tmp/backup/
备份etcd数据
cp -r /var/lib/etcd /tmp/etcd-backup/
3、删除旧的证书
将 /etc/kubernetes/pki 下要重新生成的证书删除
sudo rm -rf /etc/kubernetes/pki/apiserver.key .......
4、重新生成证书
主要通过 kubeadm alpha certs renew 命令生成,命令简介如下
kubeadm init phase kubeconfig -h Usage: kubeadm init phase kubeconfig [flags] kubeadm init phase kubeconfig [command] Available Commands: admin Generates a kubeconfig file for the admin to use and for kubeadm itself all Generates all kubeconfig files controller-manager Generates a kubeconfig file for the controller manager to use kubelet Generates a kubeconfig file for the kubelet to use *only* for cluster bootstrapping purposes scheduler Generates a kubeconfig file for the scheduler to use
重新生成所有证书
kubeadm alpha certs renew all
重新生成某个组件的证书
kubeadm alpha certs renew apiserver
5、 重新生成配置文件
备份旧的配置
mv /etc/kubernetes/*.conf /tmp/
生成新的配置,主要通过 kubeadm init phase kubeconfig 命令执行:
kubeadm init phase kubeconfig -h Usage: kubeadm init phase kubeconfig [flags] kubeadm init phase kubeconfig [command] Available Commands: admin Generates a kubeconfig file for the admin to use and for kubeadm itself all Generates all kubeconfig files controller-manager Generates a kubeconfig file for the controller manager to use kubelet Generates a kubeconfig file for the kubelet to use *only* for cluster bootstrapping purposes scheduler Generates a kubeconfig file for the scheduler to use
重新生成所有配置
kubeadm init phase kubeconfig all
重新生成单个配置文件
// 重新生成 admin 配置文件 kubeadm init phase kubeconfig admin // 重新生成 kubelet 配置文件 kubeadm init phase kubeconfig kubelet
6、 后续操作
完成证书和配置文件的更新后,需要进行一系列后续操作保证更新生效,主要包括重启 kubelet、更新管理配置。
- 重启 kubelet
systemctl restart kubelet
- 更新 admin 配置
将新生成的 admin.conf 文件拷贝,替换 ~/.kube 目录下的 config 文件。
cp /etc/kubernetes/admin.conf ~/.kube/config
完成以上操作后整个集群就可以正常通信了,操作过程中主要就是 kubeadm alpha certs renew 命令和 kube init phase kubeconfig命令,在操作过程中发现网上很多资料命令因为版本原因已经不适用了,因此自己在操作时一定要通过 -h 详细看下命令,避免操作出错。
注意:如果是多个master节点,需要同步证书到其他master节点上,或者每个master节点都执行上面步骤。
7、其他问题
重新颁发kubernetes证书后可能会遇到下面问题
1)颁发证书后查看证书过期时间发现etcd相关证书都缺失
[root@master1 ~]# kubeadm alpha certs check-expiration [check-expiration] Reading configuration from the cluster... [check-expiration] FYI: You can look at this config file with 'kubectl -n kube-system get cm kubeadm-config -oyaml' [check-expiration] Error reading configuration from the Cluster. Falling back to default configuration W0308 13:01:12.196352 31105 configset.go:202] WARNING: kubeadm cannot validate component configs for API groups [kubelet.config.k8s.io kubeproxy.config.k8s.io] CERTIFICATE EXPIRES RESIDUAL TIME CERTIFICATE AUTHORITY EXTERNALLY MANAGED admin.conf Mar 08, 2023 04:58 UTC 364d no apiserver Mar 08, 2023 04:57 UTC 364d ca no !MISSING! apiserver-etcd-client apiserver-kubelet-client Mar 08, 2023 04:57 UTC 364d ca no controller-manager.conf Mar 08, 2023 04:58 UTC 364d no !MISSING! etcd-healthcheck-client !MISSING! etcd-peer !MISSING! etcd-server front-proxy-client Mar 08, 2023 04:57 UTC 364d front-proxy-ca no scheduler.conf Mar 08, 2023 04:58 UTC 364d no CERTIFICATE AUTHORITY EXPIRES RESIDUAL TIME EXTERNALLY MANAGED ca Feb 24, 2031 01:55 UTC 8y no !MISSING! etcd-ca front-proxy-ca Feb 24, 2031 01:55 UTC 8y no
并且kube-apiserver服务也起不来,查看日志如下
c = "transport: Error while dialing dial tcp 192.168.249.141:2379: connect: connection refused". Reconnecting...
W0308 04:59:47.532589 1 clientconn.go:1208] grpc: addrConn.createTransport failed to connect to {https://192.168.249.141:2379 <nil> 0 <nil>}. Err :connection error: desc = "transport: Error while dialing dial tcp 192.168.249.141:2379: connect: connection refused". Reconnecting...
W0308 04:59:48.850564 1 clientconn.go:1208] grpc: addrConn.createTransport failed to connect to {https://192.168.249.141:2379 <nil> 0 <nil>}. Err :connection error: desc = "transport: Error while dialing dial tcp 192.168.249.141:2379: connect: connection refused". Reconnecting...
.....
通过查看etcd服务日志可以看到当前控制节点不能拉取etcd镜像
[root@master1 manifests]# journalctl -f -u etcd -- Logs begin at 二 2022-03-08 13:04:12 CST. -- 3月 08 13:09:41 master1 systemd[1]: Stopped etcd docker wrapper. 3月 08 13:09:41 master1 systemd[1]: Starting etcd docker wrapper... 3月 08 13:09:42 master1 docker[5857]: Error: No such container: etcd1 3月 08 13:09:42 master1 systemd[1]: Started etcd docker wrapper. 3月 08 13:09:42 master1 etcd[5878]: Unable to find image '192.168.249.143/cloudbases/etcd:v3.3.12' locally 3月 08 13:09:42 master1 etcd[5878]: /usr/bin/docker: Error response from daemon: Get https://192.168.249.143/v2/: dial tcp 192.168.249.143:443: connect: connection refused. 3月 08 13:09:42 master1 etcd[5878]: See '/usr/bin/docker run --help'. 3月 08 13:09:42 master1 systemd[1]: etcd.service: main process exited, code=exited, status=125/n/a 3月 08 13:09:42 master1 systemd[1]: Unit etcd.service entered failed state. 3月 08 13:09:42 master1 systemd[1]: etcd.service failed.
当前控制节点拉取etcd镜像后,服务都恢复正常。

