

Kubernetes EventBroadcaster事件管理机制源码分析
1、概述
Kubernetes的事件(Event)是一种资源对象(Resource Object),用于展示集群内发生的情况,Kubernetes系统中的各个组件会将运行时发生的各种事件上报给Kubernetes API Server。例如,调度器做了什么决定,某些Pod为什么被从节点中驱逐。由于Kubernetes的事件是一种资源对象,因此它们存储在Kubernetes API Server的Etcd集群中,为避免磁盘空间被填满,故强制执行保留策略:在最后一次的事件发生后,删除1小时之前发生的事件。Kubernetes Event资源对象的概念、使用及持久化方案请参考《Kubernetes Event详述及持久化方案》。
2、EventBroadcaster事件管理机制原理
2.1 谁会发送事件?
Kubernetes以Pod资源为核心,Deployment、StatefulSet、ReplicaSet、DaemonSet、CronJob等,最终都会创建出Pod。因此事件机制也是围绕 pod 进行的,在Pod生命周期的关键步骤都会产生事件消息。比如 Controller Manager 会记录节点注册和销毁的事件、Deployment 扩容和升级的事件;kubelet 会记录镜像回收事件、volume 无法挂载事件等;Scheduler 会记录调度事件等,这些Kubernetes核心组件都是基于EventBroadcaster事件管理机制进行Kubernetes Event处理。本文主要目的是讲解EventBroadcaster事件管理机制,通过讲解EventBroadcaster事件管理机制,我们在自定义组件的时候可以通过EventBroadcaster事件管理机制来管理我们自定义资源类型产生的事件,通过查看自定义资源类型关联的事件可以便于调试、排查、定位问题。
2.2 EventBroadcaster事件管理机制组成及运行原理
Event事件管理机制主要有三部分组成:
- EventRecorder:事件生产者,也称为事件记录器 ,k8s组件通过调用EventRecorder的方法来生成事件;
- EventBroadcaster:事件消费者, 也称为事件广播器。事件广播器,负责消费EventRecorder产生的事件,然后分发给broadcasterWatcher;分发过程有两种机制,分别是非阻塞(Non-Blocking )分发机制和阻塞( Blocking )分发机制;
- broadcasterWatcher:观察者管理,用于定义事件的处理方式,如上报事件至apiserver;
EventBroadcaster事件管理机制运行原理如下图所示:
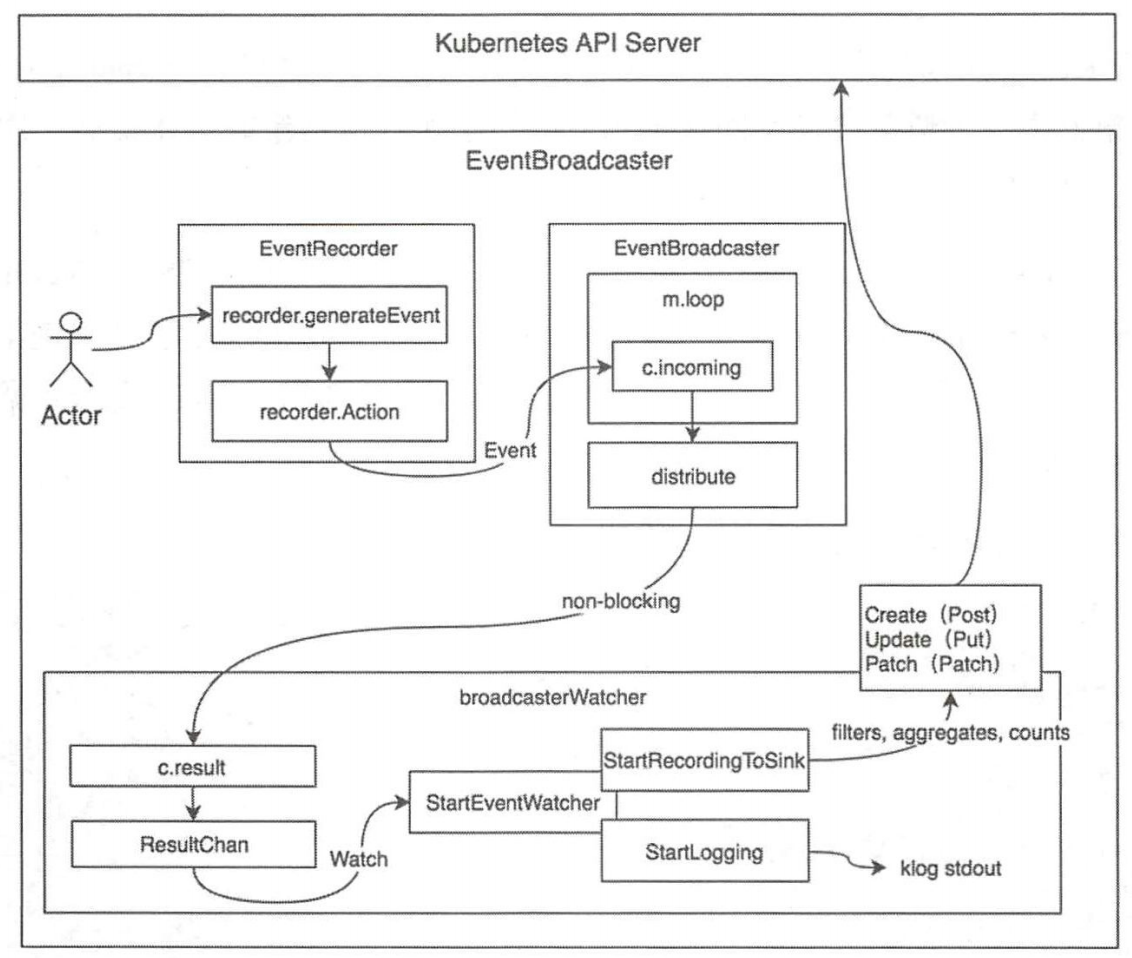
如上图所示, Actor 可以是 Kubernetes 系统中的任意组件(当然也可以是自定义组件),当组件中发生了些关键性事件时,可通过 EventRecorder 记录该事件。
注意:此图摘自《Kuberneter源码剖析》,其Kuberneter版本为1.14.0,请注意您使用的Kubernetes版本,不同版本EventBroadcaster三个组件调用的方法可能和上图有所出入,本文以Kuberneter1.21.7进行剖析EventBroadcaster事件管理机制。
3、Event资源数据结构
以下数据结构都来自k8s.io/api/core/v1/types.go文件:
- Event结构体:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 | //事件是集群中某处事件的报告。type Event struct { metav1.TypeMeta `json:",inline"` //标准对象的元数据。 metav1.ObjectMeta `json:"metadata" protobuf:"bytes,1,opt,name=metadata"` //与此 event 有直接关联的资源对象(触发event的资源对象) InvolvedObject ObjectReference `json:"involvedObject" protobuf:"bytes,2,opt,name=involvedObject"` //这应该是一个简短的,机器可理解的字符串,该字符串给出了转换为对象当前状态的原因。 // +optional Reason string `json:"reason,omitempty" protobuf:"bytes,3,opt,name=reason"` //此操作状态的可读描述。(给一个更易让人读懂的详细说明) // +optional Message string `json:"message,omitempty" protobuf:"bytes,4,opt,name=message"` //报告此事件的组件。 应该是机器可以理解的短字符串。 // +optional Source EventSource `json:"source,omitempty" protobuf:"bytes,5,opt,name=source"` //首次记录事件的时间。 (服务器收到时间以TypeMeta表示。) // +optional FirstTimestamp metav1.Time `json:"firstTimestamp,omitempty" protobuf:"bytes,6,opt,name=firstTimestamp"` //最近一次记录此事件的时间。 // +optional LastTimestamp metav1.Time `json:"lastTimestamp,omitempty" protobuf:"bytes,7,opt,name=lastTimestamp"` // 此事件发生的次数。 // +optional Count int32 `json:"count,omitempty" protobuf:"varint,8,opt,name=count"` // 此事件的类型(正常,警告),将来可能会添加新的类型 // +optional Type string `json:"type,omitempty" protobuf:"bytes,9,opt,name=type"` //首次观察到此事件的时间。 // +optional EventTime metav1.MicroTime `json:"eventTime,omitempty" protobuf:"bytes,10,opt,name=eventTime"` // 有关此事件表示的事件系列的数据,如果是单例事件,则为nil。 // +optional Series *EventSeries `json:"series,omitempty" protobuf:"bytes,11,opt,name=series"` // 针对对象已采取/未采取什么措施。 // +optional Action string `json:"action,omitempty" protobuf:"bytes,12,opt,name=action"` // 可选的辅助对象,用于更复杂的操作。 // +optional Related *ObjectReference `json:"related,omitempty" protobuf:"bytes,13,opt,name=related"` // 发出此事件的控制器的名称,例如 `kubernetes.io / kubelet`。 // +optional ReportingController string `json:"reportingComponent" protobuf:"bytes,14,opt,name=reportingComponent"` // 控制器实例的ID,例如 `kubelet-xyzf`。 // +optional ReportingInstance string `json:"reportingInstance" protobuf:"bytes,15,opt,name=reportingInstance"`} |
-
involvedObject结构体: 定义了与此 Event 有直接关联的资源对象:
1 2 3 4 5 6 7 8 9 | type ObjectReference struct { Kind string `json:"kind,omitempty" protobuf:"bytes,1,opt,name=kind"` Namespace string `json:"namespace,omitempty" protobuf:"bytes,2,opt,name=namespace"` Name string `json:"name,omitempty" protobuf:"bytes,3,opt,name=name"` UID types.UID `json:"uid,omitempty" protobuf:"bytes,4,opt,name=uid,casttype=k8s.io/apimachinery/pkg/types.UID"` APIVersion string `json:"apiVersion,omitempty" protobuf:"bytes,5,opt,name=apiVersion"` ResourceVersion string `json:"resourceVersion,omitempty" protobuf:"bytes,6,opt,name=resourceVersion"` FieldPath string `json:"fieldPath,omitempty" protobuf:"bytes,7,opt,name=fieldPath"`} |
- EventSource结构体,定义了与此Event直接关联的组件(上报事件的组件信息):
1 2 3 4 5 6 7 8 | type EventSource struct { // Component from which the event is generated. // +optional Component string `json:"component,omitempty" protobuf:"bytes,1,opt,name=component"` // Node name on which the event is generated. // +optional Host string `json:"host,omitempty" protobuf:"bytes,2,opt,name=host"`} |
-
types.go常量:定义了两种Event类型:
1 2 3 4 5 6 7 8 | const ( // 正常事件 // Information only and will not cause any problems EventTypeNormal string = "Normal" // 警告事件 // These events are to warn that something might go wrong EventTypeWarning string = "Warning") |
4、EventBroadcaster源码分析
4.1 EventRecorder记录事件(事件生产者/事件记录器)
- EventRecorder
在client-go中的tools/record/event.go中定义的EventRecorder接口:
1 2 3 4 5 6 7 8 9 10 11 | // EventRecorder knows how to record events on behalf of an EventSource.type EventRecorder interface { // 对刚发生的事件进行记录 Event(object runtime.Object, eventtype, reason, message string) // 通过使用fmt.Sprintf格式化输出事件的格式。 Eventf(object runtime.Object, eventtype, reason, messageFmt string, args ...interface{}) // 功能与Eventf一样,但附加了注释(Annotations )字段。 AnnotatedEventf(object runtime.Object, annotations map[string]string, eventtype, reason, messageFmt string, args ...interface{})} |
EventRecorder定义了记录Event的三种方法,用以帮助kubernetes组件记录Event。其中Event是可以用来记录刚发生的事件;Eventf通过使用fmt.Sprintf格式化输出事件的格式;AnnotatedEventf功能和Eventf一致,但是附加了注释字段。
- recorderImpl
结构体recorderImpl是EventRecorder接口的实现:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 | // client-go/tools/record/event.gotype recorderImpl struct { //k8s资源注册表 scheme *runtime.Scheme //上报事件的组件,例如kubelet,kube-controller-manager source v1.EventSource //事件消费 匿名字段 *watch.Broadcaster clock clock.Clock}// recorderImpl实例化方法,基于事件消费者实现类 eventBroadcasterImpl,建立了生产者和消费者之间的联系func (e *eventBroadcasterImpl) NewRecorder(scheme *runtime.Scheme, source v1.EventSource) EventRecorder { return &recorderImpl{scheme, source, e.Broadcaster, clock.RealClock{}}}func (recorder *recorderImpl) Event(object runtime.Object, eventtype, reason, message string) { recorder.generateEvent(object, nil, eventtype, reason, message)}func (recorder *recorderImpl) Eventf(object runtime.Object, eventtype, reason, messageFmt string, args ...interface{}) { recorder.Event(object, eventtype, reason, fmt.Sprintf(messageFmt, args...))}func (recorder *recorderImpl) AnnotatedEventf(object runtime.Object, annotations map[string]string, eventtype, reason, messageFmt string, args ...interface{}) { recorder.generateEvent(object, annotations, eventtype, reason, fmt.Sprintf(messageFmt, args...))} |
recorderImpl结构体中包含apimachinery/pkg/watch/mux.go中的Broadcaster结构体对象地址,因此可以调用Broadcaster实现的方法。
recorderImpl实现了EventRecorder接口定义的三个方法,以Event方法为例,调用链为:
recorderImpl.Event方法→ recorderImpl.generateEvent方法→Broadcaster.ActionOrDrop方法:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 | // client-go/tools/record/event.gofunc (recorder *recorderImpl) generateEvent(object runtime.Object, annotations map[string]string, eventtype, reason, message string) { //实例化事件直接关联的资源对象 ref, err := ref.GetReference(recorder.scheme, object) if err != nil { klog.Errorf("Could not construct reference to: '%#v' due to: '%v'. Will not report event: '%v' '%v' '%v'", object, err, eventtype, reason, message) return } // 验证事件类型,目前只支持Normal和Warning两种事件类型 if !util.ValidateEventType(eventtype) { klog.Errorf("Unsupported event type: '%v'", eventtype) return } // 实例化Event event := recorder.makeEvent(ref, annotations, eventtype, reason, message) // 设置上报事件的组件信息 event.Source = recorder.source //将Event写入m.incoming Chan中,完成事件生产过程 if sent := recorder.ActionOrDrop(watch.Added, event); !sent { klog.Errorf("unable to record event: too many queued events, dropped event %#v", event) }} |
makeEvent方法会创建Event资源实例
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 | // client-go/tools/record/event.gofunc (recorder *recorderImpl) makeEvent(ref *v1.ObjectReference, annotations map[string]string, eventtype, reason, message string) *v1.Event { t := metav1.Time{Time: recorder.clock.Now()} namespace := ref.Namespace // 如果与此event直接关联的资源对象是集群资源,那么此event将创建在default命名空间下 if namespace == "" { namespace = metav1.NamespaceDefault } return &v1.Event{ ObjectMeta: metav1.ObjectMeta{ Name: fmt.Sprintf("%v.%x", ref.Name, t.UnixNano()), Namespace: namespace, Annotations: annotations, }, // 此event有直接关联的资源对象 InvolvedObject: *ref, Reason: reason, Message: message, FirstTimestamp: t, LastTimestamp: t, Count: 1, Type: eventtype, }} |
generateEvent方法会异步的调用ActionOrDrop方法,将事件写入到incoming中:
1 2 3 4 5 6 7 8 9 | // apimachinery/pkg/watch/mux.gofunc (m *Broadcaster) ActionOrDrop(action EventType, obj runtime.Object) bool { select { case m.incoming <- Event{action, obj}: return true default: return false }} |
4.2 EventBroadcaster事件广播(事件消费者/事件广播器)
-
EventBroadcaster
在client-go中的tools/record/event.go中定义了EventBroadcaster接口:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 | // EventBroadcaster knows how to receive events and send them to any EventSink, watcher, or log.type EventBroadcaster interface { // StartEventWatcher starts sending events received from this EventBroadcaster to the given // event handler function. The return value can be ignored or used to stop recording, if // desired. StartEventWatcher(eventHandler func(*v1.Event)) watch.Interface //启动事件监听,然后进行广播 // StartRecordingToSink starts sending events received from this EventBroadcaster to the given // sink. The return value can be ignored or used to stop recording, if desired. StartRecordingToSink(sink EventSink) watch.Interface //启动记录事件到EventSink // StartLogging starts sending events received from this EventBroadcaster to the given logging // function. The return value can be ignored or used to stop recording, if desired. StartLogging(logf func(format string, args ...interface{})) watch.Interface //启动记录事件到日志 // StartStructuredLogging starts sending events received from this EventBroadcaster to the structured // logging function. The return value can be ignored or used to stop recording, if desired. StartStructuredLogging(verbosity klog.Level) watch.Interface //启动记录事件到日志,使用klog插件记录日志,可以指定日志级别 // 事件生产者实例化方法,用于发送事件到此事件消费者 // NewRecorder returns an EventRecorder that can be used to send events to this EventBroadcaster // with the event source set to the given event source. NewRecorder(scheme *runtime.Scheme, source v1.EventSource) EventRecorder // Shutdown shuts down the broadcaster Shutdown() //停止事件广播} |
EventBroadcaster作为Event消费者和事件广播器,消费EventRecorder记录的事件并将其分发给目前所有已连接的broadcasterWatcher。
结构体eventBroadcasterImpl是其实现:
1 2 3 4 5 | type eventBroadcasterImpl struct { *watch.Broadcaster sleepDuration time.Duration options CorrelatorOptions} |
eventBroadcasterImpl结构体中,同样包含Broadcaster结构体对象地址,因此可以调用Broadcaster实现的方法。sleepDuration是最终watcher在记录事件的时候报错后会重试,这个参数代表了每次重试的时间间隔。options这个参数在记录事件的过程中很重要,不赋值的话,系统会使用默认的一组值,用来对事件进行聚合处理,我们知道事件里面有一个count属性,表明此事件发生了多少次,这个值就是通过对事件的聚合而生成的值,k8s为了防止大量事件的产生对etcd造成冲击,就搞了这么一个聚合机制,把相似的事件聚合成一个event。
在apimachinery中的pkg/watch/mux.go中定义了Broadcaster结构体:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 | type Broadcaster struct { watchers map[int64]*broadcasterWatcher //注册的watch(观察者) nextWatcher int64 //watch编号 distributing sync.WaitGroup incoming chan Event //存放事件 stopped chan struct{} // How large to make watcher's channel. watchQueueLength int //watcher存储事件的缓冲管道长度 // If one of the watch channels is full, don't wait for it to become empty. // Instead just deliver it to the watchers that do have space in their // channels and move on to the next event. // It's more fair to do this on a per-watcher basis than to do it on the // "incoming" channel, which would allow one slow watcher to prevent all // other watchers from getting new events. fullChannelBehavior FullChannelBehavior //存放事件的缓冲通道满了之后,再来事件是否要抛弃事件 } |
client-go的tools/record/event.go中,提供的实例化eventBroadcasterImpl的函数:
1 2 3 4 5 6 7 | // Creates a new event broadcaster.func NewBroadcaster() EventBroadcaster { return &eventBroadcasterImpl{ Broadcaster: watch.NewLongQueueBroadcaster(maxQueuedEvents, watch.DropIfChannelFull), sleepDuration: defaultSleepDuration, }} |
Broadcaster实际由apimachinery/pkg/watch/mux.go中的NewLongQueueBroadcaster函数创建:
1 2 3 4 5 6 7 8 9 10 11 12 | func NewLongQueueBroadcaster(queueLength int, fullChannelBehavior FullChannelBehavior) *Broadcaster { m := &Broadcaster{ watchers: map[int64]*broadcasterWatcher{}, //观察者 incoming: make(chan Event, queueLength), //事件接收缓冲 stopped: make(chan struct{}), watchQueueLength: queueLength, fullChannelBehavior: fullChannelBehavior, //broadcasterWatcher存放事件的result通道缓存满了之后再来写入的事件是否抛弃事件,这里默认都是抛弃,逻辑在下面的distribute()方法里面 } m.distributing.Add(1) // sysc.WaitGroup go m.loop() // 死循环消费事件直到incoming通道关闭 return m} |
创建时,会在内部启动goroutine,通过m.loop方法监控m.incoming;
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 | // k8s.io/apimachinery/pkg/watch/mux.gofunc (m *Broadcaster) loop() { //获取m.incoming管道中的数据,死循环直到incoming通道关闭 for event := range m.incoming { if event.Type == internalRunFunctionMarker { event.Object.(functionFakeRuntimeObject)() continue } //事件下发给观察者 m.distribute(event) } // incoming通道关闭后清理资源(关闭所有观察者) m.closeAll() m.distributing.Done()} |
可以看到loop方法,一直从m.incoming里面获取值,然后调用distribute方法,下发给所有已连接的BroadcasterWatcher处理具体的事件,除非m.incoming被close,否则for循环将一直维持。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 | func (m *Broadcaster) distribute(event Event) { if m.fullChannelBehavior == DropIfChannelFull { for _, w := range m.watchers { //遍历所有观察者 select { case w.result <- event: //把事件分发给每一个观察者 case <-w.stopped: //如果观察者被停止 default: //非阻塞分发,如果w.result满了,则丢弃事件 } } } else { for _, w := range m.watchers { select { case w.result <- event: //阻塞分发,如果w.result满了,则一直等待事件被处理后在放入事件 case <-w.stopped: } } }} |
这个方法做的事情就是把从incoming里面获取的事件拿到之后,遍历所有的watcher,然后把事件放到每一个watcher接收事件的result通道里面。watcher在注册的时候,会启动一个for循环从result通道里面获取事件,执行记录逻辑,后面会看到的。
分发过程有两种机制,分别是非阻塞(Non-Blocking)分发机制和阻塞(Blocking)分发机制。在非阻塞分发机制(默认)下使用DropIfChannelFull标识。DropIfChannelFull标识位于select多路复用中,使用default关键字做非阻塞分发,当w.result缓冲区满的时候,事件会丢失。在阻塞分发机制下使用WaitIfChannelFull标识。WaitIfChannelFull标识也位于select多路复用中,没有default关键字,当w.result缓冲区满的时候,分发过程会阻塞并等待。
这里之所以需要丢失事件,是因为随着k8s集群越来越大,上报事件也随之增多,那么每次上报都要对etcd进行读写,这样会给etcd集群带来压力。但是事件丢失并不会影响集群的正常工作,所以非阻塞分发机制下事件会丢失。
这里再分析一下关闭“事件消费者”相关方法:
Shutdown方案和下文实例化watcher那里类似,将关闭“事件消费者”作为事件交于核心逻辑loop方法处理,这样可以保障调用shutdown方法前加入到incoming通道的事件都可以被消费,直到处理完调用shutdown方法前加入到incoming通道的事件才限制往incoming通道加入数据,通过m.distributing.Wait()阻塞可以保障调用Shutdown()后incoming通道的事件都被消费
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 | //停止事件消费者func (e *eventBroadcasterImpl) Shutdown() { e.Broadcaster.Shutdown()}func (m *Broadcaster) Shutdown() { m.blockQueue(func() { close(m.stopped) close(m.incoming) }) m.distributing.Wait()}//这里再粘贴下核心逻辑loop方法,incoming通道关闭后,等incoming中的事件都消费完后,会调用m.closeAll()方法关闭当前“事件消费者”关联的观察者func (m *Broadcaster) loop() { // Deliberately not catching crashes here. Yes, bring down the process if there's a // bug in watch.Broadcaster. for event := range m.incoming { if event.Type == internalRunFunctionMarker { event.Object.(functionFakeRuntimeObject)() continue } m.distribute(event) } m.closeAll() m.distributing.Done()}func (m *Broadcaster) closeAll() { for _, w := range m.watchers { close(w.result) } // Delete everything from the map, since presence/absence in the map is used // by stopWatching to avoid double-closing the channel. m.watchers = map[int64]*broadcasterWatcher{}} |
关闭了incoming,从loop方法可以看出来,将会结束对incoming的遍历动作,关闭所有watcher的result通道,清空watcher。
4.3 broadcasterWatcher事件的处理
eventBroadcasterImpl实现的三种Event的处理方法:
(1)StartLogging:将事件写入日志中。
1 2 3 4 5 6 | func (e *eventBroadcasterImpl) StartLogging(logf func(format string, args ...interface{})) watch.Interface { return e.StartEventWatcher( func(e *v1.Event) { logf("Event(%#v): type: '%v' reason: '%v' %v", e.InvolvedObject, e.Type, e.Reason, e.Message) })} |
(2)StartStructuredLogging:将事件写入结构化日志中。
1 2 3 4 5 6 | func (e *eventBroadcasterImpl) StartStructuredLogging(verbosity klog.Level) watch.Interface { return e.StartEventWatcher( func(e *v1.Event) { klog.V(verbosity).InfoS("Event occurred", "object", klog.KRef(e.InvolvedObject.Namespace, e.InvolvedObject.Name), "kind", e.InvolvedObject.Kind, "apiVersion", e.InvolvedObject.APIVersion, "type", e.Type, "reason", e.Reason, "message", e.Message) })} |
(3)StartRecordingToSink:将事件存储到相应的sink。
1 2 3 4 5 6 7 | func (e *eventBroadcasterImpl) StartRecordingToSink(sink EventSink) watch.Interface { eventCorrelator := NewEventCorrelatorWithOptions(e.options) return e.StartEventWatcher( func(event *v1.Event) { recordToSink(sink, event, eventCorrelator, e.sleepDuration) })} |
NewEventCorrelatorWithOptions方法返回一个EventCorrelator对象(事件相关因子),它主要是用来做事件的聚合的,我们知道一个pod在运行过程中会产生很多事件,比如拉取镜像失败,pod会重试拉取镜像,那么就会产生很多相似的事件,这些事件如果不加以处理,就有可能产生过多的事件资源,对etcd造成很大的压力。
eventBroadcasterImpl实现的三种Event的处理方法都依赖StartEventWatcher方法:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 | func (e *eventBroadcasterImpl) StartEventWatcher(eventHandler func(*v1.Event)) watch.Interface { watcher := e.Watch() //注册watcher到watchers里面 go func() { defer utilruntime.HandleCrash() for watchEvent := range watcher.ResultChan() { event, ok := watchEvent.Object.(*v1.Event) if !ok { continue } //回调传入的方法 eventHandler(event) } }() return watcher} |
逻辑很简单,注册watcher到watchers里面,然后一个for循环,监听watcher的result,有事件的话,就调用传入的参数方法(eventHandler)去处理事件
我们看看e.Watch() 这个方法如何注册的,这块代码很艺术!
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 | // 实例化观察者对象(broadcasterWatcher)并注册到watchers里,键自增func (m *Broadcaster) Watch() Interface { var w *broadcasterWatcher m.blockQueue(func() { id := m.nextWatcher m.nextWatcher++ w = &broadcasterWatcher{ result: make(chan Event, m.watchQueueLength), stopped: make(chan struct{}), id: id, m: m, } m.watchers[id] = w }) if w == nil { // The panic here is to be consistent with the previous interface behavior // we are willing to re-evaluate in the future. panic("broadcaster already stopped") } return w}// 参数f fun()提供了watcher的创建方式func (m *Broadcaster) blockQueue(f func()) { select { case <-m.stopped: return default: } var wg sync.WaitGroup wg.Add(1) m.incoming <- Event{ Type: internalRunFunctionMarker, Object: functionFakeRuntimeObject(func() { //将func(){ defer wg.Done() f() }强制转换成functionFakeRuntimeObject类型,functionFakeRuntimeObject类型实现了runtime.object接口 defer wg.Done() f() }), } wg.Wait()} |
Watch方法做了3件事,声明一个broadcasterWatcher对象,调用blockQueue方法(提供了watcher的创建方式),返回watcher。 blockQueue方法给incoming里面写入了一个事件,而我们生成watcher的方法(入参)被放倒了Event的对象里面,也就是把注册watcher这个动作当成了一个”注册Event“,交给了事件核心处理逻辑去处理了,还记得核心逻辑loop方法吗,再贴一遍loop代码
1 2 3 4 5 6 7 8 9 10 11 12 13 | func (m *Broadcaster) loop() { // Deliberately not catching crashes here. Yes, bring down the process if there's a // bug in watch.Broadcaster. for event := range m.incoming { if event.Type == internalRunFunctionMarker { //来看这里!!!!! event.Object.(functionFakeRuntimeObject)() //调用创建watcher的方法,方法来自blockQueue方法形参 continue } m.distribute(event) } m.closeAll() m.distributing.Done()} |
在接收到一个事件的时候,首先进行了一个事件类型判断,如果是internalRunFunctionMarker (”注册Event“),然后调用里面的方法,完成了watcher的注册。这样有什么好处呢?为什么要搞的这么麻烦,直接注册进去不行吗?我理解这里的意思主要是watcher不监视已经发生的历史数据,只是从注册发生起之后的事件,因为我们的事件都是按照时间顺序排队执行的,所以把注册当成一个事件排在队列里,那么它就能获取到”注册事件“发生之后所有的事件,之前已经产生的事件都不在它的处理范围之内。
前面的sync.WaitGroup问题是因为直到注册动作完成之前都不算注册成功,所以要加一个wait,直到整个注册事件被loop方法执行完成才算注册成功。避免以为注册成功,但是却没有接收到事件的问题。好了,到这里注册的逻辑我们就理清楚了,下面看看StartEventWatcher方法里整个协程里面的动作
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 | func (e *eventBroadcasterImpl) StartEventWatcher(eventHandler func(*v1.Event)) watch.Interface { watcher := e.Watch() go func() { defer utilruntime.HandleCrash() for watchEvent := range watcher.ResultChan() { event, ok := watchEvent.Object.(*v1.Event) if !ok { // This is all local, so there's no reason this should // ever happen. continue } eventHandler(event) } }() return watcher}// 下面是broadcasterWatcher 的结构,以及ResultChan方法,都比较简单,主要是用来说明watcher.ResultChan()type broadcasterWatcher struct { result chan Event //待处理时间存放的缓冲通道 stopped chan struct{} stop sync.Once id int64 //watcher编号 m *Broadcaster //核心结构体,上面有介绍,这里主要是为了停止对应的wather}// ResultChan returns a channel to use for waiting on events.func (mw *broadcasterWatcher) ResultChan() <-chan Event { return mw.result} |
循环遍历watcher的result管道,获取事件,然后调用入参eventHandler函数,执行对事件的处理。
这里再贴一下关闭“观察者”相关方法:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 | func (mw *broadcasterWatcher) Stop() { mw.stop.Do(func() { close(mw.stopped) mw.m.stopWatching(mw.id) })}// stopWatching stops the given watcher and removes it from the list.func (m *Broadcaster) stopWatching(id int64) { m.blockQueue(func() { w, ok := m.watchers[id] if !ok { // No need to do anything, it's already been removed from the list. return } delete(m.watchers, id) close(w.result) })} |
4.4 事件处理逻辑
对于StartLogging、StartStructuredLogging方式,都是把事件信息当做日志打印了一下。这里主要看一下StartRecordingToSink方法,StartRecordingToSink封装的StartEventWatcher方法里面会处理事件消费者分发的事件,并回调recordToSink方法,对收到 events 后会进行缓存、过滤、聚合而后发送到 apiserver,apiserver 会将 events 保存到 etcd 中。下面着重分析下recordToSink方法。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 | func recordToSink(sink EventSink, event *v1.Event, eventCorrelator *EventCorrelator, sleepDuration time.Duration) { // Make a copy before modification, because there could be multiple listeners. // Events are safe to copy like this. eventCopy := *event event = &eventCopy // 复制event result, err := eventCorrelator.EventCorrelate(event) // 聚合 if err != nil { utilruntime.HandleError(err) } if result.Skip { // 跳过记录此事件 return } tries := 0 // 重试 for { if recordEvent(sink, result.Event, result.Patch, result.Event.Count > 1, eventCorrelator) { //记录事件,true代表成功或者忽略错误,跳出循环 break } tries++ if tries >= maxTriesPerEvent { //重试12次退出 klog.Errorf("Unable to write event '%#v' (retry limit exceeded!)", event) break } // Randomize the first sleep so that various clients won't all be // synced up if the master goes down. if tries == 1 { time.Sleep(time.Duration(float64(sleepDuration) * rand.Float64())) //第一次间隔事件随机 } else { time.Sleep(sleepDuration) //从个第二次起间隔事件正常。 } }} |
recordToSink方法首先会调用EventCorrelate方法对event做预处理,聚合相同的事件,避免产生的事件过多,增加 etcd 和 apiserver 的压力,如果传入的Event太多了,那么result.Skip 就会返回false;
接下来会调用recordEvent方法把事件发送到 apiserver,它会重试很多次(默认是 12 次),并且每次重试都有一定时间间隔(默认是 10 秒钟)。
下面我们分别来看看EventCorrelate方法和recordEvent方法。
- EventCorrelate
1 2 3 4 5 6 7 8 9 10 11 12 13 | 文件位置:client-go/tools/record/events_cache.go// client-go/tools/record/events_cache.gofunc (c *EventCorrelator) EventCorrelate(newEvent *v1.Event) (*EventCorrelateResult, error) { if newEvent == nil { return nil, fmt.Errorf("event is nil") } aggregateEvent, ckey := c.aggregator.EventAggregate(newEvent) observedEvent, patch, err := c.logger.eventObserve(aggregateEvent, ckey) if c.filterFunc(observedEvent) { return &EventCorrelateResult{Skip: true}, nil } return &EventCorrelateResult{Event: observedEvent, Patch: patch}, err} |
EventCorrelate方法会调用EventAggregate、eventObserve进行聚合,调用filterFunc会调用到spamFilter.Filter方法进行过滤。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 | func (e *EventAggregator) EventAggregate(newEvent *v1.Event) (*v1.Event, string) { now := metav1.NewTime(e.clock.Now()) var record aggregateRecord eventKey := getEventKey(newEvent) aggregateKey, localKey := e.keyFunc(newEvent) e.Lock() defer e.Unlock() // 查找缓存里面是否也存在这样的记录 value, found := e.cache.Get(aggregateKey) if found { record = value.(aggregateRecord) } // maxIntervalInSeconds默认时间是600s,这里校验缓存里面的记录是否太老了 // 如果是那么就创建一个新的 // 如果record在缓存里面找不到,那么lastTimestamp是零,那么也创建一个新的 maxInterval := time.Duration(e.maxIntervalInSeconds) * time.Second interval := now.Time.Sub(record.lastTimestamp.Time) if interval > maxInterval { record = aggregateRecord{localKeys: sets.NewString()} } record.localKeys.Insert(localKey) record.lastTimestamp = now // 重新加入到LRU缓存中 e.cache.Add(aggregateKey, record) // 如果没有达到阈值,那么不进行聚合 if uint(record.localKeys.Len()) < e.maxEvents { return newEvent, eventKey } record.localKeys.PopAny() eventCopy := &v1.Event{ ObjectMeta: metav1.ObjectMeta{ Name: fmt.Sprintf("%v.%x", newEvent.InvolvedObject.Name, now.UnixNano()), Namespace: newEvent.Namespace, }, Count: 1, FirstTimestamp: now, InvolvedObject: newEvent.InvolvedObject, LastTimestamp: now, // 将Message进行聚合 Message: e.messageFunc(newEvent), Type: newEvent.Type, Reason: newEvent.Reason, Source: newEvent.Source, } return eventCopy, aggregateKey} |
EventAggregate方法也考虑了很多,首先是去缓存里面查找有没有相同的聚合记录aggregateRecord,如果没有的话,那么会在校验时间间隔的时候顺便创建聚合记录aggregateRecord;
由于缓存时lru缓存,所以再将聚合记录重新Add到缓存的头部;
接下来会判断缓存是否已经超过了阈值,如果没有达到阈值,那么直接返回不进行聚合;
如果达到阈值了,那么会重新copy传入的Event,并调用messageFunc方法聚合Message;
- eventObserve
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 | func (e *eventLogger) eventObserve(newEvent *v1.Event, key string) (*v1.Event, []byte, error) { var ( patch []byte err error ) eventCopy := *newEvent event := &eventCopy e.Lock() defer e.Unlock() // 检查是否在缓存中 lastObservation := e.lastEventObservationFromCache(key) // 如果大于0说明存在,并且对Count进行自增 if lastObservation.count > 0 { event.Name = lastObservation.name event.ResourceVersion = lastObservation.resourceVersion event.FirstTimestamp = lastObservation.firstTimestamp event.Count = int32(lastObservation.count) + 1 eventCopy2 := *event eventCopy2.Count = 0 eventCopy2.LastTimestamp = metav1.NewTime(time.Unix(0, 0)) eventCopy2.Message = "" newData, _ := json.Marshal(event) oldData, _ := json.Marshal(eventCopy2) patch, err = strategicpatch.CreateTwoWayMergePatch(oldData, newData, event) } // 最后重新更新缓存记录 e.cache.Add( key, eventLog{ count: uint(event.Count), firstTimestamp: event.FirstTimestamp, name: event.Name, resourceVersion: event.ResourceVersion, }, ) return event, patch, err} |
eventObserve方法里面会去查找缓存中的记录,然后对count进行自增后更新到缓存中。
5、使用示例
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 | const (// SuccessSynced is used as part of the Event 'reason' when a Foo is syncedsuccessSynced = "Synced"// is synced successfullymessageResourceSynced = "User synced successfully")//创建事件消费者eventBroadcaster := record.NewBroadcaster()//以打印日志的方式处理事件消费者分发的事件eventBroadcaster.StartLogging(klog.Infof)//以上报apiserver方式处理事件消费者分发的事件eventBroadcaster.StartRecordingToSink(&typedcorev1.EventSinkImpl{Interface: k8sClient.CoreV1().Events("")})//创建事件生产者recorder := eventBroadcaster.NewRecorder(scheme.Scheme, corev1.EventSource{Component: controllerName})//事件生产者创建事件c.recorder.Event(user, corev1.EventTypeNormal, successSynced, messageResourceSynced) |
StartRecordingToSink会调用StartEventWatcher,StartEventWatcher方法里面会异步的调用 watcher.ResultChan()方法获取到broadcasterWatcher的result管道,result管道里面的数据就是Broadcaster的distribute方法进行分发的。
6、总结
了解完 events 的整个处理流程后,再梳理一下整个流程:
-
首先是初始化 EventBroadcaster 对象,同时会初始化一个 Broadcaster 对象,并开启一个loop循环接收所有的 events 并进行广播;
- 定义处理事件的方式,EventBroadcaster 会调用StartStructuredLogging或StartRecordingToSink方法调用封装好的StartEventWatcher方法,并执行自己的逻辑;
-
然后通过 EventBroadcaster 对象的 NewRecorder() 方法初始化 EventRecorder 对象,EventRecorder 对象会生成 events 并通过ActionOrDrop() 方法发送 events 到 Broadcaster 的 channel 队列中;
-
StartRecordingToSink封装的StartEventWatcher方法里面会处理事件消费者分发的事件,并调用recordToSink方法,对收到 events 后会进行缓存、过滤、聚合而后发送到 apiserver,apiserver 会将 events 保存到 etcd 中。
参考:https://blog.csdn.net/weixin_45413603/article/details/108204904
参考:https://www.cnblogs.com/yangyuliufeng/p/13942789.html
参考:https://blog.csdn.net/weixin_36086263/article/details/119958216


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· Manus重磅发布:全球首款通用AI代理技术深度解析与实战指南
· 被坑几百块钱后,我竟然真的恢复了删除的微信聊天记录!
· 没有Manus邀请码?试试免邀请码的MGX或者开源的OpenManus吧
· 【自荐】一款简洁、开源的在线白板工具 Drawnix
· 园子的第一款AI主题卫衣上架——"HELLO! HOW CAN I ASSIST YOU TODAY
2017-02-24 apache-storm-1.0.3安装部署
2017-02-24 Hadoop2.7.3+spark2.1.0+hbase0.98分布式集群部署
2017-02-24 /etc/security/limits.conf的相关说明