
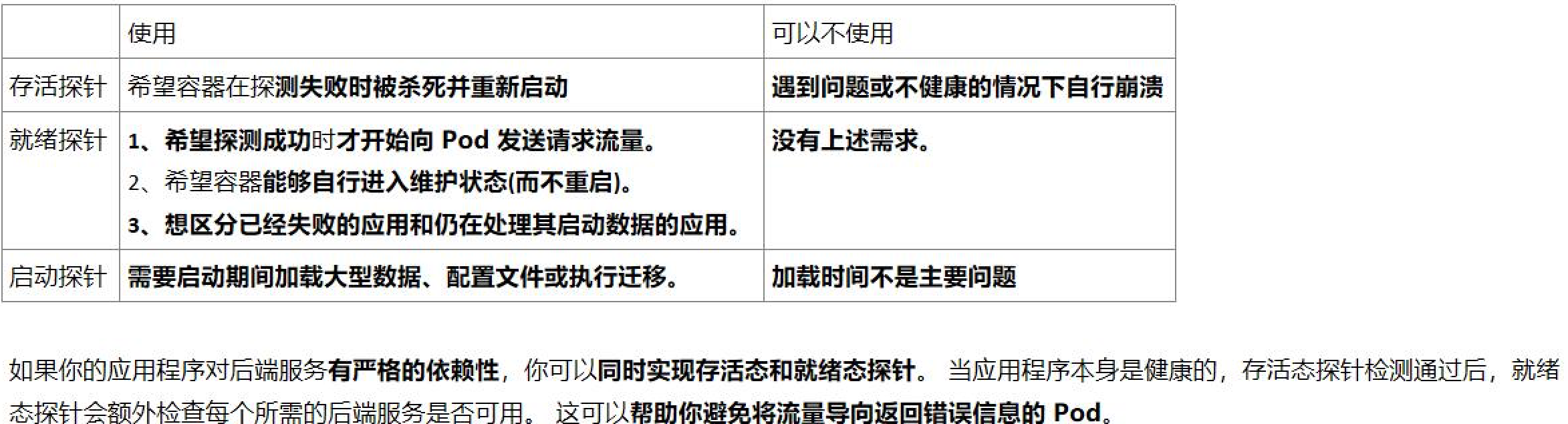
Kubernetes 就绪探针(Readiness Probe)
一个新Pod创建后,Service就能立即选择到它,并会把请求转发给Pod,那问题就来了,通常一个Pod启动是需要时间的,如果Pod还没准备好(可能需要时间来加载配置或数据,或者可能需要执行一个预热程序之类),这时把请求转给Pod的话,Pod也无法处理,造成请求失败。
Kubernetes解决这个问题的方法就是给Pod加一个业务就绪探针Readiness Probe,当检测到Pod就绪后才允许Service将请求转给Pod。
Readiness Probe同样是周期性的检测Pod,然后根据响应来判断Pod是否就绪,与存活探针(Liveness Probe)相同,就绪探针也支持如下三种类型。
- HTTP GET:Probe往容器的IP:Port发送HTTP GET请求,如果Probe收到2xx或3xx,说明已经就绪。
- TCP Socket:Probe尝试与容器建立TCP连接,如果能建立连接,说明已经就绪。
- Exec:Probe执行容器中的命令并检查命令退出的状态码,如果状态码为0,说明已经就绪。
注意 1:与就绪探针对应的还有一个存活探针(Liveness Probe),详细介绍请参见《Kubernetes存活探针(Liveness Probe)》这篇博文。
Readiness Probe的工作原理
通过Endpoints就可以实现Readiness Probe的效果,当Pod还未就绪时,将Pod的IP:Port从Endpoints中删除,Pod就绪后再加入到Endpoints中,如下图所示。

HTTP GET
Readiness Probe的配置与存活探针(livness probe)一样,都是在Pod Template的containers里面,如下所示,这个Readiness Probe向Pod发送HTTP请求,当Probe(探头,Kubelet中创建的HTTP客户端)收到2xx或3xx返回时,说明Pod已经就绪。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 | apiVersion: apps/v1kind: Deploymentmetadata: name: nginxspec: replicas: 3 selector: matchLabels: app: nginx template: metadata: labels: app: nginx spec: containers: - image: nginx:alpine name: container-0 resources: limits: cpu: 100m memory: 200Mi requests: cpu: 100m memory: 200Mi readinessProbe: # readinessProbe httpGet: # HTTP GET定义 path: /read port: 80 imagePullSecrets: - name: default-secret |
TCP Socket
TCP Socket(Kubelet中创建的TCP客户端)尝试与容器指定端口建立TCP连接,如果连接成功建立,说明容器是健康的。同样,TCP Socket类型的探针如下所示。1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 | apiVersion: apps/v1kind: Deploymentmetadata: name: nginxspec: replicas: 3 selector: matchLabels: app: nginx template: metadata: labels: app: nginx spec: containers: - image: nginx:alpine name: container-0 resources: limits: cpu: 100m memory: 200Mi requests: cpu: 100m memory: 200Mi readinessProbe: # readinessProbe tcpSocket: # TCP Socket定义 port: 80 imagePullSecrets: - name: default-secret |
Exec
Exec即执行具体命令,具体机制是Probe执行容器中的命令(Kubelet调用CRI接口进入容器内部执行命令)并检查命令退出的状态码,如果状态码为0则说明健康,定义方法如下所示。这个探针执行ls /ready命令,如果这个文件存在,则返回0,说明Pod就绪了,否则返回其他状态码。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 | apiVersion: apps/v1kind: Deploymentmetadata: name: nginxspec: replicas: 3 selector: matchLabels: app: nginx template: metadata: labels: app: nginx spec: containers: - image: nginx:alpine name: container-0 resources: limits: cpu: 100m memory: 200Mi requests: cpu: 100m memory: 200Mi readinessProbe: # Readiness Probe exec: # 定义 ls /ready 命令 command: - ls - /ready imagePullSecrets: - name: default-secret |
将上面Deployment的定义保存到deploy-read.yaml文件中,删除之前创建的Deployment,用deploy-read.yaml创建这个Deployment。
1 2 3 4 5 | # kubectl delete deploy nginxdeployment.apps "nginx" deleted# kubectl create -f deploy-read.yamldeployment.apps/nginx created |
这里由于nginx镜像不包含/ready这个文件,所以在创建完成后容器不在Ready状态,如下所示,注意READY这一列的值为0/1,表示容器没有Ready。
1 2 3 4 5 | # kubectl get poNAME READY STATUS RESTARTS AGEnginx-7955fd7786-686hp 0/1 Running 0 7snginx-7955fd7786-9tgwq 0/1 Running 0 7snginx-7955fd7786-bqsbj 0/1 Running 0 7s |
创建Service。
1 2 3 4 5 6 7 8 9 10 11 12 13 | apiVersion: v1kind: Servicemetadata: name: nginx spec: selector: app: nginx ports: - name: service0 targetPort: 80 port: 8080 protocol: TCP type: ClusterIP |
查看Service,发现Endpoints一行的值为空,表示没有Endpoints。
1 2 3 4 5 | $ kubectl describe svc nginxName: nginx......Endpoints: ...... |
如果此时给容器中创建一个/ready的文件,让Readiness Probe成功,则容器会处于Ready状态。再查看Pod和Endpoints,发现创建了/ready文件的容器已经Ready,Endpoints也已经添加。
1 2 3 4 5 6 7 8 9 10 11 | # kubectl exec nginx-7955fd7786-686hp -- touch /ready# kubectl get po -o wideNAME READY STATUS RESTARTS AGE IPnginx-7955fd7786-686hp 1/1 Running 0 10m 192.168.93.169 nginx-7955fd7786-9tgwq 0/1 Running 0 10m 192.168.166.130nginx-7955fd7786-bqsbj 0/1 Running 0 10m 192.168.252.160# kubectl get endpointsNAME ENDPOINTS AGEnginx 192.168.93.169:80 14d |
此时删除nginx-7955fd7786-686hp容器的/ready文件,会发现容器处于Not Ready状态,endpoints里面的Pod地址信息也会删除掉,并且容器重启次数还是0。这说明就绪探针的作用只是会在service负载中去掉非就绪的容器,但是并不会重启容器,所以为了让容器进行重启需要配合存活探针一起使用。
Readiness Probe高级配置
与Liveness Probe相同,Readiness Probe也有同样的高级配置选项,上面nginx Pod的describe命令回显有中有如下行。
1 | Readiness: exec [ls /var/ready] delay=0s timeout=1s period=10s #success=1 #failure=3 |
这一行表示Readiness Probe的具体参数配置,其含义如下:
- delay=0s 表示容器启动后立即开始探测,没有延迟时间
- timeout=1s 表示容器必须在1s内做出相应反馈给probe,否则视为探测失败
- period=10s 表示每10s探测一次
- #success=1 表示探测连续1次成功表示成功
- #failure=3 表示探测连续3次失败
这些是创建时默认设置的,您也可以手动配置,如下所示。
1 2 3 4 5 6 7 8 9 10 | readinessProbe: # Readiness Probe exec: # 定义 ls /readiness/ready 命令 command: - ls - /readiness/ready initialDelaySeconds: 10 # 容器启动后多久开始探测 timeoutSeconds: 2 # 表示容器必须在2s内做出相应反馈给probe,否则视为探测失败 periodSeconds: 30 # 探测周期,每30s探测一次 successThreshold: 1 # 连续探测1次成功表示成功 failureThreshold: 3 # 连续探测3次失败表示失败 |
注意:就算就绪探针探测连续失败次数超过failureThreshold也不会重启Pod,通过describe pod可以查看检测失败次数。

总结:
注意 1:就绪探针不只在容器启动加载阶段很有用,通过就绪探针还可以实现在容器负载高或应用程序响应变慢时,暂时将该容器从负载均衡中移除,以避免向其发送请求。这可以提供更好的用户体验和应用程序可用性。
当容器负载过高或应用程序响应变慢时,就绪探针可以失败,从而将该容器的就绪状态标记为不可用。此时,负载均衡器将不再将流量转发给该容器,从而将请求发送到其他可用的容器上。这样,负载将被分散到其他能够正常处理请求的容器上,减轻了负载过高的容器的压力,同时也避免了用户接收到响应较慢的请求。
当容器负载降低或应用程序恢复正常时,就绪探针将返回成功,将该容器的就绪状态标记为可用。此时,负载均衡器将重新将流量转发给该容器,使其恢复处理请求。
通过利用就绪探针的这种机制,可以提高应用程序的可用性和性能。它允许容器在负载过高或应用程序暂时不可用时进行自我调节,避免了因负载过高导致整个应用程序不可用的情况。同时,这也为应用程序提供了一种缓解负载压力和平滑恢复的机制,以保证用户的请求得到及时响应。
注意 2:单纯通过就绪探针来暂时不访问负载高的实例无法解决程序根本问题。
如果所有 Pod 实例都面临负载过高的情况,并且将某个节点标记为不可用,以将流量转发给其他节点上的容器,这可能导致所有实例都面临过载和崩溃的风险。
在负载高压力下,负载均衡器通常会将请求转发到可用的实例中,以分散负载并提供更好的性能。然而,如果所有实例都承受着相同的高负载,而没有足够的可用实例来分担负载,那么整个系统可能会面临性能问题、响应延迟或甚至崩溃。
在这种情况下,单纯通过就绪探针来暂时不访问负载高的实例可能无法解决根本问题。需要采取其他措施来应对高负载的情况,例如:
水平扩展:增加实例的数量,以便更好地分担负载。通过增加实例数,系统能够处理更多的并发请求,提高整体的性能和可扩展性。
垂直扩展:增加每个实例的资源(例如 CPU、内存),以提高单个实例的处理能力。这可以通过升级节点的硬件规格或增加 Pod 的资源请求来实现。
负载均衡策略:根据实际情况,调整负载均衡器的策略。例如,可以使用加权轮询(Weighted Round Robin)或基于负载情况的算法,将流量更均匀地分发到各个实例上。
自动伸缩:设置自动伸缩机制,根据实际负载情况动态地调整实例数量。这可以根据指标(如 CPU 使用率、请求队列长度等)自动增加或减少实例数量,以满足负载的需求。
综上所述,就绪探针在提高应用程序的可用性和性能方面发挥着重要作用,但在负载过高的情况下,需要综合考虑其他因素,并采取相应的扩展和负载均衡策略来应对高负载的挑战。
注意 3:就绪探针的作用只是会在service负载中去掉非就绪的容器,但是并不会重启容器,所以如果想让容器进行重启需要配合存活探针一起使用。
参考:https://support.huaweicloud.com/basics-cce/kubernetes_0026.html


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· .NET Core 中如何实现缓存的预热?
· 从 HTTP 原因短语缺失研究 HTTP/2 和 HTTP/3 的设计差异
· AI与.NET技术实操系列:向量存储与相似性搜索在 .NET 中的实现
· 基于Microsoft.Extensions.AI核心库实现RAG应用
· Linux系列:如何用heaptrack跟踪.NET程序的非托管内存泄露
· TypeScript + Deepseek 打造卜卦网站:技术与玄学的结合
· 阿里巴巴 QwQ-32B真的超越了 DeepSeek R-1吗?
· 【译】Visual Studio 中新的强大生产力特性
· 张高兴的大模型开发实战:(一)使用 Selenium 进行网页爬虫
· 【设计模式】告别冗长if-else语句:使用策略模式优化代码结构
2014-12-07 HDU1556:Color the ball(简单的线段树区域更新)
2014-12-07 HDU1698:Just a Hook(线段树区域更新模板题)
2014-12-07 32位的二进制数
2014-12-07 HDU5139:Formula(找规律+离线处理)