Kubernetes常见错误总结
1、屏幕持续打印Pod日志报error: unexpected EOF错误
Kubernetes: requesting flag for "kubectl logs" to avoid 5-minute timeout if no stdout/stderr
When running kubectl logs --follow on a pod, after 5 minutes of no stdout/stderr, we received:
$ kubectl --kubeconfig=config --namespace=foo logs --follow foo-oneoff-w8npn --container bar ###################################### # # # /system_tests/test_derp.py (1/4) # # # ###################################### RESULTS: [/system_tests/test_derp/TestDerp] Ran 4 tests in 130.044 s, ALL TESTS PASSED ###################################### # # # /system_tests/test_fuzz.py (2/4) # # # ###################################### error: unexpected EOF
解决方案:
For posterity, the problem here is that we're using haproxy to serve a VIP to balance HA Kubernetes masters.
Specifically we're using HA-Proxy v1.4.21, and we have this in our haproxy cfg:
defaults timeout client 500000 timeout server 500000

2、K8s集群初始化成功后,kubectl get nodes 查看节点信息时报错
报错信息:The connection to the server localhost:8080 was refused - did you specify the right host or port?
解决方法:
mkdir -p $HOME/.kube sudo cp -i /etc/kubernetes/admin.conf $HOME/.kube/config sudo chown $(id -u):$(id -g) $HOME/.kube/config
3、master节点的calico组件是0/1 Running状态,其他worker节点的calico组件是1/1 Running状态,describe pod发现是
Readiness probe failed: calico/node is not ready: BIRD is not ready: BGP not established with 10.244.0.1,10.244.2.12020-04-13 06:29:59.582 [INFO][682] health.go 156: Number of node(s) with BGP peering established = 0
解决办法:
修改的calico.yaml,新增两行:
- name: IP_AUTODETECTION_METHOD
value: "interface=eth0"
value指向从ip a看到的实际网卡名。结果如下:
# Cluster type to identify the deployment type
- name: CLUSTER_TYPE
value: "k8s,bgp"
- name: IP_AUTODETECTION_METHOD
value: "interface=eth0"
# Auto-detect the BGP IP address.
- name: IP
value: "autodetect"
# Enable IPIP
- name: CALICO_IPV4POOL_IPIP
value: "Always"
等一会就正常了。
参考:https://blog.csdn.net/majixiang1996/article/details/105438506/
4、使用kubeadm安装kubernetes集群etcd一直卡在starting状态,查看etcd日志报2020-12-08 17:11:10.741954 I | embed: rejected connection from "192.168.100.179:47288" (error "tls: failed to verify client‘s certificate: x509: certificate has expired or is not yet valid", ServerName "") 错误
错误分析:原因是生成证书的机器时间快于etcd服务器时间,导致服务器验证时,证书超出了时间使用范围。
解决办法:
1)服务器和生成证书机器进行时间同步更新(高可用k8s集群需要master节点之间时间同步)。
2)或者直接调整生成证书的机器时间,使其慢于其他节点服务器的时间。
不推荐第二种方式。
参考:http://www.bubuko.com/infodetail-3670080.html
5、如果使用nfs作为存储方案所有节点都需要保证安装好nfs-client
检查服务器是否已安装好nfs-utils、rpcbind、libtirpc包。
参考:http://www.bubuko.com/infodetail-3546759.html
6、报错 cannot allocate memory 或者 no space left on device ,修复K8S内存泄露问题
链接:https://www.cnblogs.com/zhangmingcheng/p/14309962.html
7、执行kubectl命令时报错 error: You must be logged in to the server (Unauthorized)
链接:https://www.cnblogs.com/zhangmingcheng/p/14317551.html
8、kubectl delete pod kube-scheduler-xxxx -n=kube-system 后,这个pod没有重启直接删掉了,重启kubelet服务使调度器pod重启
9、关于在k8s-v1.20以上版本使用nfs作为storageclass出现selfLink was empty, can‘t make reference错误
问题原因:kubernetes 1.20版本 禁用了 selfLink
解决方法(每个master节点都要执行):
vim /etc/kubernetes/manifests/kube-apiserver.yaml
新增配置: - --feature-gates=RemoveSelfLink=false
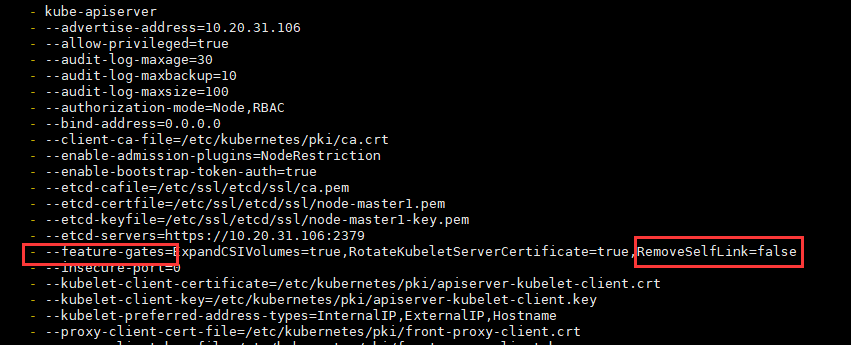
由于kube-apiserver是静态Pod,修改完静态Pod声明文件(kube-apiserver.yaml)后,无需apply最新的声明文件(kube-apiserver.yaml),即可自动修改静态Pod配置。静态Pod详细内容见:Kubernetes静态Pod
10、k8s 集群 metrics-server 组件报 authentication.go:65] Unable to authenticate the request due to an error: x509: certificate has expired or is not yet valid 错误
原因 :k8s集群证书更新后没有自动重启对应的组件
解决方法:
执行如下命令后解决
docker ps |grep -E 'k8s_kube-apiserver|k8s_kube-controller-manager|k8s_kube-scheduler|k8s_etcd_etcd' | awk -F ' ' '{print $1}' |xargs docker restart
链接:https://www.cnblogs.com/ligang0357/p/15561680.html
11、kubelet 报如下错误:failed to run Kubelet: running with swap on is not supported, please disable swap! or set --fail-swap-on flag to false. /proc/swaps contained: [Filename...
原因: 当前机器没有关闭swap,关闭当前机器swap即可。
链接:https://www.cnblogs.com/zhangmingcheng/p/12671749.html
12、使用systemctl cat kubelet命令可以看到通过systemd配置的与kubelet有关的所有配置文件的路径与内容
[root@zmc-manage-uat-106 ~]# systemctl cat kubelet # /etc/systemd/system/kubelet.service [Unit] Description=kubelet: The Kubernetes Node Agent Documentation=http://kubernetes.io/docs/ [Service] ExecStart=/usr/local/bin/kubelet Restart=always StartLimitInterval=0 RestartSec=10 [Install] WantedBy=multi-user.target # /etc/systemd/system/kubelet.service.d/10-kubeadm.conf # Note: This dropin only works with kubeadm and kubelet v1.11+ [Service] Environment="KUBELET_KUBECONFIG_ARGS=--bootstrap-kubeconfig=/etc/kubernetes/bootstrap-kubelet.conf --kubeconfig=/etc/kubernetes/kubelet.conf" Environment="KUBELET_CONFIG_ARGS=--config=/var/lib/kubelet/config.yaml" # This is a file that "kubeadm init" and "kubeadm join" generate at runtime, populating the KUBELET_KUBEADM_ARGS variable dynamically EnvironmentFile=-/var/lib/kubelet/kubeadm-flags.env # This is a file that the user can use for overrides of the kubelet args as a last resort. Preferably, the user should use # the .NodeRegistration.KubeletExtraArgs object in the configuration files instead. KUBELET_EXTRA_ARGS should be sourced from this file. EnvironmentFile=-/etc/default/kubelet Environment="KUBELET_EXTRA_ARGS=--node-ip=10.20.31.106 --hostname-override=zmc-manage-uat-106 " ExecStart= ExecStart=/usr/local/bin/kubelet $KUBELET_KUBECONFIG_ARGS $KUBELET_CONFIG_ARGS $KUBELET_KUBEADM_ARGS $KUBELET_EXTRA_ARGS [root@zmc-manage-uat-106 ~]#
参考:https://www.cnblogs.com/wangqingyong/p/14542937.html
13、kubectl get cs显示scheduler Unhealthy、controller-manager Unhealthy错误
[root@node1 ~]# kubectl get componentstatuses
Warning: v1 ComponentStatus is deprecated in v1.19+
NAME STATUS MESSAGE ERROR
scheduler Unhealthy Get "http://127.0.0.1:10251/healthz": dial tcp 127.0.0.1:10251: connect: connection refused
controller-manager Unhealthy Get "http://127.0.0.1:10252/healthz": dial tcp 127.0.0.1:10252: connect: connection refused
etcd-0 Healthy {"health":"true"}
错误分析:
1)首先确认没有启动10251、10252端口
netstat -ntlup
2)确认schedule和controller-manager组件配置是否禁用了非安全端口
解决方法:
分别修改/etc/kubernetes/manifests/kube-scheduler.yaml和/etc/kubernetes/manifests/kube-controller-manager.yaml配置文件,将容器启动参数中 --port=0注释掉,该--port=0表示禁止使用非安全的http接口。下面以修改调度器配置文件为例,控制器配置文件修改和调度器一致。
containers:
- command:
- kube-scheduler
- --authentication-kubeconfig=/etc/kubernetes/scheduler.conf
- --authorization-kubeconfig=/etc/kubernetes/scheduler.conf
- --bind-address=0.0.0.0
- --feature-gates=ExpandCSIVolumes=true,RotateKubeletServerCertificate=true
- --kubeconfig=/etc/kubernetes/scheduler.conf
- --leader-elect=true
# - --port=0
重启kubelet服务
systemctl restart kubelet
问题解决:
[root@node1 ~]# kubectl get cs
NAME STATUS MESSAGE ERROR
controller-manager Healthy ok
scheduler Healthy ok
etcd-0 Healthy {"health":"true"}
再次通过netstat -ntlup命令验证10251、10252端口是否监听:
....... tcp6 0 0 :::10250 :::* LISTEN 20137/kubelet tcp6 0 0 :::10251 :::* LISTEN 13290/kube-schedule ......
14、configmap中json或者yaml文件内容格式问题
1)问题现象说明:
比如我有一个yaml格式的配置文件config.yaml,内容如下:
service:
port: 8001
# release
mode: release
url: kube-prometheus.monitoring
port: 9090
common:
file:
upload: /opt/data/common/file/
把该配置文件使用configmap方式创建:
kubectl create configmap myconfig --from-file=config.yaml
我们希望在命令行终端查看到的内容如下:
[root@node1 ~]# kubectl get configmaps myconfig -o yaml
apiVersion: v1
data:
config.yaml: |
service:
port: 8001
# release
mode: release
url: kube-prometheus.monitoring
port: 9090
common:
file:
upload: /opt/data/common/file/
kind: ConfigMap
metadata:
creationTimestamp: 2019-04-24T05:59:52Z
name: myconfig
namespace: default
resourceVersion: "1774515"
selfLink: /api/v1/namespaces/default/configmaps/myconfig
uid: 2d066fef-6656-11e9-96e0-005056bf291a
[root@node1 ~]#
但是有时候我们看到如下格式错乱的configmap内容:
[root@intellif-0 ~]# kubectl get configmaps myconfig -o yaml
apiVersion: v1
data:
config.yaml: "service:\n port: 8001\n # release\n mode: release\n url: kube-prometheus.monitoring\n
\ port: 9090\ncommon:\n file:\n upload: /opt/data/common/file/ \n"
kind: ConfigMap
metadata:
creationTimestamp: 2019-04-24T06:01:42Z
name: myconfig
namespace: default
resourceVersion: "1774818"
selfLink: /api/v1/namespaces/default/configmaps/myconfig
uid: 6eac963e-6656-11e9-96e0-005056bf291a
[root@intellif-0 ~]#
2)分析与解决:
问题原因: 文件中某一行结尾有空格,示例中是最后一行(使用vim工具:set invlist)
正常的yaml文件
# vim config.yaml
service:$
port: 8001$
# release$
mode: release$
url: kube-prometheus.monitoring$
port: 9090$
common:$
file:$
upload: /opt/data/common/file/$
~
:set invlist
异常的yaml文件
# vim config.yaml
service:$
port: 8001$
# release$
mode: release$
url: kube-prometheus.monitoring$
port: 9090$
common:$
file:$
upload: /opt/data/common/file/ $
~
:set invlist
参考:https://blog.csdn.net/zhangxiangui40542/article/details/89491740
15、kubelet日志报不能检索密钥,导致拉取镜像不成功问题
kubelet日志:
kubelet: W1104 18:34:07.882008 843 kubelet_pods.go:863] Unable to retrieve pull secret pro/gb28181server for pro/xxxserver-v1-76cc9b558d-wmbgf due to secret "gb28181server" not found. The image pull may not succeed.
问题分析:
检查Pod的Yaml文件,发现配置文件中配置了gb28181server这个镜像拉取密钥,但实际当前Pod所在namespace下面是没有这个密钥的。
apiVersion: v1 kind: Pod metadata: ...... spec: ....... enableServiceLinks: true imagePullSecrets: - name: gb28181server nodeName: 129 ........
解决方案:
1)如果镜像所在harbor项目是公开项目的话,那么kubelet是有权限直接拉取镜像的,这种情况下可以删掉Pod Yaml文件中的imagePullSecrets配置项;
2)如果镜像所在harbor项目是私有项目的话,那么必须创建认证harbor私有仓库的gb28181server密钥。
参考:kubernetes的imagePullSecrets如何生成及使用 - 走看看
16、Centos7服务器Kubernetes新加入节点访问外部域名不通问题
背景:某项目Kubernetes集群新纳入了12台worker节点,新纳入节点和其他集群节点(master节点和worker节点)网络都是连通的,但是项目实施人员却反馈调度到这12台节点上容器组内部是连不通外部域名的,直接在这12台节点上访问外部域名正常。
问题分析:节点上访问外部域名正常,说明节点dns server配置是没问题的;而容器内部访问不通很可能是以下问题导致:
1)集群dns组件(coredns)异常,但是老节点上的容器组内部是能正常解析外部域名的,所以排除此原因;
2)新加入节点存在未开的端口策略,经检查防火墙策略单及相应测试,也都没问题;
3)容器组配置了错误的 dns server,经测试新节点不仅外部域名不通,k8s内部服务也访问不通,所以基本锁定容器组节点配置了错误的dns server,经检查确实如此。
检查Kubernetes集群DNS服务地址:
[root@master1 ~]# kubectl get svc -n=kube-system |grep dns coredns ClusterIP 10.234.0.3 <none> 53/UDP,53/TCP,9153/TCP 115d
检查新加入节点容器组DNS配置:
vim /var/lib/kubelet/config.yaml xxxxx clusterDNS: - xxx.xxx.xxx.xxx clusterDomain: cluster.local xxxxx
经排查两者dns server不一致。
解决方案:修改新加入节点容器组DNS配置。
vim /var/lib/kubelet/config.yaml xxxxx clusterDNS: - 10.234.0.3 clusterDomain: cluster.local xxxxx
重启新加节点kubelet服务和容器运行时服务,问题得以解决。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号