

hadoop的文件存储格式parquet
hadoop 里支持许多压缩算法。压缩的好处主要有两点:1. 减少了文件占用的存储空间,原来上 T 的文件可能压缩完以后只需要两三百 G 的空间即可;2. 文件的体积小了以后,数据传输的速度自然就快了。在现在的大数据环境下,这两点显得更加重要。所以现在 hdfs 文件系统上存的文件,如果数据量大到一定程度,都需要经过压缩处理。
hadoop 上常用的压缩格式包括 gzip,lzo,snappy,bzip2。以下我们对这四种压缩算法做个对比。
1.gzip
优点:压缩比高,压缩解压的速度也比较快。hadoop 本身就支持,自带相关处理 gzip 文件的 jar 包。换句话说,你可以像处理普通的文本文件一样处理 gzip 压缩文件。缺点:不支持 split。这个就很要命了,不支持 split,那就意味着无论多大的 gzip 文件,hadoop 在处理的时候都只分配一个 mapper 给这个文件。这显然是不行的。应用场景:当每个文件压缩之后都在 128M 以内时,都可以考虑 gzip。(因为 hadoop 默认的是给 128M 分配一个 mapper)不过这条件,实在是太蛋疼。。。所以本博主工作这么些年,从来没有在 hdfs 上见过 gzip 的压缩文件。。。
2.lzo
优点:合理的压缩比,压缩解压速度也比较快。最最最重要的是,支持 split,所以本博主工作这么些年,hdfs 上的文件,一般都采用 lzo 压缩。缺点:压缩比相对 gzip 第一点。但是相比能 split 这一点,基本可以忽略。hadoop 本身没有自带 lzo,需要再安装 lzo 相关的库。在实际使用时,需要对 lzo 文件建索引,否则 hadoop 也是会把 lzo 文件看成一个文件滴。另外在写 mr 相关代码时,需要setInputFormatClass(LzoTextInputFormat.class);
应用场景:hadoop 上最流行的压缩格式。本博主实战中接触到的压缩格式都是用的他。
3.snappy 压缩
优点:合理的压缩比,高速压缩速度,支持 hadoop native 库缺点:不支持 split,压缩比低于 gzip。也需要安装应用场景:好吧,本博主没用过这种。暂时不太清楚。
4.bzip2 压缩
优点:支持 split,很高的压缩比,比 gzip 还高。hadoop 本身也支持缺点:压缩 解压速度慢。这个就比较吃亏了,因为压缩是很耗 cpu 的操作,如果用他的话集群资源就全被他占了,所以一般实际中用 lzo 而不用他。应用场景:肯定就是对压缩比要求很高,但对速度要求不是那么苛刻的场合了。
说明:此方案已经我们已经运行 1 年。
1、场景描述:
我们对客户登录日志做了数据仓库,但实际业务使用中有一些个共同点,
A 需要关联维度表
B 最终仅取某个产品一段时间内的数据
C 只关注其中极少的字段
基于以上业务,我们决定每天定时统一关联维度表,对关联后的数据进行另外存储。各个业务直接使用关联后的数据进行离线计算。
2、择 parquet 的外部因素
在各种列存储中,我们最终选择 parquet 的原因有许多。除了 parquet 自身的优点,还有以下因素
A、公司当时已经上线 spark 集群,而 spark 天然支持 parquet,并为其推荐的存储格式 (默认存储为 parquet)。
B、hive 支持 parquet 格式存储,如果以后使用 hiveql 进行查询,也完全兼容。
3、选择 parquet 的内在原因
下面通过对比 parquet 和 csv,说说 parquet 自身都有哪些优势
csv 在 hdfs 上存储的大小与实际文件大小一样。若考虑副本,则为实际文件大小 * 副本数目。(若没有压缩)
3.1 parquet 采用不同压缩方式的压缩比
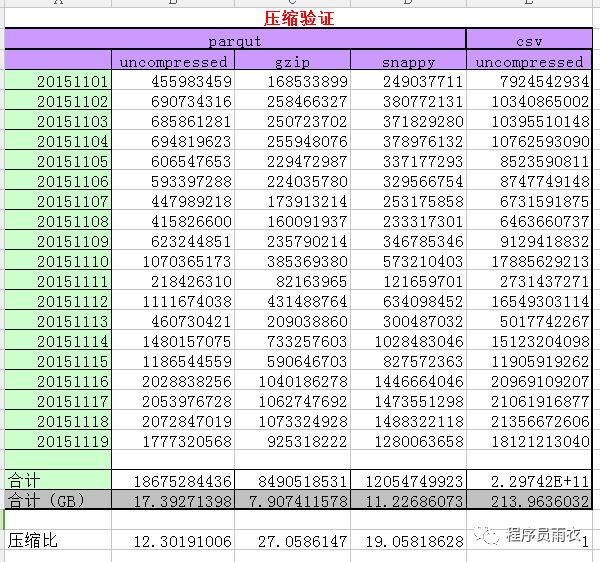
说明:原始日志大小为 214G 左右,120 + 字段
采用 csv(非压缩模式)几乎没有压缩。
采用 parquet 非压缩模式、gzip、snappy 格式压缩后分别为 17.4G、8.0G、11G,达到的压缩比分别是:12、27、19。
若我们在 hdfs 上存储 3 份,压缩比仍达到 4、9、6 倍
3.2 分区过滤与列修剪
3.2.1 分区过滤
parquet 结合 spark,可以完美的实现支持分区过滤。如,需要某个产品某段时间的数据,则 hdfs 只取这个文件夹。
spark sql、rdd 等的 filter、where 关键字均能达到分区过滤的效果。
使用 spark 的 partitionBy 可以实现分区,若传入多个参数,则创建多级分区。第一个字段作为一级分区,第二个字段作为 2 级分区。。。。。
3.2.2 列修剪
列修剪:其实说简单点就是我们要取回的那些列的数据。
当取得列越少,速度越快。当取所有列的数据时,比如我们的 120 列数据,这时效率将极低。同时,也就失去了使用 parquet 的意义。
3.2.3 分区过滤与列修剪测试如下:
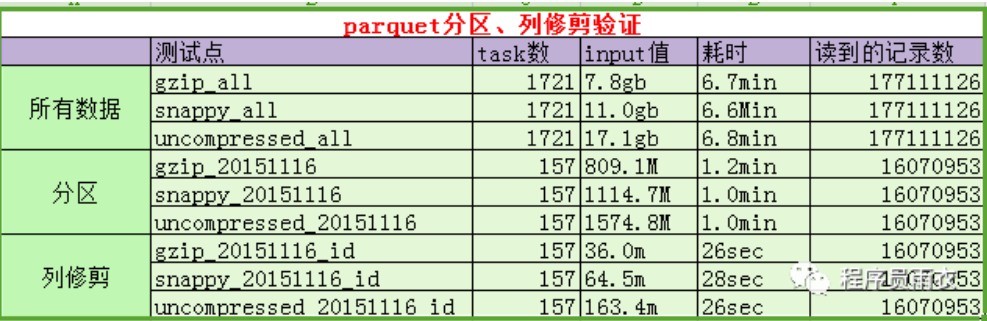
说明:
A、task 数、input 值、耗时均为 spark web ui 上的真实数据。
B、之所以没有验证 csv 进行对比,是因为当 200 多 G,每条记录为 120 字段时,csv 读取一个字段算个 count 就直接 lost excuter 了。
C、注意:为避免自动优化,我们直接打印了每条记录每个字段的值。(以上耗时估计有多部分是耗在这里了)
D、通过上图对比可以发现:
-
当我们取出所有记录时,三种压缩方式耗时差别不大。耗时大概 7 分钟。
-
当我们仅取出某一天时,parquet 的分区过滤优势便显示出来。仅为 6 分之一左右。貌似当时全量为七八天左右吧。
-
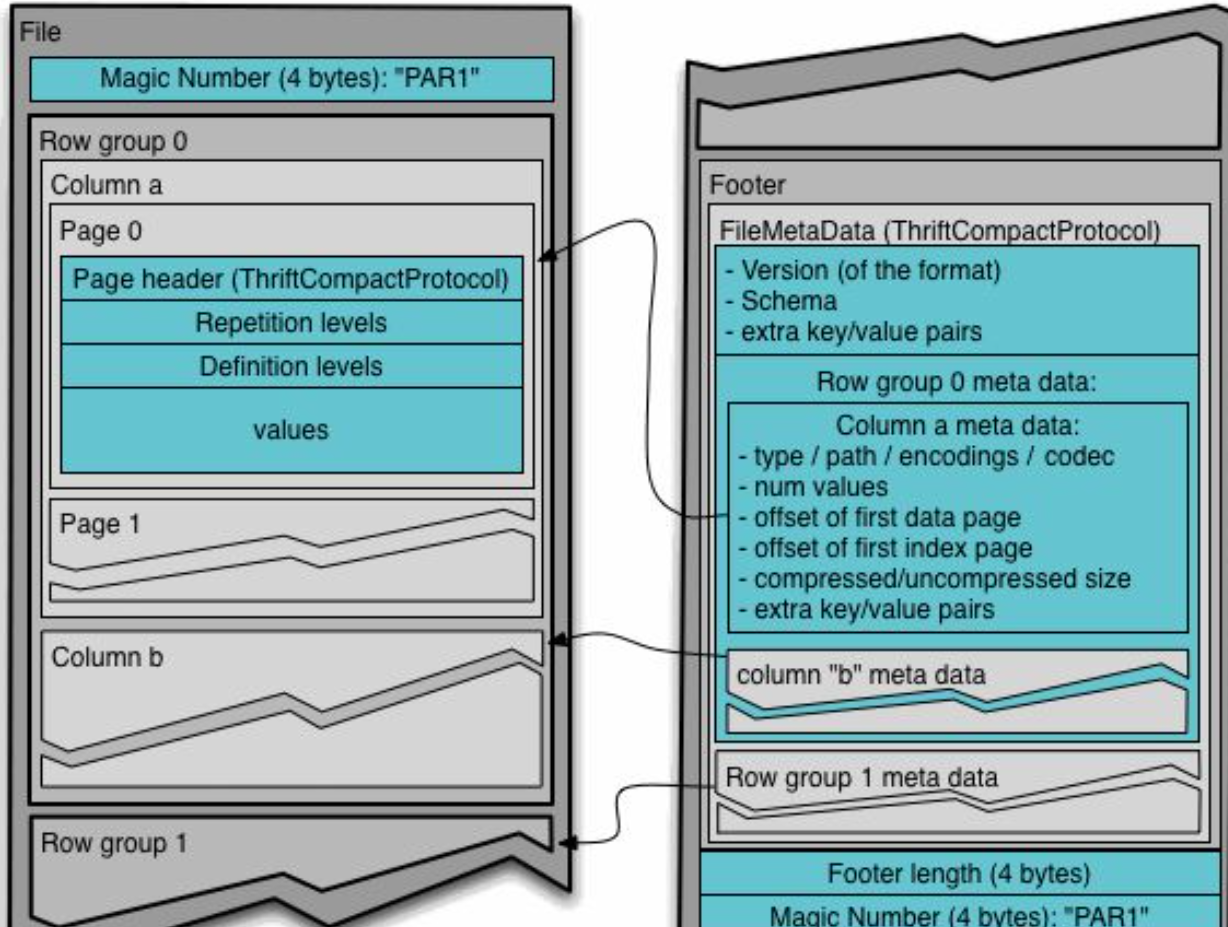
当我们仅取某一天的一个字段时,时间将再次缩短。这时,硬盘将只扫描该列所在 rowgroup 的柱面。大大节省 IO。如有兴趣,可以参考 深入分析 Parquet 列式存储格式
-
E、测试时请开启 filterpushdown 功能
4、结论
-
parquet 的 gzip 的压缩比率最高,若不考虑备份可以达到 27 倍。可能这也是 spar parquet 默认采用 gzip 压缩的原因吧。
-
分区过滤和列修剪可以帮助我们大幅节省磁盘 IO。以减轻对服务器的压力。
-
如果你的数据字段非常多,但实际应用中,每个业务仅读取其中少量字段,parquet 将是一个非常好的选择。
仅学习使用,文章转载自:https://www.modb.pro/db/133916


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 震惊!C++程序真的从main开始吗?99%的程序员都答错了
· 【硬核科普】Trae如何「偷看」你的代码?零基础破解AI编程运行原理
· 单元测试从入门到精通
· 上周热点回顾(3.3-3.9)
· winform 绘制太阳,地球,月球 运作规律