


今日刷题总结4
自动类型转换(C语言)
(1)若参与运算的变量类型不同,则先转换成同一类型再进行运算。
(2)转换按数据长度或者精度增加的方向进行。若两种类型的数据长度相同并且精度相同,而符号不同,则将有符号转换为无符号。
(3)所有的浮点运算都是以双精度进行的,即使表达式仅含float类型变量,也要先转换成double。
(4)char型和short型(在visual c++等环境下)参与运算时,必须先转换成int型。
(5)在赋值运算中,赋值号两边量的数据类型不同时,赋值号右边变量的类型将转换为左边变量的类型。如果右边变量的数据类型长度比左边长时,将丢失一部分数据,这样会降低精度,丢失的部分直接舍去。
数据库范式
第一范式(1NF):数据库表的每一列都是不可分割的原子数据项。所有关系数据库至少满足1NF。
第二范式(2NF):满足2NF必先满足1NF。2NF要求实体属性完全依赖于主关键字,完全依赖是指不存在只依赖于主关键字一部分的属性。简单来说就是选取一个能区分每个实体的属性或属性组,作为实体的唯一标识,这样数据库表中的每个实例或记录可以被唯一地区分。
第三范式(3NF):满足3NF必先满足2NF。任何非主属性不依赖于其它非主属性(传递依赖于主属性)。简单来说就是在一个关系中不包含已在其它关系中包含的非主关键字信息。
BC范式(BCNF):任何非主属性不能对主键子集依赖(在3NF基础上消除对主码子集的依赖)。
重载与重写
重载:是指允许存在多个同名函数,而这些函数的参数表不同(或许参数个数不同,或许参数类型不同,或许两者都不同)。
重写:是指子类重新定义父类虚函数的方法。
从实现原理上来说:
重载:编译器根据函数不同的参数表,对同名函数的名称做修饰,然后这些同名函数就成了不同的函数(至少对于编译器来说是这样的)。如有两个同名函数:function func(p:integer):integer;和function func(p:string):integer;。那么编译器做过修饰后的函数名称可能是这样的:int_func、str_func。对于这两个函数的调用,在编译器间就已经确定了,是静态的。也就是说,它们的地址在编译期就绑定了(早绑定),因此,重载和多态无关!
重写:和多态真正相关。当子类重新定义了父类的虚函数后,父类指针通过指向不同的子类对象,动态的调用该子类重写的虚函数,这样的函数调用在编译期间是无法确定的(调用的子类的虚函数的地址无法给出)。因此,这样的函数地址是在运行期绑定的(晚绑定)。
参考https://www.nowcoder.com/test/question/done?tid=9452786&qid=15074#summary
程序IO方式:是采用busy-waiting的方式,即CPU会采用轮询的方式来询问数据,效果最差
中断IO方式:设备控制器取出一个数据之后向CPU发送一个中断,然后CPU将数据从控制器中取到CPU寄存器,再然后转移到内存中。这种方式下CPU是以字节的方式来响应数据的。
DMA方式:CPU通过向DMA控制器设定若干参数,然后DMA打开了一条内存到设备的通道,这样设备(内存)中的数据可以不通过CPU来进行数据交互。缺点是,有多少设备就需要多少DMA,而且DMA方式下,CPU的访问设备是以数据块为周期的。
IO通道方式:IO通道相当于一个简单的处理机,有自己的指令,也可以执行指令。指令存储在内存。 IO通道相当于一条PCI总线,一条IO通道可以连接所有的设备控制器。然后CPU向IO通道发出指令,IO通道将会自动进行获取数据。 另外,IO通道是以一组块为单位进行获取的。 所以,IO通道方式需要最少的CPU干预。
内存分配算法
首次适应(first fit):从空闲分区表的第一个表目起查找该表,把最先能够满足要求的空闲区分配给作业,这种方法目的在于减少查找时间。为适应这种算法,空闲分区表(空闲区链)中的空闲分区要按地址由低到高进行排序。该算法优先使用低址部分空闲区,在低址空间造成许多小的空闲区,在高地址空间保留大的空闲区。
循环首次适应(next fit):在分配内存空间时,不再每次从表头(链首)开始查找,而是从上次找到空闲区的下一个空闲区开始查找,直到找到第一个能满足要求的的空闲区为止,并从中划出一块与请求大小相等的内存空间分配给作业。该算法能使内存中的空闲区分布得较均匀。
最佳适应(best fit):从全部空闲区中找出能满足作业要求的、且大小最小的空闲分区,这种方法能使碎片尽量小。为适应此算法,空闲分区表(空闲区链)中的空闲分区要按从小到大进行排序,自表头开始查找到第一个满足要求的自由分区分配。该算法保留大的空闲区,但造成许多小的空闲区。
最坏适应(worst fit):该算法要求将所有的空闲分区按其容量从大到小的顺序形成一空闲分区链,查找时只要看第一个分区能否满足作业要求。优点是可使剩下的空闲分区不至于太小,产生碎片的几率最小,对中、小作业有利,同时该算法查找效率很高。缺点是会使内存中缺乏大的空闲分区。
进程主要组成部分
(1)程序:描述进程要完成的功能。
(2)数据:程序在执行时所需要的数据和工作区。
(3)PCB:包含进程的描述信息和控制信息。它是进程存在的唯一标志。
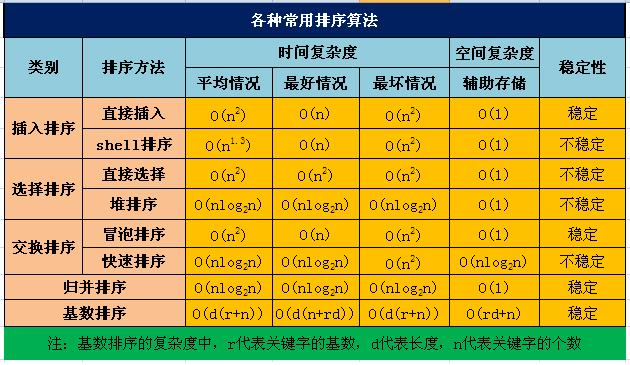
各类排序算法的复杂度
posted on 2017-07-30 17:45 yifangzhuhou 阅读(133) 评论(0) 编辑 收藏 举报

