

吴恩达老师机器学习课程学习--课时七
课时七 正则化
1、过拟合
过拟合问题是指我们利用某个机器学习算法在一个训练集上训练出的模型,在该训练集上效果很好,但是到其他数据集上测试,效果并不好,这就是过拟合。
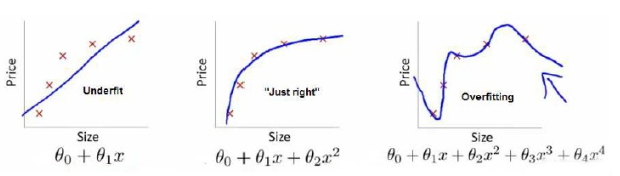
上图中第一张图是欠拟合,不能很好地适应训练集,第三张图是过拟合,过于强调拟合原始数据,预测新数据会表现很差,中间的模型最为合适。
解决过拟合的问题,一般有两种解决方法:
1、丢弃一些不能帮助我们正确预测的特征。可以通过手工选择保留哪些特征,或者利用一些模型算法来帮忙。
2、利用正则化,保留所有特征,但是减小参数大小。
2、正则化
假设我们的回归模型是如下的:
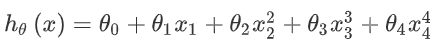
我们知道是因为假设函数中的高次项导致了过拟合,所以正则化的思想就是尽量减小这些高次项的参数值。做法就是修改代价函数,为x3和x4的参数设置一些惩罚,修改后的代价函数:
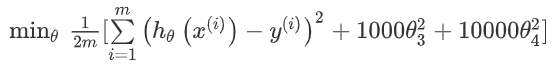
这样做的话,如果我们要求代价函数尽量小,那么就必须让参数θ3和θ4尽可能的小,因为他们前面乘了一个很大的数1000。
上面是一个特例,普遍来看,修改后的代价函数:
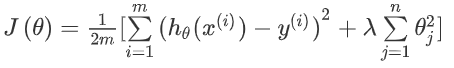
注意:我们不对θ0设置惩罚,并且要选好参数λ的值,这样才能更好地应用正则化。
3、正则化线性回归
正则化线性回归的代价函数:
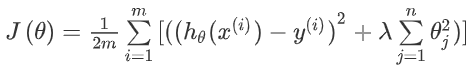
如果我们要用梯度下降算法寻找参数的话,要注意,我们没有对θ0正则化,所以,梯度下降算法要分两段:
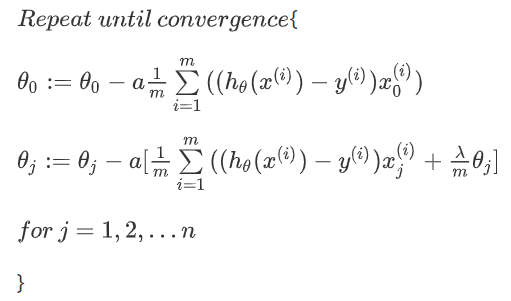
经过化简,θj的可化成下面:
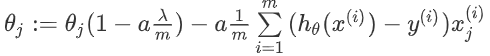
利用正规方程来求解正则化线性回归模型的方法:
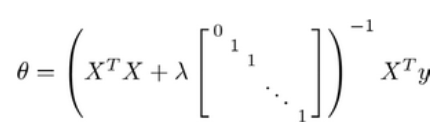
图中矩阵尺寸为(n+1)*(n+1)
4、正则化逻辑回归



正则化的内容我只是简单的理解了它是用来防止过拟合的,其中的原理细节理解的还不算透彻,以后希望能彻底搞懂。
以上就是课时七的内容,部分笔记来自“机器学习初学者”网站提供的吴恩达老师的2014机器学习课程笔记http://www.ai-start.com/

