机器学习第一章复习
第一章概述
在第一章的学习中,主要讲述了机器学习与模式识别的一些基本概念和一些基础公式。还有模式识别的一些应用。这里列出一些知识点。
模式识别的概念
模式识别主要分为 分类和回归两个动作。
在课中,模式识别的概念为根据已有知识的表达,针对待识别模式,判别决策其所属的类别,或预测其对于应的回归值。
对于模式识别的数学解释,可以理解为:一种函数映射f(x),将待识别的模式x从输入空间映射到输出空间。函数f(x)是已有知识的表达。
模型
模型的概念
关于已有的知识的一种表达方式,即函数f(x)
模型的组成
特征提取:是指从原始输入数据提取出更有效的信息
回归器:的作用是将特征映射到回归值。
模型(广义)=特征提取+回归器+判别函数
模型(狭义)=特征提取+回归器
分类器=回归器+判别函数
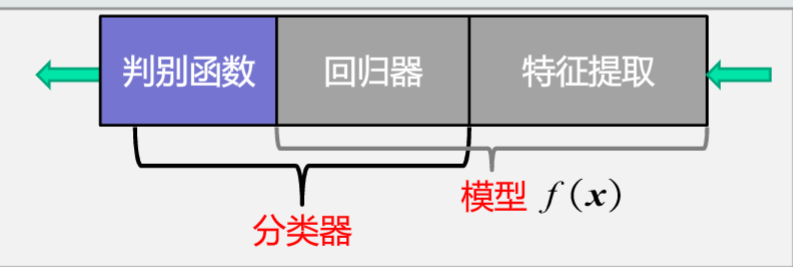
总之回归器是关键
判别器可以分为二类分类和多类分类。二类分类通过回归值的正负来确定分类的。而多类分类是通过最大值来确定分类的。
因为判别函数通常已知固定,所以不能把它当作模型的一部分。
特征
特征是指用于区分不同类别模式的、可测量的量
比如说用于区分橙子和苹果的颜色,形状等因素。
特征的判别能力
特征具有判别能力,可以提升不同类别之间的识别性能。基于统计学规律,而非个例(就是说是普遍存在的,而不是这个样本的某一个特征用来区分)
特征的鲁棒性
针对不同的观测条件,仍能够有效表达类别之间的差异性。
特征向量
特征向量是指多个特征构成的(列)向量
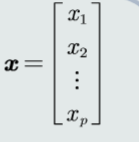
特征向量的长度就是向量的模。
特征向量的方向就是特征向量除去它的模长
特征空间
就是每个坐标轴表示一个特征
然后空间中和坐标原点相连的向量代表着该模式的特征向量
特征向量点积
特征向量点积就是向量的点积
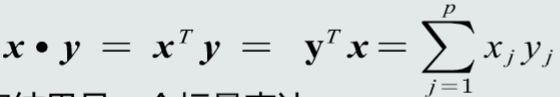
正如向量的点积一样,它是个标量。
特征向量的计算值为

点积的几何定义
点积可以代表两个特征向量的共线性,即方向上的相似度。
点积为0说明两个向量在方向上是正交的。
两个向量的夹角反应了方向上的差异性。
由计算向量之间的夹角公式得特征向量之间的夹角如下:
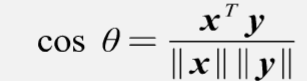
特征向量投影
向量x到向量y的投影是向量x垂直投射到向量y方向上的长度。所以投影是个标量。
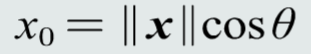
投影的含义是向量x分解到向量y方向上的长度。能够分接越多,说明两个向量方向上越相似。
残差向量
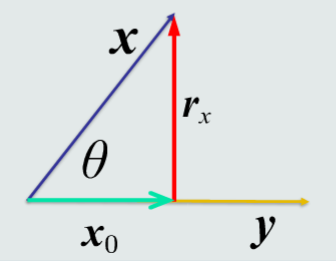
如图所示,r就是残差向量
特征向量的欧式距离
两个特征向量的欧式距离可以表示两个向量间的相似程度(包含方向和长度)
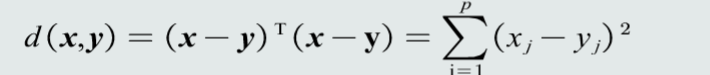
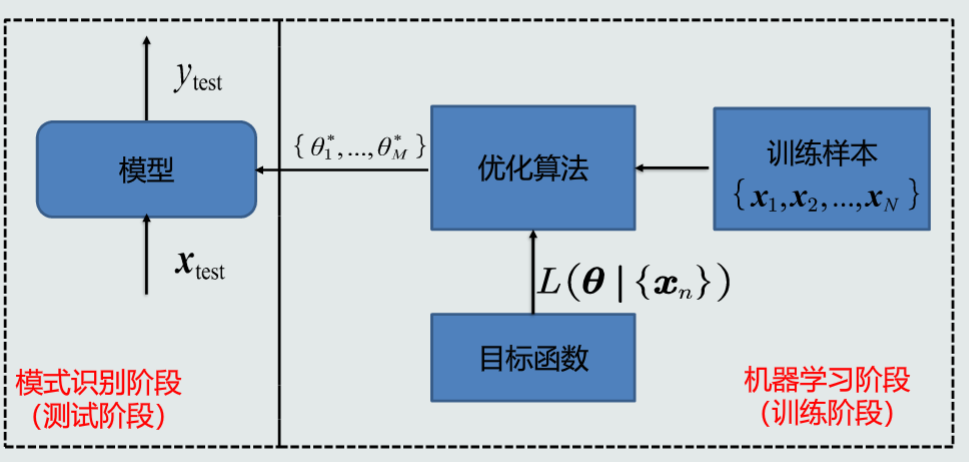
机器学习的基本概念
机器学习的流程示意图
机器学习的分类
机器学习分为监督式学习,无监督式学习,半监督式学习,强化学习
监督式学习
监督式学习指的是你拥有一个输入变量和一个输出变量,使用某种算法去学习从输入到输出的映射函数
算法学习从训练数据集学习的过程可以被看成类似于一名教师在监督学习学习的过程。我们已经知道了正确的答案,而算法不断迭代来对训练数据做出预测同时不断被一名教师修正。当算法达到一个可接受程度的表现时学习过程停止。
监督式学习问题可以进一步被分为回归和分类问题
分类:分类问题指的是当输出变量属于一个范畴,比如“红色”和“蓝色”或者“生病”和“未生病”。
回归:回归问题指的是输出变量是一个实值,比如“价格”和“重量”
无监督式学习
非监督式学习指的是只拥有输入变量但是没有相关的输出变量。
非监督式学习的目标是对数据中潜在的结构和分布建模,以便对数据作更进一步的学习。
这种学习方式就称为非监督式学习,因为其和监督式学习不同,对于学习并没有确切的答案和学习过程也没有教师监督。算法独自运行以发现和表达数据中的有意思的结构。
非监督式学习问题可以进一步分为聚类问题和关联问题
聚类问题:聚类学习问题指的是我们想在数据中发现内在的分组,比如以购买行为对顾客进行分组。
关联问题:关联问题学习问题指的是我们想发现数据的各部分之间的联系和规则,例如购买X物品的顾客也喜欢购买Y物品。
半监督式学习
当拥有大部分的输入数据但是只有少部分的数据拥有标签,这种情形称为半监督式学习问题
半监督式学习问题介于监督式和非监督式学习之间。这里有一个好例子如:照片分类,但是只有部分照片带有标签(如,狗、猫和人),但是大部分照片都没有标签。
许多现实中的机器学习问题都可以归纳为这一类。因为对数据打标签需要专业领域的知识,这是费时费力的。相反无标签的数据和收集和存储起来都是方便和便宜的。
可以使用非监督式学习的技术来发现和学习输入变量的结构。
也可以使用监督式学习技术对无标签的数据进行标签的预测,把这些数据传递给监督式学习算法作为训练数据,然后使用这个模型在新的数据上进行预测。
模型的泛化能力
泛化能力是指,训练得到的模型不仅要对训练样本要具有决策能力,还要对新的模式具有决策能力。
训练样本存在的一些问题
1、训练样本稀疏:给定的训练样本数量是有限的,很难完整表达样本的真实分布
2、训练样本采样过程可能不均匀:有些区域采样密一些,有些区域采样疏一些
3、一些样本可能带有噪声
过拟合
模型训练阶段表现很好,但是在测试阶段表现差
模型过于拟合训练
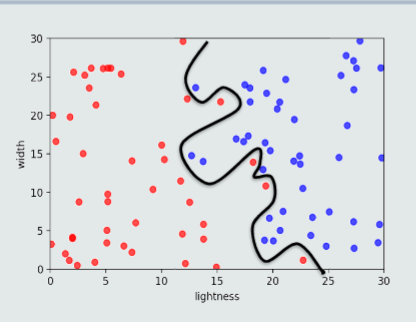
如何提高泛化能力
1、选择复杂度适合的模型:模型选择
2、正则化:在目标函数中加入正则项
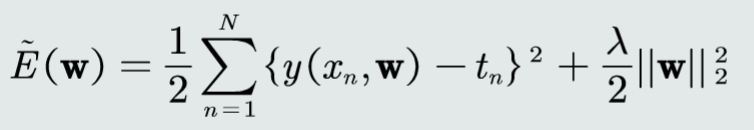
评估方法与性能指标
留出法
留出法直接将数据集D划分为两个互斥的部分,其中一部分作为训练集S,另一部分用作测试集T。
通常训练集和测试集的比例为70%:30%。同时,训练集测试集的划分有两个注意事项:
1. 尽可能保持数据分布的一致性。避免因数据划分过程引入的额外偏差而对最终结果产生影响。在分类任务中,保留类别比例的采样方法称为“分层采样”(stratified sampling)。
2. 采用若干次随机划分避免单次使用留出法的不稳定性。
交叉验证法(cross validation)
交叉验证法先将数据集D划分为k个大小相似的互斥子集,每次采用k−1个子集的并集作为训练集,剩下的那个子集作为测试集。进行k次训练和测试,最终返回k个测试结果的均值。又称为“k折交叉验证”(k-fold cross validation)。
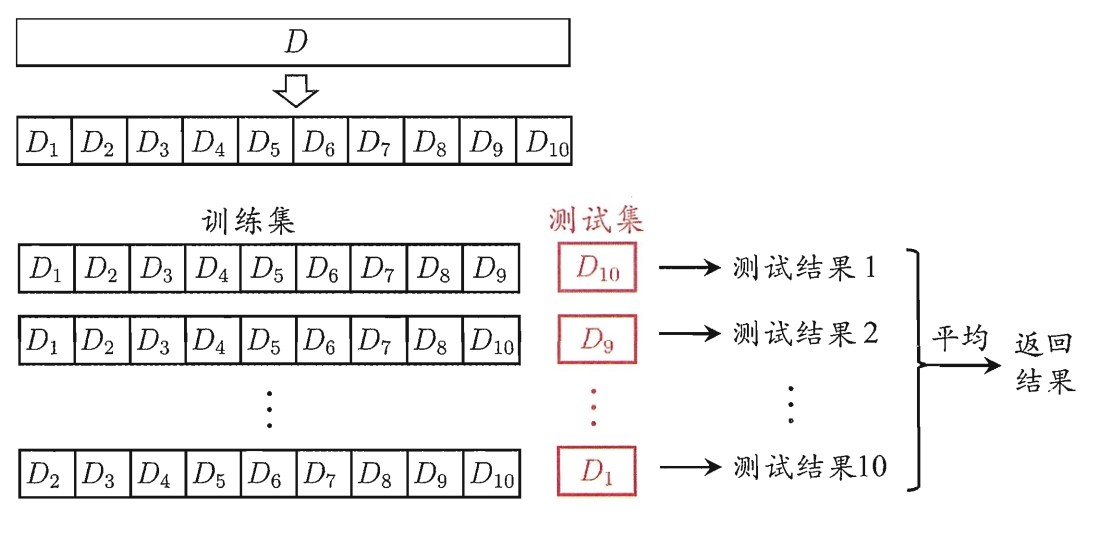
为减少因样本划分带来的偏差,通常重复p次不同的划分,最终结果是p次k折交叉验证结果的均值。
留一法(leave-one-out,LOO)
留一法是k折交叉验证k=m(m为样本数)时候的特殊情况。即每次只用一个样本作测试集。该方法计算开销较大。
性能度量
二分类问题常用的评价指标时查准率和查全率。
根据预测正确与否,将样例分为以下四种:
1)True positive(TP): 真正例,将正类正确预测为正类数;
2)False positive(FP): 假正例,将负类错误预测为正类数;
3)False negative(FN):假负例,将正类错误预测为负类数;
4)True negative(TN): 真负例,将负类正确预测为负类数。
查准率(precision,精确率):
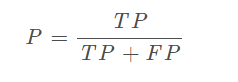
即将正类预测为正类数与预测为正类的总数的比值。
查全率(recall,召回率)
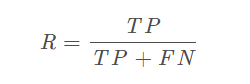
即将正类预测为正类数与正类总数的比值。
查准率和查全率是一对矛盾的度量。是查准率和查全率的调和平均:
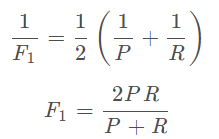

 浙公网安备 33010602011771号
浙公网安备 33010602011771号