


10.11 总结
笔试:
1. hashmap 与 treemap ,collections.synchronizemap 和 concurrenthashmap 的区别
而ConcurrentHashMap是DougLea的util.concurrent包的一部分,现已被集成到JDK5.0中,它提供比Hashtable或者synchronizedMap更高程度的并发性。而且,对于大多数成功的get()操作它会设法避免完全锁定,其结果就是使得并发应用程序有着非常好的吞吐量。
1 针对吞吐量进行优化
ConcurrentHashMap使用了几个技巧来获得高程度的并发以及避免锁定,包括为不同的hashbucket(桶)使用多个写锁和使用JMM的不确定性来最小化锁被保持的时间——或者根本避免获取锁。对于大多数一般用法来说它是经过优化的,这些用法往往会检索一个很可能在map中已经存在的值。事实上,多数成功的get()操作根本不需要任何锁定就能运行。(警告:不要自己试图这样做!想比JMM聪明不像看上去的那么容易。util.concurrent类是由并发专家编写的,并且在JMM安全性方面经过了严格的同行评审。)
2 多个写锁
我们可以回想一下,Hashtable(或者替代方案Collections.synchronizedMap)的可伸缩性的主要障碍是它使用了一个map范围(map-wide)的锁,为了保证插入、删除或者检索操作的完整性必须保持这样一个锁,而且有时候甚至还要为了保证迭代遍历操作的完整性保持这样一个锁。这样一来,只要锁被保持,就从根本上阻止了其他线程访问Map,即使处理器有空闲也不能访问,这样大大地限制了并发性。
ConcurrentHashMap摒弃了单一的map范围的锁,取而代之的是由32个锁组成的集合,其中每个锁负责保护hashbucket的一个子集。锁主要由变化性操作(put()和remove())使用。具有32个独立的锁意味着最多可以有32个线程可以同时修改map。这并不一定是说在并发地对map进行写操作的线程数少于32时,另外的写操作不会被阻塞——32对于写线程来说是理论上的并发限制数目,但是实际上可能达不到这个值。但是,32依然比1要好得多,而且对于运行于目前这一代的计算机系统上的大多数应用程序来说已经足够了。
3 map范围的操作
有32个独立的锁,其中每个锁保护hashbucket的一个子集,这样需要独占访问map的操作就必须获得所有32个锁。一些map范围的操作,比如说size()和isEmpty(),也许能够不用一次锁整个map(通过适当地限定这些操作的语义),但是有些操作,比如map重排(扩大hashbucket的数量,随着map的增长重新分布元素),则必须保证独占访问。Java语言不提供用于获取可变大小的锁集合的简便方法。必须这么做的情况很少见,一旦碰到这种情况,可以用递归方法来实现。
4 JMM概述
在进入put()、get()和remove()的实现之前,让我们先简单地看一下JMM。JMM掌管着一个线程对内存的动作(读和写)影响其他线程对内存的动作的方式。由于使用处理器寄存器和预处理cache来提高内存访问速度带来的性能提升,Java语言规范(JLS)允许一些内存操作并不对于所有其他线程立即可见。有两种语言机制可用于保证跨线程内存操作的一致性——synchronized和volatile。
按照JLS的说法,“在没有显式同步的情况下,一个实现可以自由地更新主存,更新时所采取的顺序可能是出人意料的。”其意思是说,如果没有同步的话,在一个给定线程中某种顺序的写操作对于另外一个不同的线程来说可能呈现出不同的顺序,并且对内存变量的更新从一个线程传播到另外一个线程的时间是不可预测的。
虽然使用同步最常见的原因是保证对代码关键部分的原子访问,但实际上同步提供三个独立的功能——原子性、可见性和顺序性。原子性非常简单——同步实施一个可重入的(reentrant)互斥,防止多于一个的线程同时执行由一个给定的监视器保护的代码块。不幸的是,多数文章都只关注原子性方面,而忽略了其他方面。但是同步在JMM中也扮演着很重要的角色,会引起JVM在获得和释放监视器的时候执行内存壁垒(memorybarrier)。
一个线程在获得一个监视器之后,它执行一个读屏障(readbarrier)——使得缓存在线程局部内存(比如说处理器缓存或者处理器寄存器)中的所有变量都失效,这样就会导致处理器重新从主存中读取同步代码块使用的变量。与此类似,在释放监视器时,线程会执行一个写屏障(writebarrier)——将所有修改过的变量写回主存。互斥独占和内存壁垒结合使用意味着只要您在程序设计的时候遵循正确的同步法则(也就是说,每当写一个后面可能被其他线程访问的变量,或者读取一个可能最后被另一个线程修改的变量时,都要使用同步),每个线程都会得到它所使用的共享变量的正确的值。
2. 计算斐波那契数
public class FibonacciPrint{
public static void main(String args[]){
int n = Integer.parseInt(args[0]);
FibonacciPrint t = new FibonacciPrint();
for(int i=1;i<=n;i++){
t.print(i);}}
public void print(int n){
int n1 = 1;//第一个数
int n2 = 1;//第二个数
int sum = 0;//和
if(n<=0){System.out.println("参数错误!");
return;}
if(n<=2){ sum = 1;
}else{
for(int i=3;i<=n;i++){
sum = n1+n2;
n1 = n2;
n2 = sum;}}
System.out.print(sum+" ");}}
3. 实现序列化接口Serialize的时候,如果不指定serialVersionUID 的值,编译时就会出现警告,为什么?什么情况下需要修改serialVersionUID 的值?
参 考:序列化运行时使用一个称为 serialVersionUID 的版本号与每个可序列化类相关联,该序列号在反序列化过程中用于验证序列化对象的发送者和接收者是否为该对象加载了与序列化兼容的类。如果接收者加载的该 对象的类的 serialVersionUID 与对应的发送者的类的版本号不同,则反序列化将会导致 InvalidClassException。可序列化类可以通过声明名为 "serialVersionUID" 的字段(该字段必须是静态 (static)、最终 (final) 的 long 型字段)显式声明其自己的 serialVersionUID:
ANY-ACCESS-MODIFIER static final long serialVersionUID = 42L;
如果可序列化类未显式声明 serialVersionUID,则序列化运行时将基于该类的各个方面计算该类的默认 serialVersionUID 值,如“Java(TM) 对象序列化规范”中所述。不过,强烈建议 所有可序列化类都显式声明 serialVersionUID 值,原因计算默认的 serialVersionUID 对类的详细信息具有较高的敏感性,根据编译器实 现的不同可能千差万别,这样在反序列化过程中可能会导致意外的 InvalidClassException。因此,为保证 serialVersionUID 值跨不同 java 编译器实现的一致性,序列化类必须声明一个明确的 serialVersionUID 值。还强烈建议使用 private 修改器显示声明 serialVersionUID(如果可能),原因是这种声明仅应用于立即声明类 -- serialVersionUID 字段作为继承成员没有用处。
java文件的读取方式:
1、按字节读取文件内容
2、按字符读取文件内容
3、按行读取文件内容
4、随机读取文件内容
/**
* 以字节为单位读取文件,常用于读二进制文件,如图片、声音、影像等文件。
*/
public static void readFileByBytes(String fileName) {
File file = new File(fileName);
InputStream in = null;
try {
System.out.println("以字节为单位读取文件内容,一次读一个字节:");
// 一次读一个字节
in = new FileInputStream(file);
int tempbyte;
while ((tempbyte = in.read()) != -1) {
System.out.write(tempbyte);
}
in.close();
} catch (IOException e) {
e.printStackTrace();
return;
}
try {
System.out.println("以字节为单位读取文件内容,一次读多个字节:");
// 一次读多个字节
byte[] tempbytes = new byte[100];
int byteread = 0;
in = new FileInputStream(fileName);
ReadFromFile.showAvailableBytes(in);
// 读入多个字节到字节数组中,byteread为一次读入的字节数
while ((byteread = in.read(tempbytes)) != -1) {
System.out.write(tempbytes, 0, byteread);
}
} catch (Exception e1) {
e1.printStackTrace();
} finally {
if (in != null) {
try {
in.close();
} catch (IOException e1) {
}
}
}
}
/**
* 以字符为单位读取文件,常用于读文本,数字等类型的文件
*/
public static void readFileByChars(String fileName) {
File file = new File(fileName);
Reader reader = null;
try {
System.out.println("以字符为单位读取文件内容,一次读一个字节:");
// 一次读一个字符
reader = new InputStreamReader(new FileInputStream(file));
int tempchar;
while ((tempchar = reader.read()) != -1) {
// 对于windows下,\r\n这两个字符在一起时,表示一个换行。
// 但如果这两个字符分开显示时,会换两次行。
// 因此,屏蔽掉\r,或者屏蔽\n。否则,将会多出很多空行。
if (((char) tempchar) != '\r') {
System.out.print((char) tempchar);
}
}
reader.close();
} catch (Exception e) {
e.printStackTrace();
}
try {
System.out.println("以字符为单位读取文件内容,一次读多个字节:");
// 一次读多个字符
char[] tempchars = new char[30];
int charread = 0;
reader = new InputStreamReader(new FileInputStream(fileName));
// 读入多个字符到字符数组中,charread为一次读取字符数
while ((charread = reader.read(tempchars)) != -1) {
// 同样屏蔽掉\r不显示
if ((charread == tempchars.length)
&& (tempchars[tempchars.length - 1] != '\r')) {
System.out.print(tempchars);
} else {
for (int i = 0; i < charread; i++) {
if (tempchars[i] == '\r') {
continue;
} else {
System.out.print(tempchars[i]);
}
}
}
}
} catch (Exception e1) {
e1.printStackTrace();
} finally {
if (reader != null) {
try {
reader.close();
} catch (IOException e1) {
}
}
}
}
/**
* 以行为单位读取文件,常用于读面向行的格式化文件
*/
public static void readFileByLines(String fileName) {
File file = new File(fileName);
BufferedReader reader = null;
try {
System.out.println("以行为单位读取文件内容,一次读一整行:");
reader = new BufferedReader(new FileReader(file));
String tempString = null;
int line = 1;
// 一次读入一行,直到读入null为文件结束
while ((tempString = reader.readLine()) != null) {
// 显示行号
System.out.println("line " + line + ": " + tempString);
line++;
}
reader.close();
} catch (IOException e) {
e.printStackTrace();
} finally {
if (reader != null) {
try {
reader.close();
} catch (IOException e1) {
}
}
}
}
/**
* 随机读取文件内容
*/
public static void readFileByRandomAccess(String fileName) {
RandomAccessFile randomFile = null;
try {
System.out.println("随机读取一段文件内容:");
// 打开一个随机访问文件流,按只读方式
randomFile = new RandomAccessFile(fileName, "r");
// 文件长度,字节数
long fileLength = randomFile.length();
// 读文件的起始位置
int beginIndex = (fileLength > 4) ? 4 : 0;
// 将读文件的开始位置移到beginIndex位置。
randomFile.seek(beginIndex);
byte[] bytes = new byte[10];
int byteread = 0;
// 一次读10个字节,如果文件内容不足10个字节,则读剩下的字节。
// 将一次读取的字节数赋给byteread
while ((byteread = randomFile.read(bytes)) != -1) {
System.out.write(bytes, 0, byteread);
}
} catch (IOException e) {
e.printStackTrace();
} finally {
if (randomFile != null) {
try {
randomFile.close();
} catch (IOException e1) {
}
}
}
}
/**
* 显示输入流中还剩的字节数
*/
private static void showAvailableBytes(InputStream in) {
try {
System.out.println("当前字节输入流中的字节数为:" + in.available());
} catch (IOException e) {
e.printStackTrace();
}
}
public static void main(String[] args) {
String fileName = "C:/temp/newTemp.txt";
ReadFromFile.readFileByBytes(fileName);
ReadFromFile.readFileByChars(fileName);
ReadFromFile.readFileByLines(fileName);
ReadFromFile.readFileByRandomAccess(fileName);
}
}
5、将内容追加到文件尾部
/**
* A方法追加文件:使用RandomAccessFile
*/
public static void appendMethodA(String fileName, String content) {
try {
// 打开一个随机访问文件流,按读写方式
RandomAccessFile randomFile = new RandomAccessFile(fileName, "rw");
// 文件长度,字节数
long fileLength = randomFile.length();
//将写文件指针移到文件尾。
randomFile.seek(fileLength);
randomFile.writeBytes(content);
randomFile.close();
} catch (IOException e) {
e.printStackTrace();
}
}
/**
* B方法追加文件:使用FileWriter
*/
public static void appendMethodB(String fileName, String content) {
try {
//打开一个写文件器,构造函数中的第二个参数true表示以追加形式写文件
FileWriter writer = new FileWriter(fileName, true);
writer.write(content);
writer.close();
} catch (IOException e) {
e.printStackTrace();
}
}
public static void main(String[] args) {
String fileName = "C:/temp/newTemp.txt";
String content = "new append!";
//按方法A追加文件
AppendToFile.appendMethodA(fileName, content);
AppendToFile.appendMethodA(fileName, "append end. \n");
//显示文件内容
ReadFromFile.readFileByLines(fileName);
//按方法B追加文件
AppendToFile.appendMethodB(fileName, content);
AppendToFile.appendMethodB(fileName, "append end. \n");
//显示文件内容
ReadFromFile.readFileByLines(fileName);
}
}
第一部分:计算机基础(选择题都是多选题)
1、选择题:按照e1、e2、e3、e3、的顺序进栈,出栈的顺序可能是下面的哪种?
选项记不清了,但是很容易,只要从A到D去验证答案的顺序是否正确就行。我全选。这样的题目其他公司也考过很多次。
2、中缀表达X=A+B*(C-D)/E式转后缀表达式。
选项四个,但是貌似只有一个正确的。有些选项是把中序进行变形,应该是移项之后再求后缀的。
3、问以下排序算法哪些是不稳定的。
A 快速排序 B堆排序 C哈希排序 D冒泡排序 E 合并排序
排序算法稳定性讨论:http://blog.csdn.net/kavensu/article/details/8039202
答案是:ABC(我选漏了B,悲剧呀)
4、(填空题)一个四叉树、有n个结点,每个结点都有四个指向它的四个孩子的指针,那么在这4n个指针中,空指针有多少个______。
5、(写程序)实现斐波纳契数列,写一个算法求数列的第n项的值。给出算法复杂度,尽量高效。
我是这样实现的,不知道是不是最优。
- <span style="font-size:14px;">/**
- * 输出Fibonacci数列的第n个数。
- * @param n
- * @return
- */
- public static int Fibonacci(int n){
- if(0<n && n<3){
- return 1;
- }else{
- return Fibonacci(n-1)+Fibonacci(n-2);
- }
- }
- </span>
第二部分:程序设计
这些题目有些是读程序的,我记不住那么多。考了很多操作系统方面的,java的多线程、IO操作、集合框架是重点呀。
1、网易的邮箱有@126.com、@136@.com、@yeah.net 。用户名长度6~18,以字母开头,不区分大小写,其他可以是任意字母或数字。以下正则表达式哪个能正确检查账号的正确性。
选项记不清。但是不难,大家应该也可以写出来。
2、以下程序输出什么?
- <span style="white-space:pre"> </span>byte a = 5;
- int b = 10;
- int c = a>>2+b>>2;
- System.out.println(c);
运行一下,结果是0。记住,>>运算符的优先级比+低,也就是c = 5>> (2+10) >> 2;
3、说说HashMap和TreeMap的区别? 还有不是很记得是哪两个类的区别了,反正也是集合框架里面的。
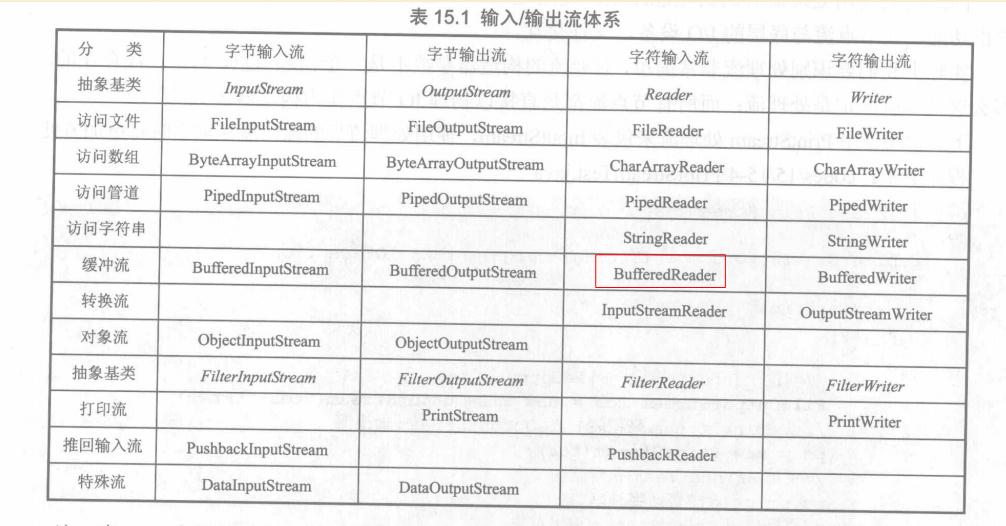
4、关于I/O流操作的。给出了四种情况,然后使用I/O流体系内提供的类写出正确的实现组合。题目提供了很多操作流的类,我不一一写出了,附上一张网上找的图片。
1) 文件的路径:D:\file\test.txt ,读取改文件,并从该文件中按行获取内容(好像是这样表述的);
2)文件的路径:D:\file\test.data ,是字节数据,读取该文件并按行输出内容;
3)str是很长的字符串……忘记了……
4)…………
倒数第二题:实现序列化接口Serialize的时候,如果不指定serialVersionUID 的值,编译时就会出现警告,为什么?什么情况下需要修改serialVersionUID 的值?
参 考:序列化运行时使用一个称为 serialVersionUID 的版本号与每个可序列化类相关联,该序列号在反序列化过程中用于验证序列化对象的发送者和接收者是否为该对象加载了与序列化兼容的类。如果接收者加载的该 对象的类的 serialVersionUID 与对应的发送者的类的版本号不同,则反序列化将会导致 InvalidClassException。可序列化类可以通过声明名为 "serialVersionUID" 的字段(该字段必须是静态 (static)、最终 (final) 的 long 型字段)显式声明其自己的 serialVersionUID:
ANY-ACCESS-MODIFIER static final long serialVersionUID = 42L;
如果可序列化类未显式声明 serialVersionUID,则序列化运行时将基于该类的各个方面计算该类的默认 serialVersionUID
值,如“Java(TM) 对象序列化规范”中所述。不过,强烈建议 所有可序列化类都显式声明 serialVersionUID
值,原因计算默认的 serialVersionUID
对类的详细信息具有较高的敏感性,根据编译器实
现的不同可能千差万别,这样在反序列化过程中可能会导致意外的
InvalidClassException。因此,为保证 serialVersionUID 值跨不同 java
编译器实现的一致性,序列化类必须声明一个明确的 serialVersionUID 值。还强烈建议使用 private 修改器显示声明
serialVersionUID(如果可能),原因是这种声明仅应用于立即声明类 -- serialVersionUID
字段作为继承成员没有用处。
6、最后一题(题目好长):一个系统有多个定时任务,设计一种数据结构用来存储这些任务。考虑定时任务的添加、删除和触发。有10000个任务的时候,分析这种数据结构的性能。(大概是这样的意思)。
我 写了一个散列表。类似于HashMap的结构。我的理解是,在添加、删除和触发的操作中,触发更重要一些。因为定时要准确,触发的延时就决定了定时的准确 性。而触发操作我理解成是查找操作,找需要唤醒的那个定时。而哈希查找性能是最理想的。不知道我这样的理解是否正确,求指导。
